Het doel van dit artikel is om redundantie uit te leggen in termen van computers, netwerken en hosting. We zullen voorbeelden uit de praktijk van redundante technologieoplossingen geven om te illustreren wat redundantie is en hoe het werkt.
Atlantic.Net heeft meerdere hostingomgevingen gecreëerd, waaronder een duurzaam cloudplatform, high-speed VPS hosting, HIPAA compliant infrastructuur en beheerde private cloud hosting. Al onze systemen zijn gebouwd met redundantie als primaire drijfveer van het ontwerpproces.
in het alledaagse Engels kan redundantie een negatieve connotatie hebben; iets redundant is meestal niet nodig of als overbodig beschouwd. In een cloudhostingomgeving kan redundantie echter het verschil betekenen tussen naadloze beschikbaarheid van het systeem en ongewenste of onverwachte uitvaltijd.
- Wat Is een Redundant systeem?
- typen redundante systemen
- voorbeelden van redundante softwarediensten
- Hyper-V Replica
- Hyper-V Clustering
- HAProxy
- Heartbeat
- voorbeelden van redundante Hardwarediensten
- RAID
- Netwerkredundantie
- First Hop Redundancy Protocols (FHRP)
- Virtual Router Redundancy Protocol (VRRP)
- Hot Standby Router Protocol (HSRP)
- Gateway Load Balancing Protocol (GLBP)
- redundantie van datacenters
- conclusie
Wat Is een Redundant systeem?
een redundant systeem biedt ondersteuning voor failover of load balancing om een live systeem te beschermen in het geval van een onverwachte storing. In het geval van stroom -, mechanische of softwarefout, zal een redundant systeem een duplicaatcomponent of platform hebben om op terug te vallen. In het algemeen kan elk onderdeel van een systeem met één storingspunt worden gezien als een risico voor productiediensten.
Power-of mechanische systemen hebben eenvoudigere fall-back-strategieën die de aanwezigheid van een ander type service vereisen; softwarefailovers vereisen meestal extra configuratie op het hostsysteem of een master of gateway.
Redundantiemogelijkheden worden aanbevolen voor elk bedrijfskritisch systeem, maar in het bijzonder voor systemen die een significante impact hebben tijdens downtime. Sommige bedrijven kunnen al hun kritieke klantinformatie in een database houden; daarom, voor bedrijfscontinuïteitsdoeleinden, beschermt die database met redundantie de gegevensintegriteit in het geval van een catastrofale storing.
typen redundante systemen
een redundant systeem bestaat uit ten minste twee systemen die met elkaar zijn verbonden en voor hetzelfde doel zijn ontworpen. Er zijn veel verschillende soorten redundante systeemconfiguraties beschikbaar, en verschillende implementaties van het systeem bieden unieke benaderingen om een systeem te allen tijde up te houden.
niet alle servers hoeven met redundantie te worden geconfigureerd; in plaats daarvan moet alleen de meest kritische worden overwogen. We raden ten zeerste een gedetailleerde risicobeoordeling aan om te begrijpen welke servers in omvang zijn en hoeveel downtime uw servers maximaal aankunnen. Gebruik deze beoordeling om een RTO (Recovery Time Objective) en RPO (Recovery Point Objective) strategie te bepalen. RTO is de maximale hoeveelheid aanvaardbare downtime. Dit kan variëren van 5 seconden tot 24 uur. De RPO is het moment waarop u uw gegevens nodig hebt; uw bedrijf kan bijvoorbeeld functioneren met een maximaal verlies van 24 uur aan gegevens.
Hier zijn een paar populaire voorbeelden:
- actief-inactief / warm-koud – wanneer een component van een systeem het actieve systeem is en een ander inactief of afgesloten is. Het inactieve component wordt alleen geactiveerd als het huidige actieve onderdeel faalt of onderhoud ondergaat
- Active-Active / Hot-Hot-wanneer beide systemen live zijn en verbindingen maken. Dit is het meest bekend als clustering. Gewoonlijk zal het apparaat voor beide machines bepalen hoe inkomend verkeer
- actief-Standby / warm-Warm-wordt gesplitst wanneer beide systemen aan staan, maar slechts één maakt verbindingen. Het tweede systeem is bedoeld om periodiek updates of back-ups te ontvangen van het primaire systeem. In het geval van een storing neemt het systeem in stand-by de primaire rol op zich totdat het initiële systeem kan worden hersteld.
elk type heeft zijn eigen voor-en nadelen.
- actief-inactief / warm-koud systemen kunnen een eenvoudig redundant platform bieden, maar elke failover zal ertoe leiden dat gebruikers een oudere versie van het systeem zien.
- Active-Active / Hot-Hot vereist een constante update van beide systemen, handmatig of via een aparte service, om ervoor te zorgen dat alle gebruikers beide systemen kunnen gebruiken. Deze aanpak kan sterk verminderen de actieve belasting op een dienst die u aan klanten.
- Active-Standby / Hot-Warm zal de failover mogelijkheden van hot-cold voorzien van een meer up-to-date kopie van uw actieve systeem op de failover, maar het biedt geen load easing.
andere vormen van redundantie met meerdere knooppunten zijn beschikbaar die een grotere redundantie en robuuste oplossingen voor taakverdeling mogelijk maken. Op dat moment heb je een cluster met hoge beschikbaarheid, ook wel een HA-cluster genoemd.
Dit kan elke combinatie van de eerder genoemde redundantieoplossingen gebruiken met maximale flexibiliteit in de aanpak of de benodigde hoeveelheid redundantie. HA-clusters kunnen ook worden opgezet op meerdere fysieke locaties om beschikbaarheid mogelijk te maken tot het backbone-niveau van internet.
voorbeelden van redundante softwarediensten
Er is weinig reden om geen eigen replicatie of redundante diensten in een virtuele omgeving op te zetten; veel van dergelijke diensten zijn dus standaard beschikbaar in de meeste virtualisatiesystemen. Al onze cloudservices hebben replicatie beschikbaar, een functie waarmee we elke server van het ene knooppunt naar het andere kunnen repliceren, ongeacht of deze zich in hetzelfde datacenter of in afzonderlijke datacenterregio ‘ s bevinden.
Hyper-V Replica
Hyper-V Replica is een vorm van warm-warm redundantie. Een primaire virtuele machine wordt gemaakt op één fysieke host en accepteert inkomende verbindingen. Wanneer replicatie wordt ingeschakeld, worden de virtuele harde schijven van de nieuwe machine overgebracht naar een afzonderlijke fysieke Hyper-V-host. Deze host configureert vervolgens een VM op zichzelf die wordt gerepliceerd op een door de gebruiker gedefinieerd schema om ervoor te zorgen dat de meest recente image van de actieve server wordt gemaakt. Extra checkpoints punten kunnen ook worden gehouden. Hyper-V private hosting met managed services wordt geleverd door Atlantic.Net met deze functie gebakken in; neem contact op met ons team voor meer informatie.
Hyper-V Clustering
Hyper-V is ook in staat om te clusteren via een verbinding met andere Hyper-V hosts. VM ‘ s op elke Hyper-V-host kunnen op die enkele host worden geclusterd om redundantie op lokaal niveau te bieden via virtuele netwerken.
Microsoft Netwerktaakverdeling (netwerktaakverdeling) kan worden gebruikt om een enkele bron te maken die bestaat uit meerdere hosts die dezelfde informatie delen, om zo een eenvoudig toegangspunt te bieden voor het delen van bestanden. Aangezien dit alleen wordt begrensd door de hoeveelheid beschikbare bronnen, kunt u in theorie meerdere hosts met meerdere VM ’s instellen voor maximale redundantie, waardoor u ook onderhoud aan individuele VM’ s kunt uitvoeren zonder in te boeten op de beschikbaarheid van service of bronnen. Hyper-V private hosting met managed services wordt geleverd door Atlantic.Net met deze functie gebakken in; neem contact op met ons team voor meer informatie.
HAProxy
afgezien van Hyper-V, kan een gateway-apparaat zoals een firewall worden gebruikt voor failover-of taakverdelingsdiensten. Bijvoorbeeld Atlantic.Net kan pfSense voorzien van High Availability Proxy, ook bekend als HAProxy.
HAProxy zal fungeren als een load balancer, een proxy of een eenvoudige hot-warm high availability oplossing voor TCP en HTTP-gebaseerde toepassingen. HAProxy is een zeer populaire, op Linux gebaseerde open-source oplossing die wordt gebruikt door enkele van de meest bezochte sites in de wereld.
Heartbeat
Heartbeat is een service beschikbaar op de meeste distributies van Linux die wordt gebruikt om te bepalen of knooppunten in een cluster nog steeds actief zijn of reageren. Het is heel eenvoudig in te stellen en biedt failover-mogelijkheden voor elk systeem dat via TCP werkt.
De ontwikkelaars van Heartbeat raden ook andere cluster resource managers aan die services starten of stoppen op basis van het feit of een bepaalde host down is. Heartbeat heeft dit opgenomen, maar andere managers zijn beschikbaar. Door de eenvoud van Heartbeat is het zeer aanpasbaar. Cloud Hosting platforms aangeboden door Atlantic.Net heb deze functie al ingebouwd, en we kunnen u helpen met het implementeren van Heartbeat op uw eigen Linux-distributie, indien nodig.
voorbeelden van redundante Hardwarediensten
het beste deel van redundante hardware is de eenvoud. Hoewel softwarediensten overmatige configuratie vereisen en mogelijk heel gevoelig zijn, is de hardware meestal zeer eenvoudig in te stellen en ongelooflijk duurzaam. Het eerste voorbeeld dat we zullen bekijken is de veelgebruikte RAID-technologie.
RAID
RAID staat voor redundante Array van onafhankelijke schijven (of redundante Array van goedkope schijven, afhankelijk van hoe lang u het gebruikt) en heeft meerdere niveaus gebruikt voor gegevensbescherming of verhoogde schijf I/O.
RAID kan worden ingesteld via een software of hardware controller. De controller heeft de software en configuratie die nodig zijn om de RAID-schijven te beheren. De configuratie kan worden geëxporteerd naar verschillende systemen met weinig tot geen extra configuratie.
RAID kan op een paar verschillende manieren worden ingesteld om een goede balans van beide kwaliteiten te bieden:
- RAID 0-Dit is in wezen geen redundantie. Geen schijven op het systeem delen gegevens door middel van mirroring, maar alle gegevens worden over elke schijf gestreept met een verhoogde lees – / schrijfsnelheid. Elke schijf kan nog steeds gebruik maken van de opslag die aan het op zijn ruimst, wat betekent dat hoe meer schijven je toevoegt aan een RAID 0, hoe meer ruimte je hebt.
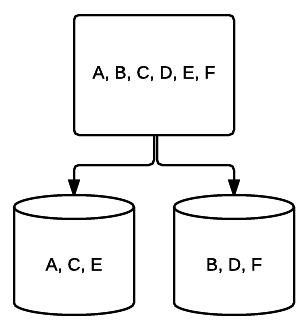
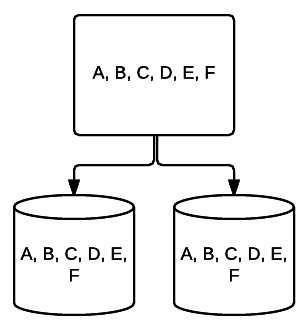
- RAID 1 – een basisvorm van spiegelen die uitstekende redundantie biedt ten koste van ruimte. In een systeem met twee aandrijvingen wordt een volledige kopie van de gegevens op de ene aandrijving naar de andere geschreven. Deze redundantie wordt verbeterd met elke schijf toegevoegd. Aangezien alle gegevens over alle schijven moeten worden gespiegeld, wordt de totale ruimte op het systeem beperkt tot alleen de ruimte van de kleinste schijf in het systeem.
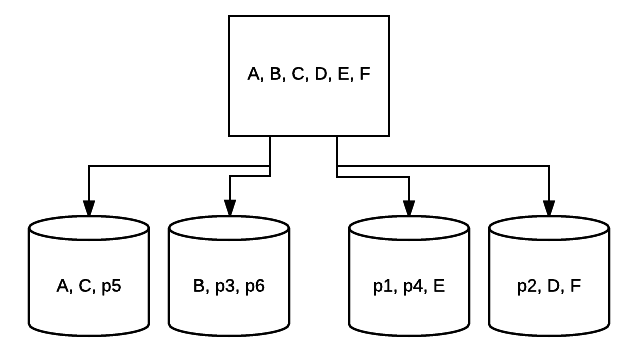
- RAID 5 – deze vorm van RAID wordt meestal gebruikt om de leessnelheid en betrouwbaarheid te verhogen. In dit geval worden strepen geplaatst over elke schijf in het systeem, met als minimum 3 schijven. Tegelijkertijd wordt een extra blok van foutcorrectiegegevens geplaatst over elke schijf in een techniek die pariteit wordt genoemd. Dit controleert of gegevens worden gewijzigd bij de overdracht van de ene schijf naar de andere. Dit zorgt ook voor een minimale vorm van redundantie aangezien 1 van deze schijven kan uitvallen en het systeem nog steeds kan draaien. Hoe meer schijven worden toegevoegd aan dit type RAID-setup, hoe meer je leessnelheid toeneemt. Met minimale redundantie en striping over alle schijven is de totale hoeveelheid ruimte in deze setup gelijk aan de grootte van uw logische RAID-volume maal het aantal schijven dat u gebruikt, min één. Bijvoorbeeld, als je 5 500 GB schijven hebt in een RAID 5, zou je 2000 GB bruikbaar hebben, of 2 TB (500 *(5-1)=2000).
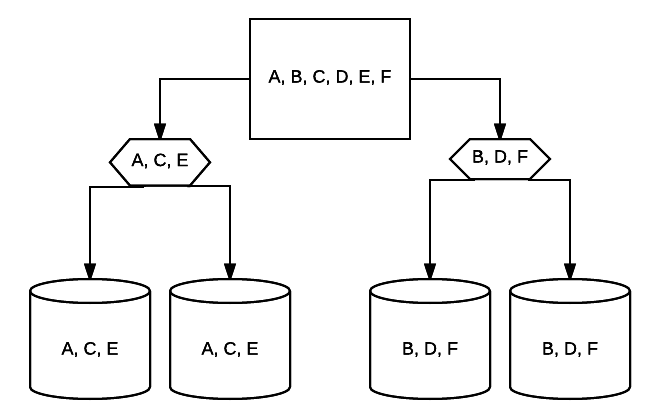
- RAID 10 – Dit is een combinatie van RAID 1 en RAID 0. In dit geval worden alle gegevens over elk apparaat gestreept met blokken gegevens die ook worden gespiegeld over het geheel van het gestreepte systeem. In een RAID 10-systeem met 4 schijven kunnen 2 500 GB-schijven bijvoorbeeld dezelfde gegevens hebben, maar niet alle gegevens die nodig zijn om het systeem goed te laten werken. De gegevens van 2 andere stations zouden nodig zijn. Denk aan elk RAID 1 systeem als een enkele schijf, en elk van deze systemen geplaatst in een RAID 0 array. In deze setup kunnen de prestaties drastisch worden verhoogd zoals in RAID 0, met wat redundantie nog steeds op zijn plaats met de mirroring. Tot de helft van de schijven in het systeem kan falen voordat het systeem crasht, maar zoals bij elke redundante array, is het het beste om schijven zo snel mogelijk te vervangen. Atlantic.Net gebruikt RAID 10 voor alle SSD Cloud VPS-opslag.
voor extra bescherming worden de RAID-controllers beschermd door battery backup units die de ROM-chips aandrijven die worden gebruikt om de configuratie in het geheugen op te slaan in geval van stroomverlies, enz. Een BBU zal stroom leveren aan een RAID-array die deel uitmaakt van een uitgeschakeld systeem voor een kleine hoeveelheid tijd, waardoor de inhoud van de cache van een RAID-controller intact blijft. Dit kan een redder in nood zijn als de informatie constant in uw RAID-array wordt ingevoerd en elke downtime gegevenscorruptie kan veroorzaken.
dus, uw fysieke systeem en de diensten binnen kunnen redundant worden gebouwd nogal adequaat. Maar hoe zit het met uw verbinding met een deel van uw systeem? Zoals in, uw directe internetverbinding met uw systeem als geheel?
Netwerkredundantie
First Hop Redundancy Protocols (FHRP)
in tegenstelling tot dynamische Gateway – detectieprotocollen, staan statische gateways eenvoudige hops toe tussen de client en de juiste gateway, maar dit creëert een enkel storingspunt-namelijk de gateway zelf.
om de impact van gatewayfouten te voorkomen of te verminderen, werden Fhrp ‘ s gemaakt. Ze bieden redundante gateways een fallback, of bieden load-balancing voor high traffic systemen, samen met redundantie. Deze protocollen omvatten VRRP, HSRP, en GLBP.
Virtual Router Redundancy Protocol (VRRP)
VRRP is een vorm van redundantie die wordt gebruikt voor routers waarvoor ten minste twee fysiek gescheiden routers zijn aangesloten via Ethernet-of optische vezelverbindingen. In deze situatie wordt een ‘virtuele router’ met statische routes gemaakt en gedeeld tussen elk systeem.
een systeem wordt beschouwd als de ‘master’ en een ander als de ‘backup’. Wanneer de master faalt, neemt de back-up het over als de volgende master. Dit kan worden ingesteld met meerdere back-ups voor extra redundantie. Het concept is zeer vergelijkbaar met Heartbeat in dat de back-upsystemen zullen controleren om te zien of de master beschikbaar is. Zodra het geen antwoord ontvangt, zal de back-up na een vooraf bepaalde tijd de controle over de virtuele switch overnemen en verbindingen accepteren voor alle aanvragen die binnenkomen voor het standaard IP-adres dat is geconfigureerd voor de master switch.
Hot Standby Router Protocol (HSRP)
HSRP is als VRRP; in dit scenario is de geconfigureerde virtuele switch echter geen ‘switch’, maar eerder een logische groep van meerdere routers. Het IP van de groep is een IP die niet is toegewezen aan een fysieke host. In plaats daarvan krijgt de groep een IP toegewezen en wordt bepaald dat een van de routers de ‘actieve’ router is.
een stand-by router is klaar om alle verbindingen te nemen als de actieve router uitvalt. Alle routers naast de actieve en standby zijn allemaal luisteren naar zijn plaats in de lijn te bepalen. HSRP is een Cisco eigen protocol en heeft zeer weinig, kleine verschillen met VRRP, zoals hun standaard timers bepalen wanneer te failover. HSRP is al een beetje langer en is meer bekend in vergelijking met VRRP.
Gateway Load Balancing Protocol (GLBP)
GLBP ‘ s belangrijkste voordeel ten opzichte van HSRP en VRRP is de mogelijkheid om balans te laden bovenop het verstrekken van redundantie aan een gateway met weinig tot geen extra configuratie. Net als HSRP en VRRP, zal GLBP een groep creëren tussen fysieke routers en een actieve virtuele Gateway, of AVG, bepalen.
een virtueel IP-adres dat momenteel niet door een van de routers in de groep wordt gebruikt, wordt toegewezen aan de AVG. De AVG distribueert vervolgens virtuele MAC-adressen onder de rest van de routers in de groep. Elke back-up router wordt nu beschouwd als een actieve virtuele Forwarder, of AVF.
ARP-verzoeken die naar de AVG worden verzonden, geven een ander virtueel MAC-adres aan de client die de aanvraag verzendt. Op dat moment wordt het verkeer van die client naar het virtuele IP van de groep doorgestuurd naar de router waarvan ze het virtuele MAC-adres hebben ontvangen, waardoor elke router nog steeds kan worden gebruikt in plaats van er werkeloos bij te zitten.
in het geval van een storing van de AVG, vindt priority-based verkiezing plaats, net als in HSRP en VRRP, en de volgende back-up neemt zijn plaats, het verspreiden van virtuele MAC-adressen als normaal. De andere routers behouden nog steeds het virtuele MAC-adres dat door de oorspronkelijke AVG wordt verstrekt en de dingen blijven normaal. In het geval van een storing van een van de AVFs, de AVG zal voorkomen dat het routeren van verkeer naar zijn virtuele MAC-adres.
net als HSRP is GLBP een door Cisco gepatenteerde vorm van FHRP.
redundantie van datacenters
naast redundantiemaatregelen voor uw persoonlijke servers of routers, zijn datacenters ontworpen om bestand te zijn tegen systeemstoringen. Datacenters vallen onder niveaus die door het Uptime Institute zijn gedefinieerd om fouttolerantie te bieden voor storingen van mechanische of servicefouten, waardoor zo veel uptime mogelijk is.
Er zijn vier niveaus, die elk op elkaar bouwen om een hoge beschikbaarheid te bieden aan alle clients binnen een datacenter:
- Tier I-basiscapaciteit: Dit vereist ruimte voor een IT-Groep voor datacenteractiviteiten, een uninterruptible power supply (UPS) die het stroomverbruik bewaakt en filtert en speciale koelapparatuur die continu 24/7 draait. Dit geldt ook voor een stroomgenerator in geval van stroomuitval.
- Tier II-redundante Capaciteitscomponenten: alles wat Tier I levert, plus redundant vermogen en koeling van de faciliteit. Dit kan extra UPS units of extra generatoren.
- niveau III-gelijktijdig te onderhouden: Alles wat Tier II biedt, plus extra apparatuur op zijn plaats om te voorkomen dat uitschakeling nodig is voor vervanging of onderhoud van apparatuur. Op dit niveau worden redundante stroom en koeling rechtstreeks toegepast op alle technische apparatuur, en de apparatuur zelf is geconfigureerd voor redundantie of naadloze failover.
- Tier IV-fouttolerantie: alles wat Tier III biedt, plus ononderbroken service op het niveau van de aanbieder. Terwijl een datacenter elektriciteit of water kan hebben geleverd door een stad of staat provider, een secundaire lijn van elke dienst die wordt gebruikt door het datacenter is vereist. Dit geldt ook voor de ISP. In het geval van een storing in een sectie voorafgaand aan de apparatuur van de klant, is er een back-up plan klaar voor een naadloze overgang.
conclusie
redundantie is door de noodzaak een alledaagse term geworden in de IT-industrie. De hoge beschikbaarheid van diensten zorgt voor een eenvoudige, betrouwbare ervaring voor onze klanten.
of het nu op serviceniveau of op datacenterniveau is, redundantie aan uw systeem bieden is een belangrijk en moeilijk probleem om aan te pakken. Hopelijk heeft dit document wat licht geworpen op de beschikbare opties en zal het helpen bij alle beslissingen die worden genomen met betrekking tot hoge beschikbaarheid in de toekomst.
klaar om te profiteren van Atlantic.Net ‘ s redundante systemen? Neem Contact met ons vandaag nog voor meer informatie over Dedicated Server Hosting met Atlantic.Net.
===Bronnen===
een Redundant Systeem basisbegrippen: http://www.ni.com/white-paper/6874/en/
Koud/Warm/Heet Server: http://searchwindowsserver.techtarget.com/definition/cold-warm-hot-server
High Availability Clustering: https://www.mulesoft.com/resources/esb/high-availability-cluster
Hyper-V Replica: https://technet.microsoft.com/en-us/library/jj134172(v=ws.11).aspx
Hyper-V and High Availability: https://technet.microsoft.com/en-us/library/hh127064.aspx
HAProxy Description: http://www.haproxy.org/#desc
HAProxy – They use it!: http://www.haproxy.org/they-use-it.html
Heartbeat: http://www.linux-ha.org/wiki/Main_Page
RAID Definition: http://searchstorage.techtarget.com/definition/RAID
Striping: http://searchstorage.techtarget.com/definition/disk-striping
RAID Battery Backup Units: https://www.thomas-krenn.com/en/wiki/Battery_Backup_Unit_(BBU/BBM)_Maintenance_for_RAID_Controllers
High-Availability – VRRP, HSRP, GLBP: http://www.freeccnastudyguide.com/study-guides/ccna/ch14/vrrp-hsrp-glbp/
Understanding VRRP: http://www.juniper.net/techpubs/en_US/junos/topics/concept/vrrp-overview-ha.html
Configuring VRRP: http://www.cisco.com/c/en/us/td/docs/ios-xml/ios/ipapp_fhrp/configuration/15-mt/fhp-15-mt-book/fhp-vrrp.html
Configuring GLBP: http://www.cisco.com/c/en/us/td/docs/ios-xml/ios/ipapp_fhrp/configuration/xe-3s/fhp-xe-3s-book/fhp-glbp.html
Explaining the Uptime Institute’s Tier Classification System: https://journal.uptimeinstitute.com/explaining-uptime-institutes-tier-classification-system/