celem tego artykułu jest wyjaśnienie redundancji w zakresie komputerów, sieci i hostingu. Przedstawimy rzeczywiste przykłady nadmiarowych rozwiązań technologicznych, aby zilustrować, czym jest redundancja i jak działa.
Atlantic.Net stworzył wiele środowisk hostingowych, w tym trwałą platformę w chmurze, szybki hosting VPS, infrastrukturę zgodną z HIPAA i zarządzany hosting w chmurze prywatnej. Wszystkie nasze systemy są budowane z redundancją jako głównym czynnikiem napędowym procesu projektowania.
w codziennym języku angielskim nadmiarowość może mieć negatywne konotacje; coś nadmiarowego zwykle nie jest potrzebne lub uważane za zbędne. Jednak w środowisku hostingu w chmurze redundancja może oznaczać różnicę między bezproblemową dostępnością systemu a niepożądanym lub nieoczekiwanym przestojem.
- Co To jest redundantny System?
- rodzaje systemów redundantnych
- przykłady redundantnych usług programowych
- Replika Hyper-V
- klastrowanie Hyper-V
- HAProxy
- Heartbeat
- przykłady redundantnych usług sprzętowych
- RAID
- redundancja sieciowa
- First Hop Redundancy Protocols (FHRP)
- Virtual Router Redundancy Protocol (VRRP)
- Hot Standby Router Protocol (HSRP)
- Gateway Load Balancing Protocol (GLBP)
- redundancja centrów danych
- podsumowanie
Co To jest redundantny System?
redundantny system zapewni obsługę failover lub load balancing, aby chronić aktywny system w przypadku nieoczekiwanej awarii. W przypadku awarii zasilania, mechaniki lub oprogramowania nadmiarowy system będzie miał duplikat komponentu lub platformy, na którą można się wycofać. Ogólnie rzecz biorąc, każdy element systemu z jednym punktem awarii może być postrzegany jako zagrożenie dla usług produkcyjnych.
systemy zasilania lub mechaniczne mają prostsze strategie awaryjne wymagające zwykłej obecności innej usługi tego samego typu; przełączanie awaryjne oprogramowania zwykle wymaga dodatkowej konfiguracji na systemie hosta lub master lub bramie.
możliwości redundancji są zalecane dla każdego krytycznego systemu biznesowego, ale szczególnie dla Systemów, które mają znaczący wpływ podczas przestojów. Niektóre firmy mogą przechowywać wszystkie krytyczne informacje o klientach w bazie danych, dlatego dla celów ciągłości biznesowej Ochrona tej bazy danych z redundancją chroni integralność danych w przypadku katastrofalnej awarii.
rodzaje systemów redundantnych
System redundantny składa się z co najmniej dwóch systemów połączonych ze sobą i zaprojektowanych do tego samego celu. Istnieje wiele różnych rodzajów redundantnych konfiguracji systemu, a różne implementacje systemu zapewniają unikalne podejścia do utrzymywania systemu przez cały czas.
nie wszystkie serwery muszą być skonfigurowane z redundancją; raczej należy wziąć pod uwagę tylko najbardziej krytyczne. Zdecydowanie zalecamy szczegółową ocenę ryzyka, aby zrozumieć, jakie serwery są w zasięgu i maksymalną ilość przestojów, z którymi mogą sobie poradzić twoje serwery. Wykorzystaj tę ocenę do określenia strategii RTO (Recovery Time Objective) i RPO (Recovery Point Objective). RTO to maksymalna dopuszczalna ilość przestojów. Może to wynosić od 5 sekund do 24 godzin. RPO to moment, od którego potrzebujesz swoich danych; na przykład Twoja firma może funkcjonować z maksymalną utratą danych w ciągu 24 godzin.
oto kilka popularnych przykładów:
- aktywny-nieaktywny/gorący-zimny – gdy jeden składnik systemu jest aktywny, a inny jest nieaktywny lub zamknięty. Nieaktywny komponent jest aktywowany tylko wtedy, gdy aktualnie uruchomiony komponent ulegnie awarii lub zostanie poddany konserwacji
- Active-Active/Hot-Hot – gdy oba systemy są aktywne i nawiązują połączenia. Jest to najczęściej znane jako klastrowanie. Zazwyczaj urządzenie znajdujące się przed obydwoma maszynami określa sposób podziału ruchu przychodzącego
- Active-Standby/Hot-Warm – gdy oba systemy są włączone, ale tylko jeden wykonuje połączenia. Drugi system ma okresowo otrzymywać aktualizacje lub kopie zapasowe z głównego systemu. W przypadku awarii, system w trybie gotowości przejmuje główną rolę, dopóki początkowy system nie zostanie odzyskany.
każdy typ ma swoje plusy i minusy.
- systemy aktywne-nieaktywne / Gorące-Zimne mogą zapewnić prostą redundantną platformę, ale każde przełączanie awaryjne spowoduje, że użytkownicy zobaczą starszą wersję systemu.
- Active-Active / Hot-Hot wymaga ciągłej aktualizacji obu systemów, ręcznie lub za pośrednictwem oddzielnej usługi, aby zapewnić, że wszyscy użytkownicy mogą korzystać z dowolnego systemu. Takie podejście może znacznie zmniejszyć aktywne obciążenie usług świadczonych klientom.
- Active-Standby / Hot-Warm zapewni możliwości przełączania awaryjnego hot-cold z bardziej aktualną kopią aktywnego systemu w przełączaniu awaryjnym, ale nie zapewnia żadnego złagodzenia obciążenia.
dostępne są Inne formy redundancji wielu węzłów, które pozwalają na większą redundancję i solidne rozwiązania równoważenia obciążenia. W tym momencie będziesz miał klaster wysokiej dostępności, znany również jako klaster HA.
może to wykorzystywać dowolną kombinację wcześniej odnotowanych rozwiązań nadmiarowych z maksymalną elastycznością w podejściu lub wymaganej ilości nadmiarowości. Klastry HA można również skonfigurować w wielu lokalizacjach fizycznych, aby zapewnić dostępność do poziomu szkieletu Internetu.
przykłady redundantnych usług programowych
w przeciwieństwie do niskiej dostępności zasobów, istnieje bardzo mały powód, aby nie tworzyć własnościowych replikacji lub redundantnych usług w środowisku wirtualnym; dlatego wiele takich usług jest domyślnie dostępnych w większości systemów wirtualizacji. Wszystkie nasze usługi w chmurze mają replikację, która pozwala nam replikować dowolny serwer z jednego węzła do drugiego, niezależnie od tego, czy znajduje się on w tym samym centrum danych, czy w oddzielnych regionach centrów danych.
Replika Hyper-V
Replika Hyper-V jest formą nadmiarowości ciepłej. Podstawowa maszyna wirtualna jest tworzona na jednym hoście fizycznym i akceptuje połączenia przychodzące. Po włączeniu replikacji wirtualne dyski twarde nowej maszyny są przenoszone na oddzielny fizyczny host Hyper-V. Ten host następnie konfiguruje maszynę wirtualną na sobie, która replikuje się zgodnie z harmonogramem zdefiniowanym przez użytkownika, aby zapewnić, że zostanie wykonany najnowszy obraz aktywnego serwera. Można również zachować dodatkowe punkty kontrolne. Prywatny hosting Hyper-V z usługami zarządzanymi jest dostarczany przez Atlantic.Net dzięki tej funkcji skontaktuj się z naszym zespołem w celu uzyskania dalszych informacji.
klastrowanie Hyper-V
Hyper-V jest również w stanie klastrować poprzez połączenie z innymi hostami Hyper-V. Maszyny wirtualne na dowolnym hoście Hyper-V można grupować na tym pojedynczym hoście, aby zapewnić redundancję na poziomie lokalnym dzięki sieci wirtualnej.
Microsoft Network Load Balancing (NLB) może być używany do tworzenia jednego Zasobu składającego się z wielu hostów, które dzielą te same informacje, aby zapewnić prosty punkt dostępu do udostępniania plików. Ponieważ jest to ograniczone tylko przez ilość dostępnych zasobów, możesz teoretycznie skonfigurować wiele hostów z wieloma maszynami wirtualnymi w celu uzyskania maksymalnej redundancji, co pozwoliłoby również na wykonywanie konserwacji na poszczególnych maszynach wirtualnych bez utraty dostępności usług lub zasobów. Prywatny hosting Hyper-V z usługami zarządzanymi jest dostarczany przez Atlantic.Net dzięki tej funkcji skontaktuj się z naszym zespołem w celu uzyskania dalszych informacji.
HAProxy
oprócz Hyper-V, urządzenie bramkowe, takie jak firewall, może być używane do przełączania awaryjnego lub równoważenia obciążenia. Na przykład Atlantic.Net może zapewnić pfSense Serwer Proxy o wysokiej dostępności, znany również jako HAProxy.
HAProxy będzie działać jako load balancer, proxy lub proste rozwiązanie hot-warm o wysokiej dostępności dla aplikacji opartych na TCP i HTTP. HAProxy jest bardzo popularnym, opartym na Linuksie rozwiązaniem open-source używanym przez niektóre z najczęściej odwiedzanych witryn na świecie.
Heartbeat
Heartbeat to usługa dostępna w większości dystrybucji Linuksa, która służy do określania, czy węzły w klastrze są nadal aktywne, czy reagują. Jest bardzo prosty w konfiguracji i zapewnia możliwości przełączania awaryjnego dla dowolnego systemu pracującego przez TCP.
twórcy Heartbeat polecają również inne Menedżery zasobów klastrów, które uruchamiają lub zatrzymują usługi w zależności od tego, czy dany host jest wyłączony. Heartbeat ma to włączone, ale inni menedżerowie są dostępni. Ze względu na prostotę Heartbeat jest wysoce konfigurowalny. Platformy hostingowe w chmurze dostarczane przez Atlantic.Net ta funkcja jest już przygotowana i możemy pomóc ci w implementacji Heartbeat na Twojej prywatnej dystrybucji Linuksa, jeśli zajdzie taka potrzeba.
przykłady redundantnych usług sprzętowych
najlepszą częścią redundantnego sprzętu jest jego prostota. Podczas gdy usługi programowe mogą wymagać nadmiernej konfiguracji i być może są dość wrażliwe, sprzęt jest zwykle bardzo prosty w konfiguracji i niezwykle trwały. Pierwszym przykładem, który przyjrzymy się, jest powszechnie stosowana technologia RAID.
RAID
RAID oznacza Redundant Array niezależnych dysków (lub Redundant Array niedrogich dysków w zależności od tego, jak długo go używasz) i ma wiele poziomów używanych do ochrony danych lub zwiększenia We/Wy dysku.
RAID można skonfigurować za pomocą kontrolera programowego lub sprzętowego. Kontroler posiada oprogramowanie i konfigurację niezbędną do zarządzania dyskami RAID. Konfigurację można eksportować do różnych systemów z niewielką lub żadną dodatkową konfiguracją.
RAID można skonfigurować na kilka różnych sposobów, aby zapewnić dobrą równowagę obu jego cech:
- RAID 0 – zasadniczo nie jest to redundancja. Żadne dyski w systemie nie udostępniają danych poprzez dublowanie, ale wszystkie dane są rozdzielane na każdy dysk, co zapewnia zwiększoną prędkość odczytu / zapisu. Każdy dysk może nadal w pełni korzystać z dostarczonej mu pamięci masowej, co oznacza, że im więcej dysków dodasz do RAID 0, tym więcej miejsca będziesz mieć.
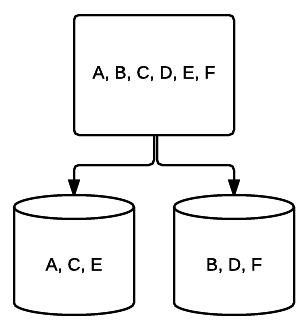
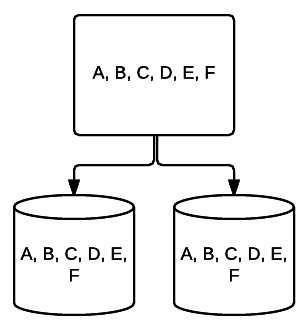
- RAID 1 – podstawowa forma dublowania zapewniająca doskonałą redundancję kosztem miejsca. W systemie dwubiegowym kompletna kopia danych na jednym dysku jest zapisywana na drugim. Redundancja ta jest zwiększana z każdym dodanym dyskiem. Ponieważ wszystkie dane muszą być dublowane na wszystkich dyskach, całkowita przestrzeń w systemie będzie ograniczona tylko do najmniejszego dysku w systemie.
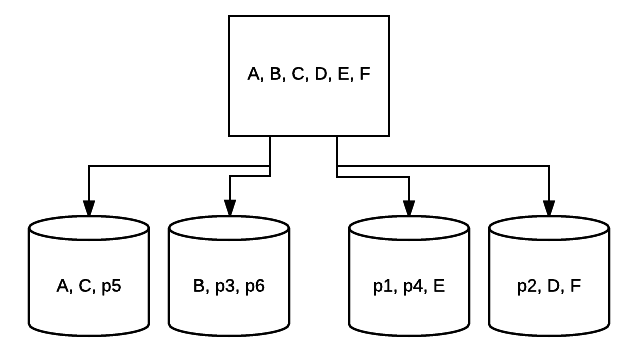
- RAID 5 – ta forma RAID jest zwykle używana do zwiększenia szybkości odczytu i niezawodności. W tym przypadku paski są umieszczane wokół każdego napędu w systemie, przy czym minimum to 3 Napędy. W tym samym czasie dodatkowy blok danych korygujących błędy jest umieszczany na temat każdego dysku w technice zwanej parzystością. Sprawdza, czy dane są zmieniane podczas przenoszenia z jednego dysku na drugi. Zapewnia to również minimalną nadmiarowość, ponieważ jeden z tych dysków może ulec awarii, a system może nadal działać. Im więcej dysków zostanie dodanych do tego typu konfiguracji RAID,tym większa szybkość odczytu. Przy minimalnej redundancji i pasowaniu na wszystkie dyski, całkowita ilość miejsca w tej konfiguracji jest równa wielkości logicznego woluminu RAID razy liczba używanych dysków, minus jeden. Na przykład, jeśli masz 5 dysków 500 GB w RAID 5, możesz użyć 2000 GB lub 2 TB (500 *(5-1)=2000).
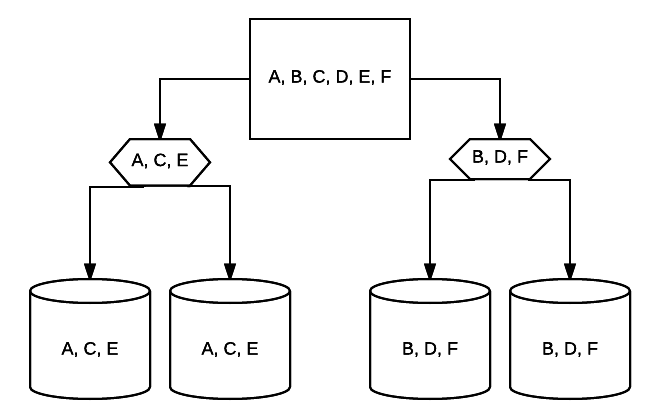
- RAID 10 – jest to kombinacja RAID 1 i RAID 0. W takim przypadku wszystkie dane są paski na każdym urządzeniu, a bloki danych są również lustrzane w całym systemie z paskami. Na przykład w systemie RAID 10 z napędem 4 2 dyski o pojemności 500 GB mogą mieć te same dane, ale nie wszystkie dane potrzebne do prawidłowego działania systemu. Wymagane będą DANE 2 innych dysków. Pomyśl o każdym systemie RAID 1 jako pojedynczym dysku, a każdy z tych systemów umieszczony w macierzy RAID 0. W tej konfiguracji wydajność może być drastycznie zwiększona, jak w RAID 0, z pewną redundancją nadal na miejscu w przypadku dublowania. Nawet połowa dysków w systemie może zawieść przed awarią systemu, ale jak w przypadku każdej redundantnej tablicy, najlepiej wymienić dyski tak szybko, jak to możliwe. Atlantic.Net używa RAID 10 dla wszystkich dysków SSD w chmurze VPS.
aby zapewnić dodatkową ochronę, kontrolery RAID są chronione przez zasilacze bateryjne, które zasilają układy ROM używane do zapisywania konfiguracji w pamięci w przypadku utraty zasilania itp. BBU zapewni zasilanie macierzy RAID, która jest częścią wyłączonego systemu przez krótki czas, dzięki czemu zawartość pamięci podręcznej kontrolera RAID pozostanie nienaruszona. Może to być ratunkiem, Jeśli informacje są stale wprowadzane do macierzy RAID, a wszelkie przestoje mogą spowodować uszkodzenie danych.
tak więc Twój system fizyczny i usługi wewnątrz mogą być zbudowane redundantnie raczej odpowiednio. Ale co z Twoim połączeniem z dowolną częścią systemu? Jak w, bezpośrednie połączenie z Internetem do systemu jako całości?
redundancja sieciowa
First Hop Redundancy Protocols (FHRP)
w przeciwieństwie do dynamicznych protokołów wykrywania bram, statyczne bramy umożliwiają proste przeskoki między Klientem a odpowiednią bramą, ale tworzy to pojedynczy punkt awarii – a mianowicie samą bramę.
aby zapobiec lub zmniejszyć wpływ awarii bramy, utworzono Fhrp. Zapewniają one nadmiarowe bramy awaryjne lub oferują równoważenie obciążenia dla Systemów o dużym natężeniu ruchu wraz z redundancją. Protokoły te obejmują VRRP, HSRP i GLBP.
Virtual Router Redundancy Protocol (VRRP)
VRRP jest formą redundancji używaną dla routerów, która wymaga co najmniej dwóch fizycznie oddzielnych routerów podłączonych za pośrednictwem Ethernetu lub światłowodu. W tej sytuacji, „wirtualny router” zawierający statyczne trasy jest tworzony i współdzielony między każdym systemem.
jeden system jest uważany za „master”, a drugi za „backup”. Gdy master zawiedzie, kopia zapasowa przejmuje funkcję następnego master. Można to skonfigurować z wieloma kopiami zapasowymi, aby uzyskać dodatkową nadmiarowość. Koncepcja jest bardzo podobna do Heartbeat, ponieważ systemy kopii zapasowych sprawdzą, czy master jest dostępny. Gdy nie otrzyma odpowiedzi, po określonym czasie kopia zapasowa przejmie kontrolę nad przełącznikiem wirtualnym i zaakceptuje połączenia dla wszystkich żądań przychodzących dla domyślnego adresu IP skonfigurowanego dla przełącznika głównego.
Hot Standby Router Protocol (HSRP)
HSRP jest jak VRRP; jednak w tym scenariuszu skonfigurowany wirtualny przełącznik nie jest „przełącznikiem”, ale raczej logiczną grupą wielu routerów. Adres IP grupy to adres IP Nie przypisany do fizycznego hosta. Zamiast tego grupie przypisany jest adres IP, a jeden z routerów jest określany jako „aktywny” router.
Router rezerwowy jest gotowy do podjęcia wszelkich połączeń w przypadku awarii aktywnego routera. Wszystkie routery oprócz aktywnego i czuwania słuchają, aby określić jego miejsce w linii. HSRP jest zastrzeżonym protokołem Cisco i ma bardzo niewiele, drobnych różnic w stosunku do VRRP, takich jak ich domyślne timery określające, kiedy przełączać awaryjnie. HSRP istnieje nieco dłużej i jest bardziej znany w porównaniu do VRRP.
Gateway Load Balancing Protocol (GLBP)
główną zaletą GLBP w stosunku do HSRP i VRRP jest jego zdolność do równoważenia obciążenia poza zapewnieniem redundancji bramce z niewielką lub żadną dodatkową konfiguracją. Podobnie jak HSRP i VRRP, GLBP tworzy grupę pomiędzy fizycznymi routerami i określa aktywną bramę wirtualną lub AVG.
wirtualny adres IP, który nie jest obecnie używany przez żaden z routerów w grupie, jest przypisany do AVG. Następnie AVG rozdziela wirtualne adresy MAC pomiędzy Pozostałe routery w grupie. Każdy router kopii zapasowej jest teraz uważany za Aktywnego Wirtualnego spedytora lub AVF.
żądania ARP wysyłane do AVG dostarczą klientowi wysyłającemu żądanie inny wirtualny adres MAC. W tym momencie Ruch z tego klienta na wirtualny adres IP grupy przechodzi do routera, którego wirtualny adres MAC otrzymał, umożliwiając korzystanie z każdego routera zamiast siedzieć bezczynnie.
w przypadku awarii AVG odbywa się wybranie oparte na priorytetach, podobnie jak w HSRP i VRRP, a na jego miejsce powstaje Następna kopia zapasowa, która normalnie rozprowadza wirtualne adresy MAC. Inne routery nadal zachowują wirtualny adres MAC podany przez oryginalny AVG i wszystko przebiega normalnie. W przypadku awarii jednego z plików AVF program AVG uniemożliwi kierowanie ruchu na wirtualny adres MAC.
podobnie jak HSRP, GLBP jest zastrzeżoną formą Fhrp firmy Cisco.
redundancja centrów danych
oprócz redundancji osobistych serwerów lub routerów, centra danych są zaprojektowane tak, aby były odporne na awarie systemu. Centra danych należą do poziomów zdefiniowanych przez Instytut Uptime, aby zapewnić odporność na awarie w przypadku awarii mechanicznych lub serwisowych, pozwalając na jak najdłuższy czas pracy.
istnieją cztery poziomy, z których każdy opiera się na sobie, aby zapewnić wysoką dostępność wszystkim klientom w centrum danych:
- poziom i-pojemność Podstawowa: Wymaga to Miejsca dla grupy informatycznej do pracy w centrum danych, zasilacza awaryjnego (UPS) monitorującego i filtrującego zużycie energii oraz dedykowanego sprzętu chłodzącego, który działa nieprzerwanie 24 godziny na dobę, 7 dni w tygodniu. Obejmuje to również agregat prądotwórczy w przypadku awarii zasilania elektrycznego.
- Tier II – redundantne Komponenty mocy: wszystko, co zapewnia poziom i, a także redundantne zasilanie i chłodzenie obiektu. Może to obejmować dodatkowe zasilacze UPS lub dodatkowe Generatory.
- Poziom III – jednocześnie utrzymywany: Wszystko, co zapewnia Tier II, a także dodatkowe wyposażenie, aby zapobiec konieczności przestojów w celu wymiany lub konserwacji sprzętu. Na tym poziomie redundantne zasilanie i chłodzenie są stosowane bezpośrednio do wszystkich urządzeń technicznych, a samo urządzenie jest skonfigurowane pod kątem redundancji lub bezproblemowego przełączania awaryjnego.
- poziom IV-odporność na awarie: wszystko, co zapewnia Poziom III, plus nieprzerwana usługa na poziomie dostawcy. Podczas gdy centrum danych może mieć energię elektryczną lub wodę dostarczaną przez dostawcę miejskiego lub państwowego, wymagana jest dodatkowa linia każdej usługi wykorzystywanej przez centrum danych. Dotyczy to również ISP. W przypadku awarii w dowolnej sekcji prowadzącej do sprzętu klienta, istnieje plan zapasowy gotowy do bezproblemowego przejścia.
podsumowanie
redundancja stała się codziennym terminem w branży IT z powodu konieczności. Wysoka dostępność usług zapewnia naszym klientom łatwe i niezawodne doświadczenie.
niezależnie od tego, czy chodzi o poziom usług, czy o Centrum Danych, zapewnienie nadmiarowości systemu jest ważnym i trudnym problemem do rozwiązania. Mamy nadzieję, że niniejszy dokument rzuci nieco światła na dostępne opcje i pomoże we wszelkich decyzjach dotyczących wysokiej dostępności w przyszłości.
gotowy do skorzystania z Atlantic.Net redundantne systemy? Skontaktuj się z nami już dziś, aby dowiedzieć się więcej o hostingu serwerów dedykowanych z Atlantic.Net.
===Źródła===
podstawowe pojęcia systemu redundantnego:
Serwer Zimny/ciepły/gorący: http://searchwindowsserver.techtarget.com/definition/cold-warm-hot-server
klastrowanie wysokiej dostępności: https://www.mulesoft.com/resources/esb/high-availability-cluster
replika Hyper-V: https://technet.microsoft.com/en-us/library/jj134172(V=WS.11).aspx
Hyper-V and High Availability: https://technet.microsoft.com/en-us/library/hh127064.aspx
HAProxy Description: http://www.haproxy.org/#desc
HAProxy – They use it!: http://www.haproxy.org/they-use-it.html
Heartbeat: http://www.linux-ha.org/wiki/Main_Page
RAID Definition: http://searchstorage.techtarget.com/definition/RAID
Striping: http://searchstorage.techtarget.com/definition/disk-striping
RAID Battery Backup Units: https://www.thomas-krenn.com/en/wiki/Battery_Backup_Unit_(BBU/BBM)_Maintenance_for_RAID_Controllers
High-Availability – VRRP, HSRP, GLBP: http://www.freeccnastudyguide.com/study-guides/ccna/ch14/vrrp-hsrp-glbp/
Understanding VRRP: http://www.juniper.net/techpubs/en_US/junos/topics/concept/vrrp-overview-ha.html
Configuring VRRP: http://www.cisco.com/c/en/us/td/docs/ios-xml/ios/ipapp_fhrp/configuration/15-mt/fhp-15-mt-book/fhp-vrrp.html
Configuring GLBP: http://www.cisco.com/c/en/us/td/docs/ios-xml/ios/ipapp_fhrp/configuration/xe-3s/fhp-xe-3s-book/fhp-glbp.html
Explaining the Uptime Institute’s Tier Classification System: https://journal.uptimeinstitute.com/explaining-uptime-institutes-tier-classification-system/