in het artikel van vandaag gaan we een kijkje nemen op rolling and expanding windows.
aan het einde van het bericht kunt u deze vragen beantwoorden:
- Wat is een rolling window?
- Wat is een uitbreidingsvenster?
- Waarom zijn ze nuttig?
Wat is een rol-of Uitbreidingsvenster?

Hier is een normaal venster.
we gebruiken normale vensters omdat we een glimp van de buitenkant willen hebben, hoe groter het venster hoe meer van de buitenkant we te zien krijgen.
Als vuistregel geldt ook dat hoe groter de vensters in iemands huis, hoe beter hun aandelenportefeuille deed …
net als echte vensters bieden ook gegevensvensters ons een kleine glimp van iets groters.
een bewegend venster stelt ons in staat om een subset van onze gegevens te onderzoeken.
rollende vensters
vaak willen we een statistische eigenschap van onze tijdreekgegevens weten, maar omdat alle tijdmachines in Roswell zijn opgesloten, kunnen we geen statistiek berekenen over het volledige monster en dat gebruiken om inzicht te krijgen.
dat zou een vooruitblik in ons onderzoek introduceren.
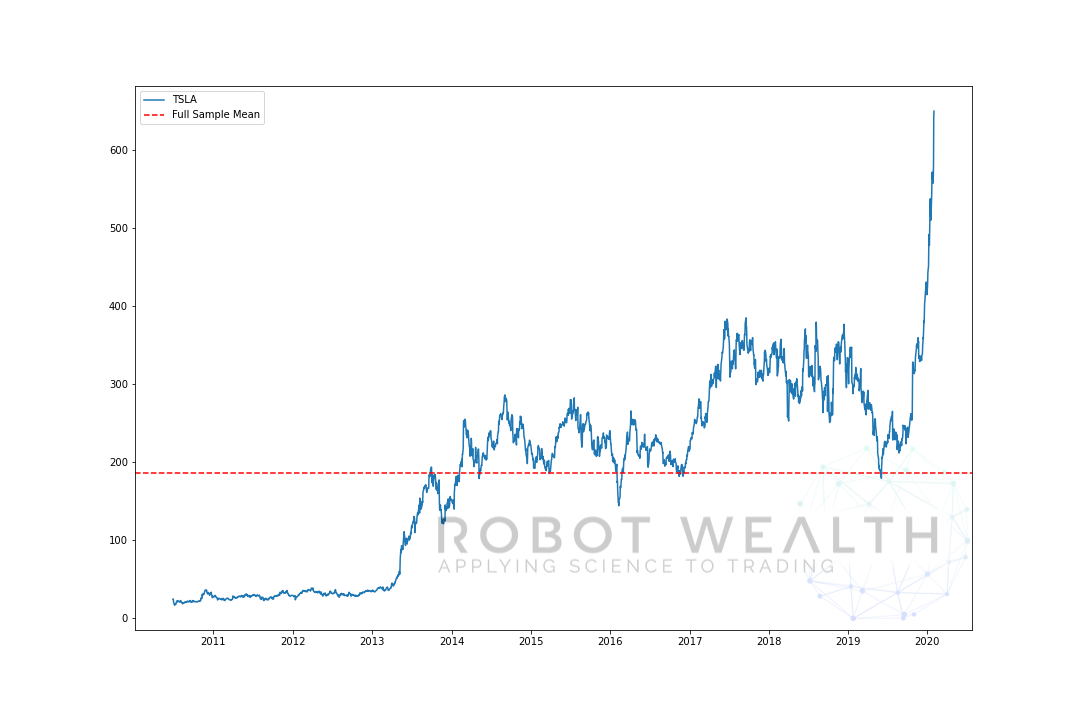
Hier is een extreem voorbeeld daarvan. Hier hebben we de TSLA prijs en het gemiddelde over de volledige steekproef uitgezet.
import pandas as pdimport matplotlib.pyplot as plt #Load TSLA OHLC df = pd.read_csv('TSLA.csv')#Calculate full sample meanfull_sample_mean = df.mean()#Plotplt.plot(df,label='TSLA')plt.axhline(full_sample_mean,linestyle='--',color='red',label='Full Sample Mean')plt.legend()plt.show()
In dit geval, als we net TSLA hadden gekocht toen de prijs onder het gemiddelde lag en het boven het gemiddelde verkochten, zouden we een killing hebben gemaakt, tenminste tot 2019…
maar het probleem is dat we de gemiddelde waarde op dat moment niet hadden geweten.
dus het is vrij duidelijk waarom we niet het hele Monster kunnen gebruiken, maar wat kunnen we dan doen? Een manier waarop we dit probleem kunnen aanpakken is door het gebruik van rollende of uit te breiden ramen.
als je ooit een eenvoudig voortschrijdend gemiddelde hebt gebruikt, dan gefeliciteerd-je hebt een rollend venster gebruikt.
Hoe werken rollende vensters?
stel dat u 20 dagen voorraadgegevens hebt en u wilt de gemiddelde prijs van de voorraad van de laatste 5 dagen weten. Wat doe je voor werk?
u neemt de laatste 5 dagen, Som ze op en deel ze door 5.
maar wat als u het gemiddelde van de voorgaande 5 dagen voor elke dag in uw gegevensverzameling wilt weten?
Dit is waar rolling windows kan helpen.
In dit geval zou ons venster een grootte van 5 hebben, wat betekent dat het voor elk punt in de tijd Het gemiddelde van de laatste 5 gegevenspunten bevat.
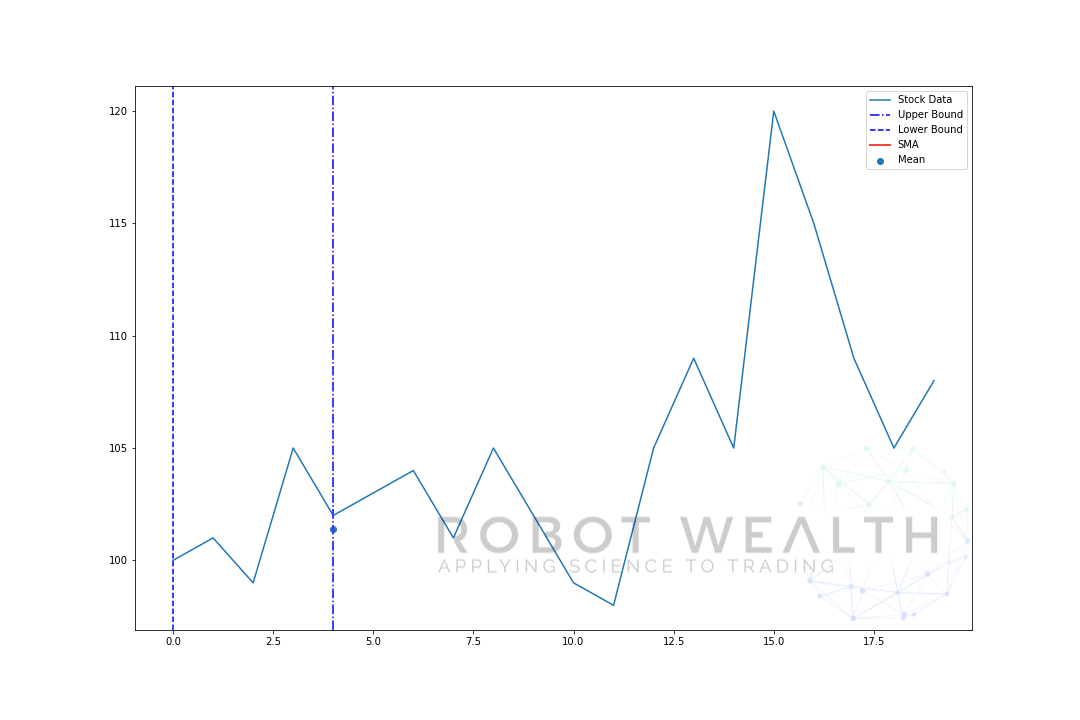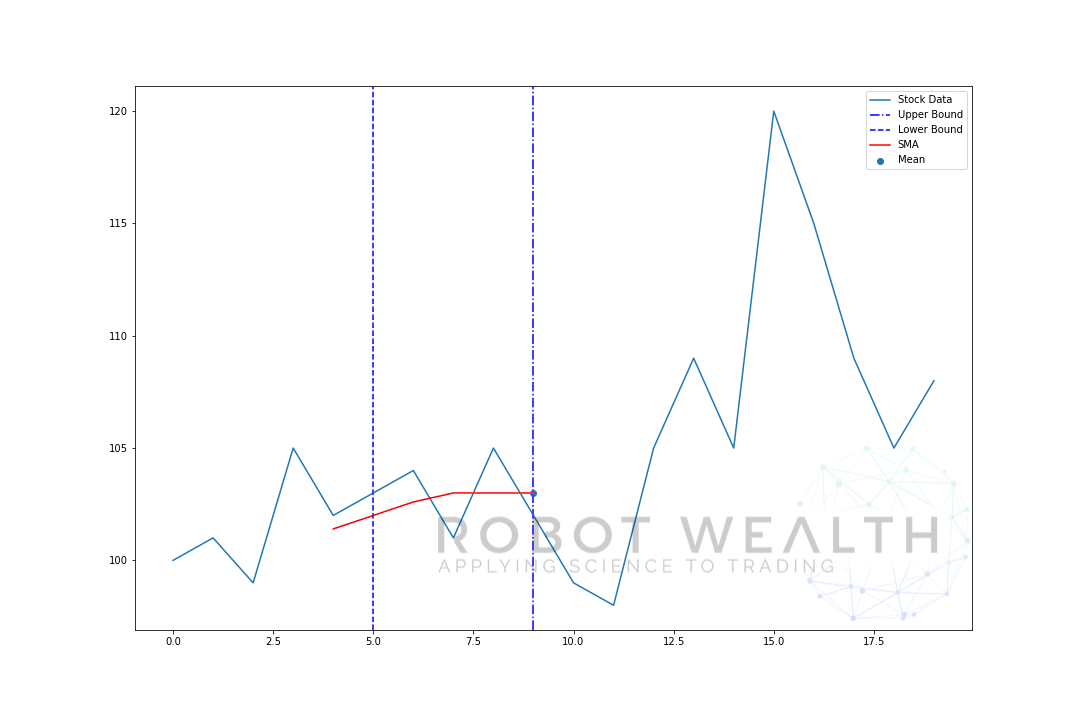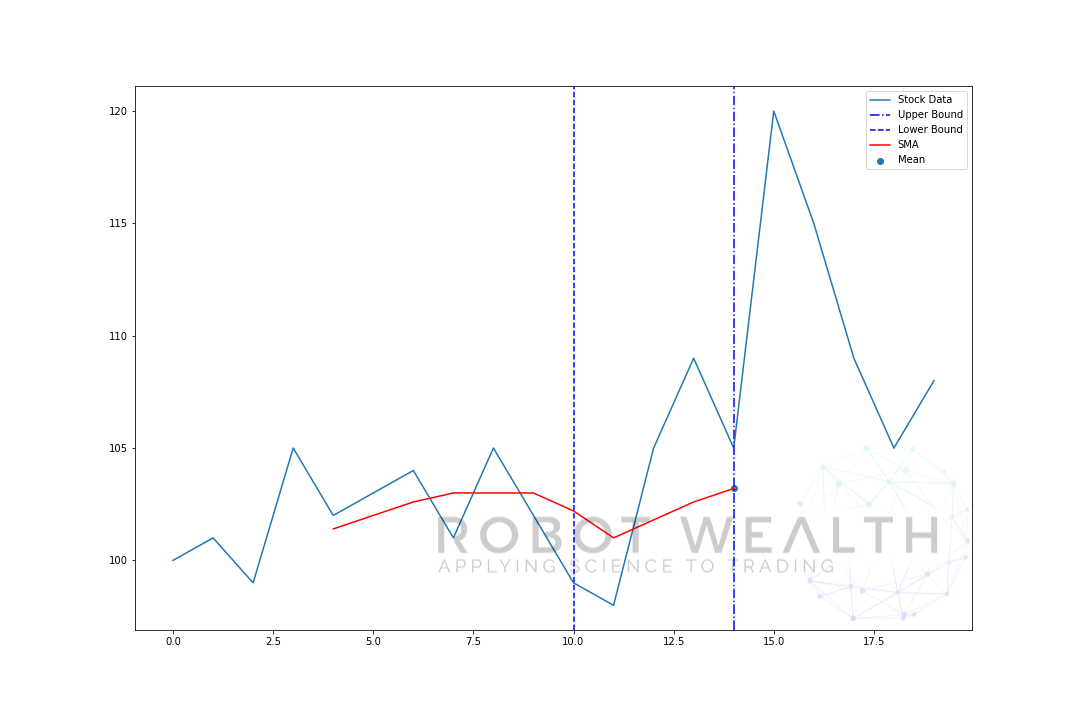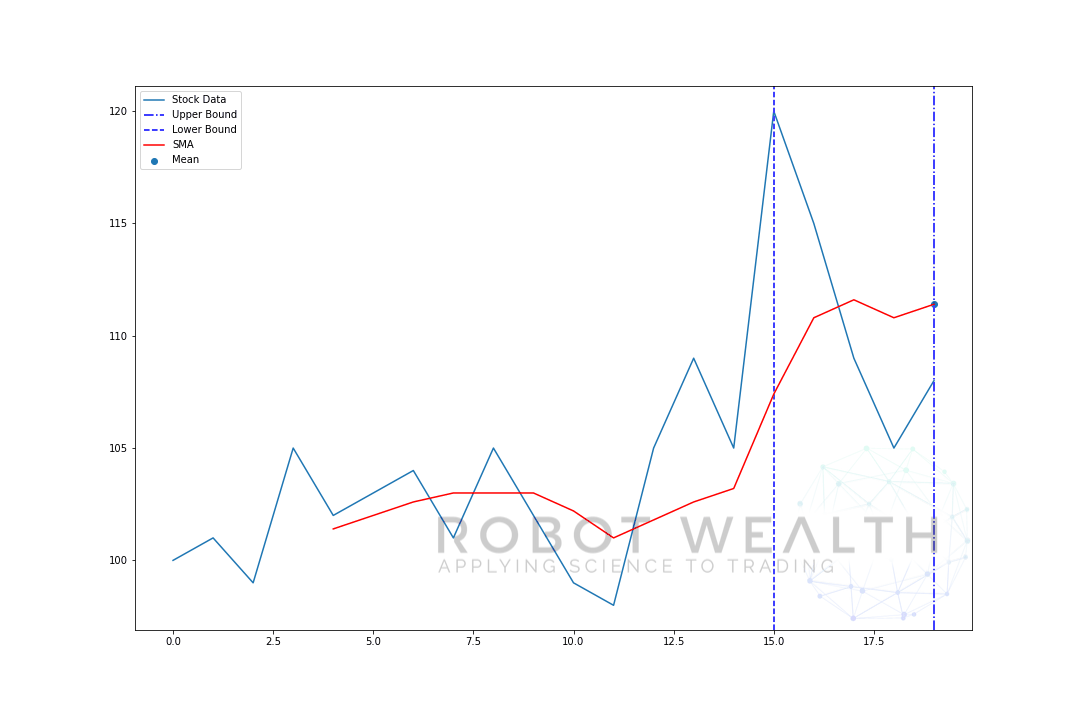
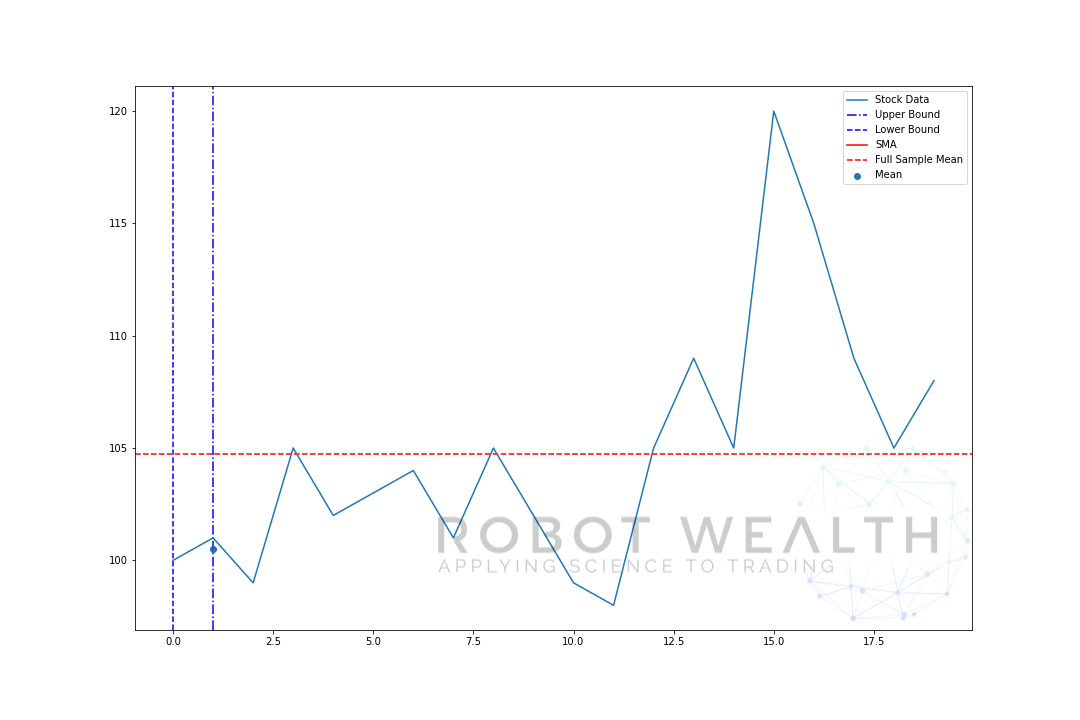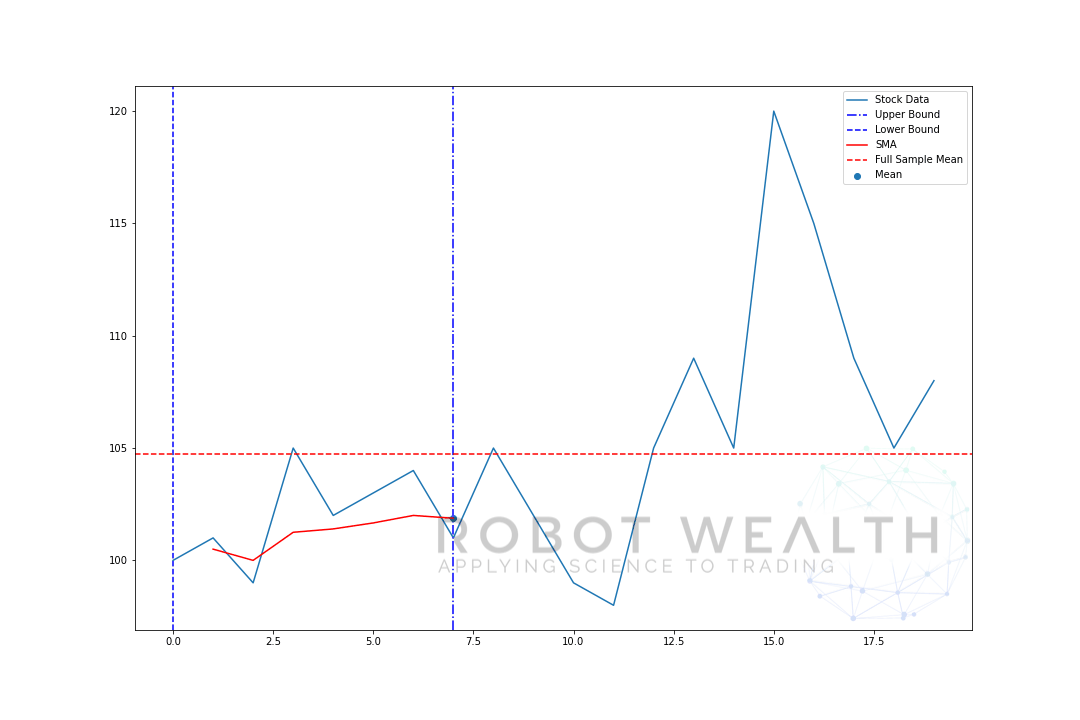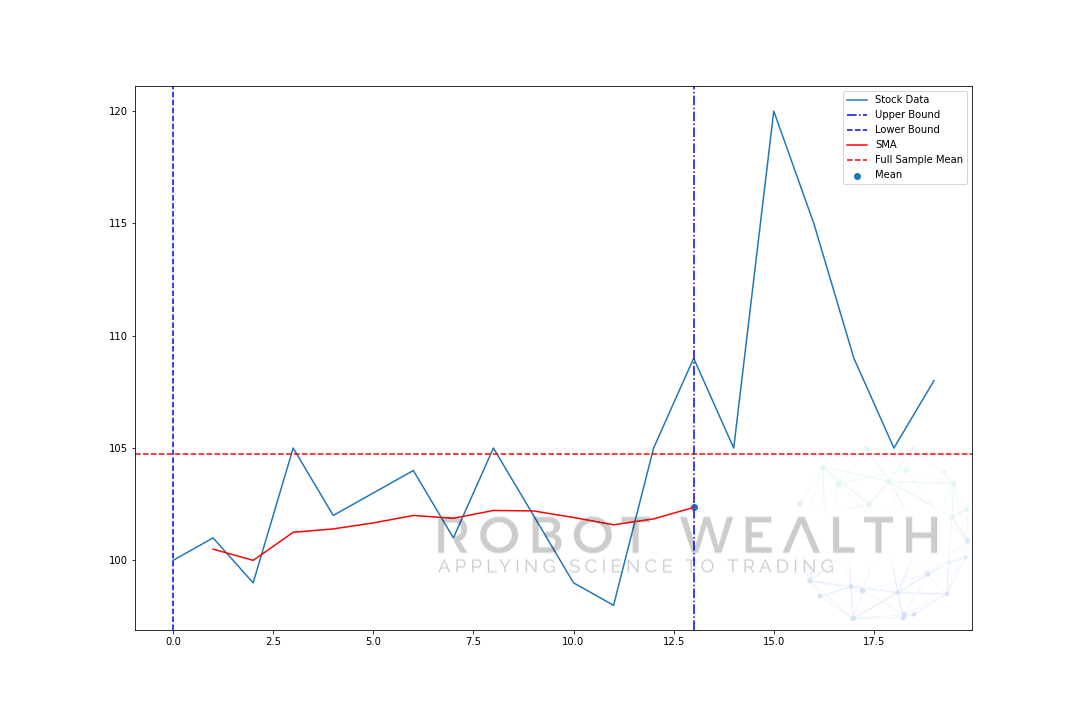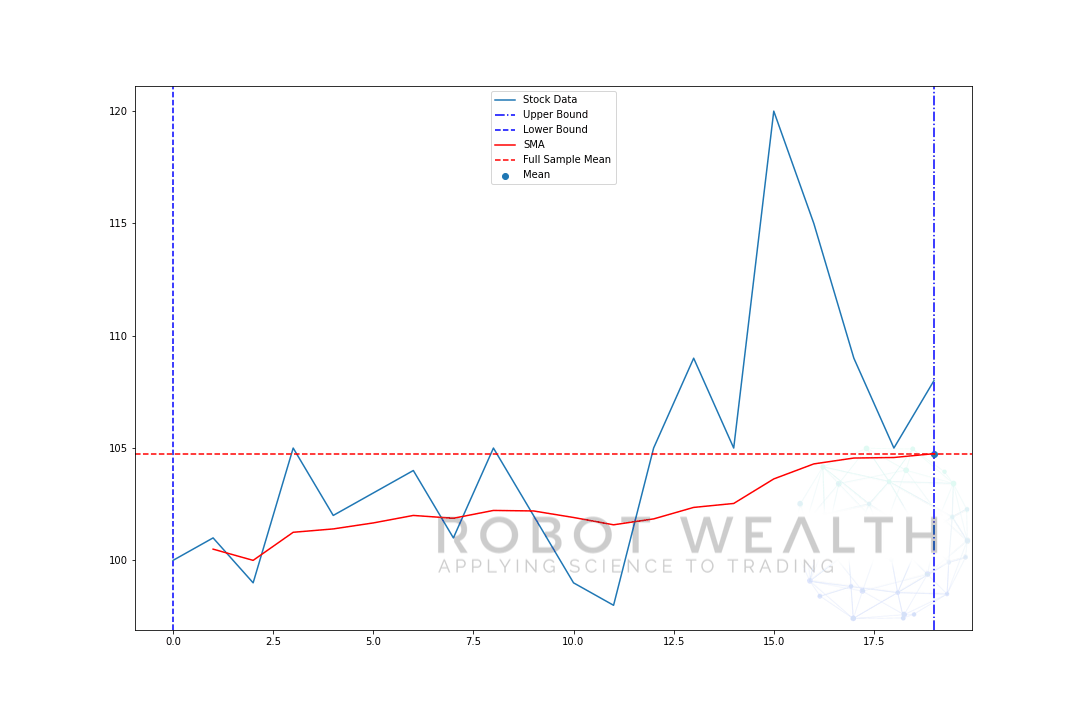
laten we stap voor stap een voorbeeld visualiseren met een bewegend venster van grootte 5.
#Random stock pricesdata = #Create pandas DataFrame from listdf = pd.DataFrame(data,columns=)#Calculate a 5 period simple moving averagesma5 = df.rolling(window=5).mean()#Plotplt.plot(df,label='Stock Data')plt.plot(sma5,label='SMA',color='red')plt.legend()plt.show()
dus laten we deze grafiek opsplitsen.
- we hebben 20 dagen aandelenkoersen in deze grafiek, gelabelde Aandelengegevens.
- voor elk punt in de tijd (de blauwe stip) willen we weten wat de gemiddelde prijs van 5 dagen is.
- de voorraadgegevens die gebruikt worden voor de berekening zijn de gegevens tussen de twee blauwe verticale lijnen.
- nadat we het gemiddelde berekenen van 0-5 komt ons gemiddelde voor dag 5 beschikbaar.
- om het gemiddelde voor dag 6 te krijgen moeten we het venster met 1 verschuiven, zodat het gegevensvenster 1-6 wordt.
en dit is wat bekend staat als een rollend venster, de grootte van het venster is vast. Alles wat we doen is het vooruit rollen.
zoals u waarschijnlijk hebt gemerkt hebben we geen SMA-waarden voor de punten 0-4. Dit komt omdat onze venstergrootte (ook bekend als een terugkijkperiode) minstens 5 datapunten vereist om de berekening uit te voeren.
Uitbreidingsvensters
wanneer rollende vensters een vaste grootte hebben, hebben uitbreidingsvensters een vast beginpunt en nemen ze nieuwe gegevens op zodra deze beschikbaar komen.
Hier is de manier waarop ik hierover denk:
“Wat is het gemiddelde van de afgelopen n waarden op dit punt in de tijd?”- Gebruik rollende ramen hier.
” Wat is het gemiddelde van alle gegevens die tot op dit moment beschikbaar zijn?”- Gebruik hier uitbreidende vensters.
uitbreidende Vensters hebben een vaste ondergrens. Alleen de bovengrens van het raam wordt naar voren gerold (het raam wordt groter).
laten we een uitbreidend venster visualiseren met dezelfde gegevens van de vorige plot.
#Random stock prices data = #Create pandas DataFrame from list df = pd.DataFrame(data,columns=) #Calculate expanding window meanexpanding_mean = df.expanding(min_periods=1).mean()#Calculate full sample mean for referencefull_sample_mean = df.mean()#Plot plt.plot(df,label='Stock Data') plt.plot(expanding_mean,label='Expanding Mean',color='red')plt.axhline(full_sample_mean,label='Full Sample Mean',linestyle='--',color='red')plt.legend()plt.show()
U kunt zien dat in het begin de SMA een beetje zenuwachtig is. Dat komt omdat we een kleiner aantal datapunten hebben aan het begin van de plot, en als we meer gegevens krijgen, breidt het venster uit totdat uiteindelijk het uitbreidende venstergemiddelde convergeert naar het volledige steekproefgemiddelde, omdat het venster de grootte van de volledige dataset heeft bereikt.
samenvatting
Het is belangrijk om geen gegevens uit de toekomst te gebruiken om het verleden te analyseren. Rollende en uitbreidende vensters zijn essentiële hulpmiddelen om “uw gegevens door te laten lopen” om deze problemen te voorkomen.
Als u graag deze zult u waarschijnlijk willen deze ook…
Financiële Data Manipulatie in dplyr voor Quant Handelaren
met Behulp van Digitale signaalverwerking in Kwantitatieve Trading Strategieën
“back-testing” Bias: Voelt het Goed, Tot Je Blaas