
Strojové učení je nakonec použit k předpovědět výsledky vzhledem k tomu, sadu funkcí. Proto vše, co můžeme udělat pro zobecnění výkonu našeho modelu, je považováno za čistý zisk. Výpadek je technika používaná k zabránění nadměrnému vybavení modelu. Výpadek funguje náhodně nastavením odchozích okrajů skrytých jednotek (neuronů, které tvoří skryté vrstvy) na 0 při každé aktualizaci tréninkové fáze. Pokud jste se podívat na Keras dokumentace pro vypuštění vrstvy, uvidíte odkaz na bílý papír napsal Geoffrey Hinton a přátele, které jde do teorie za odpadlíka.
V řízení příklad, budeme používat Keras budovat neuronové sítě s cílem rozpoznávání ručně psaných číslic.
from keras.datasets import mnist
from matplotlib import pyplot as plt
plt.style.use('dark_background')
from keras.models import Sequential
from keras.layers import Dense, Flatten, Activation, Dropout
from keras.utils import normalize, to_categorical
používáme Keras importovat data do našeho programu. Data jsou již rozdělena do tréninkových a testovacích sad.
(X_train, y_train), (X_test, y_test) = mnist.load_data()
pojďme se podívat, s čím pracujeme.
plt.imshow(x_train, cmap = plt.cm.binary)
plt.show()
po dokončení výcviku modelu by měl být schopen rozpoznat předchozí obrázek jako pět.
existuje malé předzpracování, které musíme provést předem. Pixely (funkce) normalizujeme tak, aby se pohybovaly od 0 do 1. To umožní modelu konvergovat k tak rychlejšímu řešení. Dále transformujeme každý z cílových štítků pro daný vzorek na pole 1s a 0s, kde index čísla 1 označuje číslici, kterou obrázek představuje. Děláme to proto, že jinak by náš model interpretoval číslici 9 jako vyšší prioritu než číslo 3.
X_train = normalize(X_train, axis=1)
X_test = normalize(X_test, axis=1)
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
Bez Vypuštění
Před krmením 2 dimenzionální matice do neuronové sítě, používáme zploštit vrstvy, které transformuje do 1 rozměrné pole přidáním každé další řadě, aby ten, který mu předcházel. Použijeme dvě skryté vrstvy, které se skládají ze 128 neuronů a výstupní vrstvu sestávající z 10 neuronů, každý pro jednu z 10 možných číslic. Funkce aktivace softmax Vrátí pravděpodobnost, že vzorek představuje danou číslici.

když se snažíme předvídat tříd, používáme kategorické crossentropy jako naše ztráta funkce. Výkon modelu změříme pomocí přesnosti.
model.compile(
loss='categorical_crossentropy',
optimizer='adam',
metrics=
)
10% dat jsme vyčlenili pro ověření. Použijeme to k porovnání tendence modelu k overfit s a bez výpadku. Šarže velikost 32 znamená, že budeme vypočítat gradient a udělat krok ve směru gradientu o síle rovnající se rychlost učení, poté, co projdou 32 vzorků prostřednictvím neuronové sítě. Děláme to celkem 10krát, jak je stanoveno počtem epoch.
history = model.fit(
X_train,
y_train,
epochs=10,
batch_size=32,
validation_split=0.1,
verbose = 1,
shuffle=True
)
můžeme si plánovat školení a ověření přesnosti v každé epoše pomocí historie proměnné vrácené fit funkce.
jak vidíte, bez výpadku se ztráta ověření zastaví po třetí epoše.

As you can see, without dropout, the validation accuracy tends to plateau around the third epoch.

Using this simple model, we still managed to obtain an accuracy of over 97%.
test_loss, test_acc = model.evaluate(X_test, y_test)
test_acc
Vypuštění
Tam je nějaká debata jak k zda vypuštění by měl být umístěn před nebo po aktivaci funkce. Zpravidla umístěte výpadek po aktivační funkci pro všechny aktivační funkce jiné než relu. Při průchodu 0,5 je každá skrytá jednotka (neuron) nastavena na 0 s pravděpodobností 0,5. Jinými slovy, je 50% změna, že výstup daného neuronu bude vynucen na 0.

Znovu, protože jsme se snaží předpovědět, tříd, používáme kategorické crossentropy jako naše ztráta funkce.
model_dropout.compile(
loss='categorical_crossentropy',
optimizer='adam',
metrics=
)
Tím, že poskytují ověření rozdělení parametr, model se odlišuje zlomek tréninková data a vyhodnotí ztrátu a každý model metrik na tato data na konci každé epochy. Pokud předpoklad za vypuštění drží, pak bychom měli vidět velký rozdíl v ověření přesnosti ve srovnání s předchozím modelem. Parametr shuffle zamíchá tréninková data před každou epochou.
history_dropout = model_dropout.fit(
X_train,
y_train,
epochs=10,
batch_size=32,
validation_split=0.1,
verbose = 1,
shuffle=True
)

Jak můžete vidět, validace ztráta je výrazně nižší než hodnota získaná pomocí běžného modelu.

Jak můžete vidět, model konvergované mnohem rychleji a získat přesností téměř 98% na ověření nastavit, vzhledem k tomu, že předchozí model plateau kolem třetí epochy.

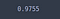
Přesnost získané u zkoušky není moc jiný, než ten, získaný z modelu bez vypuštění. To je s největší pravděpodobností způsobeno omezeným počtem vzorků.
test_loss, test_acc = model_dropout.evaluate(X_test, y_test)
test_acc

závěr
Vypuštění může pomoci model zobecnit tím, že náhodně nastavení výstupu pro daný neuron 0. Při nastavení výstupu na 0 se funkce nákladů stává citlivější na sousední neurony, které mění způsob, jakým budou váhy aktualizovány během procesu backpropagace.