
koneoppimista käytetään lopulta ennustamaan tuloksia, jotka on annettu joukolle ominaisuuksia. Siksi kaikki, mitä voimme tehdä mallimme suorituskyvyn yleistämiseksi, nähdään nettovoittona. Dropout on tekniikka, jota käytetään estämään mallin ylilyöntejä. Dropout toimii asettamalla satunnaisesti lähtevien reunojen piilotettu yksiköiden (neuronien, jotka muodostavat piilotettu kerrokset) on 0 jokaisen päivityksen koulutusvaiheen. Jos otat tarkastella keras dokumentaatio dropout kerros, näet linkin valkoinen paperi kirjoittanut Geoffrey Hinton and friends, joka menee teorian takana dropout.
menettelyesimerkissä rakennetaan Kerojen avulla neuroverkko, jonka tavoitteena on tunnistaa käsin kirjoitetut numerot.
from keras.datasets import mnist
from matplotlib import pyplot as plt
plt.style.use('dark_background')
from keras.models import Sequential
from keras.layers import Dense, Flatten, Activation, Dropout
from keras.utils import normalize, to_categorical
käytämme Kerasia tuodaksemme tiedot ohjelmaamme. Tiedot on jo jaettu koulutus-ja testisarjoihin.
(X_train, y_train), (X_test, y_test) = mnist.load_data()
katsotaan, minkä kanssa toimitaan.
plt.imshow(x_train, cmap = plt.cm.binary)
plt.show()

kun olemme treenanneet ulos mallista, sen pitäisi pystyä tunnistamaan edeltävä kuva vitoseksi.
on pieni esikäsittely, joka meidän on suoritettava etukäteen. Normalisoimme Pikselit (ominaisuudet) siten, että ne vaihtelevat 0: sta 1: een. Tämä mahdollistaa mallin lähentymisen kohti ratkaisua paljon nopeammin. Seuraavaksi muutamme kunkin kohteen etiketit tietyn näytteen array 1s ja 0s jossa indeksi numero 1 osoittaa numeron kuva edustaa. Teemme näin, koska muuten mallimme tulkitsisi numeron 9 olevan tärkeämpi kuin numeron 3.
X_train = normalize(X_train, axis=1)
X_test = normalize(X_test, axis=1)
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
ilman keskeyttämistä
ennen kuin syötetään 2-ulotteinen matriisi neuroverkkoon, käytetään tasaista kerrosta, joka muuttaa sen 1-ulotteiseksi matriisiksi liittämällä jokainen seuraava rivi sitä edeltäneeseen riviin. Käytämme kahta Piilotettua kerrosta, jotka koostuvat 128 hermosolusta ja 10 hermosolusta, joista jokainen vastaa yhtä 10: stä mahdollisesta numerosta. Softmax-aktivointifunktio palauttaa todennäköisyyden, että näyte edustaa tiettyä lukua.

koska yritämme ennustaa luokkia, käytämme kategorista ristentropiaa tappiofunktionamme. Mittaamme mallin suorituskykyä tarkkuuden avulla.
model.compile(
loss='categorical_crossentropy',
optimizer='adam',
metrics=
)
asetamme 10% tiedoista sivuun validointia varten. Vertaamme tämän avulla mallin taipumusta ylilyönteihin keskeyttämisen kanssa ja ilman sitä. Erän koko 32 tarkoittaa, että laskemme gradientin ja otamme askeleen gradientin suuntaan, jonka suuruus on yhtä suuri kuin Oppimisnopeus, kun olemme läpäisseet 32 näytettä neuroverkkoon. Teemme tämän yhteensä 10 kertaa määrä aikakausia.
history = model.fit(
X_train,
y_train,
epochs=10,
batch_size=32,
validation_split=0.1,
verbose = 1,
shuffle=True
)
/div>
voimme piirtää koulutus-ja validointitarkkuudet kullakin ajanjaksolla käyttämällä fit-funktion palauttamaa historiamuuttujaa.
kuten näette, ilman keskeyttämistä validointihäviö lakkaa pienenemästä kolmannen aikakauden jälkeen.

As you can see, without dropout, the validation accuracy tends to plateau around the third epoch.

Using this simple model, we still managed to obtain an accuracy of over 97%.
test_loss, test_acc = model.evaluate(X_test, y_test)
test_acc
div>
dropout
on jonkin verran keskustelua siitä, pitäisikö keskeyttäjä sijoittaa ennen aktivointifunktiota vai sen jälkeen. Nyrkkisääntönä voidaan pitää, että keskeyttäjä sijoitetaan aktivointitoiminnon jälkeen kaikille muille aktivointitoiminnoille kuin relu: lle. 0,5: n ohituksessa jokainen piiloyksikkö (neuroni) asetetaan arvoon 0 0 todennäköisyydellä 0,5. Toisin sanoen on olemassa 50% muutos, että tietyn neuronin ulostulo pakotetaan 0: een.

taas, koska yritämme ennustaa luokkia, käytämme kategorista ristentropiaa häviöfunktionamme.
model_dropout.compile(
loss='categorical_crossentropy',
optimizer='adam',
metrics=
)
antamalla validations split-parametrin malli erottaa murto-osan harjoitustiedoista ja arvioi näiden tietojen häviöt ja mahdolliset mallimittarit kunkin aikakauden lopussa. Jos lähtökohtana dropout pätee, meidän pitäisi nähdä merkittävä ero validoinnin tarkkuus verrattuna edelliseen malliin. Shuffle-parametri sekoittaa harjoitustiedot ennen jokaista aikakautta.
history_dropout = model_dropout.fit(
X_train,
y_train,
epochs=10,
batch_size=32,
validation_split=0.1,
verbose = 1,
shuffle=True
)

kuten näette, validointihäviö on huomattavasti pienempi kuin tavallisella mallilla saatu.

kuten näette, malli lähentyi paljon nopeammin ja sai lähes 98% tarkkuuden validointijoukossa, kun edellinen malli tasaantui kolmannen aikakauden tienoille.

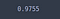
testisarjalla saatu tarkkuus ei ole kovin erilainen kuin mallilla ilman keskeyttämistä saatu tarkkuus. Tämä johtuu mitä todennäköisimmin näytteiden vähäisestä määrästä.
test_loss, test_acc = model_dropout.evaluate(X_test, y_test)
test_acc

div>
final thoughts
Dropout voi auttaa mallia yleistämään asettamalla satunnaisesti tietyn hermosolun ulostulo arvoon 0. Asetettaessa lähtö arvoon 0, kustannusfunktio herkistyy viereisille neuroneille muuttaen tapaa, jolla painot päivittyvät vastapainon prosessin aikana.