tämän artikkelin tarkoituksena on selittää redundanssia tietojenkäsittelyn, verkostoitumisen ja Hostingin suhteen. Tarjoamme reaalimaailman esimerkkejä tarpeettomista teknologiaratkaisuista havainnollistaaksemme, mitä irtisanominen on ja miten se toimii.
Atlantic.Net on luonut useita hosting-ympäristöjä, mukaan lukien kestävä pilvialusta, nopea VPS hosting, HIPAA-yhteensopiva infrastruktuuri ja hallittu yksityinen pilvihostaus. Kaikki järjestelmämme on rakennettu redundanssilla suunnitteluprosessin ensisijaisena liikkeellepanevana tekijänä.
arkienglannissa redundanssilla voi olla negatiivinen konnotaatio; jotain turhaa ei yleensä tarvita tai sitä pidetään tarpeettomana. Pilvipalveluympäristössä redundanssi voi kuitenkin tarkoittaa saumattoman järjestelmän käytettävyyden ja ei-toivottujen tai odottamattomien seisokkien välistä eroa.
- mikä on tarpeeton järjestelmä?
- päällekkäisten järjestelmien tyypit
- esimerkkejä tarpeettomista ohjelmistopalveluista
- Hyper-V Replica
- Hyper-V-ryhmittely
- Haproksi
- Heartbeat
- esimerkkejä tarpeettomista Laitteistopalveluista
- RAID
- Networking Redundancy
- First Hop Redundancy Protocols (Fhrp)
- Virtual Router Redundancy Protocol (VRRP)
- Hot Standby Router Protocol (HSRP)
- Gateway Load Balancing Protocol (GLBP)
- datakeskusten redundanssi
- johtopäätös
mikä on tarpeeton järjestelmä?
tarpeeton järjestelmä tarjoaa vikaantumis-tai kuormitustasaustuen, joka suojaa elävää järjestelmää odottamattoman vian sattuessa. Jos kyseessä on teho, mekaaninen, tai ohjelmisto vika, tarpeeton järjestelmä on kaksinkertainen komponentti tai Alustan turvautua. Yleensä mikä tahansa järjestelmän osa, jossa on yksi vikapaikka, voidaan nähdä riskinä tuotantopalveluille.
sähkö-tai mekaanisissa järjestelmissä on yksinkertaisemmat varastrategiat, jotka edellyttävät pelkästään toisen samantyyppisen palvelun läsnäoloa; ohjelmistojen vikaantuminen edellyttää yleensä ylimääräistä konfigurointia isäntäjärjestelmässä tai pää-tai yhdyskäytävässä.
Redundanssiominaisuuksia suositellaan mille tahansa liiketoiminnan kannalta kriittiselle järjestelmälle, mutta erityisesti järjestelmille, joilla on merkittävä vaikutus seisokin aikana. Jotkut yritykset voivat pitää kaikki kriittiset asiakastietonsa tietokannassa; siksi liiketoiminnan jatkuvuuden vuoksi kyseisen tietokannan suojaaminen irtisanomisella suojaa tietojen eheyttä katastrofaalisen vian sattuessa.
päällekkäisten järjestelmien tyypit
tarpeeton järjestelmä koostuu vähintään kahdesta järjestelmästä, jotka on yhdistetty toisiinsa ja suunniteltu samaan tarkoitukseen. On olemassa monia erilaisia tarpeettomia järjestelmän kokoonpanot käytettävissä,ja eri toteutukset järjestelmän tarjoavat ainutlaatuisia lähestymistapoja, miten pitää järjestelmän koko ajan.
kaikkia palvelimia ei tarvitse konfiguroida redundanssilla, vaan vain kriittisimmät tulisi ottaa huomioon. Suosittelemme yksityiskohtaista riskinarviointia, jotta ymmärtäisimme, mitkä palvelimet ovat laajuudeltaan ja kuinka paljon palvelimet voivat käyttää seisokkeja. Käytä tätä arviointia RTO: n (palautumisajan tavoite) ja RPO: n (Palautumispisteen tavoite) strategian määrittämiseen. RTO on suurin hyväksyttävä seisokkeja. Tämä voi vaihdella 5 sekunnista 24 tuntiin. RPO on ajankohta, josta lähtien tarvitset tietojasi; esimerkiksi yrityksesi voi toimia enintään 24 tunnin tietojen menettämisellä.
Tässä muutamia suosittuja esimerkkejä:
- Aktiivinen-inaktiivinen / kuuma-kylmä – kun yksi järjestelmän osa on aktiivinen ja toinen on inaktiivinen tai sammutettu. Inaktiivinen komponentti aktivoituu vain, kun käynnissä oleva komponentti ei toimi tai sitä huolletaan
- Active-Active/Hot-Hot – kun molemmat järjestelmät ovat toiminnassa ja muodostavat yhteyksiä. Tätä kutsutaan yleisimmin ryhmittelyksi. Yleensä molempien koneiden edessä oleva laite määrittää, miten saapuva liikenne jaetaan
- Active-Standby / Hot-Warm – kun molemmat järjestelmät ovat päällä, mutta vain toinen tekee yhteyksiä. Toisen järjestelmän on tarkoitus vastaanottaa säännöllisesti päivityksiä tai varmuuskopioita ensisijaisesta järjestelmästä. Vikatilanteessa valmiustilassa oleva järjestelmä on pääroolissa, kunnes alkuperäinen järjestelmä saadaan palautettua.
jokaisella tyypillä on omat hyvät ja huonot puolensa.
- Active-inaktiivinen / kuuma-kylmä-järjestelmät voivat tarjota yksinkertaisen ylimääräisen Alustan, mutta mahdollinen vikaantuminen johtaa siihen, että käyttäjät näkevät järjestelmän vanhemman version.
- Active-Active / Hot-Hot vaatii molempien järjestelmien jatkuvaa päivittämistä joko manuaalisesti tai erillisen palvelun kautta, jotta kaikki käyttäjät voivat käyttää jompaakumpaa järjestelmää. Tämä lähestymistapa voi merkittävästi vähentää aktiivista kuormitusta palvelun tarjoat asiakkaille.
- Active-Standby / Hot-Warm tarjoaa hot-cold-järjestelmän vikaantumisominaisuuksiin ajantasaisemman kopion aktiivisesta järjestelmästäsi vikaantumisvaiheessa, mutta se ei helpota kuormitusta.
muitakin monen solmun redundanssin muotoja on saatavilla, jotka mahdollistavat suuremman redundanssin ja kestävät kuormituksen tasapainotusratkaisut. Siinä vaiheessa, sinulla on korkean käytettävyyden klusteri, joka tunnetaan myös nimellä HA klusteri.
tässä voidaan käyttää mitä tahansa aiemmin todettujen redundanssiratkaisujen yhdistelmää, jossa tarvittava lähestymistapa tai määrä on mahdollisimman joustava. HA klustereita voidaan myös perustaa useisiin fyysisiin paikkoihin, jotta saatavuus Internetin runkoverkkotasolle asti on mahdollista.
esimerkkejä tarpeettomista ohjelmistopalveluista
resurssien vähäisen saatavuuden vuoksi ei ole juurikaan syytä olla rakentamatta omaa toisintoa tai turhia palveluja virtuaaliympäristössä; näin ollen monet tällaiset palvelut ovat oletusarvoisesti saatavilla useimmissa virtualisointijärjestelmissä. Kaikissa pilvipalveluissamme on saatavilla replikaatio, ominaisuus, jonka avulla voimme kopioida minkä tahansa palvelimen solmusta toiseen, olivatpa ne samassa datakeskuksessa tai erillisillä datakeskusalueilla.
Hyper-V Replica
Hyper-V Replica on kuuman lämpimän redundanssin muoto. Ensisijainen virtuaalikone luodaan yhdellä fyysisellä isännällä ja hyväksyy saapuvat yhteydet. Kun replikointi otetaan käyttöön, uuden koneen virtuaaliset kiintolevyt siirretään erilliseen fyysiseen Hyper-V-isäntään. Tämä isäntä määrittää sitten itselleen VM: n, joka toistuu käyttäjän määrittelemässä aikataulussa varmistaakseen, että aktiivipalvelimen viimeisin kuva otetaan. Myös muita tarkastuspisteitä voidaan pitää. Hyper – V private hosting with managed services tarjoaa Atlantic.Net tämän ominaisuuden leivotaan; ota yhteyttä tiimiimme lisätietoja.
Hyper-V-ryhmittely
Hyper-V pystyy myös ryhmittymään yhteyden kautta muihin Hyper-V-isäntiin. VMs tahansa Hyper-V isäntä voidaan ryhmittyä yhteen, että yksikössä isäntä tarjota redundanssia paikallistasolla virtuaalisen verkottumisen.
Microsoft Network Load Balancing (NLB) – toiminnon avulla voidaan luoda yksi resurssi, joka koostuu useista saman tiedon jakavista isännistä, jotta tiedostojen jakamiseen voidaan käyttää yksinkertaista käyttöpistettä. Koska tämä on rajattu vain käytettävissä olevien resurssien määrällä, voit teoriassa perustaa useita isäntiä, joilla on useita VMs-järjestelmiä maksimaaliseen redundanssiin, mikä mahdollistaisi myös yksittäisten VMS-järjestelmien ylläpidon uhraamatta palvelua tai resurssien saatavuutta. Hyper – V private hosting with managed services tarjoaa Atlantic.Net tämän ominaisuuden leivotaan; ota yhteyttä tiimiimme lisätietoja.
Haproksi
Hyper-V: n lisäksi porttilaitetta, kuten palomuuria, voidaan käyttää vikaantumis-tai kuormantasauspalveluihin. Esimerkiksi Atlantic.Net voi tarjota Pfsenselle korkean saatavuuden välityspalvelimen, joka tunnetaan myös nimellä HAProxy.
HAProxy toimii kuormituksen tasapainottajana, välityspalvelimena tai yksinkertaisena lämpimän lämpimän korkean käytettävyyden ratkaisuna TCP-ja HTTP-pohjaisille sovelluksille. HAProxy on erittäin suosittu, Linux-pohjainen avoimen lähdekoodin ratkaisu, jota jotkut maailman vierailluimmista sivustoista käyttävät.
Heartbeat
Heartbeat on useimmissa Linuxin jakeluissa saatavilla oleva palvelu, jonka avulla voidaan määrittää, ovatko klusterin solmut edelleen pystyssä vai responsiivisia. Se on hyvin yksinkertainen perustaa ja tarjoaa vikasietokykyä tahansa järjestelmän yli TCP.
Heartbeatin kehittäjät suosittelevat myös muita klusteriresurssien hoitajia, jotka käynnistävät tai lopettavat palvelut sen perusteella, onko tietty isäntä alhaalla. Heartbeat on mukana tässä, mutta muitakin managereita on tarjolla. Heartbeatin yksinkertaisuuden vuoksi se on hyvin muokattavissa. Pilvi Hosting-alustat, jotka tarjoaa Atlantic.Net tämä ominaisuus on jo leivottu, ja voimme auttaa Sinua toteuttamaan syke oman yksityisen Linux-jakelu, jos tarpeen.
esimerkkejä tarpeettomista Laitteistopalveluista
parasta tarpeettomassa laitteistossa on sen yksinkertaisuus. Vaikka ohjelmistopalvelut saattavat vaatia liiallista konfigurointia ja ovat mahdollisesti melko herkkiä, laitteisto on yleensä hyvin yksinkertainen asentaa ja uskomattoman kestävä. Ensimmäinen esimerkki tarkastelemme on laajalti käytetty RAID-tekniikka.
RAID
RAID tulee sanoista Redundant Array of Independent Disks (or Redundant Array of edullisia Diskettejä riippuen siitä, kuinka kauan olet käyttänyt sitä) ja siinä on useita tasoja, joita käytetään joko tietosuojaan tai korotettuun levyyn I/O.
RAID voidaan perustaa joko ohjelmiston tai laiteohjaimen kautta. Ohjaimessa on ohjelmisto ja kokoonpano, jota tarvitaan RAID-levyjen hallintaan. Kokoonpano voidaan viedä eri järjestelmiin vain vähän tai ei mitään lisäasetukset.
RAID voidaan perustaa muutamalla eri tavalla, jotta sen molemmat ominaisuudet olisivat hyvässä tasapainossa:
- RAID 0 – tämä ei periaatteessa ole redundanssia. Mikään järjestelmässä oleva levy ei jaa tietoja peilauksen kautta, mutta kaikki tiedot on raidoitettu jokaisen levyn yli, mikä lisää luku – /kirjoitusnopeutta. Jokainen asema voi silti käyttää tallennustilaa sen täysillä, eli enemmän asemia lisäät RAID 0 enemmän tilaa sinulla on.
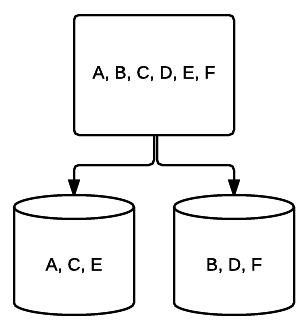
- RAID 1 – peilauksen perusmuoto, joka tarjoaa erinomaisen redundanssin tilan kustannuksella. Kaksimoottorisessa järjestelmässä toisen aseman tiedoista kirjoitetaan täydellinen kopio toiselle. Tämä redundanssi paranee jokaisen aseman lisäämisen myötä. Koska kaikki tiedot on peilattava kaikkiin asemiin, kokonaistila järjestelmässä rajoittuu vain järjestelmän pienimmän aseman tilaan.
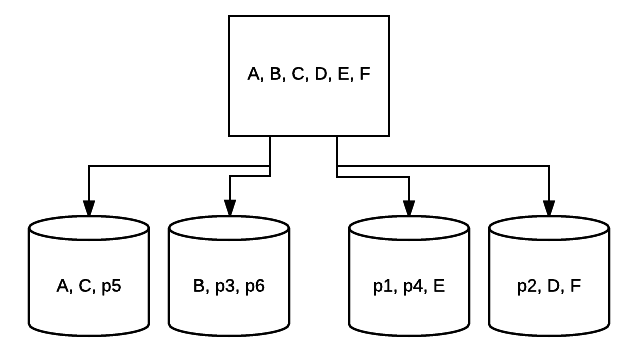
- RAID 5 – tätä Raidin muotoa käytetään yleensä lukunopeuden ja luotettavuuden lisäämiseksi. Tässä tapauksessa raidat on sijoitettu noin kunkin aseman järjestelmään, jossa vähintään on 3 asemaa. Samalla jokaiseen asemaan sijoitetaan ylimääräinen virheenkorjausdata pariteetti-nimisellä tekniikalla. Tämä tarkistaa, muuttuvatko tiedot siirrettäessä asemalta toiselle. Tämä tarjoaa myös minimaalisen redundanssin, koska 1 näistä asemista voi epäonnistua ja järjestelmä voi silti toimia. Mitä enemmän asemia lisätään tämäntyyppiseen RAID-asetukseen, sitä enemmän lukunopeus kasvaa. Pienin irtisanominen ja raidoitus kaikissa asemissa, kokonaismäärä tilaa tässä asetuksessa on yhtä suuri kuin koko loogisen RAID tilavuus kertaa määrä asemia käytät, miinus yksi. Esimerkiksi, jos sinulla on 5 500 GB ajaa RAID 5, sinulla olisi 2000 GB käytettävissä, tai 2 TB (500 *(5-1)=2000).
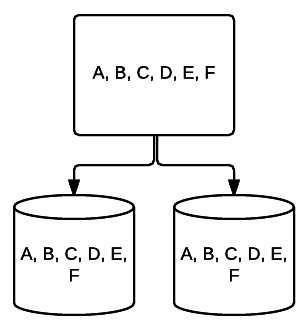
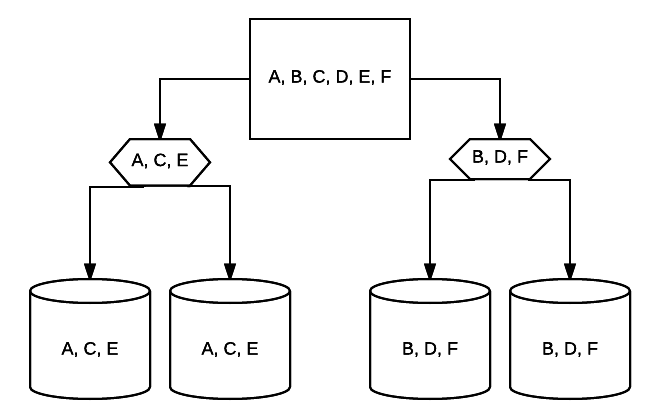
- RAID 10 – Tämä on yhdistelmä RAID 1: stä ja RAID 0: sta. Tässä tapauksessa, kaikki tiedot on raidallinen kunkin laitteen kanssa lohkojen tiedot myös peilataan koko raidallinen järjestelmä. Esimerkiksi 4 drive RAID 10-järjestelmässä 2 500 GB-asemilla voi olla samat tiedot, mutta ei kaikkia tietoja, joita järjestelmä tarvitsee toimiakseen kunnolla. 2 muiden asemien tietoja tarvittaisiin. Ajattele jokainen RAID 1 järjestelmä yhtenä asema, ja jokainen näistä järjestelmistä sijoitettu RAID 0 array. Tässä setup, suorituskykyä voidaan merkittävästi lisätä kuten RAID 0, joidenkin redundanssi vielä paikallaan peilaus. Jopa puolet järjestelmän asemista voi epäonnistua ennen järjestelmän kaatumista, mutta kuten minkä tahansa ylimääräisen järjestelmän kanssa, on parasta vaihtaa asemat mahdollisimman pian. Atlantic.Net käyttää RAID 10 kaikille SSD pilvi VPS varastointi.
lisäsuojauksen vuoksi RAID-ohjaimet on suojattu akun varayksiköillä, jotka käyttävät konfiguraation tallentamiseen käytettäviä ROM-siruja muistiin sähkökatkoksen sattuessa jne. BBU antaa virtaa RAID array, joka on osa sammutettu järjestelmä pienen aikaa, jolloin sisältö RAID-ohjaimen välimuistin pysyä ennallaan. Tämä voi olla hengenpelastaja, jos tietoja syötetään jatkuvasti RAID array ja seisokit voivat aiheuttaa tietojen korruptiota.
niin fyysinen järjestelmä ja palvelut sisällä voidaan rakentaa redundantly melko riittävästi. Entä yhteytesi johonkin järjestelmäsi osaan? Siis suora internet-yhteys koko järjestelmään?
Networking Redundancy
First Hop Redundancy Protocols (Fhrp)
toisin kuin dynaamiset gateway discovery protocols, staattiset yhdyskäytävät mahdollistavat suoraviivaisen humalan asiakkaan ja sen sopivan yhdyskäytävän välillä, mutta tämä luo yhden vikapaikan – nimittäin yhdyskäytävän itsensä.
yhdyskäytävävikojen vaikutusten ehkäisemiseksi tai vähentämiseksi luotiin Fhrp-järjestelmät. Ne tarjoavat tarpeettomat yhdyskäytävät varasuunnitelmaksi tai tarjoavat kuormantasausta korkeille liikennejärjestelmille yhdessä irtisanomisten kanssa. Näitä protokollia ovat VRRP, HSRP ja GLBP.
Virtual Router Redundancy Protocol (VRRP)
VRRP on reitittimille käytettävä redundanssin muoto, joka vaatii vähintään kaksi fyysisesti erillistä reititintä, jotka on kytketty joko Ethernet-tai valokuituyhteyksillä. Tässä tilanteessa luodaan ”virtuaalinen reititin”, joka sisältää staattisia reittejä ja jaetaan kunkin järjestelmän kesken.
yhtä järjestelmää pidetään ”päällikkönä” ja toista ”varajärjestelmänä”. Kun mestari epäonnistuu, taustajoukko siirtyy seuraavaksi mestariksi. Tämä voidaan perustaa useita varmuuskopioita ylimääräisiä irtisanomisia. Konsepti on siinä mielessä hyvin samankaltainen kuin Heartbeat, että varajärjestelmät tarkistavat, onko master käytettävissä. Kun se ei saa vastausta, ennalta määrätyn ajan kuluttua varmuuskopiointi ottaa hallintaansa virtuaalisen kytkimen ja hyväksyy yhteydet kaikkiin pyyntöihin, jotka tulevat pääkytkimelle määritetylle oletetulle IP: lle.
Hot Standby Router Protocol (HSRP)
HSRP on kuin VRRP; kuitenkin, tässä skenaariossa, määritetty virtuaalinen kytkin ei ole ”kytkin”, vaan looginen ryhmä useita reitittimiä. Ryhmän IP on IP, jota ei ole määritetty fyysiselle isännälle. Sen sijaan ryhmälle annetaan IP ja yksi reitittimistä määritetään ”aktiiviseksi” reitittimeksi.
valmiustilareititin on valmis ottamaan kaikki yhteydet, jos aktiivinen reititin menee nurin. Kaikki reitittimet active ja valmiustilassa kaikki kuuntelevat määrittää sen paikka jonossa. HSRP on Ciscon oma protokolla ja sillä on hyvin vähän pieniä eroja VRRP: hen, kuten niiden oletusajat, jotka määrittävät, milloin vikaantua. HSRP on ollut olemassa hieman pidempään ja se on tunnetumpi verrattuna VRRP: hen.
Gateway Load Balancing Protocol (GLBP)
GLBP: n tärkein etu HSRP: hen ja VRRP: hen nähden on sen kyky ladata tasapaino sen lisäksi, että se tarjoaa redundanssin yhdyskäytävälle, jossa on vähän tai ei lainkaan ylimääräistä konfiguraatiota. Aivan kuten HSRP ja VRRP, GLBP luo ryhmän fyysisten reitittimien väliin ja määrittää aktiivisen virtuaalisen yhdyskäytävän eli AVG: n.
virtuaalinen IP, jota mikään ryhmän reitittimistä ei tällä hetkellä käytä, on määritetty AVG: lle. Tämän jälkeen AVG jakaa virtuaalisia MAC-osoitteita ryhmän muiden reitittimien kesken. Jokainen varmuuskopio reititin pidetään nyt aktiivinen virtuaalinen Kuormatraktori, tai AVF.
AVG: lle lähetetyt ARP-pyynnöt antavat pyynnön lähettäneelle asiakkaalle erilaisen virtuaalisen MAC-osoitteen. Tällöin kyseisen asiakkaan ja ryhmän virtuaalisen IP: n välinen liikenne siirtyy reitittimelle, jonka virtuaalisen MAC-osoitteen he saivat, jolloin jokaista reititintä voidaan edelleen käyttää sen sijaan, että se istuisi toimettomana vieressä.
AVG: n epäonnistuessa tapahtuu prioriteettipohjainen vaali, kuten HSRP: ssä ja VRRP: ssä, ja sen tilalle tulee seuraava varmuuskopio, joka jakaa virtuaalisia MAC-osoitteita normaalisti. Muut reitittimet säilyttävät edelleen alkuperäisen AVG: n tarjoaman virtuaalisen MAC-osoitteen ja asiat jatkuvat normaalisti. Jos jokin AVFs epäonnistuu, AVG estää liikenteen reitityksen virtuaaliseen MAC-osoitteeseensa.
kuten HSRP, GLBP on Fhrp: n Ciscon omistama muoto.
datakeskusten redundanssi
henkilökohtaisten palvelimien tai reitittimien redundanssitoimenpiteiden lisäksi datakeskukset on suunniteltu kestämään järjestelmävika. Datakeskukset kuuluvat Uptime Instituten määrittelemien tasojen alaisuuteen, jotta mekaanisen tai palveluvian vikaantumiseen saadaan viansietokyky, mikä mahdollistaa mahdollisimman paljon käytettävyyttä.
on neljä tasotasoa, jotka kukin rakentuvat toistensa varaan tarjotakseen korkean käytettävyyden kaikille datakeskuksen asiakkaille:
- Tier I – peruskapasiteetti: Tämä vaatii tilaa it-ryhmälle datakeskuksen toimintaa varten, keskeytymättömän virransyötön (ups), joka valvoo ja suodattaa virrankulutusta, sekä omat jäähdytyslaitteet, jotka ovat jatkuvasti käynnissä 24/7. Tähän sisältyy myös sähkögeneraattori sähkökatkoksen sattuessa.
- Tier II – Redundant Capacity Components: Everything that Tier I provides, plus redundant power and cooling to the facility. Tämä voi sisältää ylimääräisiä UPS-yksiköitä tai ylimääräisiä generaattoreita.
- Tier III-samanaikaisesti ylläpidettävissä: Kaikki, mitä Tier II tarjoaa, sekä ylimääräiset laitteet, jotka estävät laitteiden vaihdon tai huollon keskeytykset. Tällä tasolla tarpeeton teho ja jäähdytys levitetään suoraan kaikkiin teknisiin laitteisiin, ja itse laite on konfiguroitu redundanssia tai saumatonta vikaantumista varten.
- Tier IV – Vikatoleranssi: kaikki, mitä Tier III tarjoaa, sekä keskeytymätön palvelu tarjoajatasolla. Vaikka datakeskuksessa voi olla kaupungin tai valtion tarjoama sähkö tai vesi, tarvitaan toissijainen rivi kustakin datakeskuksen käyttämästä palvelusta. Tämä sisältää myös Internet-palveluntarjoajan. Jos vika missä tahansa osassa, joka johtaa asiakkaan laitteisiin, on varasuunnitelma valmiina saumattomaan siirtymiseen.
johtopäätös
irtisanomisesta on tullut IT-alalla pakon edessä arkipäiväinen termi. Palveluiden korkea saatavuus tarjoaa asiakkaillemme helpon ja luotettavan kokemuksen.
oli kyse sitten palvelutasosta tai datakeskustasosta, redundanssin tarjoaminen järjestelmälle on tärkeä ja vaikea asia käsitellä. Toivottavasti tämä asiakirja on valottanut käytettävissä olevia vaihtoehtoja ja auttaa mahdollisissa korkeaan saatavuuteen liittyvissä päätöksissä eteenpäin.
valmis hyödyntämään Atlantic.Net tarpeettomat järjestelmät? Ota yhteyttä jo tänään saadaksesi lisätietoja Dedicated Server Hosting with Atlantic.Net
=Sources==
Redundant System Basic Concepts:
Cold/Warm/Hot Server: http://searchwindowsserver.techtarget.com/definition/cold-warm-hot-server
High Availability Clustering: https://www.mulesoft.com/resources/esb/high-availability-cluster
Hyper-V Replica: https://technet.microsoft.com/en-us/library/jj134172(V=ws.11).aspx
Hyper-V and High Availability: https://technet.microsoft.com/en-us/library/hh127064.aspx
HAProxy Description: http://www.haproxy.org/#desc
HAProxy – They use it!: http://www.haproxy.org/they-use-it.html
Heartbeat: http://www.linux-ha.org/wiki/Main_Page
RAID Definition: http://searchstorage.techtarget.com/definition/RAID
Striping: http://searchstorage.techtarget.com/definition/disk-striping
RAID Battery Backup Units: https://www.thomas-krenn.com/en/wiki/Battery_Backup_Unit_(BBU/BBM)_Maintenance_for_RAID_Controllers
High-Availability – VRRP, HSRP, GLBP: http://www.freeccnastudyguide.com/study-guides/ccna/ch14/vrrp-hsrp-glbp/
Understanding VRRP: http://www.juniper.net/techpubs/en_US/junos/topics/concept/vrrp-overview-ha.html
Configuring VRRP: http://www.cisco.com/c/en/us/td/docs/ios-xml/ios/ipapp_fhrp/configuration/15-mt/fhp-15-mt-book/fhp-vrrp.html
Configuring GLBP: http://www.cisco.com/c/en/us/td/docs/ios-xml/ios/ipapp_fhrp/configuration/xe-3s/fhp-xe-3s-book/fhp-glbp.html
Explaining the Uptime Institute’s Tier Classification System: https://journal.uptimeinstitute.com/explaining-uptime-institutes-tier-classification-system/