今日の記事では、rolling and expanding windowsを見ていきます。
投稿の終わりまでに、あなたはこれらの質問に答えることができるようになります:
- ローリングウィンドウとは何ですか?
- 拡張ウィンドウとは何ですか?なぜ彼らは便利ですか?
ローリングウィンドウまたはエキスパンドウィンドウとは何ですか?h2>

ここには通常のウィンドウがあります。
私たちは外を垣間見ることをしたいので、通常の窓を使用しています。
また、一般的な経験則として、誰かの家の窓が大きければ大きいほど、株式ポートフォリオは良くなりました…
実際の窓のように、データ窓も私たちに大きなものを垣間見ることができます。
移動ウィンドウは、データのサブセットを調査することを可能にします。
ローリングウィンドウ
多くの場合、時系列データの統計的性質を知りたいのですが、すべてのタイムマシンがロズウェルにロックされているそれは私たちの研究に先読みバイアスを導入するでしょう。
それは私たちの研究に先読みバイアスを導入するでしょう。ここにその極端な例があります。
ここでは、フルサンプルに対するTSLA価格とその平均をプロットしました。
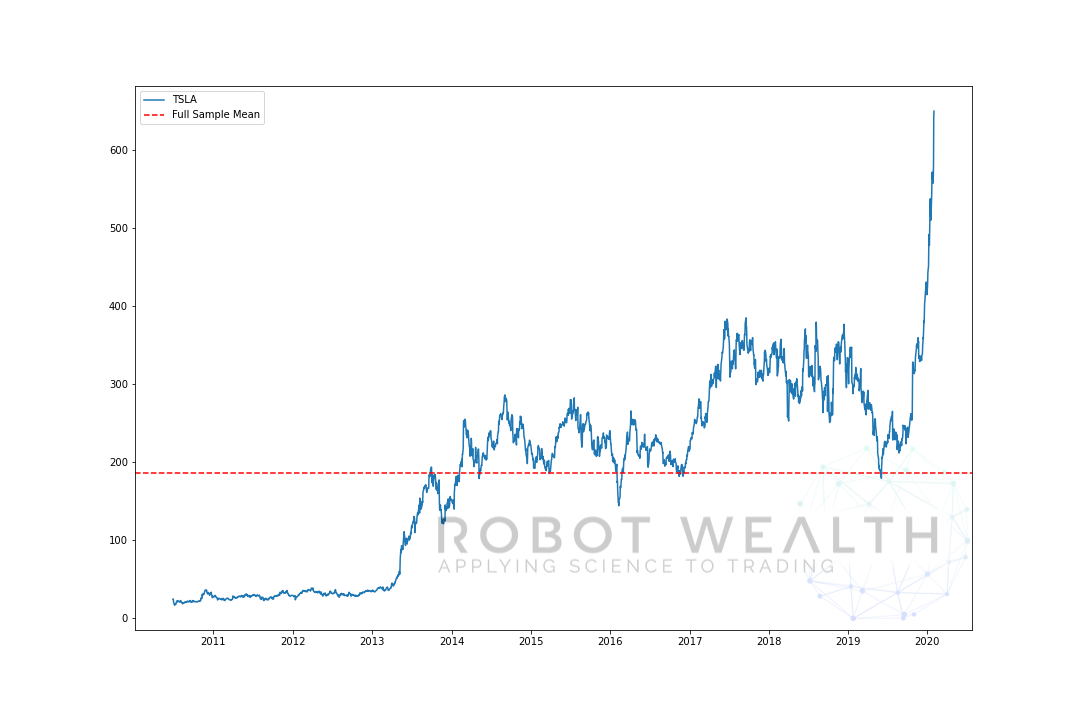
import pandas as pdimport matplotlib.pyplot as plt #Load TSLA OHLC df = pd.read_csv('TSLA.csv')#Calculate full sample meanfull_sample_mean = df.mean()#Plotplt.plot(df,label='TSLA')plt.axhline(full_sample_mean,linestyle='--',color='red',label='Full Sample Mean')plt.legend()plt.show()
この場合、価格が平均値を下回っていて、平均値を上回って販売したときにTSLAを購入しただけであれば、少なくとも2019年までは殺すことができたでしょう…
しかし、問題は、その時点で平均値を知らなかったということです。なぜサンプル全体を使用できないのかは明らかですが、次に何ができますか? この問題に対処する方法の1つは、ウィンドウの展開または展開を使用することです。
単純な移動平均を使用したことがある場合は、おめでとうございます–ローリングウィンドウを使用しました。
ローリングウィンドウはどのように動作しますか?h3>
20日間の在庫データがあり、過去5日間の在庫の平均価格を知りたいとしましょう。 あなたは何をしますか?p>
20日間の在庫データがあり、過去5日間の在庫の平均価格を知りたいとしましょう。 あなたは何をしますか?p>
あなたは最後の5日間を取り、それらを合計し、5で除算します。しかし、データセット内の各日の過去5日間の平均を知りたい場合はどうすればよいですか?p>
ローリングウィンドウが助けることができる場所です。
この場合、ウィンドウのサイズは5で、各時点に最後の5つのデータポイントの平均が含まれています。
サイズが5の移動ウィンドウの例を段階的に視覚化してみましょう。
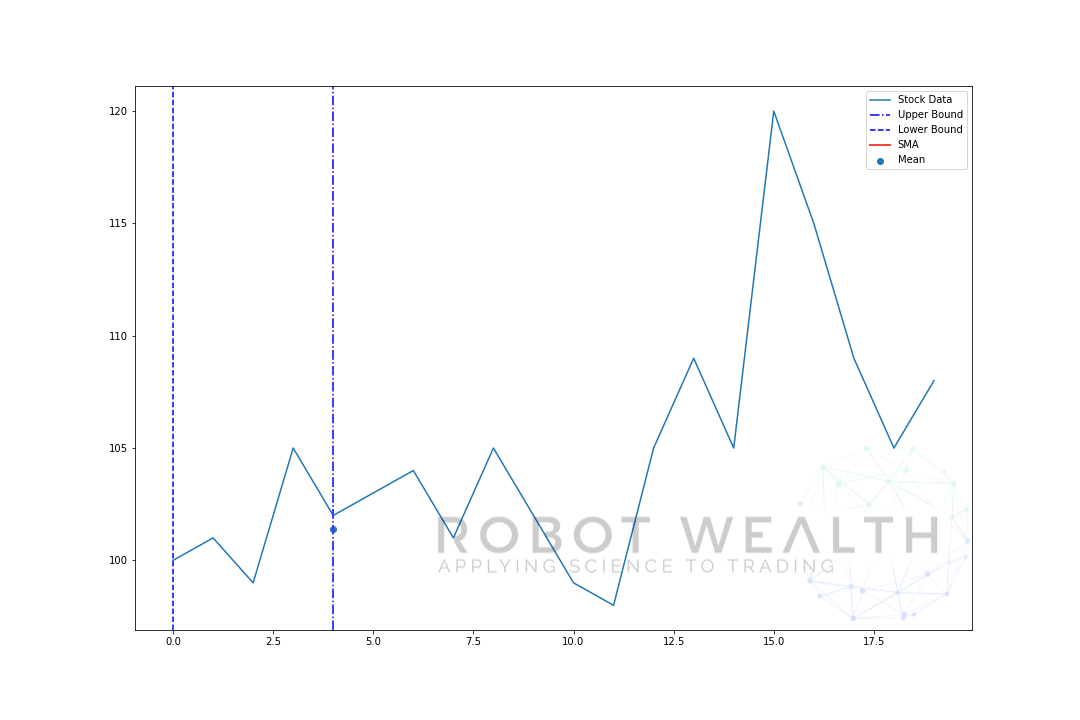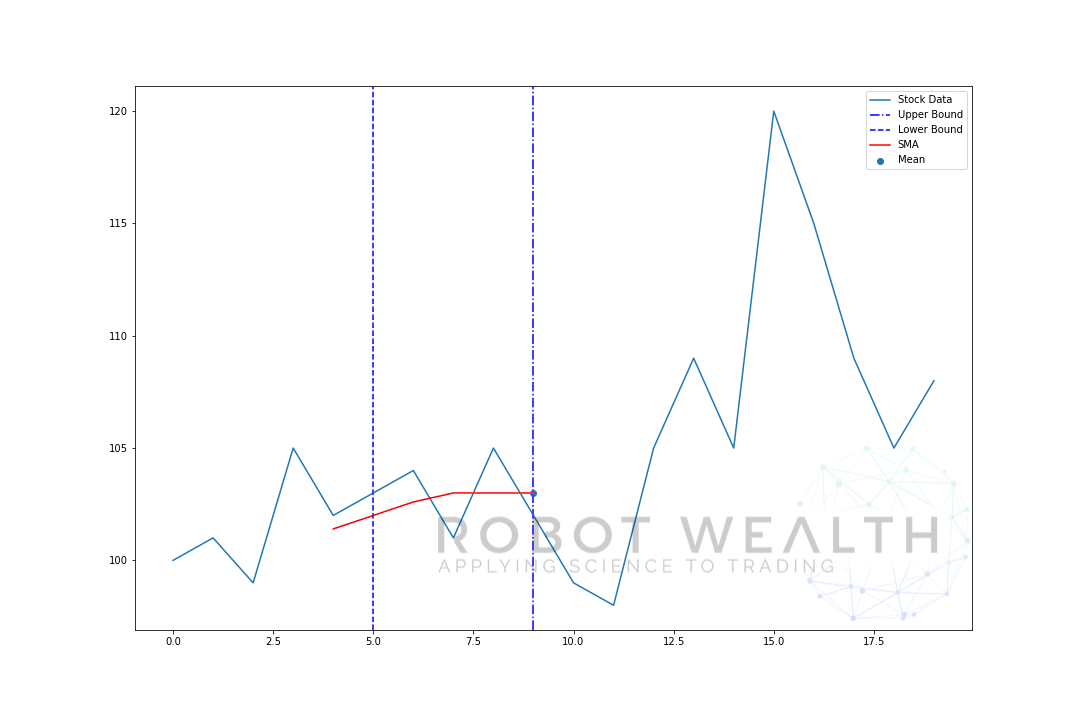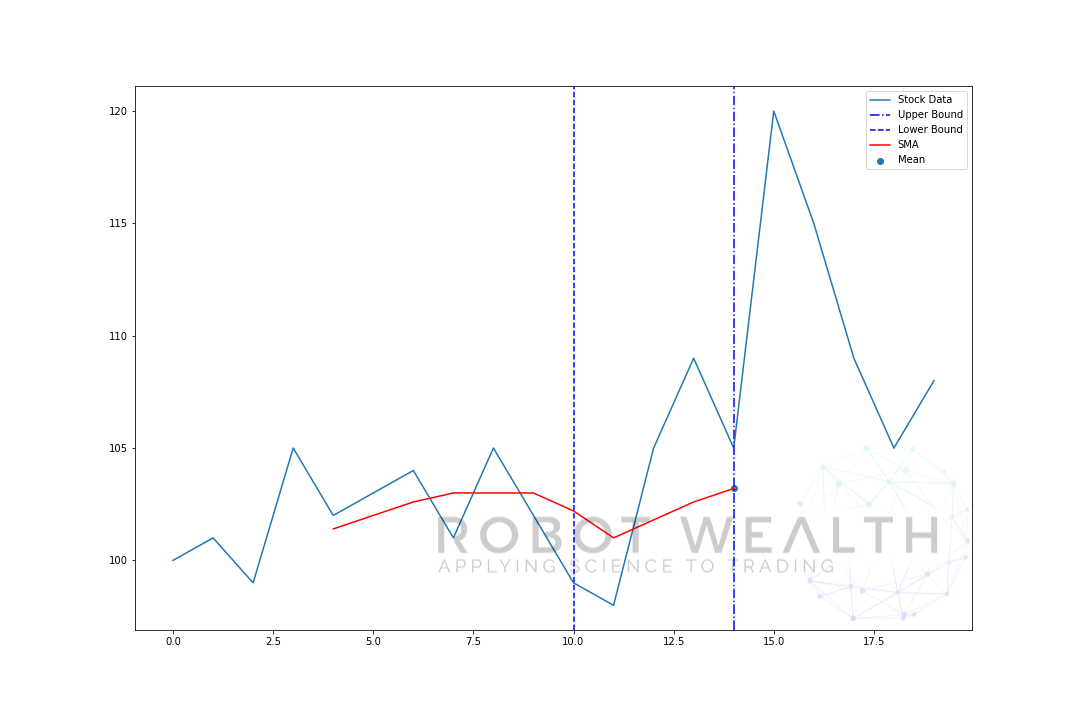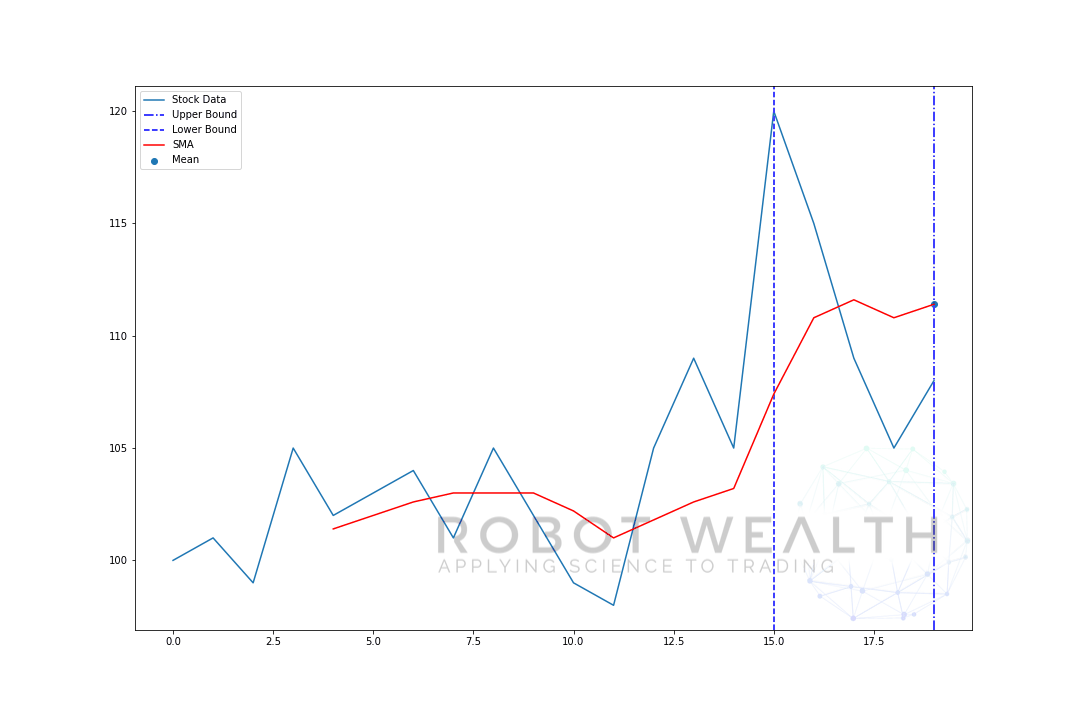
#Random stock pricesdata = #Create pandas DataFrame from listdf = pd.DataFrame(data,columns=)#Calculate a 5 period simple moving averagesma5 = df.rolling(window=5).mean()#Plotplt.plot(df,label='Stock Data')plt.plot(sma5,label='SMA',color='red')plt.legend()plt.show()
このチャートを内訳にしましょう。
- このチャートには20日間の株価データがあります。
- 各時点(青い点)について、5日間の平均価格を知りたいと思います。
- 計算に使用される在庫データは、2つの青い縦線の間のものです。
- 0-5から平均を計算した後、5日目の平均が利用可能になります。
- 6日目の平均を取得するには、ウィンドウを1ずつシフトする必要があるため、データウィンドウは1-6になります。
そして、これはローリングウィンドウとして知られているものであり、ウィンドウのサイズは固定されています。 私たちがやっているのは、それを前進させることだけです。あなたはおそらく気づいているように、我々はポイント0-4のSMA値を持っていません。
これは、ウィンドウサイズ(ルックバック期間とも呼ばれます)が計算を行うために少なくとも5つのデータポイントを必要とするためです。
展開ウィンドウ
ローリングウィンドウが固定サイズであり、展開ウィンドウが固定された開始点を持ち、利用可能になると新しいデータをここで私はこれについて考えるのが好きな方法です:
“この時点での過去のn値の平均は何ですか?
“この時点での過去のn値の平均は何ですか?
“この時点での過去のn値の平均は何ですか?”-ここで圧延窓を使用してください。
“この時点までに利用可能なすべてのデータの平均は何ですか?”-ここで拡張ウィンドウを使用してください。
展開ウィンドウの下限は固定されています。 ウィンドウの上限のみがロールフォワードされます(ウィンドウが大きくなります)。
前のプロットと同じデータで展開ウィンドウを視覚化しましょう。p>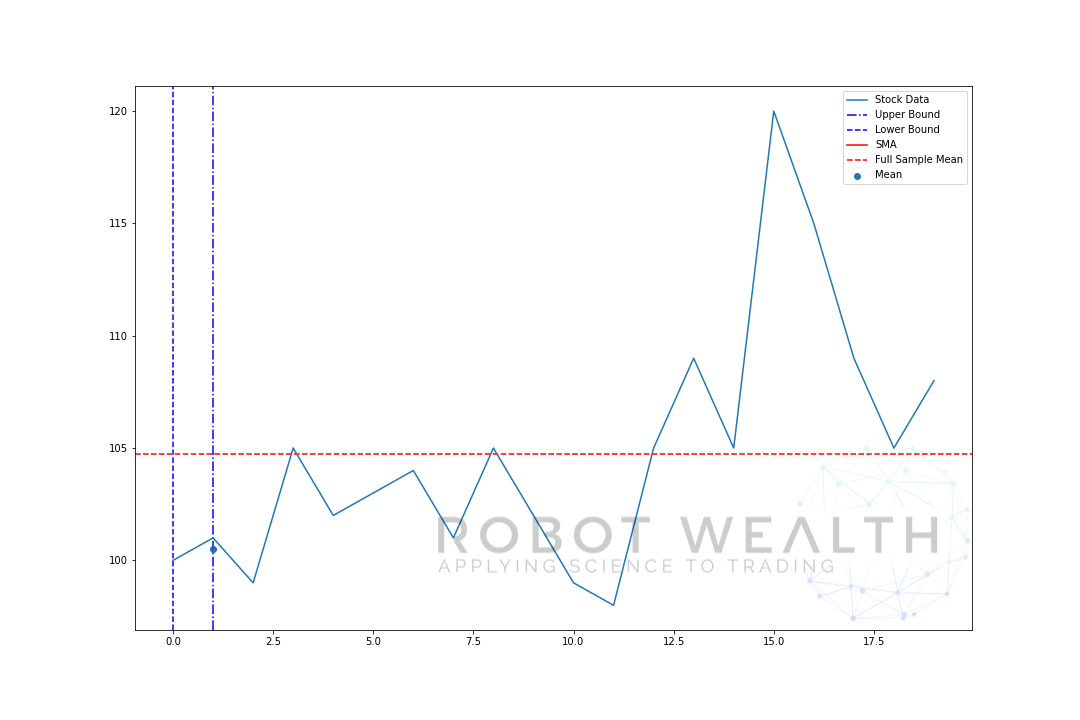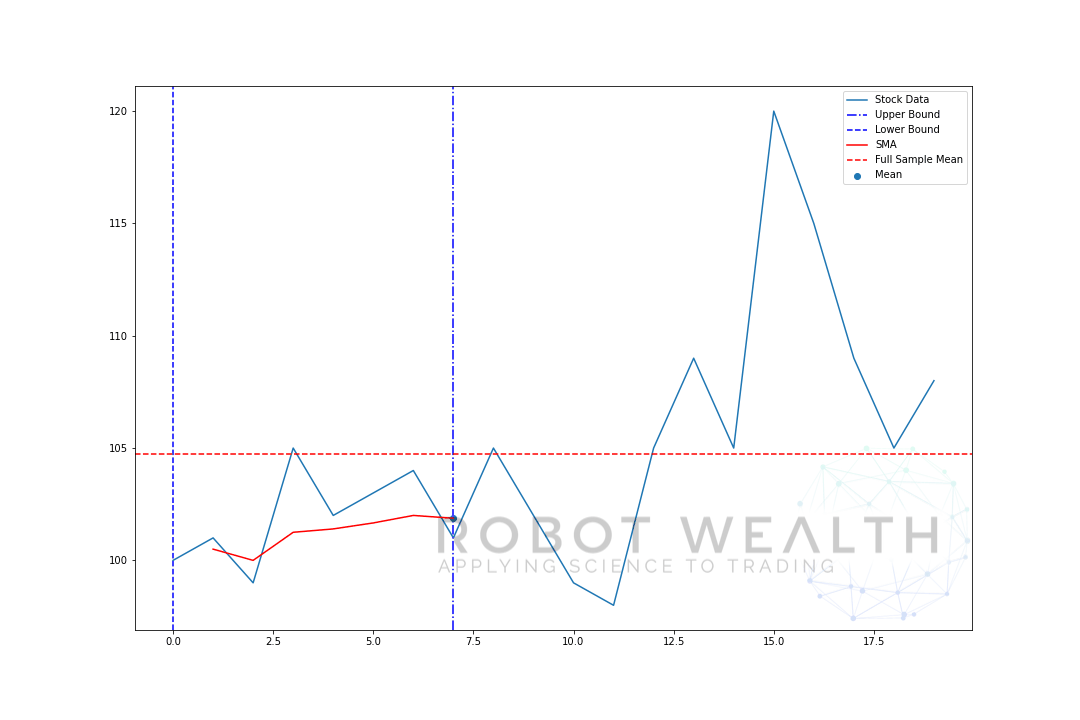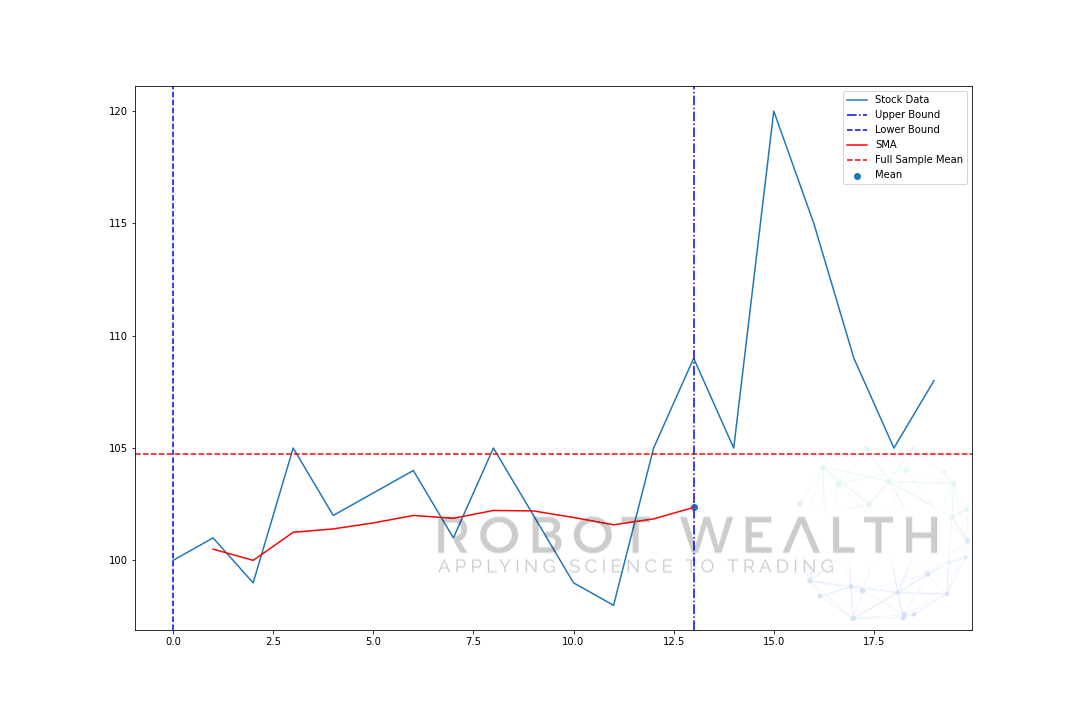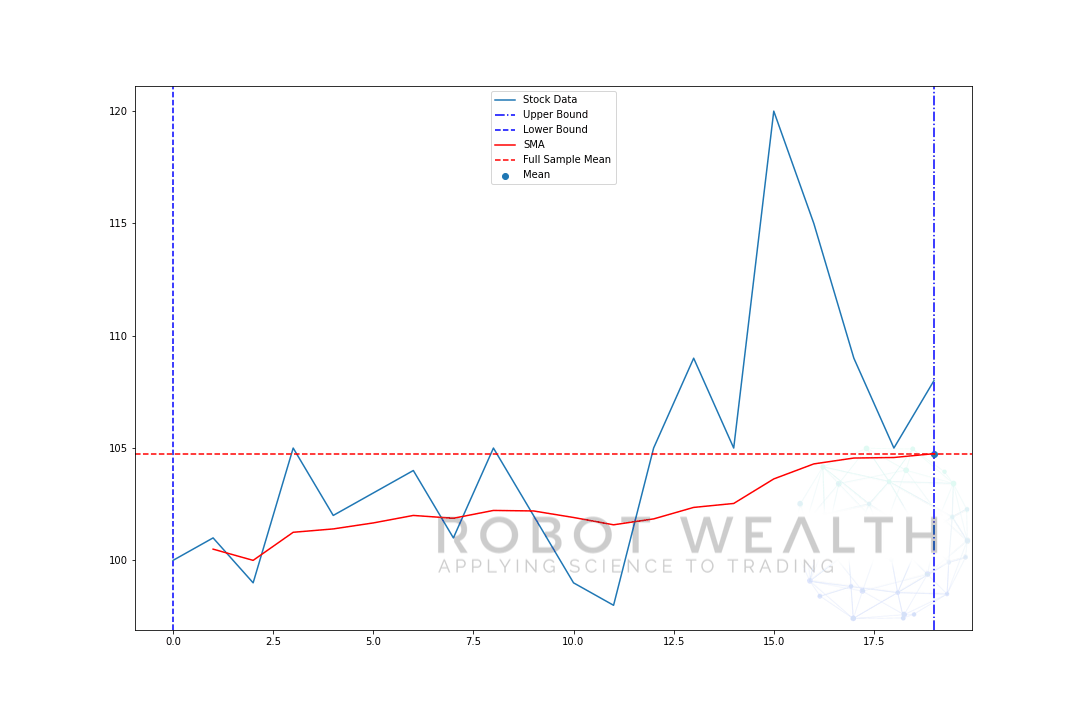
#Random stock prices data = #Create pandas DataFrame from list df = pd.DataFrame(data,columns=) #Calculate expanding window meanexpanding_mean = df.expanding(min_periods=1).mean()#Calculate full sample mean for referencefull_sample_mean = df.mean()#Plot plt.plot(df,label='Stock Data') plt.plot(expanding_mean,label='Expanding Mean',color='red')plt.axhline(full_sample_mean,label='Full Sample Mean',linestyle='--',color='red')plt.legend()plt.show()
最初は、SMAが少し不安定であることがわかります。 これは、プロットの先頭にあるデータポイントの数が少なく、データが多くなるにつれて、ウィンドウがデータセット全体のサイズに達したため、最終的に拡
概要
過去のデータを分析するために未来のデータを使用しないことが重要です。 ウィンドウの展開と展開は、これらの問題を回避するために「データを前進させる」ために不可欠なツールです。
これが好きなら、おそらくこれらも好きになるでしょう…
Quantトレーダーのためのdplyrでの財務データ操作
定量的取引戦略でデジタル信号処理を使用する
定量的な取引戦略でのデジタル信号処理を使用する
定量的な取引戦略でのデジタル信号処理を使用する
iv id=”
バックテストバイアス:あなたが爆破するまで、良い感じ
バックテストバイアス:あなたが爆破