účelem tohoto článku je vysvětlit redundanci z hlediska výpočetní techniky, sítí a hostingu. Poskytneme příklady redundantních technologických řešení v reálném světě, abychom ilustrovali, co je redundance a jak funguje.
Atlantic.Net vytvořil více hostingových prostředí, včetně odolné cloudové platformy, vysokorychlostního hostingu VPS, infrastruktury kompatibilní s HIPAA a spravovaného soukromého cloud hostingu. Všechny naše systémy jsou postaveny s redundancí jako primárním hnacím faktorem procesu návrhu.
v běžné angličtině může mít redundance negativní konotaci; něco redundantního obvykle není potřeba nebo je považováno za nadbytečné. V prostředí cloud hostingu však redundance může znamenat rozdíl mezi bezproblémovou dostupností systému a nežádoucími nebo neočekávanými prostoji.
- co je redundantní systém?
- typy redundantních systémů
- Příklady Nadbytečných Softwarových Služeb
- Hyper-V replika
- Hyper-V Clustering
- HAProxy
- Heartbeat
- příklady redundantních hardwarových služeb
- RAID
- Síťové Redundance
- První Hop Redundance Protokoly (FHRP)
- Virtual Router Redundancy Protocol (VRRP)
- Hot Standby Router Protocol (HSRP)
- Gateway Load Balancing Protocol (GLBP)
- redundance datového centra
- závěr
co je redundantní systém?
redundantní systém poskytne podporu při selhání nebo vyvažování zátěže, aby chránil živý systém v případě neočekávaného selhání. V případě výpadku napájení, mechanického nebo softwarového systému bude mít redundantní systém duplicitní součást nebo platformu, na kterou se může vrátit. Obecně lze jakoukoli součást systému s jediným bodem selhání považovat za riziko pro výrobní služby.
Napájení nebo mechanické systémy mají jednodušší ustoupit strategie, které vyžadují pouhá přítomnost jiného stejného typu služeb; software pro převzetí služeb při selhání obvykle vyžadují další konfiguraci na hostitelském systému nebo master nebo brány.
redundantní funkce se doporučují pro jakýkoli kritický obchodní systém, ale zejména pro systémy, které mají významný dopad během prostojů. Některé podniky mohou uchovávat všechny své kritické informace o zákaznících v databázi; proto, pro účely kontinuity podnikání, ochrana této databáze redundancí ochrání integritu dat v případě katastrofického selhání.
typy redundantních systémů
redundantní systém se skládá z nejméně dvou systémů, které jsou vzájemně propojeny a navrženy pro stejný účel. Existuje mnoho různých typů redundantní konfigurace systému k dispozici, a různé implementace systému poskytují jedinečné přístupy k tomu, jak udržet systém za všech okolností.
ne všechny servery musí být konfigurovány s redundancí; spíše by měly být brány v úvahu pouze ty nejkritičtější. Důrazně doporučujeme podrobné posouzení rizik, abychom pochopili, jaké servery jsou v rozsahu a maximální množství prostojů, které vaše servery zvládnou. Pomocí tohoto posouzení určete strategii RTO (cíl doby zotavení) a RPO (cíl bodu zotavení). RTO je maximální množství přijatelných prostojů. To se může pohybovat od 5 sekund do 24 hodin. RPO je časový bod, od kterého požadujete svá data; například vaše firma může fungovat s maximální ztrátou dat v hodnotě 24 hodin.
Zde je několik populární příklady:
- Aktivní-Neaktivní/Hot-Studená – li jednou ze součástí systému je aktivní systém a další je neaktivní nebo vypnout. Neaktivní komponenta se aktivuje pouze tehdy, když právě spuštěná komponenta selže nebo prochází údržbou
- Active-Active/Hot-Hot – když jsou oba systémy aktivní a vytvářejí připojení. Toto je nejčastěji známé jako shlukování. Zařízení před oběma stroji obvykle určí, jak rozdělit příchozí provoz
- Active-Standby/Hot-Warm – když jsou oba systémy zapnuté, ale pouze jeden provádí připojení. Druhý systém je určen k pravidelnému přijímání aktualizací nebo záloh z primárního systému. V případě poruchy převezme systém v pohotovostním režimu primární roli, dokud nebude možné obnovit původní systém.
každý typ má své klady a zápory.
- Aktivní-Neaktivní/Hot-Studená systémy mohou poskytnout jednoduchý redundantní platformě, ale žádné převzetí služeb při selhání bude mít za následek uživatelé vidět starší verzi systému.
- Active-Active/Hot-Horké, bude vyžadovat neustálé aktualizace obou systémů, a to buď ručně, nebo prostřednictvím samostatné služby, aby bylo zajištěno, že všichni uživatelé mohou použít buď systém. Tento přístup může výrazně snížit aktivní zatížení služby, kterou poskytujete zákazníkům.
- Active-Standby/Hot-Warm bude poskytovat failover schopnosti hot-cold s více up-to-date kopii vašeho aktivního systému na failover, ale neposkytuje žádné zatížení uvolnění.
jsou k dispozici další formy redundance více uzlů, které umožňují větší redundanci a robustní řešení vyrovnávání zátěže. V tomto okamžiku budete mít klastr s vysokou dostupností, známý také jako klastr HA.
to může použít libovolnou kombinaci dříve uvedených řešení redundance s maximální flexibilitou v přístupu nebo množství redundance potřebné. Klastry HA lze také nastavit na více fyzických místech, aby byla zajištěna dostupnost až na úroveň páteřní sítě internetu.
Příklady Nadbytečných Softwarových Služeb
Krátké nízkou dostupnost zdrojů, existuje jen velmi málo důvodů, aby neměl proprietární replikace nebo redundantní služby nastavit ve virtuálním prostředí; proto, mnoho z těchto služeb jsou k dispozici ve výchozím nastavení ve většině virtualizace systémů. Všechny naše cloud služby replikace k dispozici, funkce, která nám umožňuje replikovat libovolný server z jednoho uzlu do druhého, ať už jsou ve stejném datovém centru nebo samostatných datových center regionů.
Hyper-V replika
Hyper-V Replika je forma redundance za tepla. Primární virtuální stroj je vytvořen na jednom fyzickém hostiteli a přijímá příchozí připojení. Při povolení replikace jsou virtuální pevné disky nového počítače přeneseny do samostatného fyzického hostitele Hyper-V. Tento hostitel pak nakonfiguruje VM na sebe, který se replikuje na uživatelem definovaném plánu, aby zajistil, že bude pořízen nejnovější obrázek aktivního serveru. Další kontrolní body mohou být také zachovány. Privátní hosting Hyper-V se spravovanými službami poskytuje Atlantic.Net s touto funkcí pečené v; kontaktujte náš tým pro další informace.
Hyper-V Clustering
Hyper-V je také schopen shlukování prostřednictvím připojení k jiným hostitelům Hyper-V. Virtuální počítače na jakémkoli hostiteli Hyper-V mohou být seskupeny na tomto jedinečném hostiteli, aby poskytovaly redundanci na místní úrovni prostřednictvím virtuálních sítí.
Microsoft Network Load Balancing (NLB) lze použít k vytvoření jediného zdroje složeného z více hostitelů, kteří sdílejí stejné informace, a poskytují tak jednoduchý přístupový bod pro sdílení souborů. Protože je to omezeno pouze množstvím dostupných zdrojů, můžete teoreticky nastavit více hostitelů s více VM pro maximální redundanci, což by vám také umožnilo provádět údržbu jednotlivých VM bez obětování služby nebo dostupnosti zdrojů. Privátní hosting Hyper-V se spravovanými službami poskytuje Atlantic.Net s touto funkcí pečené v; kontaktujte náš tým pro další informace.
HAProxy
kromě Hyper-V lze pro služby failover nebo load balancing použít gateway zařízení, jako je firewall. Například Atlantik.Net může poskytnout pfSense s vysokou dostupností Proxy, také známý jako HAProxy.
HAProxy bude fungovat jako load balancer, proxy, nebo jednoduché hot-teplé řešení s vysokou dostupností pro TCP a HTTP aplikací založených. HAProxy je velmi populární open-source řešení založené na Linuxu, které používají některé z nejnavštěvovanějších webů na světě.
Heartbeat
Heartbeat je služba dostupná na většině distribucí Linuxu, která se používá k určení, zda jsou uzly v clusteru stále nahoře nebo reagují. Nastavení je velmi jednoduché a poskytuje funkce převzetí služeb při selhání každému systému pracujícímu přes TCP.
vývojáři, srdeční Tep také doporučit další cluster resource manažery, které spustit nebo zastavit služby, založené na tom, zda konkrétní hostitel je dole. Heartbeat to zahrnuje, ale další manažeři jsou k dispozici. Díky jednoduchosti Heartbeatu je vysoce přizpůsobitelný. Cloud Hosting platformy poskytované Atlantic.Net tuto funkci již máte upečenou a v případě potřeby vám můžeme pomoci s implementací Heartbeat na vaší soukromé distribuci Linuxu.
příklady redundantních hardwarových služeb
nejlepší na redundantním hardwaru je jeho jednoduchost. Zatímco softwarové služby mohou vyžadovat nadměrnou konfiguraci a jsou možná docela citlivé, hardware je obvykle velmi jednoduchý a neuvěřitelně odolný. Prvním příkladem, na který se podíváme, je široce používaná technologie RAID.
RAID
RAID je zkratka pro Redundant Array of Independent Disks (nebo Redundant Array of Levných Disků v závislosti na tom, jak dlouho jsi to používal) a má více úrovní, použít buď pro ochranu údajů nebo zvýšené disk I/O.
RAID můžete buď nastavit prostřednictvím softwaru nebo hardwaru řadiče. Řadič má software a konfiguraci nezbytnou pro správu disků RAID. Konfiguraci lze exportovat do různých systémů s malou nebo žádnou další konfigurací.
RAID lze nastavit několika různými způsoby, aby byla zajištěna dobrá rovnováha obou jeho vlastností:
- RAID 0 – to v podstatě není redundance – Žádné disky v systému sdílet data prostřednictvím zrcadlení, ale všechna data jsou pruhované přes každý disk poskytuje zvýšenou rychlost čtení/zápisu. Každá jednotka může stále využívat úložiště, které jí bylo poskytnuto, což znamená, že čím více jednotek přidáte do RAID 0, tím více místa budete mít.
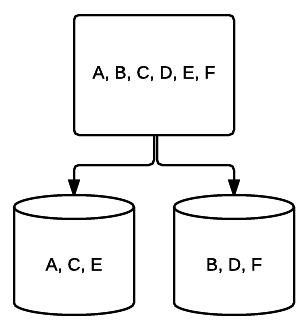
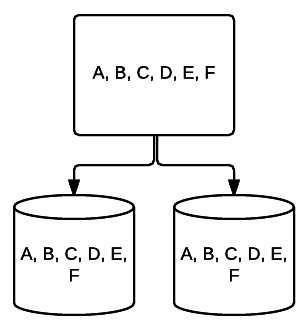
- RAID 1 – základní forma zrcadlení poskytuje vynikající redundance na úkor prostoru. V systému se dvěma jednotkami je na druhou zapsána úplná kopie dat na jedné jednotce. Tato redundance se zvyšuje s každou přidanou jednotkou. Protože všechna data musí být zrcadlena na všech jednotkách, celkový prostor v systému bude omezen pouze na prostor nejmenší jednotky v systému.
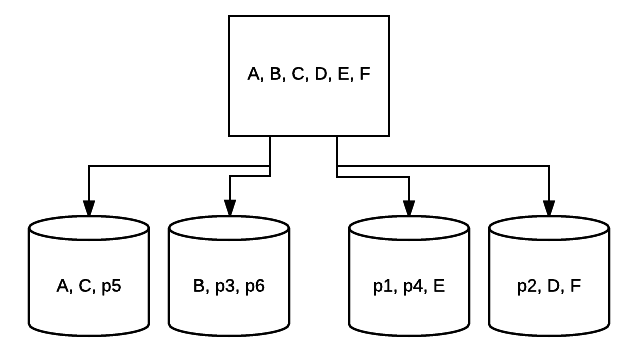
- RAID 5 – Tato forma RAID se obvykle používá ke zvýšení rychlosti čtení a spolehlivost. V tomto případě jsou pruhy umístěny kolem každé jednotky v systému, přičemž minimální jsou 3 jednotky. Současně je o každé jednotce umístěn další blok dat opravujících chyby v technice zvané parita. Tím se zkontroluje, zda se data mění při přenosu z jedné jednotky na druhou. To také poskytuje minimální formu redundance, protože 1 z těchto jednotek může selhat a systém může stále běžet. Čím více jednotek bylo přidáno do tohoto typu nastavení RAID, tím více se zvyšuje rychlost čtení. S minimální redundancí a prokládání napříč všemi disky, celkové množství místa v tomto nastavení se rovná velikosti vašeho logický svazek RAID časy počet disků, které používáte, minus jedna. Například, pokud máte 5 500 GB disky v RAID 5, měli byste 2000 GB použitelné, nebo 2 TB (500 *(5-1)=2000).
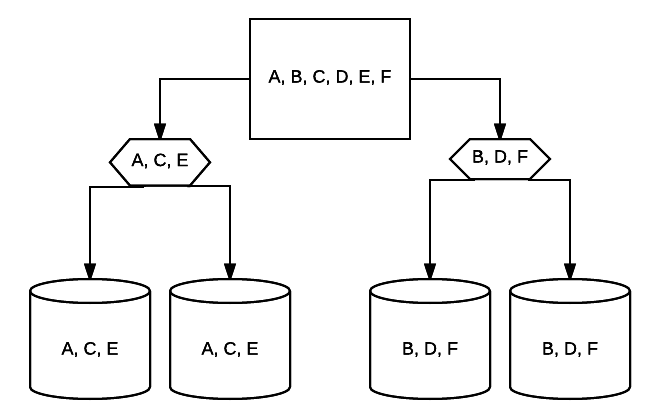
- RAID 10 – jedná se o kombinaci RAID 1 a RAID 0. V tomto případě jsou všechna data pruhována napříč každým zařízením, přičemž bloky dat jsou také zrcadleny v celém pruhovaném systému. Například v systému 4 drive RAID 10 mohou mít jednotky 2 500 GB stejná data, ale ne všechna data potřebná pro správnou funkci systému. 2 budou vyžadována data jiných jednotek. Přemýšlejte o každém systému RAID 1 jako o jediné jednotce a o každém z těchto systémů umístěných do pole RAID 0. V tomto nastavení může být výkon drasticky zvýšen jako v RAID 0, s určitou redundancí stále na místě se zrcadlením. Až polovina jednotek v systému může selhat před zhroucením systému, ale stejně jako u jakéhokoli redundantního pole je nejlepší vyměnit disky co nejdříve. Atlantic.Net používá RAID 10 pro všechna úložiště SSD Cloud VPS.
Pro větší ochranu, RAID řadiče jsou chráněny záložní baterie jednotky, které pohánějí ROM čipy slouží k uložení konfigurace do paměti v případě výpadku napájení, atd. BBU poskytne napájení pole RAID, které je součástí vypnutého systému po malou dobu, což umožní, aby obsah mezipaměti řadiče RAID zůstal neporušený. To může být zachránce, pokud jsou informace neustále přiváděny do pole RAID a jakékoli prostoje by mohly způsobit poškození dat.
takže váš fyzický systém a služby uvnitř mohou být konstruovány redundantně poměrně adekvátně. Ale co vaše připojení k jakékoli části vašeho systému? Jako v, vaše přímé připojení k internetu do vašeho systému jako celku?
Síťové Redundance
První Hop Redundance Protokoly (FHRP)
na rozdíl od dynamické brána discovery protokoly, statické brány umožňují jednoduché chmel mezi klientem a jejich příslušné bráně, ale to vytváří single point of failure – tedy brány sám.
aby se zabránilo nebo snížilo dopad selhání brány, byly vytvořeny Fhrp. Poskytují redundantní brány záložní, nebo nabízejí vyvažování zátěže pro systémy s vysokým provozem, spolu s redundancí. Tyto protokoly zahrnují VRRP, HSRP a GLBP.
Virtual Router Redundancy Protocol (VRRP)
VRRP je forma redundance používá pro routery, které vyžaduje alespoň dvě fyzicky oddělené směrovače připojené buď přes Ethernet nebo optické vlákno připojení. V této situaci je vytvořen a sdílen „virtuální směrovač“ obsahující statické trasy mezi jednotlivými systémy.
jeden systém je považován za „master“ a druhý za „backup“. Když master selže, záloha převezme jako další master. To lze nastavit s více zálohami pro extra redundanci. Koncept je velmi podobný Heartbeat v tom, že záložní systémy zkontrolují, zda je master k dispozici. Jakmile neobdrží odpověď, po předem stanoveném čase záloha převezme kontrolu nad virtuálním přepínačem a přijme připojení pro všechny požadavky přicházející pro výchozí IP nakonfigurovanou pro hlavní přepínač.
Hot Standby Router Protocol (HSRP)
HSRP je jako VRRP; nicméně, v tomto případě nakonfigurován virtuální přepínač není ‚switch‘, ale spíše logické skupiny více směrovačů. IP skupiny je IP, která není přiřazena fyzickému hostiteli. Místo toho je skupině přiřazena IP a jeden ze směrovačů je určen jako „aktivní“ směrovač.
pohotovostní směrovač je připraven k připojení, pokud by Aktivní směrovač klesl. Všechny směrovače kromě aktivního a pohotovostního režimu poslouchají, aby určily své místo v řadě. HSRP je Cisco proprietární protokol, a má velmi málo, drobné rozdíly VRRP jako jejich výchozí časovače určení, kdy k převzetí služeb při selhání. HSRP byl asi o něco déle a je známější ve srovnání s VRRP.
Gateway Load Balancing Protocol (GLBP)
hlavní výhodou GLBP oproti HSRP a VRRP je jeho schopnost načíst rovnováhu nad poskytováním redundance bráně s malou až žádnou další konfigurací. Podobně jako HSRP a VRRP, GLBP vytvoří skupinu mezi fyzickými směrovači a určí aktivní virtuální bránu nebo AVG.
virtuální IP, který v současné době nepoužívá žádný ze směrovačů ve skupině, je přiřazen AVG. AVG pak distribuuje virtuální MAC adresy mezi ostatní směrovače ve skupině. Každý záložní router je nyní považován za aktivní virtuální Forwarder nebo AVF.
ARP požadavky odeslané do AVG poskytnou klientovi odesílajícímu požadavek jinou virtuální MAC adresu. V tomto bodě, provoz z klienta na virtuální IP skupiny forwardů k routeru, jehož virtuální MAC adresy, které obdrželi, takže každý směrovač, aby ještě být používán místo toho, aby seděl se založenýma rukama.
V případě selhání AVG, založené na prioritách voleb se koná, stejně jako v HSRP a VRRP, a další zálohy má své místo, distribuce virtuálních adres MAC jako normální. Ostatní směrovače si stále zachovávají virtuální MAC adresu poskytovanou původním AVG a věci pokračují jako obvykle. V případě selhání jednoho z AVFs AVG zabrání směrování provozu na svou virtuální MAC adresu.
stejně jako HSRP, GLBP je Cisco proprietární forma FHRP.
redundance datového centra
kromě opatření redundance pro vaše osobní servery nebo směrovače jsou datová centra navržena tak, aby byla odolná vůči selhání systému. Datová centra spadají do úrovní definovaných Institutem Uptime, aby poskytovaly odolnost proti chybám při selhání jakékoli mechanické nebo servisní poruchy, což umožňuje co největší provozuschopnost.
existují čtyři úrovně, z nichž každá navazuje na sebe, aby poskytovala vysokou dostupnost všem klientům v datovém centru:
- Tier I-Základní kapacita: To vyžaduje prostor pro skupinu IT pro operace datových center, nepřerušitelný zdroj napájení (UPS), který monitoruje a filtruje spotřebu energie a vyhrazené chladicí zařízení, které neustále běží 24/7. To také zahrnuje generátor energie v případě výpadku elektrické energie.
- Tier II-redundantní komponenty kapacity: vše, co úroveň I poskytuje, plus redundantní výkon a chlazení zařízení. To může zahrnovat další jednotky UPS nebo další generátory.
- úroveň III-současně udržovatelná: Vše, co Tier II poskytuje, plus další zařízení na místě, aby se zabránilo nutnosti odstávek pro výměnu nebo údržbu zařízení. Na této úrovni se redundantní výkon a chlazení aplikují přímo na všechna technická zařízení a samotné zařízení je nakonfigurováno pro redundanci nebo bezproblémové převzetí služeb při selhání.
- Tier IV-odolnost proti poruchám: vše, co Tier III poskytuje, plus nepřetržitý servis na úrovni poskytovatele. Zatímco datové centrum může mít elektřinu nebo vodu poskytovanou městským nebo státním poskytovatelem, je vyžadována sekundární linka každé služby využívané datovým centrem. To zahrnuje také ISP. V případě poruchy na kterékoli části vedoucí k klientskému vybavení je připraven záložní plán pro bezproblémový přechod.
závěr
redundance se stala každodenním termínem v IT průmyslu kvůli nutnosti. Vysoká dostupnost služeb poskytuje našim zákazníkům snadný a spolehlivý zážitek.
ať už na úrovni služeb nebo na úrovni datových center, poskytování redundance do vašeho systému je důležitým a obtížným problémem. Doufejme, tento dokument vrhl světlo na dostupné možnosti a pomůže při jakýchkoli rozhodnutích týkajících se vysoké dostupnosti do budoucna.
připraveni využít Atlantic.Net redundantní systémy? Kontaktujte nás ještě dnes, abyste zjistili více o Dedikovaný Server Hosting s Atlantic.Net.
===Zdroje===
Redundantní Systém Základní Pojmy: http://www.ni.com/white-paper/6874/en/
Studený/Teplý/Horký Server: http://searchwindowsserver.techtarget.com/definition/cold-warm-hot-server
Vysokou Dostupnost Clusterů: https://www.mulesoft.com/resources/esb/high-availability-cluster
Repliky Hyper-V: https://technet.microsoft.com/en-us/library/jj134172(v=ws.11).aspx
Hyper-V and High Availability: https://technet.microsoft.com/en-us/library/hh127064.aspx
HAProxy Description: http://www.haproxy.org/#desc
HAProxy – They use it!: http://www.haproxy.org/they-use-it.html
Heartbeat: http://www.linux-ha.org/wiki/Main_Page
RAID Definition: http://searchstorage.techtarget.com/definition/RAID
Striping: http://searchstorage.techtarget.com/definition/disk-striping
RAID Battery Backup Units: https://www.thomas-krenn.com/en/wiki/Battery_Backup_Unit_(BBU/BBM)_Maintenance_for_RAID_Controllers
High-Availability – VRRP, HSRP, GLBP: http://www.freeccnastudyguide.com/study-guides/ccna/ch14/vrrp-hsrp-glbp/
Understanding VRRP: http://www.juniper.net/techpubs/en_US/junos/topics/concept/vrrp-overview-ha.html
Configuring VRRP: http://www.cisco.com/c/en/us/td/docs/ios-xml/ios/ipapp_fhrp/configuration/15-mt/fhp-15-mt-book/fhp-vrrp.html
Configuring GLBP: http://www.cisco.com/c/en/us/td/docs/ios-xml/ios/ipapp_fhrp/configuration/xe-3s/fhp-xe-3s-book/fhp-glbp.html
Explaining the Uptime Institute’s Tier Classification System: https://journal.uptimeinstitute.com/explaining-uptime-institutes-tier-classification-system/