door: Arshad Ali / bijgewerkt: 2020-07-29 / Comments (6) | verwant: meer > JOIN Tables
probleem
in de tip SQL Server JoinExamples sprak Jeremy Kadlec over verschillende logische join operators, maar hoe implementeert SQL Server ze fysiek? Wat zijn de verschillende fysieke joinoperators? Hoe zijn ze verschillend van elkaar en in welk scenario is de ene voorkeur boven de andere? In deze tip behandelen we deze vragen en meer.
oplossing
we gebruiken logische operators wanneer we query ‘ s schrijven om een relationele query op het conceptuele niveau te definiëren (wat er gedaan moet worden). SQL implementeert deze logische operatoren met drie verschillende fysieke operatoren om de door de logische operatoren gedefinieerde operatie te implementeren (hoe het moet worden gedaan). Hoewel er tientallen fysieke operators zijn, zal ik in deze tip specifieke fysieke join operators behandelen. Hoewel we verschillende soorten logische joins hebben op het conceptuele / query niveau, maar SQL Serverimplementeert ze allemaal met drie verschillende fysieke join operators zoals hieronder besproken.
We zullen het volgende behandelen:
- geneste lussen Join
- Merge Join
- Hash Join
We zullen uitvoerplannen bekijken om deze operators te zien en Ik zal uitleggen waarom elk voorkomt.
voor deze voorbeelden gebruik ik de dventureworks database.
SQL Server geneste Loops Join uitgelegd
voordat ik in de details graaf, laat me je eerst vertellen wat een geneste Loops joinis als je nieuw bent in de programmeerwereld.
een geneste lussen join is een logische structuur waarin een lus (iteratie) resideert binnen een andere, dat wil zeggen voor elke iteratie van de buitenste lus alle theiteraties van de binnenste lus worden uitgevoerd/verwerkt.
een geneste Loops join werkt op dezelfde manier. Een van de verbindingstafels is aangeduid als de buitenste tafel en een andere als de binnenste tafel. Voor elke rij van de outertable, alle rijen van de binnenste tabel worden een voor een overeen als de rij matchesit is opgenomen in het resultaat-set anders wordt genegeerd. Vervolgens wordt de volgende rij van de buitenste tabel opgehaald en hetzelfde proces wordt herhaald en ga zo maar door.
De SQL Server optimizer kan een geneste Loops join kiezen wanneer een van de joiningtables klein is (beschouwd als de buitenste tabel) en een andere groot is (beschouwd als de binnenste tabel die is geïndexeerd op de kolom die in de join is) en daarom vereist het minimale I/O en de minste vergelijkingen.
De optimizer beschouwt drie varianten voor een geneste lussen join:
- naive geneste lussen join in welk geval de zoekopdracht scantde hele tabel of index
- index geneste lussen join wanneer de zoekopdracht een bestaande index kan gebruiken om loops uit te voeren
- tijdelijke index geneste lussen join als de optimizer een tijdelijke index creëert als onderdeel van het query-plan en deze vernietigt na query-uitvoercompletes
een index geneste lussen join presteert beter dan een merge join of hash join ifa small set van rijen zijn betrokken. Terwijl, als een grote set van rijen zijn betrokken danest lussen join misschien niet een optimale keuze. Geneste lussen ondersteunen bijna alle join types behalve rechts en volledige buitenste joins, rechts semi-join en rechts anti-semijoins.
- In Script # 1 voeg ik de SalesOrderHeader tabel toe met SalesOrderDetailtable en specificeer ik de criteria om het resultaat van de klant te filteren met CustomerID = 670.
- deze gefilterde criteria retourneren 12 records uit de SalesOrderHeader Table en omdat deze tabel daarom de kleinere is, is deze tabel door de optimizer beschouwd als de betere tabel (bovenste in het grafische uitvoeringsplan van de query).
- voor elke rij van deze 12 rijen van de buitenste tabel, worden rijen uit de binnenste tabel SalesOrderDetail matched (of de innertable wordt 12 keer gescand elke keer voor elke rij met behulp van de index seek of correlatedparameter van de buitenste tabel) en 312 overeenkomende rijen worden geretourneerd zoals u kunt zien in de tweede afbeelding.
- in de tweede query hieronder, gebruik ik SET STATISTICS PROFILE op om profile informatie van de query uitvoering samen met de query result-set weer te geven.
Script #1 – Geneste Lussen Deelnemen Voorbeeld
SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader H INNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID = 670
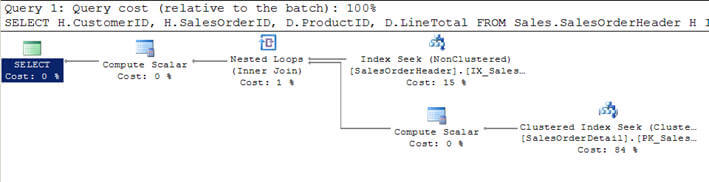
SET STATISTICS PROFILE ONSELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader HINNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderIDWHERE H.CustomerID = 670SET STATISTICS PROFILE OFF

Als het aantal records dat betrokken is groot, SQL Server kan kiezen om te parallelizea geneste lus door het verspreiden van de buitenste rijen willekeurig onder de availableNested Lussen threads dynamisch. Het geldt echter niet hetzelfde voor de binnenste tablerows. Voor meer informatie over parallelle scansklik hier.
SQL Server Merge Join Explained
het eerste wat u moet weten over een Merge join is dat beide ingangen moeten worden gesorteerd op join keys/merge columns (of beide invoertabellen hebben geclusterde indexen op de kolom die de tabellen samenvoegt) en het vereist ook ten minste één equijoin(gelijk aan) expressie / predicaat.
omdat de rijen voorgesorteerd zijn, begint een samenvoeging onmiddellijk met het matchingproces. Het leest een rij van de ene ingang en vergelijkt deze met de rij van een andere ingang.Als de rijen overeenkomen, wordt die overeenkomende rij beschouwd in de resultaatset (dan leest het de volgende rij uit de invoertabel, doet dezelfde vergelijking/match enzovoort) of de kleinste van de twee rijen wordt genegeerd en het proces gaat zo verder totdat alle rijen zijn verwerkt..
een Merge join presteert beter bij het samenvoegen van grote invoertabellen (vooraf geïndexeerd / gesorteerd)omdat de kosten de optelling van rijen in beide invoertabellen zijn in tegenstelling tot de NestedLoops waar het een product is van rijen van beide invoertabellen. Soms besluit de optimizer om een Merge join te gebruiken wanneer de invoertabellen niet gesorteerd zijn en daarom gebruikt het een expliciete Sorteer fysieke operator, maar het kan langzamer zijn dan het gebruik van een index(voorgesorteerde invoertabel).
- In Script # 2 gebruik ik een soortgelijke query als hierboven, maar deze keer heb ik een WHERE-clausule toegevoegd om alle klanten groter dan 100 te krijgen.
- in dit geval besluit de optimizer om een Merge join te gebruiken omdat beide ingangen groot zijn in termen van rijen en ze ook voorgeïndexeerd/gesorteerd zijn.
- u kunt ook zien dat beide ingangen slechts één keer worden gescand, in tegenstelling tot de 12 scans die we zagen in de geneste lussen hierboven.
Script #2 – Merge-Join Voorbeeld
SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader H INNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID > 100
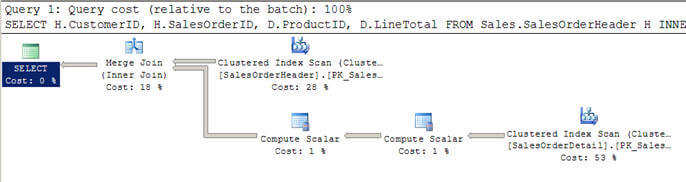
SET STATISTICS PROFILE ONSELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader HINNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderIDWHERE H.CustomerID > 100SET STATISTICS PROFILE OFF

Een Merge-join is vaak een meer efficiënte en snellere join-operator als de sorteddata kan worden verkregen uit een reeds bestaande B-tree index en voert bijna alle joinoperations zolang er ten minste één gelijkheid predikaat join betrokken. Italso ondersteunt meerdere equality join predicaten zolang de invoertabellen worden gesorteerd op alle betrokken verbindingssleutels en in dezelfde volgorde zijn.
de aanwezigheid van een berekende scalaire operator geeft de evaluatie aan van een expressieom een berekende scalaire waarde te produceren. In de bovenstaande query selecteer ik Linetotaldie een afgeleide kolom is, vandaar dat het is gebruikt in het uitvoeringsplan.
SQL Server Hash Join Explained
een Hash join wordt normaal gesproken gebruikt wanneer invoertabellen vrij groot zijn en er geen adequate indexen op bestaan. Een Hash join wordt uitgevoerd in twee fasen; de bouwfase en de Probe fase en dus de hash join heeft twee ingangen dwz Bouw input en probeinput. De kleinere van de ingangen wordt beschouwd als de build-ingang (om de Memory-vereiste te minimaliseren om een hash tabel later besproken op te slaan) en uiteraard de andereen is de probe-ingang.
tijdens de bouwfase worden verbindingssleutels van alle rijen van de bouwtabel gescand.Hashes worden gegenereerd en geplaatst in een in-memory hash tabel. In tegenstelling tot de samenvoeging join,is het blokkeren (er worden geen rijen geretourneerd) tot dit punt.
tijdens de probe-fase worden de verbindingssleutels van elke rij van de probe-tabel gescand.Opnieuw worden hashes gegenereerd (met dezelfde hash functie als hierboven) en vergeleken met de overeenkomstige hash tabel voor een match.
een Hash-functie vereist een aanzienlijke hoeveelheid CPU-cycli om hash-en geheugenbronnen te genereren om de hash-tabel op te slaan. Als er geheugendruk is, worden sommige partities van de hash tabel geruild naar tempdb en wanneer er behoefte is (om de inhoud te onderzoeken of bij te werken) wordt het terug in de cache gebracht.Om hoge prestaties te bereiken, kan de query optimizer een Hash join toscale beter parallelliseren dan elke andere join, voor meer detailsklik hier.
Er zijn in principe drie verschillende soorten hash join:
- In-memory Hash Join in dat geval is er voldoende geheugen beschikbaar om de hash tabel
- Grace Hash Join op te slaan in dat geval kan de hash tabel het geheugen niet aanpassen en sommige partities worden gemorst naar tempdb
- recursieve Hash Join in dat geval is een hash tabel zo grootde optimizer moet veel niveaus van merge joins gebruiken.
voor meer informatie over deze verschillende typen Klik hier.
- In Script #3 maak ik twee nieuwe grote tabellen (van de bestaande AdventureWorkstables) zonder indexen.
- u kunt zien dat de optimizer heeft gekozen om een Hash join te gebruiken in dit geval.
- in tegenstelling tot een geneste lussen join, scant het niet de binnenste tabel multipletimes.
Script #3 – Hash Join Voorbeeld
--Create tables without indexes from existing tables of AdventureWorks database SELECT * INTO Sales.SalesOrderHeader1 FROM Sales.SalesOrderHeader SELECT * INTO Sales.SalesOrderDetail1 FROM Sales.SalesOrderDetail GO SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader1 H INNER JOIN Sales.SalesOrderDetail1 D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID = 670 GO
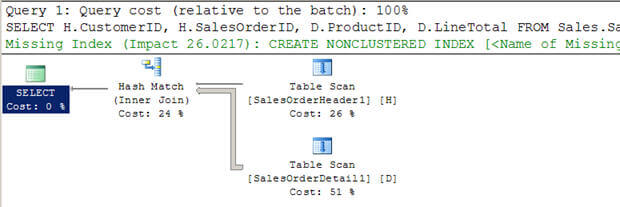
SET STATISTICS PROFILE ON SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader1 H INNER JOIN Sales.SalesOrderDetail1 D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID = 670 SET STATISTICS PROFILE OFF

--Drop the tables created for demonstration DROP TABLE Sales.SalesOrderHeader1 DROP TABLE Sales.SalesOrderDetail1
Opmerking: SQL Server heeft een goede baan bij de keuze voor de joinoperator te gebruiken in elke conditie. Het begrijpen van deze voorwaarden helpt u om te begrijpen wat er kan worden gedaan in performance tuning. Het is niet aan te raden om join hints (usingOPTION clause) te gebruiken om SQL Server te dwingen een specifieke join operator te gebruiken (tenzij je geen andere uitweg hebt), maar je kunt andere middelen gebruiken,zoals het bijwerken van statistieken, het maken van indexen of het opnieuw schrijven van je query.
volgende stappen
- ReviewSQL ServerJoin voorbeelden tip.
- Beoordelinglogical and Physical Operators Reference article on technet.
laatst bijgewerkt: 2020-07-29


 Arshad Ali is a SQL and BI Developer focusing on Data Warehousing projects for Microsoft.
Arshad Ali is a SQL and BI Developer focusing on Data Warehousing projects for Microsoft.View all my tips
- More Database Developer Tips…