Non e ‘ormai un giorno Big data..’storia che ha dato origine a questa era di big data, ma’ Molto tempo fa ago ‘ gli esseri umani hanno iniziato a raccogliere informazioni tramite indagini manuali, siti web, sensori, file e altre forme di metodi di raccolta dei dati. Anche questo include organizzazioni internazionali come l’OMS, l’ONU che ha raccolto a livello internazionale tutte le possibili serie di informazioni per il monitoraggio e il monitoraggio delle attività non solo legate all’uomo ma alla vegetazione e alle specie animali per prendere decisioni importanti e attuare le azioni richieste.
Così grandi multinazionali specialmente le società di e-commerce e marketing hanno iniziato a utilizzare la stessa strategia per monitorare e monitorare le attività dei clienti per promuovere marchi e prodotti che hanno dato origine al ramo analytics. Ora non si saturerà così facilmente poiché le aziende hanno realizzato il vero valore dei dati per prendere decisioni fondamentali in ogni fase del progetto dall’inizio alla fine per creare le migliori soluzioni ottimizzate in termini di costi, quantità, mercato, risorse e miglioramenti.
I V dei Big Data sono volume, velocità, varietà, veridicità, valenza e valore e ogni impatto raccolta dei dati, monitoraggio, archiviazione, analisi e reporting. L’ecosistema in termini di giocatori di tecnologia del sistema big data è come si vede di seguito.

Ora voglio discutere di ogni tecnologia, uno per uno, per dare un assaggio di ciò che le componenti e le interfacce.
Come estrarre i dati dai dati dei social media da Facebook, Twitter e linkedin in un semplice file csv per ulteriori elaborazioni.
Per poter estrarre dati da Facebook utilizzando un codice python è necessario registrarsi come sviluppatore su Facebook e quindi avere un token di accesso. Ecco i passaggi per questo.
1. Vai al collegamento developers.facebook.com, crei un conto là.
2. Vai al collegamento developers.facebook.com/tools/explorer.
3. Vai al menu a discesa” Le mie app “nell’angolo in alto a destra e seleziona”aggiungi una nuova app”. Scegli un nome visualizzato e una categoria e quindi “Crea ID app”.
4. Di nuovo tornare allo stesso link developers.facebook.com/tools/explorer. Vedrai ” Graph API Explorer “sotto” Le mie app” nell’angolo in alto a destra. Dal menu a discesa” Graph API Explorer”, seleziona la tua app.
5. Quindi, seleziona “Ottieni token”. Da questo menu a discesa, seleziona “Ottieni token di accesso utente”. Selezionare autorizzazioni dal menu che appare e quindi selezionare ” Get Token di accesso.”
6. Vai al collegamento developers.facebook.com/tools/accesstoken. Selezionare “Debug” corrispondente a “Token utente”. Vai a “Estendere l’accesso ai token”. Ciò garantirà che il tuo token non scada ogni due ore.
Codice Python per accedere ai dati pubblici di Facebook:
Vai al link https://developers.facebook.com/docs/graph-api se vuoi raccogliere dati su tutto ciò che è disponibile pubblicamente. Vedere https://developers.facebook.com/docs/graph-api/reference/v2.7/. Da questa documentazione, scegliere qualsiasi campo desiderato da cui si desidera estrarre dati come “gruppi” o “pagine” ecc. Vai a esempi di codici dopo aver selezionato questi e quindi selezionare “facebook graph api” e otterrete suggerimenti su come estrarre le informazioni. Questo blog è principalmente su come ottenere i dati degli eventi.
Prima di tutto, importa ‘urllib3’, ‘facebook’, ‘requests’ se sono già disponibili. In caso contrario, scaricare queste librerie. Definisci un token variabile e imposta il suo valore su ciò che hai ottenuto sopra come “Token di accesso utente”.

Estrarre i dati da Twitter:
2 Semplici passaggi possono essere eseguiti come di seguito
- Si prestano a particolari di applicazione pagina; passare alla scheda “Chiavi e token di accesso”, scorrere verso il basso e fare clic su “Crea il mio token di accesso”. Nota i valori di API Key e API Secret per un uso futuro. Non condividerli con nessuno, si può accedere al tuo account se ottengono le chiavi.
- Per estrarre i tweet, è necessario stabilire una connessione sicura tra R e Twitter come segue,
#Clear R Environment
rm(list=ls())
#Load required libraries
install.pacchetti(“twitteR”)
installare.packages (“ROAuth”)
library (“twitteR”)
library (“ROAuth”)
# Scarica il file e archivia nella tua directory di lavoro
download.per maggiori informazioni clicca qui.pem”)
#Inserisci il tuo consumerKey e consumerSecret di seguito
credenziali < OAuthFactory$new(consumerKey=’XXXXXXXXXXXXXXXXXX’,
consumerSecret=’XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX’,
requestURL=’https://api.twitter.com/oauth/request_token’,
accessURL=’https://api.twitter.com/oauth/access_token’,
authURL=’https://api.twitter.com/oauth/authorize’)
cred$stretta di mano(cainfo=”cacert.pem”)
#Carica i dati di autenticazione
carica (“autenticazione Twitter.Rdata”)
#Registrare Twitter Autenticazione
setup_twitter_oauth(credenziali$consumerKey, le credenziali di$consumerSecret, le credenziali di$oauthKey, le credenziali di$oauthSecret)
#estrae il Tweet in questione con string(primo argomento), seguito dal numero di tweet (n) e la lingua (lang)
tweet < searchTwitter(‘#DataLove’, n=10, lang=”it”),
Ora è possibile cercare qualsiasi parola nella ricerca di Twitter funzione per estrarre i tweet contenenti la parola.
Estrazione dei dati da Oracle ERP
È possibile visitare il link per controllare passo dopo passo l’estrazione del file csv dal database oracle ERP cloud.
Acquisizione e archiviazione dei dati:
Ora, una volta che i dati vengono estratti, devono essere memorizzati ed elaborati, cosa che facciamo nella fase di acquisizione e archiviazione dei dati.
Vediamo come Spark, Cassandra, Flume, HDFS, HBASE funziona.
Spark
Spark può essere distribuito in vari modi, fornisce collegamenti nativi per i linguaggi di programmazione Java, Scala, Python e R e supporta SQL, streaming di dati, apprendimento automatico e elaborazione di grafici.
RDD è il framework per spark che aiuterà nell’elaborazione parallela dei dati dividendoli in frame di dati.
Per leggere i dati dalla piattaforma Spark, utilizzare il seguente comando
results = spark.sql (“Seleziona * da persone”)
nomi = risultati.mappa (lambda p: p.name)
Connettersi a qualsiasi fonte di dati come json, JDBC, Hive a scintilla utilizzando semplici comandi e funzioni. Come puoi leggere i dati json come di seguito
spark.Leggete.json (“s3n://…”).registerTempTable (“json”)
risultati = spark.sql (“SELECT * FROM people JOIN json …”)
Spark consiste in più funzionalità come lo streaming da fonti di dati in tempo reale che abbiamo visto sopra usando R e python source.
Nel sito web principale di apache spark puoi trovare molti esempi che mostrano come spark possa svolgere un ruolo nell’estrazione dei dati, nella modellazione.
https://spark.apache.org/examples.html
Cassandra:
Cassandra è anche una tecnologia Apache come spark per l’archiviazione e il recupero di dati e archiviazione in più nodi per fornire 0 tolleranza ai guasti. Utilizza normali comandi di database come creare, selezionare, aggiornare ed eliminare le operazioni. Inoltre è possibile creare indici , vista materializzata e normale con comandi semplici come in SQL. L’estensione è che puoi usare il tipo di dati JSON per eseguire operazioni aggiuntive come come visto di seguito
Inserisci in mytable JSON ‘{ “\”myKey\””: 0, “value”: 0}’
Fornisce driver open source git hub da utilizzare con.net, Python, Java, PHP, NodeJS, Scala, Perl, ROR.
Quando si configura il database, è necessario configurare il numero di nodi in base ai nomi dei nodi, allocare token in base al carico su ciascun nodo. È inoltre possibile utilizzare i comandi di autorizzazione e ruolo per gestire l’autorizzazione a livello di dati su un determinato nodo.
Per maggiori dettagli è possibile fare riferimento al collegamento specificato
http://cassandra.apache.org/doc/latest/configuration/cassandra_config_file.html
Casandra promette di raggiungere 0 tolleranza di errore in quanto fornisce più opzioni per gestire i dati su un dato nodo memorizzando nella cache, gestione delle transazioni, replica, concorrenza per lettura e scrittura, comandi di ottimizzazione del disco, gestire il trasporto
HDFS
Quello che mi piace di più di HDFS è la sua icona, un elefante jumbo potente e resiliente come HDFS stesso.
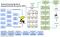
Come si vede nel diagramma di cui sopra, HDFS sistema per i big data è simile a come Cassandra, ma fornisce molto semplice interfacciamento con sistemi esterni.
I dati vengono tagliati in frame di dati di dimensioni diverse o simili che vengono memorizzati nel file system distribuito. I dati vengono ulteriormente trasferiti a vari nodi in base ai risultati delle query ottimizzati per memorizzare i dati. L’architettura di base è di modello centralizzato di Hadoop se Map reduce model.
1. I dati sono divisi in blocchi di dire 128 MB
2. Questi dati sono distribuiti su vari nodi
3. HDFS supervisiona l’elaborazione
4. La replica e la memorizzazione nella cache vengono eseguite per ottenere la massima tolleranza ai guasti.
5. dopo che map e reduce sono stati eseguiti e i lavori sono stati calcolati con successo, tornano al server principale
Hadoop è principalmente codificato in Java, quindi è fantastico se si mettono le mani su Java che sarà facile e veloce da configurare ed eseguire tutti quei comandi.
Una guida rapida per tutti i Hadoop concetto relativo, può essere trovato qui sotto il link
https://www.tutorialspoint.com/hadoop/hadoop_quick_guide.html
Creazione e Visualizzazione
Ora si Permette di parlare di SAS, R studio e Kime che sono utilizzati per l’analisi di grandi insiemi di dati con l’aiuto di algoritmi complessi che sono algoritmi di machine learning che sono basati su alcuni modelli matematici complessi che analizza set di dati completo e crea la rappresentazione grafica a frequentare desiderato obiettivo di business. Esempio di dati di vendita, potenziale di mercato dei clienti, utilizzo delle risorse, ecc.
SAS, R e Kinme tutti e tre gli strumenti offre una vasta gamma di funzionalità di analisi avanzata, IOT, machine learning, metodologie di gestione del rischio, security intelligence.
Ma dal momento che uno di essi è commerciale e altri 2 sono open source, hanno alcune importanti differenze tra loro.
Invece di passare attraverso ciascuno di essi uno per uno, ho riassunto ciascuna delle differenze software e alcuni consigli utili che parlano di loro.
