Di: Arshad Ali | Aggiornato: 2020-07-29 | Comments (6) / Related :More > JOIN Tables
Problem
Nel suggerimento SQL Server JoinExamples, Jeremy Kadlec ha parlato di diversi operatori logici di join, ma comes SQL Server li implementa fisicamente? Quali sono i diversi joinoperators fisici? In che modo sono diversi l’uno dall’altro e in quale scenario si preferiscesull’altro? In questo suggerimento, copriamo queste domande e altro ancora.
Soluzione
Usiamo operatori logici quando scriviamo query per definire una query relazionale a livello concettuale (cosa deve essere fatto). SQL implementa questi operatori logicicon tre diversi operatori fisici per implementare l’operazione definita dagli operatori logici (come deve essere eseguita). Anche se ci sono decine di physicaloperators, in questo suggerimento mi occuperò specifici operatori fisici join. Sebbene abbiamo diversi tipi di join logici a livello concettuale/query, ma SQL Serverimplements tutti con tre diversi operatori di join fisici come discusso di seguito.
Copriremo:
- Annidati Loop Join
- Unisci Join
- Hash Join
Guarderemo piani di esecuzione per vedere questi operatori e spiegherò perché ognuno si verifica.
Per questi esempi, sto usando il database AdventureWorks.
SQL Server annidati Loop Join Spiegato
Prima di scavare nei dettagli, lasciate che vi dica prima che cosa un annidati Loop joinis se siete nuovi al mondo della programmazione.
Un join di loop nidificati è una struttura logica in cui un ciclo (iterazione) risiede all’interno di un altro, vale a dire per ogni iterazione del ciclo esterno vengono eseguite / elaborate tutte le iterazioni del ciclo interno.
Un loop annidato join funziona allo stesso modo. Una delle tabelle di giunzione è designatatedas il tavolo esterno e un altro come il tavolo interno. Per ogni riga della tabella esterna, tutte le righe della tabella interna vengono abbinate una ad una se la riga matchesit è inclusa nel set di risultati altrimenti viene ignorata. Quindi la riga successiva dala tabella esterna viene raccolta e lo stesso processo viene ripetuto e così via.
L’ottimizzatore di SQL Server potrebbe scegliere un join di loop nidificati quando uno dei joiningtables è piccolo (considerato come la tabella esterna) e un altro è grande (considerato come la tabella interna che è indicizzata sulla colonna che si trova nel join) e quindi richiede I / O minimi e il minor numero di confronti.
L’ottimizzatore considera tre varianti per un join di loop nidificati:
- ingenuo nested loop join nel quale caso la ricerca scansthe intera tabella o di un indice
- index nested loop join quando la ricerca è possibile utilizzare anexisting indice per eseguire le ricerche
- indice temporaneo nested loop join se l’ottimizzatore createsa indice temporaneo come parte del piano di query e la distrugge dopo query executioncompletes
Un indice Nested Loop join si comporta meglio di un merge join o hash join ifa piccolo set di righe in cui sono coinvolti. Considerando che, se è coinvolto un ampio set di righe, i loop testati join potrebbero non essere una scelta ottimale. I loop nidificati supportano quasi tutti i tipi di join tranne i join esterni giusti e completi, i semi-join giusti e gli anti-semijoins giusti.
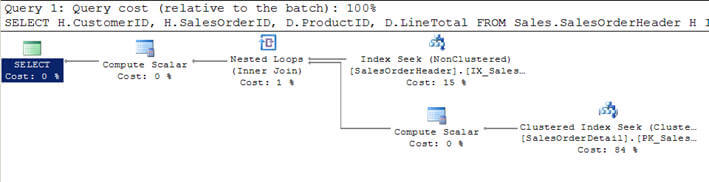
- Nello script #1, mi unisco alla tabella SalesOrderHeader con SalesOrderDetailtable e specificando i criteri per filtrare il risultato del cliente concustomerid = 670.
- Questo criterio filtrato restituisce 12 record dalla tabella SalesOrderHeader e quindi essendo quello più piccolo, questa tabella è stata considerata come tabella di theouter (quella superiore nel piano di esecuzione della query grafica)dall’ottimizzatore.
- Per ogni riga di queste 12 righe della tabella esterna, le righe dalla tabella interna SalesOrderDetail vengono abbinate (o la tabella interna viene scansionata 12 volte ogni volta per ogni riga utilizzando l’indice seek o correlatedparameter dalla tabella esterna) e 312 righe corrispondenti vengono restituite come puoi vedere nella seconda immagine.
- Nella seconda query qui sotto, sto usando SET STATISTICS PROFILE ON per visualizzare le informazioni sul profilo dell’esecuzione della query insieme al set di risultati della query.
Script #1 – Nested Loop Join Esempio
SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader H INNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID = 670
SET STATISTICS PROFILE ONSELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader HINNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderIDWHERE H.CustomerID = 670SET STATISTICS PROFILE OFF

Se il numero di record coinvolti è di grandi dimensioni, SQL Server potrebbe scegliere di parallelizea nested loop distribuendo esterno righe di una tabella in modo casuale tra i availableNested Loop thread in modo dinamico. Non si applica lo stesso per il tablerows interno però. Per saperne di più su parallel scansclicca qui.
SQL Server Merge Join Explained
La prima cosa che devi sapere su un Merge join è che richiede che entrambi gli input siano ordinati su join keys/merge columns (o entrambe le tabelle di input hanno clusteredindexes sulla colonna che unisce le tabelle) e richiede anche almeno un equijoin(uguale a) espressione / predicato.
Poiché le righe sono pre-ordinate, un Merge join inizia immediatamente il matchingprocess. Legge una riga da un input e la confronta con la riga di un altro input.Se le righe corrispondono, quella riga corrispondente viene considerata nel set di risultati (quindi legge la riga successiva dalla tabella di input, fa lo stesso confronto/corrispondenza e così via) orelse la minore delle due righe viene ignorata e il processo continua in questo modo fino a quando tutte le righe sono state elaborate..
Un Merge join si comporta meglio quando si uniscono tabelle di input di grandi dimensioni (pre-indicizzate / ordinate)poiché il costo è la somma delle righe in entrambe le tabelle di input rispetto ai NestedLoops dove è un prodotto di righe di entrambe le tabelle di input. A volte optimizerdecides utilizza un Unione quando le tabelle di input non sono ordinate e quindi utilizza un operatore fisico di ordinamento esplicito, ma potrebbe essere più lento rispetto all’utilizzo di un indice(tabella di input pre-ordinata).
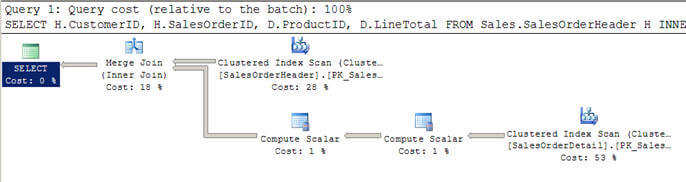
- Nello script #2, sto usando una query simile come sopra, ma questa volta ho aggiunto una clausola WHERE per ottenere tutti i clienti maggiori di 100.
- In questo caso, l’ottimizzatore decide di utilizzare un join di unione poiché entrambi gli input sono grandi in termini di righe e sono anche pre-indicizzati/ordinati.
- Puoi anche notare che entrambi gli input vengono scansionati una sola volta rispetto alle 12 scansioni che abbiamo visto nei loop nidificati sopra.
Script #2 – Merge Join Esempio
SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader H INNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID > 100
SET STATISTICS PROFILE ONSELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader HINNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderIDWHERE H.CustomerID > 100SET STATISTICS PROFILE OFF

Un Merge join è spesso un più efficiente e veloce operatore di join se il sorteddata può essere ottenuto da un indice B-tree ed esegue quasi tutti joinoperations finché c’è almeno una parità predicato di join coinvolti. Italso supporta più predicati di join di uguaglianza purché le tabelle di input siano ordinate su tutte le chiavi di join coinvolte e siano nello stesso ordine.
La presenza di un operatore Scalare di calcolo indica la valutazione di un’espressione per produrre un valore scalare calcolato. Nella query di cui sopra sto selezionando LineTotalwhich è una colonna derivata, quindi è stata utilizzata nel piano di esecuzione.
SQL Server Hash Join Explained
Un Hash join viene normalmente utilizzato quando le tabelle di input sono piuttosto grandi e non esistono adequateindex su di esse. Un Hash join viene eseguito in due fasi; la fase di compilazione e la fase Probe e quindi l’hash join hanno due input, ovvero build input e probeinput. Il più piccolo degli input è considerato come input di build (per minimizzare il requisito di memoria per memorizzare una tabella hash discussa in seguito) e ovviamente l’altro è l’input probe.
Durante la fase di compilazione, le chiavi di unione di tutte le righe della tabella di compilazione vengono scansionate.Gli hash vengono generati e inseriti in una tabella hash in memoria. A differenza del join di unione, sta bloccando (non vengono restituite righe) fino a questo punto.
Durante la fase della sonda vengono scansionati i tasti di giunzione di ogni riga della tavola della sonda.Di nuovo gli hash vengono generati (utilizzando la stessa funzione hash di cui sopra) e confrontati con la tabella hash corrispondente per una corrispondenza.
Una funzione Hash richiede una quantità significativa di cicli della CPU per generare hash e risorse di memoria per memorizzare la tabella hash. Se c’è pressione di memoria, alcune delle partizioni della tabella hash vengono scambiate con tempdb e ogni volta che è necessario (sondare o aggiornare il contenuto) viene riportato nella cache.Per ottenere prestazioni elevate, l’ottimizzatore di query può parallelizzare un Hash join toscale meglio di qualsiasi altro join, per maggiori dettagli clicca qui.
Ci sono fondamentalmente tre diversi tipi di hash join:
- In-memory Hash Join nel qual caso è disponibile abbastanza memoria per memorizzare la tabella hash
- Grace Hash Join nel qual caso la tabella hash non può adattarsi alla memoria e alcune partizioni vengono riversate in tempdb
- Recursive Hash Join nel qual caso una tabella hash è così grandel’ottimizzatore deve usare molti livelli di unione join.
Per maggiori dettagli su questi diversi tipiclicca qui.
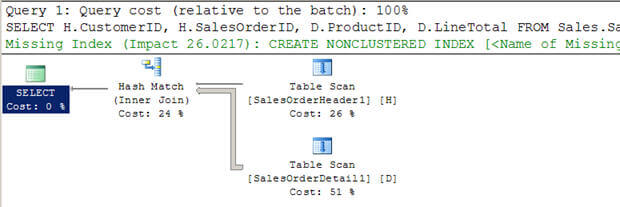
- Nello script #3, sto creando due nuove tabelle di grandi dimensioni (dagli AdventureWorkstables esistenti) senza indici.
- Puoi vedere che l’ottimizzatore ha scelto di utilizzare un Hash join in questo caso.
- Ancora una volta a differenza di un join di loop nidificati, non esegue la scansione della tabella interna più volte.
Script #3 – Hash Join Esempio
--Create tables without indexes from existing tables of AdventureWorks database SELECT * INTO Sales.SalesOrderHeader1 FROM Sales.SalesOrderHeader SELECT * INTO Sales.SalesOrderDetail1 FROM Sales.SalesOrderDetail GO SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader1 H INNER JOIN Sales.SalesOrderDetail1 D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID = 670 GO
SET STATISTICS PROFILE ON SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader1 H INNER JOIN Sales.SalesOrderDetail1 D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID = 670 SET STATISTICS PROFILE OFF

--Drop the tables created for demonstration DROP TABLE Sales.SalesOrderHeader1 DROP TABLE Sales.SalesOrderDetail1
Nota: SQL Server fa un buon lavoro nel decidere quale joinoperator per l’uso in ogni condizione. Comprendere queste condizioni ti aiuta a capirecosa si può fare nella messa a punto delle prestazioni. Non è consigliabile utilizzare i suggerimenti join (usingOPTION clause) per forzare SQL Server a utilizzare un operatore join specifico (a meno che non si abbia un’altra via d’uscita), ma è possibile utilizzare altri mezzi come l’aggiornamento delle statistiche,la creazione di indici o la riscrittura della query.
Passi successivi
- Recensioniserversql.
- ReviewLogical e operatori fisici Articolo di riferimento su technet.
Ultimo aggiornamento: 2020-07-29


 Arshad Ali is a SQL and BI Developer focusing on Data Warehousing projects for Microsoft.
Arshad Ali is a SQL and BI Developer focusing on Data Warehousing projects for Microsoft.View all my tips
- More Database Developer Tips…