v dnešním článku se podíváme na válcování a rozšiřování oken.
na konci příspěvku, budete moci odpovědět na tyto otázky:
- Co je rolovací okno?
- co je rozšiřující se okno?
- proč jsou užitečné?
co je rolovací nebo rozšiřující okno?

zde je normální okno.
používáme normální okna, protože chceme mít pohled na vnější stranu, čím větší je okno, tím více zvenčí vidíme.
Také, jako obecné pravidlo, čím větší okna na domě někdo je, tím lépe jejich akciové portfolio udělal …
Stejně jako v reálném systému windows, data, windows, také nám nabídnout malé nahlédnutí do něčeho většího.
pohyblivé okno nám umožňuje prozkoumat podmnožinu našich dat.
Rolling Windows
Často, chceme vědět, statistická vlastnost naší časové řady dat, ale proto, že všechny stroje času jsou zavřený v Roswellu, nemůžeme vypočítat statistiku za celý vzorek a použít k získat vhled.
To by představovalo předpojatost pohledu do našeho výzkumu.
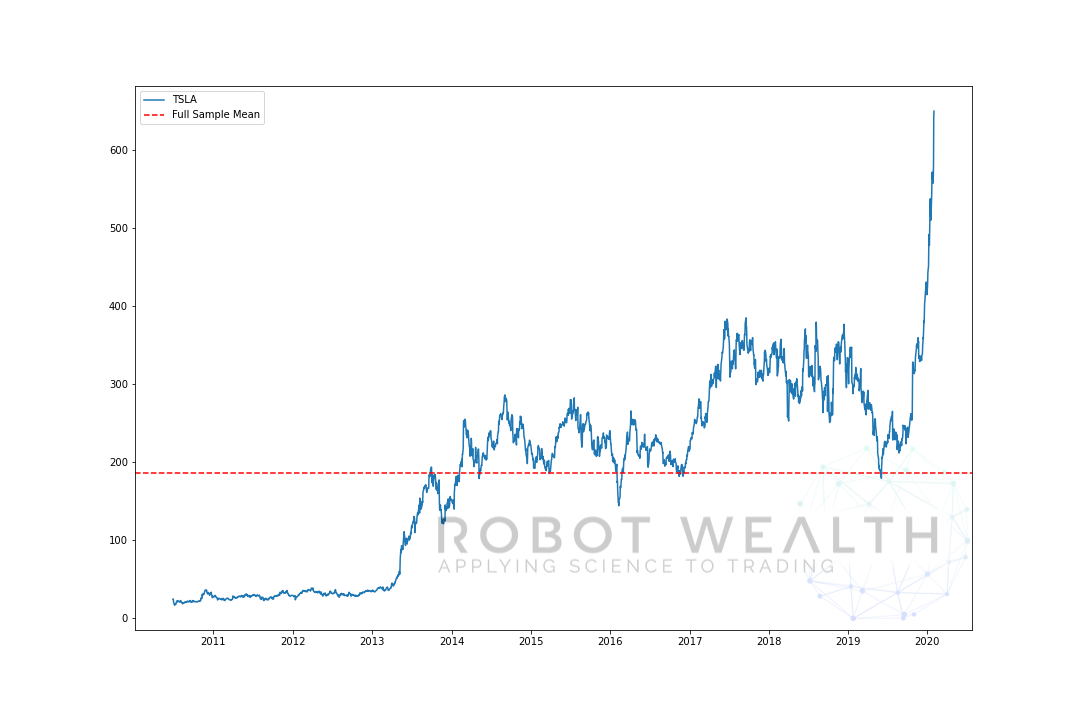
zde je extrémní příklad. Zde jsme vynesli cenu TSLA a její průměr v celém vzorku.
import pandas as pdimport matplotlib.pyplot as plt #Load TSLA OHLC df = pd.read_csv('TSLA.csv')#Calculate full sample meanfull_sample_mean = df.mean()#Plotplt.plot(df,label='TSLA')plt.axhline(full_sample_mean,linestyle='--',color='red',label='Full Sample Mean')plt.legend()plt.show()
V tomto případě, pokud jsme právě koupili TSLA když cena byla pod tím a Prodal to nad tím by jsme se zabíjení, no, alespoň až do roku 2019…
Ale problém je, že jsme nevěděli, že střední hodnota v tomto bodě v čase.
je tedy zřejmé, proč nemůžeme použít celý vzorek,ale co můžeme dělat? Jedním ze způsobů, jak bychom k tomuto problému mohli přistupovat, je použití válcování nebo rozšiřování oken.
Pokud jste někdy použili jednoduchý klouzavý průměr, Gratulujeme-použili jste rolovací okno.
jak fungují rolovací okna?
řekněme, že máte 20 dní skladových dat a chcete znát průměrnou cenu akcií za posledních 5 dní. Co děláš?
vezmete posledních 5 dní, sečtete je a vydělíte 5.
ale co když chcete znát průměr předchozích 5 dnů za každý den ve vaší datové sadě?
zde mohou rolovací okna pomoci.
v tomto případě by naše okno mělo velikost 5, což znamená, že pro každý časový bod obsahuje průměr posledních 5 datových bodů.
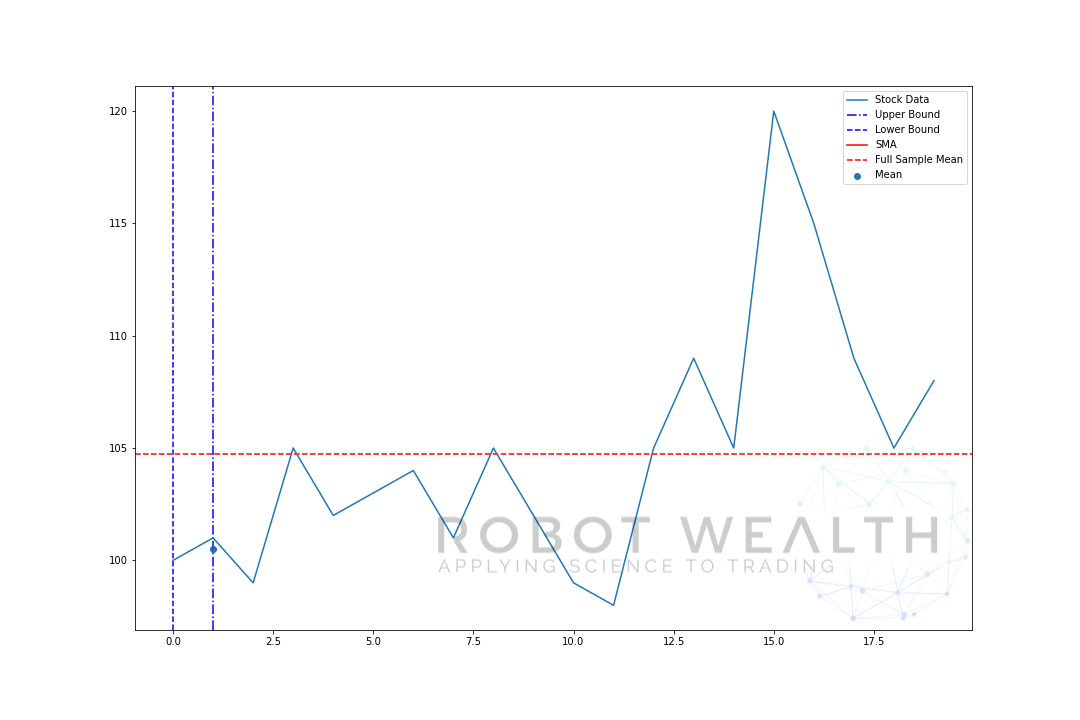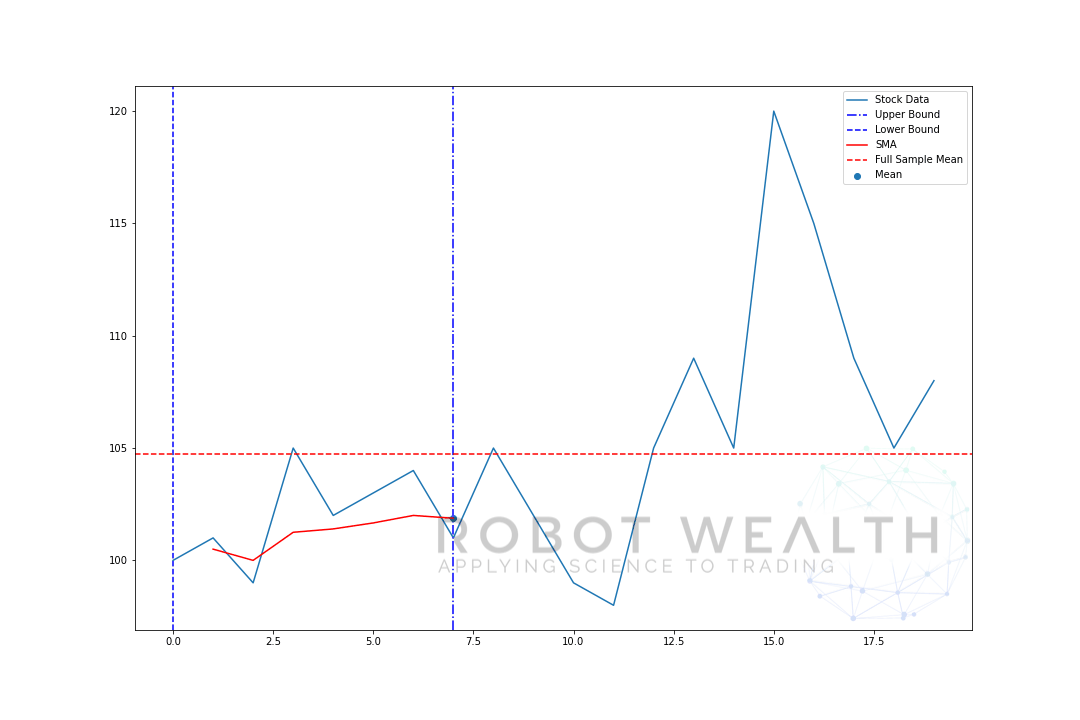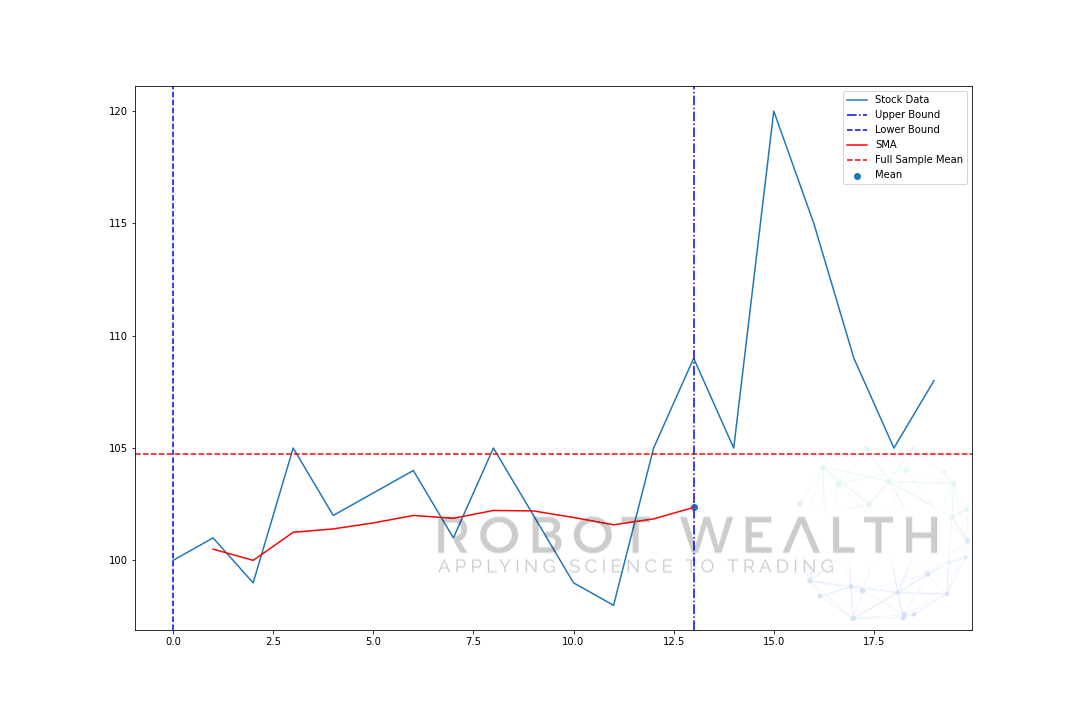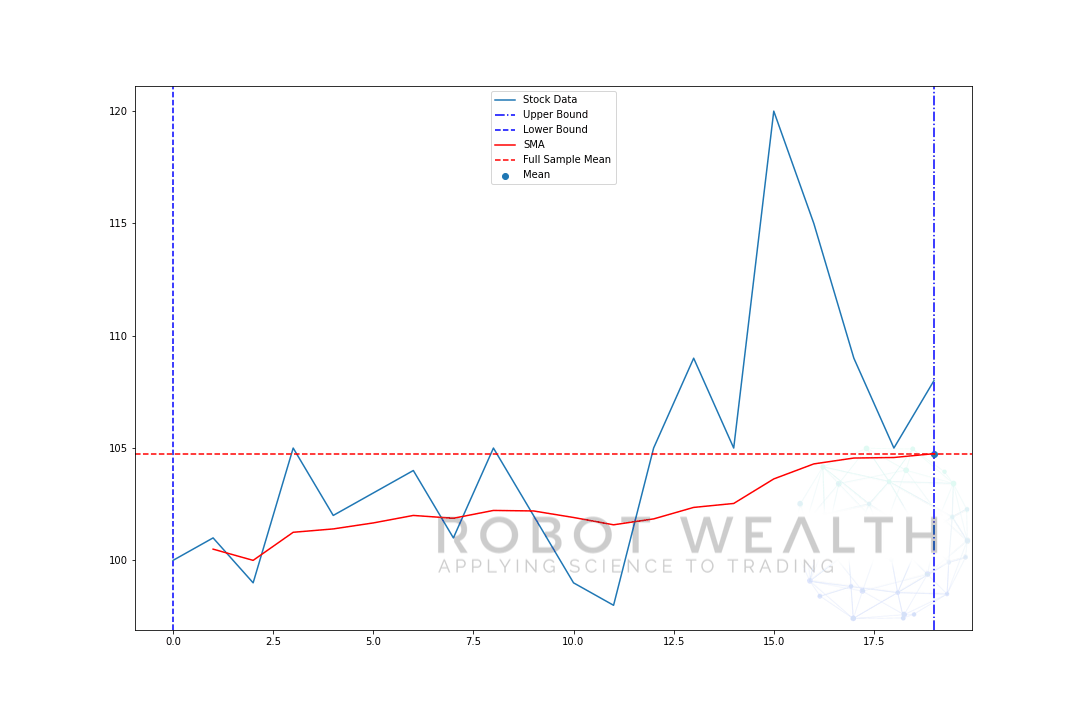
představme si příklad s pohyblivým oknem velikosti 5 krok za krokem.
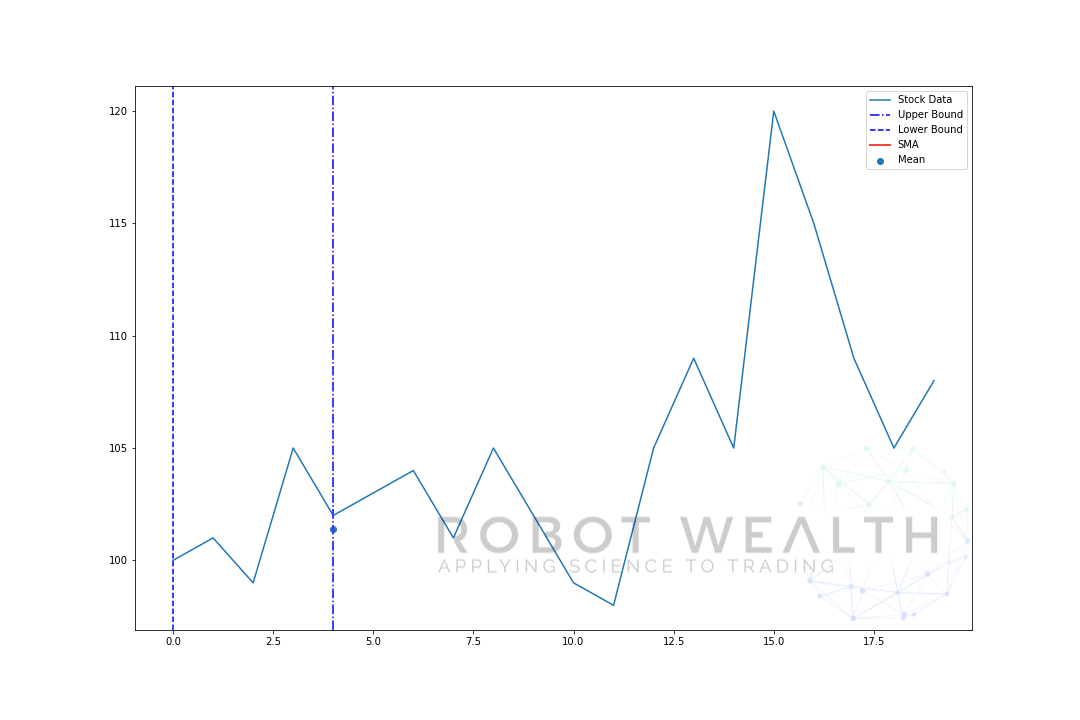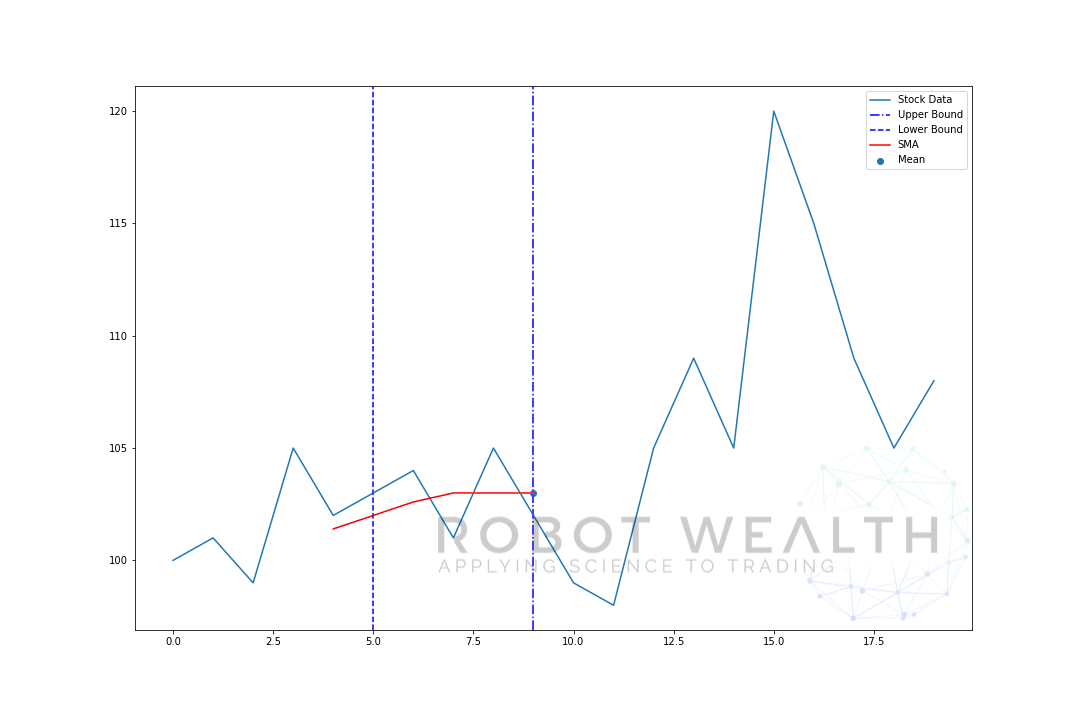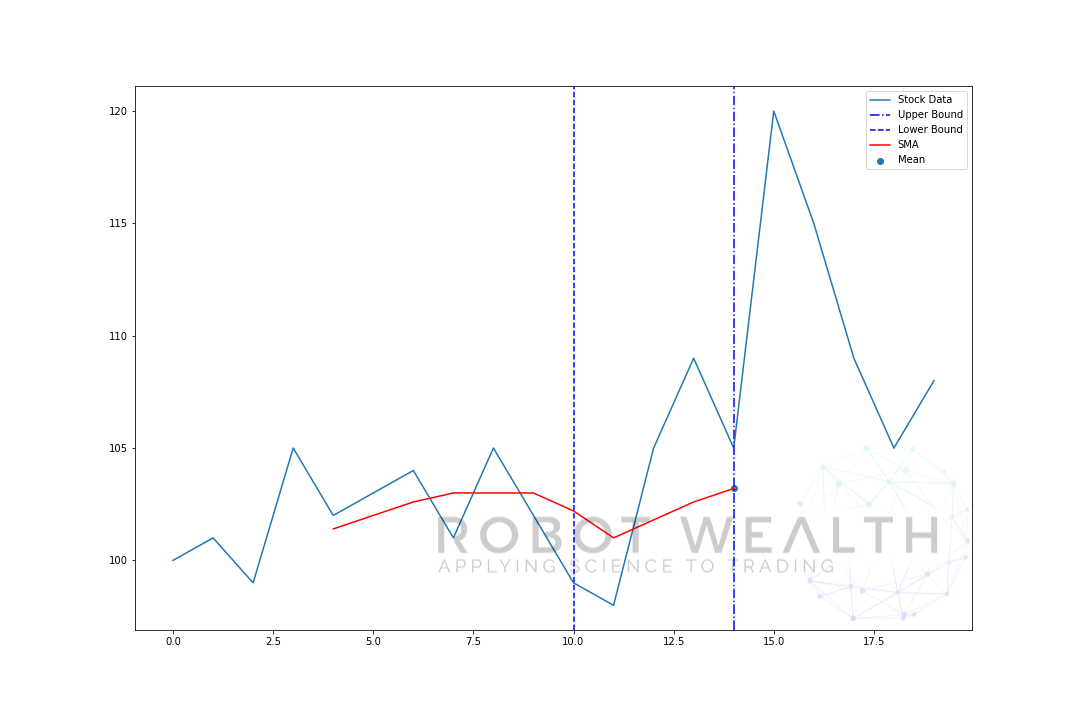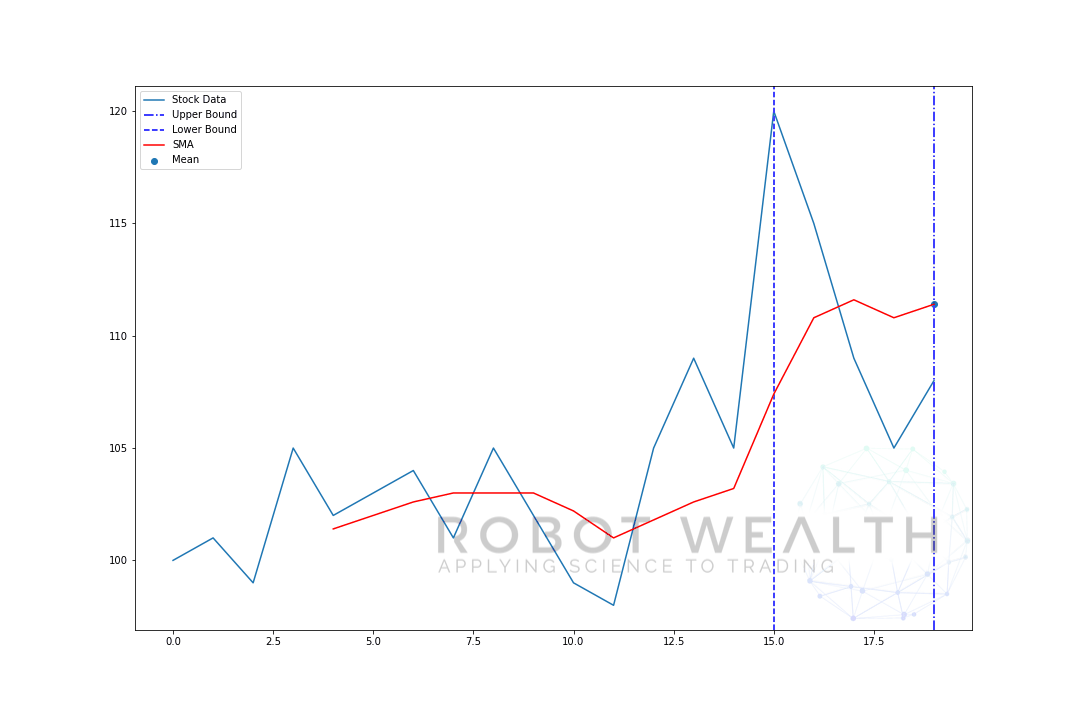
#Random stock pricesdata = #Create pandas DataFrame from listdf = pd.DataFrame(data,columns=)#Calculate a 5 period simple moving averagesma5 = df.rolling(window=5).mean()#Plotplt.plot(df,label='Stock Data')plt.plot(sma5,label='SMA',color='red')plt.legend()plt.show()
pojďme tedy rozdělit tento graf.
- v tomto grafu máme 20 dní cen akcií, označené skladové údaje.
- pro každý bod v čase (modrá tečka) chceme vědět, co je 5 denní průměrná cena.
- skladová data použitá pro výpočet jsou věci mezi 2 modrými svislými čarami.
- Po výpočtu průměru od 0-5 bude k dispozici náš průměr pro den 5.
- abychom získali průměr pro den 6, musíme posunout okno o 1, takže datové okno se stane 1-6.
a to je to, co je známé jako rolovací okno, velikost okna je pevná. Vše, co děláme, je, že to posouváme dopředu.
jak jste si pravděpodobně všimli, nemáme hodnoty SMA pro body 0-4. Je to proto, že naše velikost okna (známá také jako doba zpětného pohledu) vyžaduje pro výpočet alespoň 5 datových bodů.
rozšíření oken
kde jsou okna s pevnou velikostí, rozšíření oken má pevný výchozí bod a začleňuje nová data, jakmile budou k dispozici.
zde je způsob, jakým o tom přemýšlím:
“ jaký je průměr minulých hodnot n v tomto okamžiku?“- Zde použijte rolovací okna.
“ jaký je průměr všech dostupných dat až do tohoto okamžiku?“- Zde použijte rozšiřující se okna.
rozšiřující okna mají pevnou dolní hranici. Pouze horní okraj okna je posunut dopředu (okno se zvětší).
pojďme si představit rozšiřující se okno se stejnými daty z předchozího grafu.
#Random stock prices data = #Create pandas DataFrame from list df = pd.DataFrame(data,columns=) #Calculate expanding window meanexpanding_mean = df.expanding(min_periods=1).mean()#Calculate full sample mean for referencefull_sample_mean = df.mean()#Plot plt.plot(df,label='Stock Data') plt.plot(expanding_mean,label='Expanding Mean',color='red')plt.axhline(full_sample_mean,label='Full Sample Mean',linestyle='--',color='red')plt.legend()plt.show()
můžete vidět, že na začátku, SMA je trochu nervózní. To proto, že máme menší počet datových bodů na začátku pozemku, a jak jsme získat více dat, okno se rozšíří, až nakonec rozšiřují okna na mysli konverguje k plné výběrový průměr, protože okno dosáhla velikost celé datové sady.
shrnutí
je důležité nepoužívat data z budoucnosti k analýze minulosti. Válcování a rozšiřování oken jsou základními nástroji, které pomáhají „procházet vaše data vpřed“, aby se těmto problémům zabránilo.
Pokud se vám líbí tento, budete pravděpodobně jako ty taky…
Finanční Manipulaci s Daty v dplyr Quant Obchodníci
Pomocí Digitálního Zpracování Signálu v Kvantitativní Obchodní Strategie,
Backtesting Zkreslení: Cítí se Dobře, Dokud Tě Vyhodit,