
Machine learning wordt uiteindelijk gebruikt om resultaten te voorspellen met een aantal functies. Daarom wordt alles wat we kunnen doen om de prestaties van ons model te veralgemenen gezien als een nettowinst. Dropout is een techniek die wordt gebruikt om te voorkomen dat een model overbevist. Dropout werkt door willekeurig de uitgaande randen van verborgen eenheden (neuronen die deel uitmaken van verborgen lagen) in te stellen op 0 bij elke update van de trainingsfase. Als je kijkt naar de Keras documentatie voor de dropout laag, zie je een link naar een white paper geschreven door Geoffrey Hinton en vrienden, die ingaat op de theorie achter dropout.
in het voorbeeld zullen we Keras gebruiken om een neuraal netwerk op te bouwen met als doel handgeschreven cijfers te herkennen.
from keras.datasets import mnist
from matplotlib import pyplot as plt
plt.style.use('dark_background')
from keras.models import Sequential
from keras.layers import Dense, Flatten, Activation, Dropout
from keras.utils import normalize, to_categorical
We gebruiken Keras om de gegevens in ons programma te importeren. De gegevens zijn al opgesplitst in de trainings-en testsets.
(X_train, y_train), (X_test, y_test) = mnist.load_data()
laten we eens kijken waar we mee werken.
plt.imshow(x_train, cmap = plt.cm.binary)
plt.show()

Nadat we klaar zijn opleiding out-model, het moet kunnen herkennen in de voorgaande afbeelding als een vijf.
Er is een kleine voorbewerking die we vooraf moeten uitvoeren. We normaliseren de pixels (functies) zodanig dat ze variëren van 0 tot 1. Zo kan het model veel sneller convergeren naar een oplossing. Vervolgens transformeren we elk van de doellabels voor een bepaald monster in een array van 1s en 0s waar de index van het nummer 1 het cijfer aangeeft dat de afbeelding vertegenwoordigt. We doen dit omdat ons model anders het cijfer 9 zou interpreteren als met een hogere prioriteit dan het getal 3.
X_train = normalize(X_train, axis=1)
X_test = normalize(X_test, axis=1)
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
zonder Dropout
voordat we een 2-dimensionale matrix in een neuraal netwerk voeden, gebruiken we een vlakke laag die het transformeert in een 1-dimensionale array door elke volgende rij toe te voegen aan de rij die eraan vooraf ging. We gaan gebruik maken van twee verborgen lagen bestaande uit 128 neuronen elk en een output laag bestaande uit 10 neuronen, elk voor een van de 10 mogelijke cijfers. De softmax-activeringsfunctie retourneert de kans dat een monster een bepaald cijfer vertegenwoordigt.

omdat we klassen proberen te voorspellen, gebruiken we categorische crossentropie als onze verliesfunctie. We zullen de prestaties van het model meten met behulp van nauwkeurigheid.
model.compile(
loss='categorical_crossentropy',
optimizer='adam',
metrics=
)
we hebben 10% van de gegevens opzij gezet voor validatie. We zullen dit gebruiken om de tendens van een model te vergelijken om met en zonder uitval over te boeken. Een batchgrootte van 32 houdt in dat we de gradiënt zullen berekenen en een stap in de richting van de gradiënt zullen zetten met een magnitude die gelijk is aan de leersnelheid, nadat we 32 monsters door het neurale netwerk hebben laten gaan. We doen dit in totaal 10 keer zoals aangegeven door het aantal tijdperken.
history = model.fit(
X_train,
y_train,
epochs=10,
batch_size=32,
validation_split=0.1,
verbose = 1,
shuffle=True
)
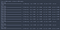
Wij kunnen de grafiek van de training en validatie nauwkeurigheden in elk tijdperk met de geschiedenis van de variabele die wordt geretourneerd door de fit-functie.
zoals u kunt zien, stopt het validatieverlies zonder uitval na de derde Epoche.

As you can see, without dropout, the validation accuracy tends to plateau around the third epoch.

Using this simple model, we still managed to obtain an accuracy of over 97%.
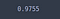
test_loss, test_acc = model.evaluate(X_test, y_test)
test_acc
uitval
Er is enige discussie over de vraag of de uitval voor of na de activeringsfunctie moet worden geplaatst. Als vuistregel plaatst u de uitval na de activeringsfunctie voor alle andere activeringsfuncties dan relu. Bij het passeren van 0,5, elke verborgen eenheid (neuron) is ingesteld op 0 met een waarschijnlijkheid van 0,5. Met andere woorden, er is een verandering van 50% dat de output van een gegeven neuron wordt gedwongen tot 0.

opnieuw, sinds we proberen klassen te voorspellen, we gebruiken categorische crossentropie als onze verliesfunctie.
model_dropout.compile(
loss='categorical_crossentropy',
optimizer='adam',
metrics=
)
door de parameter validations split op te geven, zal het model een fractie van de trainingsgegevens apart zetten en zal het verlies en eventuele modelgegevens op deze gegevens aan het einde van elke epoch evalueren. Als het uitgangspunt achter dropout houdt, dan moeten we een opmerkelijk verschil in de validatie nauwkeurigheid te zien in vergelijking met het vorige model. De parameter shuffle schuift de trainingsgegevens voor elke epoch.
history_dropout = model_dropout.fit(
X_train,
y_train,
epochs=10,
batch_size=32,
validation_split=0.1,
verbose = 1,
shuffle=True
)

Zoals u kunt zien, de validatie verlies is aanzienlijk lager dan die verkregen met behulp van het reguliere model.

As u kunt zien, het model converged veel sneller en verkregen een nauwkeurigheid van bijna 98% op de validatieset, terwijl het vorige model plateaued rond de derde Epoche.

de nauwkeurigheid verkregen op de testset is niet erg anders dan die verkregen van het model zonder uitval. Dit is naar alle waarschijnlijkheid te wijten aan het beperkte aantal monsters.
test_loss, test_acc = model_dropout.evaluate(X_test, y_test)
test_acc

Final Thoughts
dropout kan een model helpen generaliseren door de output van een gegeven Neuron willekeurig in te stellen op 0. Bij het instellen van de output op 0, wordt de kostenfunctie gevoeliger voor naburige neuronen die de manier veranderen waarop de gewichten worden bijgewerkt tijdens het proces van backpropagatie.