: Arshad Ali | Aktualizováno: 2020-07-29 | Komentáře (6) | Související: Více > PŘIPOJIT Tabulky
V tip SQL Server JoinExamples, Jeremy Kadlec mluvil o různé logické spojení operátory, ale jak SQL Server je realizovat fyzicky? Jaké jsou různé fyzické joinoperátory? Jak se liší od sebe a v jakém scénáři je jeden preferovánnad ostatními? V tomto tipu se zabýváme těmito otázkami a dalšími.
řešení
při psaní dotazů používáme logické operátory k definování relačního dotazu na koncepční úrovni(co je třeba udělat). SQL implementuje tyto logické operátorys třemi různými fyzickými operátory pro implementaci operace definované logickými operátory (jak je třeba provést). I když existují desítky fyzickýchoperátorů, v tomto tipu se budu zabývat konkrétními fyzickými operátory. I když máme různé druhy logických spojení na koncepční / dotazovací úrovni, ale SQL Serverimplements je všechny se třemi různými fyzickými operátory spojení, jak je popsáno níže.
se Budeme zabývat:
- Vnořené Smyčky Spojit
- Sloučit spojení
- spojení Hash
podíváme se atexecution plány, jak tyto hospodářské subjekty a jsem se vysvětlit, proč každé vyskytuje.
pro tyto příklady používám databázi AdventureWorks.
SQL Server vnořené smyčky připojit vysvětleno
před kopáním do detailů, dovolte mi, abych vám nejprve říct, co vnořené smyčky joinis pokud jste nový programovacího světa.
Vnořené Smyčky spojení je logické struktury, v nichž jedna smyčka (iterace) residesinside další, to znamená, že pro každou iteraci vnějšího cyklu všechny theiterations vnitřní smyčky jsou provedeny/zpracované.
vnořené smyčky fungují stejným způsobem. Jeden ze spojovacích stolů je označenjako vnější stůl a druhý jako vnitřní stůl. Pro každý řádek vnější tabulky jsou všechny řádky z vnitřní tabulky porovnány jeden po druhém, pokud se řádek shodujeje zahrnut ve výsledku-jinak je ignorován. Pak další řádek zvnější stůl je zvednut a stejný proces se opakuje a tak dále.
SQL Server optimalizátor může zvolit Vnořené Smyčky spojit, když jeden z joiningtables je malý (považován za vnější tabulka) a další jeden je velký (consideredas vnitřní tabulka, která je indexována na sloupec, který je v join) a henceit vyžaduje minimální I/O a nejmenší srovnání.
optimalizátor zvažuje tři varianty spojení vnořených smyček:
- naivní vnořené smyčky spojit v takovém případě hledat scansthe celou tabulku nebo index
- index vnořené smyčky spojit při hledání můžete využít anexisting index provádět vyhledávání
- dočasné index vnořené smyčky připojit, pokud optimalizátor createsa dočasné index jako součást plánu dotazu a ničí to po dotazu executioncompletes
Index Vnořené Smyčky spojit provádí lépe než sloučit spojení nebo spojení hash ifa malou sadu řádků, které jsou zapojeny. Kdežto pokud se jedná o velkou množinu řad, nemusí být spojení smyček optimální volbou. Vnořené smyčky podporují téměř všechny typy spojů kromě pravého a úplného vnějšího spojení, pravého polospojení a pravého antisemijoinu.
- Ve Scénáři #1, jsem se přidala do SalesOrderHeader tabulka s SalesOrderDetailtable a upřesní kritéria pro filtrování zákazníka withCustomerID = 670.
- filtrovat kritéria vrátí 12 záznamy z SalesOrderHeader tabulkya proto být menší, tato tabulka byla považována za vnější tabulky (horní, jeden v grafickém provedení dotazu plán)pro optimalizaci.
- Pro každý řádek z těchto 12 řádků z vnější tabulky, rowsfrom vnitřní SalesOrderDetail tabulky jsou uzavřeno (nebo innertable je snímán 12 krát v každém čase pro každý řádek pomocí indexu hledat nebo correlatedparameter z vnější tabulky) a 312 odpovídající řádky jsou vráceny jako byste vidět na druhém obrázku.
- ve druhém dotazu níže používám SET STATISTICS PROFILE ON k zobrazení profile informací o provedení dotazu spolu s výsledkem dotazu-set.
Scénář #1 – Vnořené Smyčky Spojit Příklad
SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader H INNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID = 670
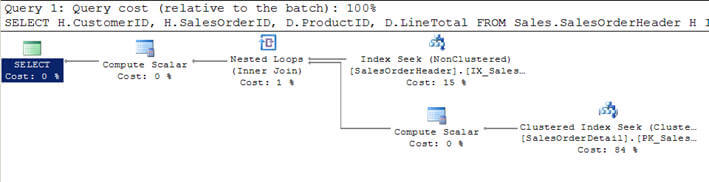
SET STATISTICS PROFILE ONSELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader HINNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderIDWHERE H.CustomerID = 670SET STATISTICS PROFILE OFF

Pokud je počet záznamů je velký, SQL Server může vybrat parallelizea vnořené smyčky distribucí vnější řádky tabulky náhodně mezi availableNested Smyčky nitě dynamicky. To neplatí totéž pro vnitřní tablerows ačkoli. Chcete-li se dozvědět více o paralelních skenechklikněte zde.
SQL Server Sloučení Připojit Vysvětlil
první věc, co potřebujete vědět o Sloučení spojení je, že to requiresboth vstupy, které mají být řazeny na připojit klíče/sloučit sloupce (nebo obě vstupní tabulky mají clusteredindexes na sloupec, který se připojí do tabulky) a také to vyžaduje alespoň jeden equijoin(rovná se) výraz/predikát.
protože jsou řádky předřazeny, sloučení spojení okamžitě zahájí proces porovnávání. Přečte řádek z jednoho vstupu a porovná jej s řádkem jiného vstupu.Pokud řádky zápas, který odpovídal řádek je považován za v result-set (pak to readsthe další řádek ze vstupního stolu, dělá to samé srovnání/zápas, a tak dále) nebo menší o dva řádky je ignorován a proces pokračuje tímto způsobem untilall řádky byly zpracovány..
Sloučit spojení provádí lépe, když se připojí velká vstupní tabulky (pre-indexovány / řazena)jako cena je součtem řádků obou vstupních tabulek oproti NestedLoops, kde je produkt řádků obou vstupních tabulek. Někdy optimizerrozhodne použít spojení sloučení, když vstupní tabulky nejsou seřazeny, a proto používá explicitní fyzický operátor řazení,ale může být pomalejší než použití indexu (předřazená vstupní tabulka).
- ve skriptu #2 používám podobný dotaz jako výše, ale tentokrát jsem přidal klauzuli WHERE, abych získal všechny zákazníky větší než 100.
- v tomto případě se optimalizátor rozhodne použít spojení sloučení, protože oba vstupy jsou velké z hlediska řádků a jsou také předindexovány/tříděny.
- můžete si také všimnout, že oba vstupy jsou skenovány pouze jednou, na rozdíl od 12 skenů, které jsme viděli ve vnořených smyčkách připojit výše.
Scénář #2 – Sloučit Spojit Příklad
SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader H INNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID > 100
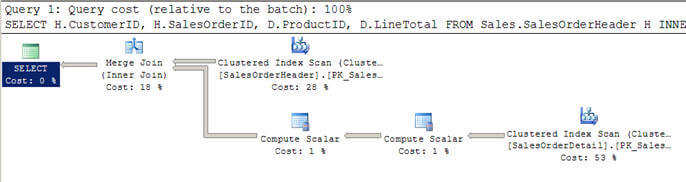
SET STATISTICS PROFILE ONSELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader HINNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderIDWHERE H.CustomerID > 100SET STATISTICS PROFILE OFF

Sloučení spojení je často efektivnější a rychlejší spojení operátor-li sorteddata lze získat z existujícího B-tree index a plní téměř všechny joinoperations jak dlouho jak tam je alespoň jeden rovnosti predikát spojení zapojeni. Rovněž podporuje více rovnosti připojit predikáty tak dlouho, dokud vstupní tabulky aresorted na všech spojení klíčů a jsou ve stejném pořadí.
přítomnost výpočetního skalárního operátora označuje vyhodnocení výrazupro vytvoření vypočtené skalární hodnoty. Ve výše uvedeném dotazu volím LineTotalwhich je odvozený sloupec, proto byl použit v plánu provádění.
SQL Server hash Join Explained
Hash join se běžně používá, když jsou vstupní tabulky poměrně velké a neexistují na nich žádné adekvátní kódy. Hash spojení se provádí ve dvou fázích; Fáze sestavení a fáze sondy a tím i hash join má dva vstupy, tj. build input a probeinput. Menší ze vstupů je považován za sestavení vstup (minimalizovat thememory požadavek ukládat hash tabulky diskutovány později) a samozřejmě otherone je sonda vstup.
během fáze sestavení jsou skenovány spojovací klíče všech řádků tabulky sestavení.Hashe jsou generovány a umístěny v tabulce hash v paměti. Na rozdíl od sloučení join, to je blokování (žádné řádky jsou vráceny) až do tohoto bodu.
během fáze sondy se skenují spojovací klíče každého řádku tabulky sondy.Opět hashe jsou generovány (pomocí stejné hašovací funkce jako výše) a comparedagainst odpovídající hašovací tabulky pro zápas.
hašovací funkce vyžaduje značné množství cyklů CPU pro generování hashesand paměťové prostředky pro uložení tabulky hash. Pokud je tlak v paměti, některé oddíly tabulky hash jsou vyměněny za tempdb a kdykoli je potřeba (buď zkoumat nebo aktualizovat obsah), je přenesen zpět do mezipaměti.Chcete-li dosáhnout vysokého výkonu, optimalizátor dotazů může paralelizovat hash join toscale lépe než jakýkoli jiný join, pro více podrobnostíklikněte zde.
v zásadě Existují tři různé typy hash spojení:
- V paměti Hash Spojit v takovém případě dostatek paměti je k dispozici obchod hash tabulky
- Grace Hash Spojit v takovém případě hash tabulky nelze přesně padnoucí paměti a některé oddíly se rozlil do databáze tempdb
- Rekurzivní Hash Spojit v takovém případě hash tabulka je tak largethe optimizer má používat mnoho úrovní sloučit se připojí.
pro více informací o těchto různých typechklikněte zde.
- ve skriptu #3 vytvářím dvě nové velké tabulky (ze stávajících AdventureWorkstables) bez indexů.
- můžete vidět, že optimalizátor se v tomto případě rozhodl použít hash join.
- opět na rozdíl od vnořených smyček join, to není skenování vnitřní tabulky násobky.
Scénář #3 – Hash Spojit Příklad
--Create tables without indexes from existing tables of AdventureWorks database SELECT * INTO Sales.SalesOrderHeader1 FROM Sales.SalesOrderHeader SELECT * INTO Sales.SalesOrderDetail1 FROM Sales.SalesOrderDetail GO SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader1 H INNER JOIN Sales.SalesOrderDetail1 D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID = 670 GO
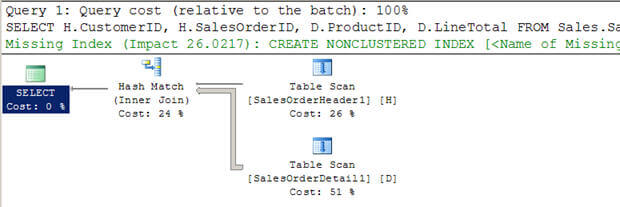
SET STATISTICS PROFILE ON SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader1 H INNER JOIN Sales.SalesOrderDetail1 D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID = 670 SET STATISTICS PROFILE OFF

--Drop the tables created for demonstration DROP TABLE Sales.SalesOrderHeader1 DROP TABLE Sales.SalesOrderDetail1
Poznámka: SQL Server dělá docela dobrou práci při rozhodování, který joinoperator použít v každém stavu. Pochopení těchto podmínek vám pomůže pochopitco lze provést při ladění výkonu. To není doporučeno používat spojení rady (usingOPTION doložka) vynutit SQL Server použít konkrétní operátor spojení (pokud nejsou další způsob, jak ven), ale můžete použít i jiné prostředky, jako je aktualizace statistik,vytváření indexů, nebo re-psát svůj dotaz.
další kroky
- Recenzesql ServerJoin příklady tip.
- Recenzelogické a fyzické operátory referenční článek na technetu.
Poslední aktualizace: 2020-07-29


 Arshad Ali is a SQL and BI Developer focusing on Data Warehousing projects for Microsoft.
Arshad Ali is a SQL and BI Developer focusing on Data Warehousing projects for Microsoft.View all my tips
- More Database Developer Tips…