By: Arshad Ali | Updated: 2020-07-29 | Comments (6)/Related: More > JOIN Tables
Problem
in the tip SQL Server JoinExamples, Jeremy Kadlec talk about different logical join operators, but howdoes SQL Server implement them physical? Mitkä ovat erilaiset fyysiset liitoskumppanit? Miten ne eroavat toisistaan ja missä skenaariossa toinen on parempi kuin toinen? Tässä vinkissä käsitellään näitä kysymyksiä ja paljon muuta.
ratkaisu
käytämme loogisia operaattoreita kirjoittaessamme kyselyitä määrittääksemme relaatiokyselyn käsitteellisellä tasolla (mitä on tehtävä). SQL toteuttaa nämä loogiset operaattorit kolmella eri fyysisellä operaattorilla toteuttaakseen loogisten operaattoreiden määrittelemän operaation (miten se on tehtävä). Vaikka fyysisiäoperaattoreita on kymmeniä, tässä vinkissä käsittelen tiettyjä fyysisiä liittymäoperaattoreita. Vaikka meillä on erilaisia loogisia liittymiä käsitteellisellä / kyselytasolla,mutta SQL Palvelintoteuttaa ne kaikki kolmella eri fyysisellä join operaattorit kuten alla.
käymme läpi:
- Merge Join
- hash Join
käymme läpi rakennussuunnitelmat nähdäksemme nämä operaattorit ja selitän, miksi kukin tapahtuu.
näissä esimerkeissä käytän adventureworks-tietokantaa.
SQL Serverin sisäkkäisten silmukoiden liittyminen selitetty
ennen yksityiskohtien penkomista kerron ensin, mikä sisäkkäisten silmukoiden liittymä on, jos olet uusi ohjelmointimaailmassa.
sisäkkäinen Silmukkaliitos on looginen rakenne, jossa yhden silmukan (iteraation) sisällä on toinen, eli jokaisen ulomman silmukan iteraation kohdalla suoritetaan / käsitellään kaikki sisemmän silmukan iteraatiot.
sisäkkäinen Silmukkaliitos toimii samalla tavalla. Yksi liitospöydistä on ulompi pöytä ja toinen sisempi pöytä. Kunkin ulomman taulukon rivin kaikki sisemmän taulukon rivit täsmäävät yksitellen, jos rivin täsmäytysse sisältyy tulosjoukkoon, muuten se jätetään huomiotta. Sitten seuraava rivi ulommasta taulukosta poimitaan ja sama prosessi toistetaan ja niin edelleen.
SQL Server optimizer saattaa valita sisäkkäisen silmukan, kun yksi liitostauluista on pieni (pidetään ulompana taulukkona) ja toinen on suuri (pidetään sisempänä taulukkona, joka on indeksoitu liittymässä olevaan sarakkeeseen) ja henceit vaatii minimaalisen I / O: n ja vähiten vertailuja.
optimoija pitää Sisäkkäiselle silmukalle kolmea vaihtoehtoa:
- naiivi sisäkkäinen silmukka liittyy, jolloin haku skaalaa koko taulukon tai indeksin
- indeksin sisäkkäiset silmukat yhtyvät, kun haku voi käyttää olemassa olevaa indeksiä hakujen suorittamiseen
- tilapäisen indeksin sisäkkäiset silmukat yhtyvät, jos optimoija luo tilapäisen indeksin osana kyselysuunnitelmaa ja tuhoaa sen kyselyn suorituksen jälkeen
indeksin sisäkkäinen Silmukkaliitos toimii paremmin kuin yhdistämisliitos tai hajautusliitos, jos kyseessä on pieni rivistö. Kun taas, jos suuri joukko rivejä ovat mukana theNested silmukoita liittyä ei ehkä ole optimaalinen valinta. Sisäkkäiset silmukat tukevat lähes kaikkia liitostyyppejä paitsi oikeaa ja täyttä ulompaa liitosta, oikeaa puoliliitosta ja oikeaa antisemijointia.
- Script #1: ssä Liityn Sales Orderheader-taulukkoon, jossa on Sales Orderdetailable ja täsmennetään asiakkaan tuloksen suodatuskriteerit asiakkaan kanssa customerid = 670.
- tämä suodatettu kriteeri palauttaa 12 tietuetta Sales Orderheader-taulukosta ja on siten pienempi, joten tätä taulukkoa on pidetty optimoijan Outer-taulukkona (ylimpänä graafisessa kyselyn suoritussuunnitelmassa).
- jokaiselle riville näistä ulomman taulukon 12 rivistä täsmätään sisemmän taulukon Myyntijärjestyksen rivit (tai sisätaulukko skannataan 12 kertaa joka kerta kunkin rivin osalta käyttäen ulomman taulukon indeksihakua tai vastaavuusparametriä) ja 312 vastaavaa riviä palautetaan, kuten näet toisessa kuvassa.
- alla olevassa toisessa kyselyssä käytän SET STATISTICS PROFILE ON displayprofile-tietoa kyselyn suorituksesta yhdessä kyselyn tulosjoukon kanssa.
Script #1 – sisäkkäisten silmukoiden Liitosesimerkki
SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader H INNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID = 670
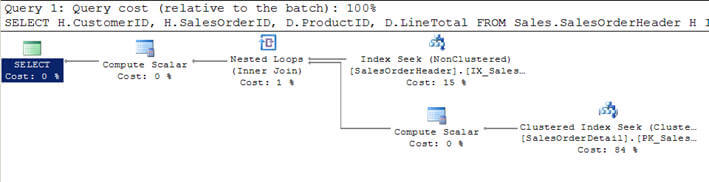
SET STATISTICS PROFILE ONSELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader HINNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderIDWHERE H.CustomerID = 670SET STATISTICS PROFILE OFF
div>
Jos mukana olevien tietueiden määrä on suuri, SQL Server saattaa valita parallelizean sisäkkäisen silmukan jakamalla uloimmat taulukkorivit satunnaisesti käytettävissä olevien silmukoiden säikeiden kesken dynaamisesti. Se ei koske samaa sisempi tablerows vaikka. Lisätietoja parallel scansclick täällä.
SQL Server Merge Join Explained
ensimmäinen asia, joka sinun tarvitsee tietää Yhdistämisliitoksesta, on se, että se vaatii molempia syötteitä lajiteltavaksi join keys/merge-sarakkeisiin (tai molemmat syöttötaulukot ovat ryhmittyneet taulukoihin liittyvään sarakkeeseen) ja se vaatii myös vähintään yhden yhtäläisen lausekkeen / predikaatin.
koska rivit ovat valmiiksi lajiteltuja, yhdistymisprosessi alkaa välittömästi. Se lukee rivin yhdestä syötteestä ja vertaa sitä toisen syötteen riviin.Jos rivit täsmäävät, että hyväksytty rivi katsotaan tulosjoukossa (sitten se lukee seuraavan rivin syötetaulukosta, onko sama vertailu/ottelu ja niin edelleen) orelse pienempi kahdesta rivistä ohitetaan ja prosessi jatkuu tällä tavalla, kunnes kaikki rivit on käsitelty..
Yhdistämisliittymä toimii paremmin yhdistettäessä suuria syöttötaulukoita (esiindeksoitu / lajiteltu), koska kustannus on rivien yhteenlasku molemmissa syöttötaulukoissa verrattuna Nestedloopeihin, joissa se on molempien syöttötaulukoiden rivien tulo. Joskus optimizerdecides käyttää Yhdistämisliittymää, kun syöttötauluja ei ole lajiteltu ja siksi se käyttää eksplisiittistä lajittelu-fyysistä operaattoria, mutta se voi olla hitaampaa kuin indeksin käyttäminen(ennalta lajiteltu syöttötaulukko).
- skriptissä #2 käytän samanlaista kyselyä kuin yllä, mutta tällä kertaa olen lisännyt WHERE-lausekkeen, jotta kaikki asiakkaat olisivat suurempia kuin 100.
- tässä tapauksessa optimoija päättää käyttää Yhdistämisliittymää, koska molemmat syötteet ovat rivien suhteen suuria ja ne on myös esiindeksoitu / lajiteltu.
- Voit myös huomata, että molemmat tulot skannataan vain kerran, toisin kuin 12 skannausta, jotka näimme yllä olevissa Sisäkkäisissä silmukoissa.
Script #2 – Merge Join Example
SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader H INNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID > 100
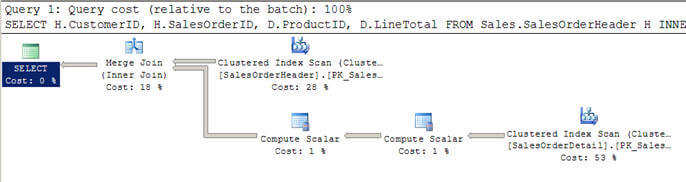
SET STATISTICS PROFILE ONSELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader HINNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderIDWHERE H.CustomerID > 100SET STATISTICS PROFILE OFF

merge join on usein tehokkaampi ja nopeampi liittymisoperaattori, jos sorteddata voidaan saada olemassa olevasta B-puuindeksistä ja se suorittaa lähes kaikki liittymisoperaatiot niin kauan kuin mukana on vähintään yksi tasa-arvoisen liittymisen predikaatti. Se tukee myös useita tasa-arvo liittyä predikaatteja niin kauan kuin syöttötaulukot aresorted kaikkien liittymisen avaimet mukana ja ovat samassa järjestyksessä.
laskukoneen skalaarioperaattorin läsnäolo ilmaisee ekspression arviointia lasketun skalaariarvon tuottamiseksi. Yllä olevassa kyselyssä valitsen LineTotalwhich on johdettu sarake, joten sitä on käytetty suoritussuunnitelmassa.
SQL Server Hash Join Explained
Hash-liittymistä käytetään yleensä, kun syöttötaulukot ovat melko suuria eikä niissä ole riittäviä liitteitä. Hasisliittymä suoritetaan kahdessa vaiheessa; Rakentamisvaihe ja koettimen vaihe ja siten hash-liitos on kaksi tuloa eli rakentaa Tulo ja probeinput. Pienempi panosten pidetään rakentaa tulo (minimoida themory vaatimus tallentaa hajautustaulukon keskusteltu myöhemmin) ja ilmeisesti toinen on koetin tulo.
rakentamisvaiheen aikana skannataan kaikkien rakentamistaulukon rivien liitosavaimet.Tiivisteet luodaan ja sijoitetaan muistissa olevaan hajautustaulukkoon. Toisin kuin Yhdistämisliitos, se estää (rivejä ei palauteta) tähän pisteeseen asti.
koettimen vaiheen aikana skannataan jokaisen koettimen taulukon rivin yhtyvät näppäimet.Jälleen hasheja luodaan(käyttäen samaa hash-toimintoa kuin yllä) ja verrataan vastaavaan hash-taulukkoon.
hajautusfunktio vaatii merkittävän määrän SUORITINSYKLEJÄ hajautustaulukon luomiseen ja muistiresursseja hajautustaulukon tallentamiseen. Jos on muistipainetta, osa hajautustaulun osioista vaihdetaan tempdb: hen ja aina kun on tarvetta (joko tutkia tai päivittää sisältöä), se tuodaan takaisin välimuistiin.Saavuttaa korkean suorituskyvyn, kyselyn optimoija voi parallelize Hash liittyä toscale paremmin kuin mikään muu liittyä, lisätietoja klikkaa täällä.
on periaatteessa kolmenlaisia hajautusliittymiä:
- in-memory Hash-liittymiä, jolloin hajautustaulukkoon on saatavilla tarpeeksi muistia
- Grace Hash-liittymistä, jolloin hajautustaulukko ei mahdu muistiin ja osa osioista valuu tempdb: hen
- rekursiivinen Hash-liittymä, jolloin hajautustaulukko on niin suuri, että optimoijan on käytettävä monia yhdistämisliittymätasoja.
tarkempia tietoja näistä eri tyypeistä klikkaa tästä.
- käsikirjoituksessa #3 luon kaksi uutta suurta taulukkoa (olemassa olevista AdventureWorkstables) ilman indeksejä.
- näet, että optimoija päätti käyttää tässä tapauksessa Hajautusliittymää.
- taas toisin kuin sisäkkäinen Silmukkaliitos, se ei skannaa sisempiä taulukon kerrannaisia.
Script #3 – Hash Join Example
--Create tables without indexes from existing tables of AdventureWorks database SELECT * INTO Sales.SalesOrderHeader1 FROM Sales.SalesOrderHeader SELECT * INTO Sales.SalesOrderDetail1 FROM Sales.SalesOrderDetail GO SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader1 H INNER JOIN Sales.SalesOrderDetail1 D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID = 670 GO
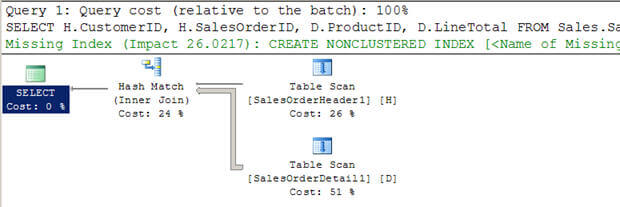
SET STATISTICS PROFILE ON SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader1 H INNER JOIN Sales.SalesOrderDetail1 D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID = 670 SET STATISTICS PROFILE OFF

--Drop the tables created for demonstration DROP TABLE Sales.SalesOrderHeader1 DROP TABLE Sales.SalesOrderDetail1
Huom: SQL Server tekee melko hyvää työtä päättäessään, mitä joinoperaattoria käyttää kussakin tilassa. Ymmärtäminen nämä ehdot auttaa ymmärtämään, mitä voidaan tehdä suorituskyvyn viritys. Ei ole suositeltavaa käyttää join vihjeet (usingOPTION lauseke) pakottaa SQL Server käyttämään tiettyä liittyä operaattori (ellet haveno muuta tietä ulos), vaan voit käyttää muita keinoja,kuten päivittää tilastoja, luoda indeksejä tai uudelleen kirjallisesti kyselyn.
Next Steps
- ReviewSQL-Palvelinjoin esimerkkejä kärki.
- ReviewLogical and Physical Operators Reference article on technet.
päivitetty viimeksi: 2020-07-29


 Arshad Ali is a SQL and BI Developer focusing on Data Warehousing projects for Microsoft.
Arshad Ali is a SQL and BI Developer focusing on Data Warehousing projects for Microsoft.View all my tips
- More Database Developer Tips…