By:Arshad Ali|Updated:2020-07-29|Comments(6)|Related:More>JOIN Tables
Problem
ヒントSQL Server JoinExamplesでは、Jeremy Kadlecは異なる論理結合演算子につい 別の物理的なjoinoperatorsは何ですか? 彼らはどのようにお互いに異なっており、どのようなシナリオが好まれていますか他の人よりも? このヒントでは、これらの質問などをカバーしています。
Solution
クエリを記述するときに論理演算子を使用して、概念的なレベル(何をする必要があるか)でリレーショナルクエリを定義します。 SQLは、これらの論理演算子を3つの異なる物理演算子で実装し、論理演算子によって定義された操作を実装します(どのように行う必要があるか)。 数十のphysicaloperatorsがありますが、このヒントでは特定のphysical join演算子について説明します。 概念的/クエリレベルではさまざまな種類の論理結合がありますが、SQL Serverでは、以下で説明するように、3つの異なる物理結合演算子を使用してそれら
私たちはカバーします:
- ネストされたループ結合
- マージ結合
- ハッシュ結合
私たちは、これらの演算子を見るためにexecution計画を見ていきます。これらの例では、AdventureWorksデータベースを使用しています。
SQL Server Nested Loops Join Explained
詳細を掘り下げる前に、プログラミングの世界に慣れていない場合は、ネストされたループjoinisが何であるかを最初に教えてくださ
ネストされたループ結合は、あるループ(反復)が別のループの内側に存在する論理構造であり、すなわち、外側のループの反復ごとに、内側のループのすべての反復が実行/処理されるということである。
ネストされたループ結合は同じように機能します。 結合テーブルの1つが指定されています外側のテーブルとして、もう1つが内側のテーブルとして指定されています。 Outertableの各行について、行matchesitが結果セットに含まれている場合、内部テーブルのすべての行が1つずつ一致します。 次に、次の行外側のテーブルがピックアップされ、同じプロセスが繰り返されます。
Joiningtablesの1つが小さい場合(外部テーブルと見なされます)、もう1つが大きい場合(結合内の列にインデックスが付けられた内部テーブルと見なされます)、henceitが最小のI/Oと最小の比較を必要とする場合、Sql Serverオプティマイザはネストされたループ結合を選択する可能性があります。
オプティマイザは、ネストされたループ結合の三つのバリアントを考慮します:
- naive nested loops joinこの場合、検索はテーブル全体またはインデックスをスキャンします。
- インデックスnested loops join検索で既存のインデックスを使用して検索を実行できる場合。
- 一時インデックスnested loops joinオプティマイザがクエリプランの一部として一時インデックスを作成し、クエリの実行完了後に破棄する場合。
インデックスNested Loops joinは、行の小さなセットが含まれている場合、マージ結合またはハッシュ結合よりも優れています。 一方、大きな行のセットが含まれている場合は、ループ結合は最適な選択ではない可能性があります。 ネストされたループは、rightおよびfull outer join、right semi-joinおよびright anti-semijoinsを除くほぼすべてのjoin型をサポートします。スクリプト#1では、SalesOrderHeaderテーブルをSalesOrderDetailtableに結合し、customer withCustomerID=670の結果をフィルタリングする基準を指定しています。
スクリプト#1-ネストされたループの結合例
SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader H INNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID = 670
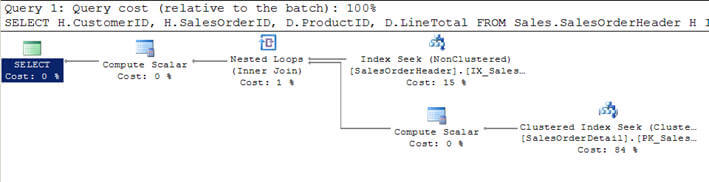
SET STATISTICS PROFILE ONSELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader HINNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderIDWHERE H.CustomerID = 670SET STATISTICS PROFILE OFF
SET STATISTICS PROFILE ONSELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader HINNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderIDWHERE H.CustomerID = 670SET STATISTICS PROFILE OFF
SET STATISTICS PROFILE ONSELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader HINNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderIDWHERE H.CustomerID = 670SET STATISTICS PROFILE OFF
関連するレコードの数が多い場合、sql serverは、availablenested loopsスレッド間で外部テーブルの行をランダムに分散させることによって、ネストされたループスレッドを動的に並列化することを選択する可能性があります。 しかし、内側のtablerowsには同じことは適用されません。 並列scansclickの詳細については、ここをクリックしてください。
SQL Server Merge Join Explained
マージ結合について最初に知っておく必要があるのは、結合キー/マージ列でソートする両方の入力が必要であることです(または両方の入力
行は事前にソートされているため、マージ結合はすぐにmatchingprocessを開始します。 ある入力から行を読み取り、別の入力の行と比較します。行が一致する場合、その一致した行は結果セットで考慮されます(入力テーブルから次の行を読み取り、同じ比較/一致などを行います)。.
マージ結合は、両方の入力テーブルの行の積であるNestedLoopsとは対照的に、コストが両方の入力テーブルの行の合計であるため、大きな入力テーブル(事前にイン Optimizerdecidesは、入力テーブルがソートされていない場合にマージ結合を使用することがあり、明示的なソート物理演算子を使用しますが、インデックス(事前ソートされた入スクリプト#2では、上記と同様のクエリを使用していますが、今回はWHERE句を追加して、100を超えるすべての顧客を取得しました。
SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader H INNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID > 100
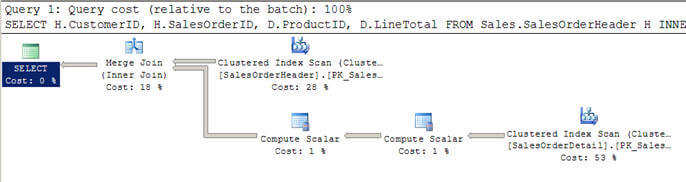
SET STATISTICS PROFILE ONSELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader HINNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderIDWHERE H.CustomerID > 100SET STATISTICS PROFILE OFF
SET STATISTICS PROFILE ONSELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader HINNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderIDWHERE H.CustomerID > 100SET STATISTICS PROFILE OFF

マージ結合は、sorteddataが既存のbツリーインデックスから取得でき、少なくとも一つの等式結合述語が関与している限り、ほぼすべてのjoinoperationsを実行 Italsoは、入力テーブルが関連するすべての結合キーでソートされ、同じ順序である限り、複数の等値結合述語をサポートします。
計算スカラー演算子の存在は、計算されたスカラー値を生成する式の評価を示します。 上記のクエリでは、派生列であるLineTotalwhichを選択しているため、実行計画で使用されています。
SQL Server Hash Join Explained
ハッシュ結合は、通常、入力テーブルが非常に大きく、適切なインデックスが存在しない場合に使用されます。 ハッシュ結合は2つのフェーズで実行されます; ビルドフェーズとプローブフェーズ、したがってハッシュ結合には2つの入力、つまりビルド入力とprobeinputがあります。 入力の小さい方がビルド入力と見なされ(後述するハッシュテーブルを格納するためのthememory要件を最小限に抑えるため)、明らかにotheroneはprobe入力です。
ビルドフェーズ中に、ビルドテーブルのすべての行の結合キーがスキャンされます。ハッシュは生成され、メモリ内のハッシュテーブルに配置されます。 マージ結合とは異なり、この時点まではブロックされています(行は返されません)。
プローブフェーズ中に、プローブテーブルの各行の結合キーがスキャンされます。再びハッシュが生成され(上記と同じハッシュ関数を使用して)、一致する対応するハッシュテーブルと比較されます。
ハッシュ関数は、ハッシュテーブルを格納するためのハッシュとメモリリソースを生成するためにかなりの量のCPUサイク メモリの負荷がある場合、ハッシュテーブルのパーティションの一部がtempdbに交換され、必要があるときはいつでも(内容をプローブまたは更新するために)キャ高いパフォーマンスを実現するために、クエリオプティマイザーは、他のどの結合よりも優れたハッシュ結合を並列化することができます。詳細については、ここをクリックしてください。
ハッシュ結合には基本的に三つの異なるタイプがあります。
- メモリ内ハッシュ結合ハッシュテーブルを格納するために十分なメモリが利用可能である場合
- グレースハッシュ結合ハッシュテーブルがメモリ内に収まらず、一部のパーティションがtempdbにこぼれている場合
- 再帰ハッシュ結合ハッシュテーブルが非常に大きい場合オプティマイザは多くのレベルのマージ結合を使用する必要があります。
これらの異なるタイプの詳細については、ここをクリックしてください。スクリプト#3では、インデックスなしで(既存のAdventureWorkstablesから)2つの新しい大きなテーブルを作成しています。
--Create tables without indexes from existing tables of AdventureWorks database SELECT * INTO Sales.SalesOrderHeader1 FROM Sales.SalesOrderHeader SELECT * INTO Sales.SalesOrderDetail1 FROM Sales.SalesOrderDetail GO SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader1 H INNER JOIN Sales.SalesOrderDetail1 D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID = 670 GO
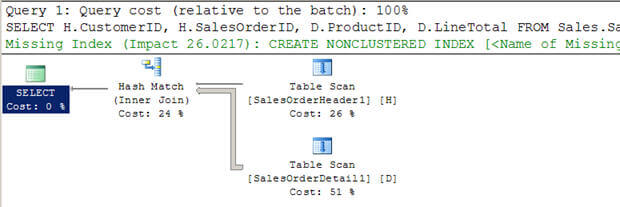
SET STATISTICS PROFILE ON SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader1 H INNER JOIN Sales.SalesOrderDetail1 D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID = 670 SET STATISTICS PROFILE OFF
SET STATISTICS PROFILE ON SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader1 H INNER JOIN Sales.SalesOrderDetail1 D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID = 670 SET STATISTICS PROFILE OFF
--Create tables without indexes from existing tables of AdventureWorks database SELECT * INTO Sales.SalesOrderHeader1 FROM Sales.SalesOrderHeader SELECT * INTO Sales.SalesOrderDetail1 FROM Sales.SalesOrderDetail GO SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader1 H INNER JOIN Sales.SalesOrderDetail1 D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID = 670 GO
--Create tables without indexes from existing tables of AdventureWorks database SELECT * INTO Sales.SalesOrderHeader1 FROM Sales.SalesOrderHeader SELECT * INTO Sales.SalesOrderDetail1 FROM Sales.SalesOrderDetail GO SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader1 H INNER JOIN Sales.SalesOrderDetail1 D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID = 670 GO
SET STATISTICS PROFILE ON SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader1 H INNER JOIN Sales.SalesOrderDetail1 D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID = 670 SET STATISTICS PROFILE OFF

--Drop the tables created for demonstration DROP TABLE Sales.SalesOrderHeader1 DROP TABLE Sales.SalesOrderDetail1
注:sql serverは、各条件で使用するjoinoperatorを決定する上でかなり良い仕事をしています。 これらの条件を理解することは、パフォーマンスチューニングで何ができるかを理解するのに役立ちます。 結合ヒント(usingOPTION句)を使用して、SQL Serverに特定の結合演算子を強制的に使用させることはお勧めしません(他の方法がない場合を除きます)が、統計の更新、イン
次の手順
- ReviewSQL ServerJoinサンプルヒント。
- ReviewLogical And Physical Operators Reference article on technet.
最終更新日: 2020-07-29


 Arshad Ali is a SQL and BI Developer focusing on Data Warehousing projects for Microsoft.
Arshad Ali is a SQL and BI Developer focusing on Data Warehousing projects for Microsoft.View all my tips
- More Database Developer Tips…