It not ’Now a day Big data..’tarina, joka synnytti tämän suuren datan aikakauden, mutta’ kauan sitten… ’ ihmiset alkoivat kerätä tietoa manuaalisten tutkimusten, verkkosivustojen, antureiden, tiedostojen ja muiden tiedonkeruumenetelmien avulla. Jopa tämä sisältää kansainväliset järjestöt, kuten WHO, YK, joka keräsi kansainvälisesti kaikki mahdolliset tietokokonaisuudet seuranta-ja seurantatoimia ei vain liittyvät ihmisiin, mutta kasvillisuus ja eläinlajit tehdä tärkeitä päätöksiä ja toteuttaa tarvittavat toimet.
niin suuret monikansalliset yritykset erityisesti verkkokauppa-ja markkinointiyritykset alkoivat käyttää samaa strategiaa seuratakseen ja seuratakseen asiakkaiden toimintaa brändien ja tuotteiden edistämiseksi, mikä synnytti analytiikkahaaran. Nyt se ei kyllästy niin helposti, koska yritykset ovat ymmärtäneet todellisen datan arvon ydinpäätösten tekemiseen projektin jokaisessa vaiheessa alusta loppuun, jotta voidaan luoda parhaat optimoidut ratkaisut kustannusten, määrän, markkinoiden, resurssien ja parannusten suhteen.
Big Datan V: t ovat tilavuus, nopeus, lajike, todenperäisyys, valenssi ja arvo ja jokainen vaikutus tiedonkeruu, seuranta, varastointi, analysointi ja raportointi. Ekosysteemi kannalta teknologian toimijoita big data system on kuten alla.

nyt aion keskustella jokaisesta teknologiasta yksitellen antaakseni vilauksen siitä, mitä tärkeitä komponentteja ja rajapintoja.
miten Facebookista, Twitteristä ja LinkedInistä poimitaan sosiaalisen median datasta tietoja yksinkertaiseen csv-tiedostoon jatkokäsittelyä varten.
voidaksesi poimia tietoja Facebookista python-koodilla sinun täytyy rekisteröityä kehittäjäksi Facebookiin ja sen jälkeen sinulla on käyttöoikeuspaletti. Tässä ovat vaiheet siihen.
1. Siirry linkkiin developers.facebook.com, Luo tili siellä.
2. Siirry linkkiin developers.facebook.com/tools/explorer.
3. Mene” Omat sovellukset ”pudota alas oikeassa yläkulmassa ja valitse”Lisää uusi sovellus”. Valitse Näytön nimi ja luokka ja sitten ”Luo App ID”.
4. Palaa taas samaan linkkiin developers.facebook.com/tools/explorer. näet ”Graph API Explorer ”alla” Omat sovellukset ” oikeassa yläkulmassa. Vuodesta ”Graph API Explorer” pudota alas, Valitse sovellus.
5. Sitten, valitse ”Get Token”. Valitse tästä pudotusvalikosta ”Get User Access Token”. Valitse käyttöoikeudet valikosta, joka näkyy ja valitse sitten ”Get Access Token.”
6. Siirry linkkiin developers.facebook.com/tools/accesstoken. valitse ”Debug” vastaa ”User Token”. Siirry kohtaan ”Extend Token Access”. Tämä varmistaa, että token ei vanhene kahden tunnin välein.
Python-koodi, jolla pääsee käsiksi Facebook-julkisiin tietoihin:
mene Linkille https://developers.facebook.com/docs/graph-api jos haluaa kerätä tietoja kaikesta, mikä on julkisesti saatavilla. https://developers.facebook.com/docs/graph-api/reference/v2.7/. Valitse tästä dokumentaatiosta haluamasi kenttä, josta haluat poimia tietoja, kuten ”ryhmät” tai ”sivut” jne. Siirry esimerkkejä koodeista, kun olet valinnut nämä ja valitse sitten ”facebook graph api” ja saat vinkkejä siitä, miten poimia tietoja. Tämä blogi on ensisijaisesti saada tapahtumia tietoja.
ensinnäkin tuo ”urlib3”, ”facebook”, ”pyynnöt”, jos ne ovat jo saatavilla. Jos ei, lataa nämä kirjastot. Määrittele muuttuja token ja aseta sen arvo sille, mitä sait edellä ”User Access Token”.

tietojen poimiminen Twitteristä:
yksinkertaisia 2 vaihetta voi seurata alla olevan
- lainaat sovelluksen tiedot-sivulla; siirry’ avaimet ja Access Tokens ’välilehti, selaa alaspäin ja klikkaa ’Luo oma access token’. Huomaa API Key ja API Secret arvot tulevaa käyttöä varten. Et jaa näitä kenenkään kanssa, yksi voi käyttää tiliäsi, jos he saavat avaimet.
- twiittien purkamiseksi on luotava turvallinen yhteys R: n ja Twitterin välille seuraavasti,
#Clear R-ympäristö
rm(list=ls())
#Load required libraries
install.paketit (”twitteR”)
asenna.packages (”ROAuth”)
library (”twitteR”)
library (”ROAuth”)
# Download the file and store in your working directory
download.file (url= ”http://curl.haxx.se/ca/cacert.pem”, destfile= ”cacert.pem”)
# Lisää kulutusavaimesi ja kulutusesitteesi alle
valtakirjat <- OAuthFactory$new(consumerKey=’XXXXXXXXXXXXXXXXXX’,
consumerSecret=’XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX’,
requestURL=’https://api.twitter.com/oauth/request_token”,
accessURL=”https://api.twitter.com/oauth/access_token”,
authURL= ”https://api.twitter.com/oauth/authorize”)
cred$handshake(cainfo= ” cacert.pem”)
#Load Authentication Data
load (”twitter authentication.Rdata”)
#Register Twitter Authentication
setup_twitter_oauth(valtakirjat$consumerKey, valtakirjat$consumerSecret, valtakirjat$oauthkey, valtakirjat$oauthsecret)
#Extract Tweets with concerned string(first argument), followed by number of tweets (N) and language (lang)
tweets <- searctwitter (”#DataLove”, n=10, lang= ”en”)
nyt voit hakea minkä tahansa sanan haku-Twitter-funktiosta poimiaksesi sanan sisältävät twiitit.
tietojen poimiminen Oracle ERP: stä
voit käydä linkissä tarkistamassa csv-tiedoston porrastetusti Oracle ERP cloud-tietokannasta.
tiedonhankinta ja varastointi:
nyt kun tieto on saatu ulos, se on tallennettava ja käsiteltävä, kuten teemme tiedonhankinnan vaiheessa ja tallennuksessa.
katsotaan, miten Spark, Cassandra, Flume, HDFS, HBASE toimii.
Spark
Spark voidaan ottaa käyttöön useilla eri tavoilla, se tarjoaa natiivisidontoja Java -, Scala -, Python-ja R-ohjelmointikielille sekä tukee SQL -, streaming -, koneoppiminen-ja graafinkäsittelyä.
RDD on kipinän kehys, joka auttaa rinnakkaisessa tiedon käsittelyssä jakamalla sen tietokehyksiin.
Jos haluat lukea tietoja Spark-alustalta, käytä alla olevaa komentoa
results = spark.sql (”Select * from people”)
names = results.kartta (lambda p: p.name)
Yhdistä mihin tahansa tietolähteeseen, kuten json, JDBC, Hive Spark käyttäen yksinkertaisia komentoja ja toimintoja. Like you can read json data as below
spark.lukea.JSON (”s3n://…”).registerTempTable (”json”)
results = spark.sql (”SELECT * from people JOIN JSON…”)
Spark koostuu useammista ominaisuuksista, kuten suoratoisto reaaliaikaisista tietolähteistä, jotka näimme edellä käyttäen R-ja python-lähdettä.
Apache spark-kotisivuilta löytyy monia esimerkkejä, jotka osoittavat, miten Sparkilla voi olla rooli tiedon louhinnassa, mallintamisessa.
https://spark.apache.org/examples.html
Cassandra:
Cassandra on myös Sparkin kaltainen Apache-tekniikka datan tallentamiseen ja hakemiseen sekä tallentamiseen useisiin solmuihin, jotta saadaan 0 vikasietoisuutta. Se käyttää normaaleja tietokannan komentoja, kuten luo, valitse, Päivitä ja poista toimintoja. Voit myös luoda indeksejä, materialisoitua ja normaalia näkymää yksinkertaisilla komennoilla, kuten SQL: ssä. Extension is You can use JSON data type for performing additional operations like as seen as seen below
Insert into mytable JSON ’{ ”\”myKey\””: 0, ”value”: 0}’
It provides git hub open source drivers to be used with.net, Python, Java, PHP, NodeJs, Scala, Perl, ROR.
kun määrität tietokantaa, täytyy määrittää solmujen lukumäärä solmujen nimien mukaan, jakaa token kunkin solmun kuormituksen perusteella. Voit myös käyttää valtuutus-ja roolikomentoja hallitaksesi tietyn solmun datatason käyttöoikeuksia.
lisätietoja voi viitata annettuun linkkiin
http://cassandra.apache.org/doc/latest/configuration/cassandra_config_file.html
Casandra lupaa saavuttaa 0 vikatoleranssin, koska se tarjoaa useita vaihtoehtoja hallita tietyn solmun tietoja Välimuistin avulla, tapahtumanhallinta, replikointi, samanaikainen luku-ja kirjoitustoiminta, levyn optimointikomennot, hallita tiedonsiirtoa ja datakehyskoon pituutta.
HDFS
eniten pidän HDFS: stä sen ikonista, JUMBONORSUSTA, joka on voimakas ja sitkeä kuten HDFS itse.
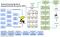
kuten yllä olevasta kaaviosta näkyy, big datan HDFS-järjestelmä on samanlainen kuin Cassandra, mutta tarjoaa hyvin yksinkertaisen rajapinnan ulkoisiin järjestelmiin.
Tiedot pilkotaan erisuuruisiksi tai samankokoisiksi tietokehyksiksi, jotka tallennetaan hajautettuun tiedostojärjestelmään. Dataa siirretään edelleen eri solmuihin optimoitujen kyselytulosten perusteella datan tallentamiseksi. Perusarkkitehtuuri on keskitettyä mallia Hadoop if Map reduction-mallista.
1. Data on jaettu lohkoihin, joissa sanotaan 128 MB
2. Nämä tiedot ovat kuin jakautuneet eri solmuihin
3. HDFS valvoo käsittelyä
4. Replikointi ja välimuistiin tallentaminen suoritetaan maksimaalisen vikasietoisuuden saavuttamiseksi.
5. kun Kartta ja vähentää on suoritettu ja työt onnistuneesti laskettu, ne menevät takaisin pääpalvelimelle
Hadoop on pääasiassa koodattu Java niin sen suuri jos saat joitakin käsiä Java kuin se nopea ja helppo asentaa ja ajaa kaikki ne komennot.
pikaopas kaikille Hadoopiin liittyville käsitteille löytyy alla olevasta linkistä
https://www.tutorialspoint.com/hadoop/hadoop_quick_guide.html
raportointi ja visualisointi
nyt puhutaan SAS: stä, R studiosta ja Kimestä, joita käytetään suurten tietomäärien analysointiin monimutkaisten algoritmien avulla, jotka ovat koneoppimisen algoritmeja, jotka perustuvat joihinkin monimutkaisiin matemaattisiin malleihin, jotka analysoivat täydellistä dataa ja luovat graafisen esityksen tietyn halutun liiketoiminnan tavoitteen saavuttamiseksi. Esimerkki myyntitiedot, asiakkaan markkinapotentiaali, resurssien käyttö jne.
SAS, R ja Kimme kaikki kolme työkalua tarjoavat laajan valikoiman ominaisuuksia kehittyneestä analytiikasta, IOT: stä, koneoppimisesta, Riskienhallintamenetelmistä, tietoturvatiedustelusta.
mutta koska niistä yksi on kaupallinen ja muut 2 ovat avointa lähdekoodia, niiden välillä on joitakin suuria eroja.
sen sijaan, että olisin käynyt läpi jokaisen niistä yksitellen, olen tiivistänyt jokaisen ohjelmistoeron ja muutamia hyödyllisiä vinkkejä, jotka puhuvat niistä.
