この記事の目的は、コンピューティング、ネットワーキング、およびホスティングの面で冗長性を説明することです。 冗長性とは何か、それがどのように機能するかを説明するために、冗長技術ソリューションの実際の例を提供します。
Atlantic.Net 耐久性のあるクラウドプラットフォーム、高速VPSホスティング、HIPAA準拠のインフラストラクチャ、マネージドプライベートクラウドホスティングなど、複数のホ 私達のシステムすべては設計過程の第一次運転の要因として重複と造られる。
日常の英語では、冗長性は否定的な意味合いを持っているかもしれません。 しかし、クラウドホスティング環境では、冗長性は、シームレスなシステム可用性と不要または予期しないダウンタイムの違いを意味する可能性があ
冗長システムとは何ですか?
冗長システムは、予期しない障害が発生した場合にライブシステムを保護するために、フェールオーバーまたは負荷分散サポートを提供します。 電源障害、機械障害、またはソフトウェア障害の場合、冗長システムにはフォールバックするコンポーネントまたはプラットフォームが重複しています。 一般に、単一障害点を持つシステムのコンポーネントは、運用サービスのリスクと見なすことができます。
電源システムまたは機械システムは、同じタイプのサービスの別の存在だけを必要とするより単純なフォールバック戦略を持っています。
冗長性機能は、ビジネスクリティカルなシステムに推奨されますが、特にダウンタイム中に重大な影響を与えるシステムには推奨されません。 したがって、ビジネス継続性のために、そのデータベースを冗長性で保護することで、致命的な障害が発生した場合にデータの整合性を保護します。
冗長システムの種類
冗長システムは、同じ目的のために相互接続され、設計された少なくとも二つのシステムで構成されています。 利用可能な冗長システム構成には多くの異なるタイプがあり、システムの異なる実装は、システムを常に維持するための独自のアプローチを提供します。
すべてのサーバーを冗長性で構成する必要はありません。 どのサーバーがスコープ内にあるか、サーバーが処理できるダウンタイムの最大量を理解するために、詳細なリスク評価を強くお勧めします。 この評価を使用して、RTO(目標復旧時間)およびRPO(目標復旧時点)戦略を決定します。 RTOは、許容可能なダウンタイムの最大量です。 これは5秒から24時間まで及ぶことができます。 たとえば、ビジネスは最大24時間分のデータ損失で機能する可能性があります。
いくつかの一般的な例を次に示します。
- Active-Inactive/Hot-Cold–システムのあるコンポーネントがアクティブなシステムであり、別のコンポーネントが非アクテ 非アクティブなコンポーネントは、現在実行中のコンポーネントが故障した場合、またはメンテナンスを受けた場合にのみアクティブになります
- Active-Active/Hot-Hot–両方のシステムが稼働しており、接続を行っている場合。 これは、最も一般的にクラスタリングとして知られています。 通常、両方のマシンの前にあるデバイスは、着信トラフィックを分割する方法を決定します
- Active-Standby/Hot-Warm–両方のシステムがオンになっているが、一方だけ 第二のシステムは、プライマリシステムから定期的に更新またはバックアップを受信することを意図しています。 障害が発生した場合、スタンバイ状態のシステムは、最初のシステムを回復できるまで主な役割を果たします。
各タイプには独自の長所と短所があります。
- Active-Inactive/Hot-Coldシステムは単純な冗長プラットフォームを提供できますが、フェールオーバーすると、ユーザーに古いバージョンのシステムが表示されます。
- Active-Active/Hot-Hotは、すべてのユーザーがいずれかのシステムを使用できるように、手動または別のサービスを介して両方のシステムを一定の更新する必要があ このアプローチは、顧客に提供しているサービスのアクティブな負荷を大幅に減らすことができます。
- Active-Standby/Hot-Warmは、フェールオーバー時にアクティブなシステムの最新のコピーを使用してhot-coldのフェールオーバー機能を提供しますが、負荷イージングは提供しません。
より高い冗長性と堅牢な負荷分散ソリューションを可能にする複数ノード冗長性の他の形態が利用可能です。 この時点で、HAクラスターとも呼ばれる高可用性クラスターが作成されます。
これは、前述の冗長ソリューションの任意の組み合わせを使用して、必要な冗長性のアプローチまたは量に最大限の柔軟性を持つことができます。 HAクラスタは、インターネットバックボーンレベルまでの可用性を可能にするために、複数の物理的な場所にまたがって設定することもできます。
冗長ソフトウェアサービスの例
リソースの可用性が低いため、仮想環境で独自のレプリケーションや冗長サービスを設定しない理由はほとん すべてのクラウドサービスには、同じデータセンターまたは別のデータセンターリージョンにあるかどうかにかかわらず、あるノードから別のノードに任意のサー
Hyper-Vレプリカ
Hyper-Vレプリカは、ホットウォーム冗長性の一形態です。 プライマリ仮想マシンは1つの物理ホスト上に作成され、着信接続を受け入れます。 レプリケーションを有効にすると、新しいマシンの仮想ハードディスクが別の物理Hyper-Vホストに転送されます。 このホストは、アクティブなサーバーの最新のイメージが確実に取得されるように、ユーザー定義のスケジュールでレプリケートされるVMをそれ自体で構成します。 追加のチェックポイントポイントも保持することができます。 管理されたサービスとのHyper-Vの私用催すことはによって提供されますAtlantic.Net この機能を使用すると、詳細については当社のチームにお問い合わせください。
Hyper-Vクラスタリング
Hyper-Vは、他のHyper-Vホストへの接続を介してクラスタリングすることもできます。 任意のHyper-Vホスト上のvmをその単一ホスト上に一緒にクラスタ化して、仮想ネットワークを通じてローカルレベルで冗長性を提供できます。
Microsoft Network Load Balancing(NLB)を使用して、同じ情報を共有する複数のホストで構成される単一のリソースを作成し、ファイル共有のための簡単なアクセスポイントを提 これは利用可能なリソースの量によってのみ制限されるため、理論的には複数のVmを持つ複数のホストを設定して冗長性を最大限に高めることがで 管理されたサービスとのHyper-Vの私用催すことはによって提供されますAtlantic.Net この機能を使用すると、詳細については当社のチームにお問い合わせください。
HAProxy
Hyper-Vのほかに、ファイアウォールなどのゲートウェイデバイスをフェールオーバーや負荷分散サービスに使用できます。 例えば、大西洋。Netは、HAProxyとも呼ばれる高可用性プロキシをpfSenseに提供できます。
HAPROXYは、TCPおよびHTTPベースのアプリケーション用のロードバランサー、プロキシ、または単純なhot-warm高可用性ソリューションとして機能します。 HAProxyは、世界で最も訪問されたサイトのいくつかで使用される非常に人気のある、Linuxベースのオープンソースソリューションです。
Heartbeat
Heartbeatは、クラスター内のノードがまだ稼働しているか応答しているかを判断するために使用されるLinuxのほとんどのディストリビューションで利用 セットアップは非常に簡単で、TCP経由で動作する任意のシステムにフェールオーバー機能を提供します。
Heartbeatの開発者は、特定のホストがダウンしているかどうかに基づいてサービスを開始または停止する他のクラスタリソースマネージャも推奨します。 Heartbeatにはこれが含まれていますが、他の管理者も利用できます。 Heartbeatのシンプルさのために、それは高度にカスタマイズ可能です。 によって提供されるクラウドホスティングプラットフォームAtlantic.Net すでにこの機能が組み込まれており、必要に応じて独自のプライベートLinuxディストリビューションでHeartbeatを実装するのを支援できます。
冗長ハードウェアサービスの例
冗長ハードウェアについての最良の部分は、そのシンプルさです。 ソフトウェアサービスは過度の構成を必要とし、おそらく非常に敏感ですが、ハードウェアは通常、セットアップが非常に簡単で、非常に耐久性があ 最初に見る例は、広く使用されているRAID技術です。
RAID
RAIDはRedundant Array of Independent Disks(またはRedundant Array of Inexpensive Disks)の略で、データ保護またはディスクI/Oの増加のために複数のレベルが使用されています。
RAIDは、ソフ コントローラには、RAIDディスクを管理するために必要なソフトウェアと構成があります。 構成は、追加の構成をほとんどまたはまったく使用せずに、異なるシステムにエクスポートすることができます。
RAIDは、両方の品質をバランスよく提供するために、いくつかの異なる方法で設定できます。
- RAID0–これは本質的に冗長性ではありません。 システム上のディスクはミラーリングを介してデータを共有しませんが、すべてのデータが各ディスクにストライプ化され、読み取り/書 各ドライブは、まだあなたが持っているでしょうより多くのスペースをRAID0に追加するより多くのドライブを意味し、その最大限にそれに提供され
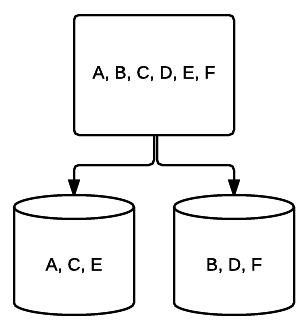
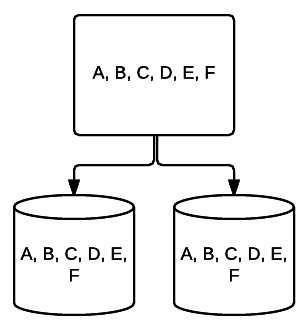
- RAID1–スペースを犠牲にして優れた冗長性を提供するミラーリングの基本的な形式。 2つのドライブシステムでは、一方のドライブ上のデータの完全なコピーが他方のドライブに書き込まれます。 この冗長性は、各ドライブが追加されると強化されます。 すべてのデータをすべてのドライブにミラーリングする必要があるため、システム上の合計容量は、システム内の最小ドライブの容量に制限されます。
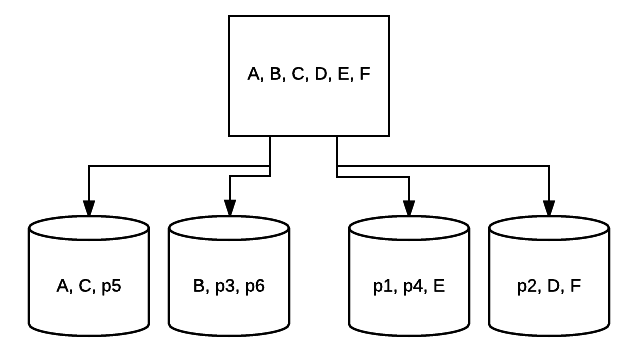
- RAID5–この形式のRAIDは、通常、読み取り速度と信頼性を向上させるために使用されます。 この場合、ストライプはシステム内の各ドライブの周りに配置され、最小は3つのドライブです。 同時に、エラー訂正データの余分なブロックは、パリティと呼ばれる技術で各ドライブの周りに配置されます。 これは、あるドライブから別のドライブに転送するときにデータが変更されているかどうかをチェックします。 これはまたこれらのドライブの1つが失敗でき、システムがまだ動くことができるので重複の最低の形態を提供する。 このタイプのRAIDセットアップに追加されたドライブが多いほど、読み取り速度が向上します。 すべてのドライブ間で最小の冗長性とストライピングを使用すると、このセットアップの合計容量は、論理RAIDボリュームのサイズに使用するドライブ数 たとえば、RAID5に500GBのドライブが5台ある場合、使用可能な2000GB、つまり2TBになります。(500 *(5-1)=2000).
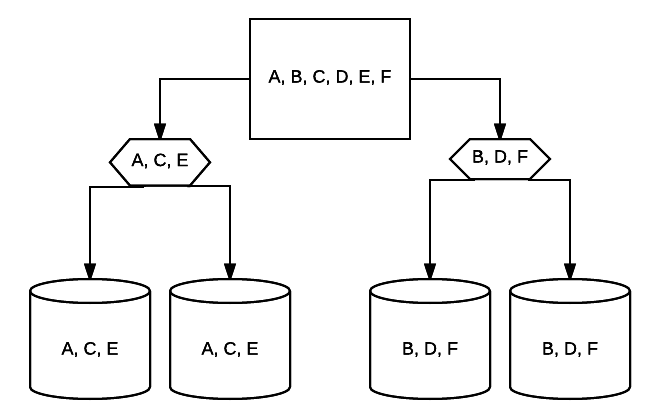
- RAID10–これはRAID1とRAID0の組み合わせです。 この場合、すべてのデータは各デバイスでストライプ化され、データのブロックもストライプ化されたシステム全体でミラー化されます。 たとえば、4ドライブRAID10システムでは、2つの500GBドライブに同じデータがある場合がありますが、システムが正常に動作するために必要なすべてのデー 他の2つのドライブのデータが必要になります。 各RAID1システムを単一のドライブと考え、それらの各システムをRAID0アレイに配置します。 この設定では、RAID0のようにパフォーマンスを大幅に向上させることができ、ミラーリングにはいくつかの冗長性が残っています。 システムがクラッシュする前に、システム内のドライブの半分までが故障する可能性がありますが、冗長アレイと同様に、できるだけ早くドライブを交換することをお勧めします。 Atlantic.Net すべてのSSDクラウドVPSストレージにRAID10を使用します。
追加された保護のために、RAIDコントローラは、電力損失などの場合にメモリに構成を保存するために使用されるROMチップに電力を供給するバッテリーバックアップユニットによって保護されている。 BBUは、パワーダウンされたシステムの一部であるRAIDアレイに少量の時間電力を供給し、RAIDコントローラのキャッシュの内容をそのまま維持することがで 情報が常にRAIDアレイに供給されており、ダウンタイムがデータの破損を引き起こす可能性がある場合、これは命の恩人になる可能性があります。したがって、物理システムとその中のサービスは、冗長的にかなり適切に構築できます。 しかし、あなたのシステムのどの部分へのあなたの接続はどうですか? のように、あなたのシステム全体へのあなたの直接インターネット接続?
ネットワーク冗長性
First Hop Redundancy Protocols(FHRP)
動的なゲートウェイ検出プロトコルとは対照的に、静的なゲートウェイはクライアントと適切なゲートウェイとの間で簡単なホップを可能にしますが、これにより単一障害点、すなわちゲートウェイ自体が作成されます。
ゲートウェイ障害の影響を防止または軽減するために、Fhrpが作成されました。 これらは、冗長ゲートウェイにフォールバックを提供するか、冗長性と一緒に、高トラフィックシステムのための負荷分散を提供します。 これらのプロトコルには、VRRP、HSRP、およびGLBPが含まれます。
Virtual Router Redundancy Protocol(VRRP)
VRRPは、イーサネットまたは光ファイバ接続を介して接続された少なくとも二つの物理的に別々のルータを必要とするルータに使用される冗長 このような状況では、静的ルートを含む”仮想ルータ”が作成され、各システム間で共有されます。
あるシステムは’マスター’と見なされ、別のシステムは’バックアップ’と見なされます。 マスターに障害が発生すると、バックアップが次のマスターとして引き継がれます。 これは、余分な冗長性のために複数のバックアップで設定することができます。 この概念は、バックアップシステムがマスターが利用可能かどうかを確認するという点でHeartbeatと非常に似ています。 応答を受信しないと、所定の時間が経過すると、バックアップは仮想スイッチの制御を引き受け、マスタースイッチ用に構成されたデフォルトIPに対
Hot Standby Router Protocol(HSRP)
HSRPはVRRPに似ていますが、このシナリオでは、設定された仮想スイッチは”スイッチ”ではなく、複数のルータの論理グループです。 グループのIPは、物理ホストに割り当てられていないIPです。 代わりに、グループにIPが割り当てられ、ルーターの1つが「アクティブ」ルーターであると判断されます。
スタンバイ-ルーターは、アクティブ-ルーターがダウンした場合に接続を取る準備ができています。 アクティブとスタンバイ以外のすべてのルータは、すべての行でその場所を決定するためにリッスンしています。 HSRPはCisco独自のプロトコルであり、フェールオーバーするタイミングを決定するデフォルトのタイマーなど、VRRPとの違いはほとんどありません。 HSRPは少し長くなっており、VRRPと比較してよりよく知られています。
Gateway Load Balancing Protocol(GLBP)
HSRPおよびVRRPに対するGLBPの主な利点は、余分な構成をほとんどまたはまったくせずにゲートウェイに冗長性を提供する上でロードバラン HSRPやVRRPと同様に、GLBPは物理ルータ間でグループを作成し、アクティブな仮想ゲートウェイ、つまりAVGを決定します。
グループ内のどのルータでも現在使用されていない仮想IPがAVGに割り当てられます。 その後、AVGは、グループ内の残りのルータ間で仮想MACアドレスを配布します。 各バックアップルーターは、アクティブな仮想フォワーダ、またはAVFと見なされます。 AVGに送信されるARP要求は、要求を送信するクライアントに異なる仮想MACアドレスを提供します。 その時点で、そのクライアントからグループの仮想IPへのトラフィックは、受信した仮想MACアドレスを持つルータに転送され、各ルータがぼんやりと座っているのではなく、引き続き使用できるようになります。AVGに障害が発生した場合、HSRPやVRRPと同様に優先順位ベースの選択が行われ、次のバックアップが実行され、通常どおり仮想MACアドレスが配布されます。 他のルータは元のAVGによって提供された仮想MACアドレスを保持しており、物事は通常どおり継続します。 いずれかのAvfに障害が発生した場合、AVGはその仮想MACアドレスへのトラフィックのルーティングを防止します。HSRPと同様に、GLBPはシスコ独自のFHRP形式です。
データセンターの冗長性
個人用サーバーまたはルーターの冗長性対策に加えて、データセンターはシステム障害に回復力があるように設計されています。 データセンターは、Uptime Instituteによって定義された階層に分類され、機械的障害またはサービス障害の障害に対するフォールトトレランスを提供し、可能な限り多くの稼働時間を可能にします。
データセンター内のすべてのクライアントに高可用性を提供するために、それぞれが相互に構築された四つの層があります。
- Tier I-基本容量: これには、データセンター運用のためのITグループ、電力使用量を監視およびフィルタリングする無停電電源装置(UPS)、および24/7を常に実行している専用の冷却装置のためのスペースが必要です。 これには、停電の場合の発電機も含まれる。
- Tier II–冗長容量コンポーネント:Tier Iが提供するすべてのものに加えて、施設への冗長電力と冷却。 これは余分UPSの単位か余分発電機を含むことができる。
- Tier III-同時に保守可能: すべての層IIは装置の取り替えまたは維持のための操業停止のための必要性を防ぐために余分装置と、提供する。 この層では、冗長電源と冷却がすべての技術機器に直接適用され、機器自体が冗長性またはシームレスなフェールオーバー用に構成されています。
- Tier IV–フォールトトレランス:Tier IIIが提供するすべてのものと、プロバイダレベルでの中断のないサービス。 データセンターには、都市または州のプロバイダーによって提供される電気または水道がある場合がありますが、データセンターによって利用される各サービスの二次回線が必要です。 これにはISPも含まれます。 クライアント機器に至るあらゆるセクションで障害が発生した場合、シームレスな移行のための準備が整ったバックアップ計画があります。
結論
冗長性は、必要性のためにit業界では日常的な用語となっています。 サービスの高可用性は、お客様に簡単で信頼性の高い体験を提供します。
サービスレベルでもデータセンターレベルでも、システムに冗長性を提供することは、取り組むべき重要で困難な問題です。 このホワイトペーパーでは、利用可能なオプションについていくつかの光を当てており、今後の高可用性に関する決定に役立つことを願っています。
を活用する準備ができてAtlantic.Netの冗長システム? ツつィツ姪”ツつ”ツ債ツづュツつケツつュツつセツつウツつ”ツ。Atlantic.Net冗長システムの基本概念:http://www.ni.com/white-paper/6874/en/
コールド/ウォーム/ホットサーバー:http://searchwindowsserver.techtarget.com/definition/cold-warm-hot-server
高可用性クラスタリング:https://www.mulesoft.com/resources/esb/high-availability-cluster
Hyper-Vレプリカ:https://www.mulesoft.com/resources/esb/high-availability-cluster
Hyper-Vレプリカ:https://www.mulesoft.com/resources/esb/high-availability-cluster
ハイパー Vレプリカ:https://www.mulesoft.com/resources/esb/high-availability-cluster
ハイパー Vレプリカ:https://www.mulesoft.com/resources/esb/high-availability-cluster
ハイパー Vレプリカ:https://www.mulesoft.com/resources/esb/high-availability-cluster(v=ws.11).aspx
Hyper-V and High Availability: https://technet.microsoft.com/en-us/library/hh127064.aspx
HAProxy Description: http://www.haproxy.org/#desc
HAProxy – They use it!: http://www.haproxy.org/they-use-it.html
Heartbeat: http://www.linux-ha.org/wiki/Main_Page
RAID Definition: http://searchstorage.techtarget.com/definition/RAID
Striping: http://searchstorage.techtarget.com/definition/disk-striping
RAID Battery Backup Units: https://www.thomas-krenn.com/en/wiki/Battery_Backup_Unit_(BBU/BBM)_Maintenance_for_RAID_Controllers
High-Availability – VRRP, HSRP, GLBP: http://www.freeccnastudyguide.com/study-guides/ccna/ch14/vrrp-hsrp-glbp/
Understanding VRRP: http://www.juniper.net/techpubs/en_US/junos/topics/concept/vrrp-overview-ha.html
Configuring VRRP: http://www.cisco.com/c/en/us/td/docs/ios-xml/ios/ipapp_fhrp/configuration/15-mt/fhp-15-mt-book/fhp-vrrp.html
Configuring GLBP: http://www.cisco.com/c/en/us/td/docs/ios-xml/ios/ipapp_fhrp/configuration/xe-3s/fhp-xe-3s-book/fhp-glbp.html
Explaining the Uptime Institute’s Tier Classification System: https://journal.uptimeinstitute.com/explaining-uptime-institutes-tier-classification-system/