Lo scopo di questo articolo è quello di spiegare la ridondanza in termini di computing, networking e hosting. Forniremo esempi reali di soluzioni tecnologiche ridondanti per illustrare cos’è la ridondanza e come funziona.
Atlantic.Net ha creato più ambienti di hosting, tra cui una piattaforma cloud durevole, hosting VPS ad alta velocità, infrastruttura conforme HIPAA e hosting cloud privato gestito. Tutti i nostri sistemi sono costruiti con la ridondanza come fattore trainante primario del processo di progettazione.
Nell’inglese di tutti i giorni, la ridondanza può avere una connotazione negativa; qualcosa di ridondante di solito non è necessario o considerato superfluo. Tuttavia, in un ambiente di hosting cloud, la ridondanza può significare la differenza tra la disponibilità del sistema senza interruzioni e tempi di inattività indesiderati o imprevisti.
- Che cos’è un sistema ridondante?
- Tipi di sistemi ridondanti
- Esempi di servizi software ridondanti
- Hyper-V Replica
- Hyper-V Clustering
- HAProxy
- Heartbeat
- Esempi di servizi hardware ridondanti
- RAID
- Ridondanza di rete
- First Hop Redundancy Protocols (FHRP)
- Virtual Router Redundancy Protocol (VRRP)
- Hot Standby Router Protocol (HSRP)
- Gateway Load Balancing Protocol (GLBP)
- Ridondanza dei data Center
- Conclusione
Che cos’è un sistema ridondante?
Un sistema ridondante fornirà il supporto di failover o bilanciamento del carico per proteggere un sistema live in caso di guasto imprevisto. In caso di guasto elettrico, meccanico o software, un sistema ridondante avrà un componente o una piattaforma duplicati a cui ricorrere. In generale, qualsiasi componente di un sistema con un singolo punto di guasto può essere visto come un rischio per i servizi di produzione.
I sistemi di alimentazione o meccanici hanno strategie di ripiegamento più semplici che richiedono la semplice presenza di un altro dello stesso tipo di servizio; i failover software di solito richiedono una configurazione aggiuntiva sul sistema host o su un master o gateway.
Le funzionalità di ridondanza sono consigliate per qualsiasi sistema business-critical, ma in particolare per i sistemi che hanno un impatto significativo durante i tempi di inattività. Alcune aziende possono conservare tutte le informazioni critiche sui clienti in un database; pertanto, ai fini della continuità aziendale, la protezione di tale database con ridondanza proteggerà l’integrità dei dati in caso di guasto catastrofico.
Tipi di sistemi ridondanti
Un sistema ridondante è costituito da almeno due sistemi interconnessi e progettati per lo stesso scopo. Ci sono molti diversi tipi di configurazioni di sistema ridondanti disponibili, e diverse implementazioni del sistema forniscono approcci unici a come mantenere un sistema in ogni momento.
Non tutti i server devono essere configurati con ridondanza; piuttosto, solo i più critici dovrebbero essere considerati. Raccomandiamo vivamente una valutazione dettagliata dei rischi per capire quali server sono nell’ambito e la quantità massima di downtime che i server possono gestire. Utilizzare questa valutazione per determinare una strategia RTO (Recovery Time Objective) e RPO (Recovery Point Objective). RTO è la quantità massima di tempi di inattività accettabili. Questo può variare da 5 secondi a 24 ore. L’RPO è il punto nel tempo da cui si richiedono i dati; ad esempio, la vostra azienda può funzionare con una perdita massima di 24 ore di dati.
Ecco alcuni esempi popolari:
- Attivo-inattivo / Caldo-Freddo – Quando un componente di un sistema è il sistema attivo e un altro è inattivo o spento. Il componente inattivo viene attivato solo quando il componente attualmente in esecuzione si guasta o subisce manutenzione
- Attivo-Attivo / Caldo-Caldo – Quando entrambi i sistemi sono attivi e effettuano connessioni. Questo è più comunemente noto come clustering. Di solito, il dispositivo di fronte a entrambe le macchine determinerà come dividere il traffico in entrata
- Attivo-Standby/Caldo-Caldo – Quando entrambi i sistemi sono accesi, ma solo uno sta effettuando connessioni. Il secondo sistema è destinato a ricevere periodicamente aggiornamenti o backup dal sistema primario. In caso di guasto, il sistema in standby assume il ruolo primario fino a quando il sistema iniziale può essere recuperato.
Ogni tipo ha i suoi pro e contro.
- I sistemi Active-Inactive / Hot-Cold possono fornire una semplice piattaforma ridondante, ma qualsiasi failover farà sì che gli utenti vedano una versione precedente del sistema.
- Active-Active / Hot-Hot richiederà un aggiornamento costante di entrambi i sistemi, manualmente o tramite un servizio separato, per garantire che tutti gli utenti possano utilizzare entrambi i sistemi. Questo approccio può ridurre notevolmente il carico attivo su un servizio che stai fornendo ai clienti.
- Active-Standby / Hot-Warm fornirà le funzionalità di failover di hot-cold con una copia più aggiornata del sistema attivo sul failover, ma non fornisce alcun alleggerimento del carico.
Sono disponibili altre forme di ridondanza a più nodi che consentono una maggiore ridondanza e soluzioni di bilanciamento del carico robuste. A quel punto, avrai un cluster ad alta disponibilità, noto anche come cluster HA.
Questo può utilizzare qualsiasi combinazione delle soluzioni di ridondanza precedentemente note con la massima flessibilità nell’approccio o nella quantità di ridondanza necessaria. I cluster HA possono anche essere impostati su più posizioni fisiche per consentire la disponibilità fino al livello di backbone Internet.
Esempi di servizi software ridondanti
A causa della scarsa disponibilità delle risorse, non c’è motivo di non avere la replica proprietaria o servizi ridondanti impostati in un ambiente virtuale; quindi, molti di questi servizi sono disponibili di default nella maggior parte dei sistemi di virtualizzazione. Tutti i nostri servizi cloud dispongono di replica, una funzionalità che ci consente di replicare qualsiasi server da un nodo all’altro, sia che si trovino nello stesso data center o in aree di data center separate.
Hyper-V Replica
Hyper-V Replica è una forma di ridondanza caldo-caldo. Una macchina virtuale primaria viene creata su un host fisico e accetta le connessioni in entrata. Quando si abilita la replica, i dischi rigidi virtuali della nuova macchina vengono trasferiti a un host Hyper-V fisico separato. Questo host configura quindi una VM su se stessa che si replica su una pianificazione definita dall’utente per garantire che venga presa l’immagine più recente del server attivo. Ulteriori punti di controllo punti possono essere mantenuti pure. L’hosting privato Hyper-V con servizi gestiti è fornito da Atlantic.Net con questa caratteristica cotto in; contattare il nostro team per ulteriori informazioni.
Hyper-V Clustering
Hyper-V è anche in grado di clustering attraverso una connessione ad altri host Hyper-V. Le VM su qualsiasi host Hyper-V possono essere raggruppate insieme su quell’host singolare per fornire ridondanza a livello locale attraverso la rete virtuale.
Microsoft Network Load Balancing (NLB) può essere utilizzato per creare una singola risorsa composta da più host che condividono le stesse informazioni per fornire un semplice punto di accesso per la condivisione di file. Poiché questo è limitato solo dalla quantità di risorse disponibili, è possibile impostare teoricamente più host con più VM per la massima ridondanza, il che consentirebbe anche di eseguire la manutenzione su singole VM senza sacrificare la disponibilità del servizio o delle risorse. L’hosting privato Hyper-V con servizi gestiti è fornito da Atlantic.Net con questa caratteristica cotto in; contattare il nostro team per ulteriori informazioni.
HAProxy
Oltre a Hyper-V, un dispositivo gateway come un firewall può essere utilizzato per servizi di failover o bilanciamento del carico. Ad esempio, Atlantico.Net può fornire pfSense con proxy ad alta disponibilità, noto anche come HAProxy.
HAProxy fungerà da bilanciamento del carico, un proxy o una semplice soluzione hot-warm high availability per applicazioni basate su TCP e HTTP. HAProxy è una soluzione open source molto popolare basata su Linux utilizzata da alcuni dei siti più visitati al mondo.
Heartbeat
Heartbeat è un servizio disponibile sulla maggior parte delle distribuzioni di Linux che viene utilizzato per determinare se i nodi in un cluster sono ancora attivi o reattivi. È molto semplice da configurare e fornisce funzionalità di failover a qualsiasi sistema che funzioni su TCP.
Gli sviluppatori di Heartbeat raccomandano anche altri gestori di risorse cluster che avviano o interrompono i servizi in base al fatto che un determinato host sia inattivo. Heartbeat ha questo incluso, ma altri manager sono disponibili. Grazie alla semplicità di Heartbeat, è altamente personalizzabile. Piattaforme di hosting cloud fornite da Atlantic.Net hai già questa funzionalità e possiamo aiutarti a implementare Heartbeat sulla tua distribuzione Linux privata, se necessario.
Esempi di servizi hardware ridondanti
La parte migliore dell’hardware ridondante è la sua semplicità. Mentre i servizi software possono richiedere una configurazione eccessiva e sono probabilmente molto sensibili, l’hardware è di solito molto semplice da configurare e incredibilmente resistente. Il primo esempio che vedremo è la tecnologia RAID ampiamente utilizzata.
RAID
RAID sta per Redundant Array of Independent Disks (o Redundant Array of Cheap Disks Depending on how long you’ve been using it) e ha più livelli utilizzati per la protezione dei dati o per aumentare i/O del disco.
RAID può essere impostato tramite un controller software o hardware. Il controller ha il software e la configurazione necessari per gestire i dischi RAID. La configurazione può essere esportata in diversi sistemi con poca o nessuna configurazione aggiuntiva.
RAID può essere impostato in diversi modi per fornire un buon equilibrio di entrambe le sue qualità:
- RAID 0 – Questa è essenzialmente nessuna ridondanza. Nessun disco sul sistema condivide i dati attraverso il mirroring, ma tutti i dati sono a strisce su ciascun disco fornendo una maggiore velocità di lettura / scrittura. Ogni unità può comunque utilizzare lo spazio di archiviazione fornito al massimo, il che significa che più unità aggiungi a un RAID 0 più spazio avrai.
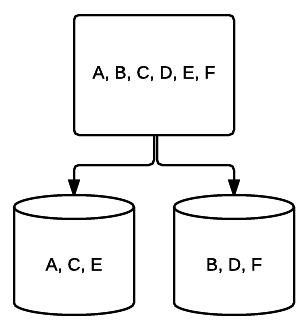
- RAID 1 – Una forma base di mirroring che fornisce un’eccellente ridondanza a costo dello spazio. In un sistema a due unità, una copia completa dei dati su un’unità viene scritta sull’altra. Questa ridondanza viene migliorata con ogni unità aggiunta. Poiché tutti i dati devono essere rispecchiati su tutte le unità, lo spazio totale sul sistema sarà limitato solo allo spazio dell’unità più piccola del sistema.
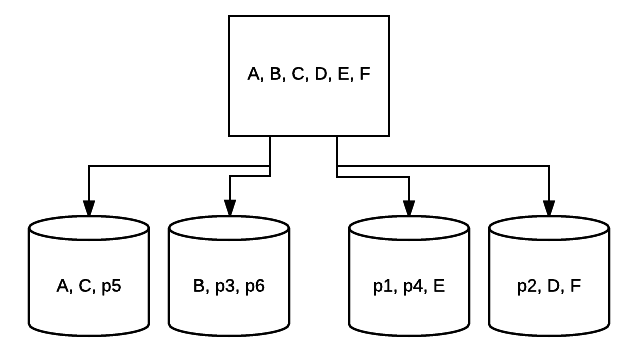
- RAID 5 – Questa forma di RAID viene solitamente utilizzata per aumentare la velocità di lettura e l’affidabilità. In questo caso, le strisce sono posizionate su ogni unità del sistema, con il minimo di 3 unità. Allo stesso tempo, viene inserito un ulteriore blocco di dati di correzione degli errori su ciascuna unità in una tecnica chiamata parità. Questo controlla se i dati vengono modificati durante il trasferimento da un’unità a un’altra. Ciò fornisce anche una forma minima di ridondanza poiché 1 di queste unità può fallire e il sistema può ancora funzionare. Più unità vengono aggiunte a questo tipo di configurazione RAID, più aumenta la velocità di lettura. Con ridondanza minima e striping su tutte le unità, la quantità totale di spazio in questa configurazione è uguale alla dimensione del volume RAID logico per il numero di unità utilizzate, meno una. Ad esempio, se si dispone di 5 unità da 500 GB in un RAID 5, si avranno 2000 GB utilizzabili o 2 TB (500 *(5-1)=2000).
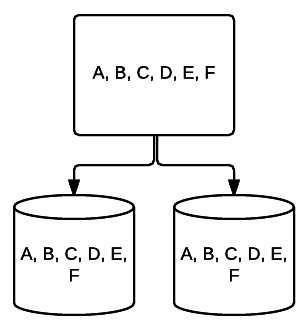
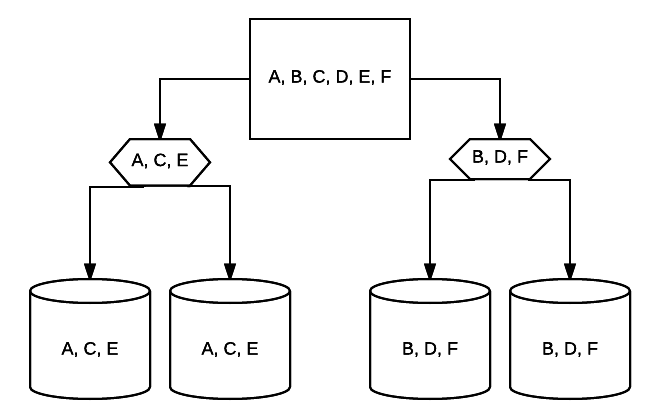
- RAID 10 – Questa è una combinazione di RAID 1 e RAID 0. In questo caso, tutti i dati sono a strisce su ogni dispositivo con blocchi di dati anche essere mirroring attraverso l’intero sistema a strisce. Ad esempio, in un sistema RAID 10 a 4 unità 2 le unità da 500 GB potrebbero avere gli stessi dati, ma non tutti i dati necessari per il corretto funzionamento del sistema. 2 sarebbero necessari dati di altre unità. Pensate a ogni sistema RAID 1 come una singola unità, e ciascuno di questi sistemi inseriti in un array RAID 0. In questa configurazione, le prestazioni possono essere drasticamente aumentate come in RAID 0, con una certa ridondanza ancora in atto con il mirroring. Fino alla metà delle unità nel sistema può fallire prima che il sistema si blocchi, ma come con qualsiasi array ridondante, è meglio sostituire le unità il prima possibile. Atlantic.Net utilizza RAID 10 per tutti SSD Cloud VPS di stoccaggio.
Per una maggiore protezione, i controller RAID sono protetti da unità di backup della batteria che alimentano i chip ROM utilizzati per salvare la configurazione in memoria in caso di perdita di potenza, ecc. Un BBU fornirà energia a un array RAID che fa parte di un sistema spento per un piccolo periodo di tempo, consentendo al contenuto della cache di un controller RAID di rimanere intatto. Questo può essere un salvagente se le informazioni vengono costantemente immesse nel tuo array RAID e qualsiasi tempo di inattività potrebbe causare il danneggiamento dei dati.
Quindi, il tuo sistema fisico e i servizi all’interno possono essere costruiti in modo ridondante piuttosto adeguato. Ma per quanto riguarda la connessione a qualsiasi parte del sistema? Come in, la connessione internet diretta al sistema nel suo complesso?
Ridondanza di rete
First Hop Redundancy Protocols (FHRP)
A differenza dei protocolli Dynamic gateway Discovery, i gateway statici consentono un hop semplice tra il client e il gateway appropriato, ma ciò crea un singolo punto di errore, ovvero il gateway stesso.
Per prevenire o ridurre l’impatto dell’errore del gateway, sono stati creati FHRP. Essi forniscono gateway ridondanti un fallback, o offrono il bilanciamento del carico per i sistemi ad alto traffico, insieme con la ridondanza. Questi protocolli includono VRRP, HSRP e GLBP.
Virtual Router Redundancy Protocol (VRRP)
VRRP è una forma di ridondanza utilizzata per i router che richiede almeno due router fisicamente separati collegati tramite connessioni Ethernet o fibra ottica. In questo caso, un’ router virtuale ‘ contenente percorsi statici viene creato e condiviso tra ciascun sistema.
Un sistema è considerato il ‘master’ e un altro il ‘backup’. Quando il master fallisce, il backup prende il posto del master successivo. Questo può essere impostato con più backup per ridondanza supplementare. Il concetto è molto simile a Heartbeat in quanto i sistemi di backup controlleranno se il master è disponibile. Una volta che non riceve una risposta, dopo un periodo di tempo prestabilito il backup assumerà il controllo dello switch virtuale e accetterà le connessioni per tutte le richieste in arrivo per l’IP predefinito configurato per lo switch master.
Hot Standby Router Protocol (HSRP)
HSRP è come VRRP; tuttavia, in questo scenario, lo switch virtuale configurato non è uno “switch”, ma piuttosto un gruppo logico di più router. L’IP del gruppo è un IP non assegnato a un host fisico. Invece, al gruppo viene assegnato un IP e uno dei router è determinato ad essere il router “attivo”.
Un router di standby è pronto a prendere qualsiasi connessione se il router attivo va giù. Tutti i router oltre all’attivo e allo standby sono tutti in ascolto per determinare il suo posto in linea. HSRP è un protocollo proprietario Cisco e ha pochissime differenze minori rispetto a VRRP, come i timer predefiniti che determinano quando eseguire il failover. HSRP è stato in giro un po ‘ più a lungo ed è più noto rispetto a VRRP.
Gateway Load Balancing Protocol (GLBP)
Il principale vantaggio di GLBP rispetto a HSRP e VRRP è la sua capacità di bilanciare il carico oltre a fornire ridondanza a un gateway con poca o nessuna configurazione extra. Proprio come HSRP e VRRP, GLBP creerà un gruppo tra router fisici e determinerà un gateway virtuale attivo, o AVG.
All’AVG viene assegnato un IP virtuale attualmente non utilizzato da nessuno dei router del gruppo. L’AVG distribuisce quindi indirizzi MAC virtuali tra il resto dei router del gruppo. Ogni router di backup è ora considerato uno spedizioniere virtuale attivo, o AVF.
Le richieste ARP inviate a AVG forniranno un indirizzo MAC virtuale diverso al client che invia la richiesta. A quel punto, il traffico da quel client all’IP virtuale del gruppo inoltra al router di cui hanno ricevuto l’indirizzo MAC virtuale, consentendo a ciascun router di essere ancora utilizzato invece di stare a guardare.
In caso di fallimento dell’AVG, l’elezione basata sulla priorità ha luogo, proprio come in HSRP e VRRP, e il backup successivo prende il suo posto, distribuendo normalmente gli indirizzi MAC virtuali. Gli altri router conservano ancora l’indirizzo MAC virtuale fornito dall’AVG originale e le cose continuano normalmente. In caso di guasto di uno degli AVFS, l’AVG impedirà il routing del traffico al suo indirizzo MAC virtuale.
Proprio come HSRP, GLBP è una forma proprietaria Cisco di FHRP.
Ridondanza dei data Center
Oltre alle misure di ridondanza per i server o i router personali, i data center sono progettati per essere resilienti ai guasti del sistema. I data center rientrano nei livelli definiti dall’Uptime Institute per fornire la tolleranza ai guasti di qualsiasi guasto meccanico o di servizio, consentendo il maggior tempo di attività possibile.
Esistono quattro livelli, ciascuno costruito l’uno sull’altro per fornire un’elevata disponibilità a tutti i clienti all’interno di un data center:
- Livello I – Capacità di base: Ciò richiede spazio per un gruppo IT per le operazioni di data center, un gruppo di continuità (UPS) che monitora e filtra il consumo di energia e apparecchiature di raffreddamento dedicate che sono costantemente in funzione 24/7. Questo include anche un generatore di corrente in caso di interruzione di corrente elettrica.
- Tier II – Componenti di capacità ridondanti: tutto ciò che Tier I fornisce, oltre a alimentazione e raffreddamento ridondanti per l’impianto. Questo può includere unità UPS extra o generatori extra.
- Livello III-Gestibile contemporaneamente: Tutto ciò che Tier II fornisce, oltre a attrezzature extra in atto per prevenire qualsiasi necessità di arresti per la sostituzione o la manutenzione delle apparecchiature. A questo livello, l’alimentazione e il raffreddamento ridondanti vengono applicati direttamente a tutte le apparecchiature tecniche e l’apparecchiatura stessa è configurata per la ridondanza o il failover senza interruzioni.
- Livello IV-Tolleranza ai guasti: tutto ciò che fornisce il livello III, oltre a un servizio ininterrotto a livello di provider. Mentre un data center può avere elettricità o acqua fornita da un fornitore di città o stato, è necessaria una linea secondaria di ciascun servizio utilizzato dal data center. Questo include anche l’ISP. In caso di guasto in qualsiasi sezione che porta all’apparecchiatura client, è disponibile un piano di backup pronto per una transizione senza interruzioni.
Conclusione
La ridondanza è diventata un termine quotidiano nel settore IT a causa della necessità. L’elevata disponibilità dei servizi offre ai nostri clienti un’esperienza facile e affidabile.
Sia a livello di servizio che a livello di data center, fornire ridondanza al sistema è un problema importante e difficile da affrontare. Speriamo che questo documento abbia fatto luce sulle opzioni disponibili e aiuterà in qualsiasi decisione presa in merito all’alta disponibilità in futuro.
Pronto a sfruttare Atlantic.Net sistemi ridondanti? Contattateci oggi per scoprire di più sui Server di Hosting Dedicato con Atlantic.Net.
===Fonti===
Sistema Ridondante Concetti di Base: http://www.ni.com/white-paper/6874/en/
Calda/Fredda/Calda Server: http://searchwindowsserver.techtarget.com/definition/cold-warm-hot-server
l’Alta Disponibilità di Clustering: https://www.mulesoft.com/resources/esb/high-availability-cluster
Hyper-V Replica: https://technet.microsoft.com/en-us/library/jj134172(v=rovescio del lavoro.11).aspx
Hyper-V and High Availability: https://technet.microsoft.com/en-us/library/hh127064.aspx
HAProxy Description: http://www.haproxy.org/#desc
HAProxy – They use it!: http://www.haproxy.org/they-use-it.html
Heartbeat: http://www.linux-ha.org/wiki/Main_Page
RAID Definition: http://searchstorage.techtarget.com/definition/RAID
Striping: http://searchstorage.techtarget.com/definition/disk-striping
RAID Battery Backup Units: https://www.thomas-krenn.com/en/wiki/Battery_Backup_Unit_(BBU/BBM)_Maintenance_for_RAID_Controllers
High-Availability – VRRP, HSRP, GLBP: http://www.freeccnastudyguide.com/study-guides/ccna/ch14/vrrp-hsrp-glbp/
Understanding VRRP: http://www.juniper.net/techpubs/en_US/junos/topics/concept/vrrp-overview-ha.html
Configuring VRRP: http://www.cisco.com/c/en/us/td/docs/ios-xml/ios/ipapp_fhrp/configuration/15-mt/fhp-15-mt-book/fhp-vrrp.html
Configuring GLBP: http://www.cisco.com/c/en/us/td/docs/ios-xml/ios/ipapp_fhrp/configuration/xe-3s/fhp-xe-3s-book/fhp-glbp.html
Explaining the Uptime Institute’s Tier Classification System: https://journal.uptimeinstitute.com/explaining-uptime-institutes-tier-classification-system/