to nie ’ teraz dzień Big data..”historia, która dała początek epoce dużych zbiorów danych, ale” dawno temu … ” ludzie zaczęli zbierać informacje za pomocą ręcznych ankiet, stron internetowych, czujników, plików i innych metod zbierania danych. Obejmuje to nawet organizacje międzynarodowe, takie jak WHO, ONZ, które zebrały na arenie międzynarodowej wszystkie możliwe zestawy informacji do monitorowania i śledzenia działań nie tylko związanych z ludźmi, ale także roślinnością i gatunkami zwierząt, aby podejmować ważne decyzje i wdrażać wymagane działania.
tak duże międzynarodowe korporacje, zwłaszcza firmy ecommerce i marketingowe, zaczęły wykorzystywać tę samą strategię do śledzenia i monitorowania działań klientów w celu promowania marek i produktów, co dało początek branży analitycznej. Teraz nie będzie nasycać się tak łatwo, jak firmy zdały sobie sprawę z prawdziwej wartości danych do podejmowania kluczowych decyzji w każdej fazie projektu Od początku do końca, aby stworzyć najlepsze zoptymalizowane rozwiązania pod względem kosztów, ilości, rynku, zasobów i ulepszeń.
V dużych danych to objętość, prędkość, różnorodność, prawdziwość, wartość i wartość, a każdy z nich wpływa na gromadzenie, monitorowanie, przechowywanie, analizę i raportowanie danych. Ekosystem pod względem graczy technologicznych systemu big data jest jak widać poniżej.

teraz omówię każdą technologię jeden po drugim, aby dać wgląd w to, co ważne komponenty i interfejsy.
Jak wyodrębnić dane z danych mediów społecznościowych z Facebooka, Twittera i linkedin do prostego pliku csv do dalszego przetwarzania.
aby móc wyodrębnić dane z Facebooka za pomocą kodu Pythona, musisz zarejestrować się jako programista na Facebooku, a następnie mieć token dostępu. Oto kroki do niego.
1. Przejdź do linku developers.facebook.com, Utwórz tam konto.
2. Przejdź do linku developers.facebook.com/tools/explorer.
3. Przejdź do listy rozwijanej” moje aplikacje „w prawym górnym rogu i wybierz”Dodaj nową aplikację”. Wybierz wyświetlaną nazwę i kategorię, a następnie „Utwórz identyfikator aplikacji”.
4. Ponownie wróć do tego samego linku developers.facebook.com/tools/explorer.zobaczysz „Graph API Explorer” poniżej „Moje aplikacje” w prawym górnym rogu. Z listy rozwijanej” Graph API Explorer ” wybierz aplikację.
5. Następnie wybierz „Pobierz Token”. Z tej listy rozwijanej wybierz „Uzyskaj Token dostępu użytkownika”. Wybierz uprawnienia z menu, które się pojawi, a następnie wybierz ” Uzyskaj Token dostępu.”
6. Przejdź do linku developers.facebook.com/tools/accesstoken. Wybierz „Debug” odpowiadający „Token użytkownika”. Przejdź do „Rozszerz dostęp do tokenów”. Dzięki temu twój token nie wygaśnie co dwie godziny.
Kod Pythona, aby uzyskać dostęp do publicznych danych Facebooka:
przejdź do linku https://developers.facebook.com/docs/graph-api, jeśli chcesz zebrać dane na temat wszystkiego, co jest publicznie dostępne. Zobacz https://developers.facebook.com/docs/graph-api /reference/v2.7/. Z tej dokumentacji Wybierz dowolne pole, z którego chcesz wyodrębnić dane, takie jak „grupy” lub „strony” itp. Przejdź do przykładów kodów Po wybraniu tych, a następnie wybierz „Facebook graph api”, a otrzymasz wskazówki, jak wyodrębnić informacje. Ten blog jest przede wszystkim na pobieranie danych zdarzeń.
Po pierwsze, Importuj 'urllib3′, 'facebook’, 'requests’, jeśli są już dostępne. Jeśli nie, pobierz te biblioteki. Zdefiniuj Token zmiennej i ustaw jego wartość na to, co masz powyżej jako „Token dostępu użytkownika”.

wydobywanie danych z Twittera:
proste 2 kroki można wykonać, jak poniżej
- użyczysz na stronie szczegółów aplikacji; przejdź do zakładki „klucze i tokeny dostępu”, przewiń w dół i kliknij „Utwórz mój token dostępu”. Zwróć uwagę na wartości API Keyand API Secret do wykorzystania w przyszłości. Nie podzielisz się nimi z nikim, można uzyskać dostęp do konta, jeśli dostanie klucze.
- aby wyodrębnić tweety, musisz ustanowić bezpieczne połączenie między R i Twitterem w następujący sposób,
#Wyczyść środowisko R
rm(list=ls())
#załaduj wymagane biblioteki
zainstaluj.packages („twitteR”)
install.packages („ROAuth”)
library („twitteR”)
library („ROAuth”)
# Pobierz plik i zapisz w katalogu roboczym
Pobierz.file (url=”http://curl.haxx.se/ca/cacert.pem”, destfile = ” cacert.pem”)
#Wstaw swój consumerKey i consumerSecret poniżej
<- OAuthFactory$new(consumerKey=’XXXXXXXXXXXXXXXXXX’,
consumerSecret=’XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX’,
requestURL=’https://api.twitter.com/oauth/request_token’,
accessURL=’https://api.twitter.com/oauth/access_token’,
authURL=’https://api.twitter.com/oauth/authorize’)
cred$handshake(cainfo=”cacert.pem”)
# Load Authentication Data
load(„twitter authentication.Rdata”)
#Register Twitter Authentication
setup_twitter_oauth(credentials$consumerKey, credentials$consumerSecret, credentials$oauthKey, credentials$oauthsecret)
#Wyodrębnij tweety z danym ciągiem znaków(pierwszy argument), po którym następuje liczba tweetów (n) i język (lang)
tweety <- searchTwitter(’#DataLove’, N=10, lang=”en”)
teraz możesz wyszukać dowolne słowo w funkcji wyszukiwania Twittera, aby wyodrębnić tweety zawierające to słowo.
Ekstrakcja danych z Oracle ERP
możesz odwiedzić link, aby sprawdzić krok po kroku ekstrakcję pliku csv z bazy danych Oracle ERP cloud.
akwizycja i przechowywanie danych:
teraz, gdy dane są wyodrębniane, muszą być przechowywane i przetwarzane, co robimy w kroku akwizycji danych i przechowywania.
zobaczmy jak działa Spark, Cassandra, Flume, HDFS, HBASE.
Spark
Spark może być wdrożony na wiele sposobów, zapewnia natywne powiązania dla języków programowania Java, Scala, Python i R oraz obsługuje SQL, strumieniowanie danych, uczenie maszynowe i przetwarzanie Wykresów.
RDD to framework dla spark, który pomoże w równoległym przetwarzaniu danych, dzieląc je na ramki danych.
Aby odczytać dane z platformy Spark, użyj poniższego polecenia
results = spark.sql („Select * From people”)
names = results.Mapa (lambda p: p.name)
Połącz się z dowolnym źródłem danych, takim jak json, JDBC, Hive, aby iskrzyć za pomocą prostych poleceń i funkcji. Jak możesz odczytać dane json jak poniżej
spark.Czytaj.json („s3n://…”).registerTempTable („json”)
results = spark.SQL („SELECT * FROM people JOIN JSON…”)
Spark składa się z więcej funkcji, takich jak przesyłanie strumieniowe ze źródeł danych w czasie rzeczywistym, które widzieliśmy powyżej przy użyciu źródła R i python.
na głównej stronie apache spark można znaleźć wiele przykładów, które pokazują, jak spark może odgrywać rolę w ekstrakcji danych, modelowaniu.
https://spark.apache.org/examples.html
Cassandra:
Cassandra jest również technologią Apache jak spark do przechowywania i pobierania danych i przechowywania w wielu węzłach, aby zapewnić 0 odporność na błędy. Używa zwykłych poleceń bazy danych, takich jak tworzenie, zaznaczanie, aktualizowanie i usuwanie operacji. Możesz również tworzyć indeksy, zmaterializowany i normalny widok za pomocą prostych poleceń, takich jak w SQL. Rozszerzenie jest to, że możesz użyć typu danych JSON do wykonywania dodatkowych operacji, jak pokazano poniżej
wstaw do mytable JSON'{„\”myKey\””: 0, „value”: 0} ’
dostarcza on sterowniki open source git hub do użytku z.Net, Python, Java, PHP, NodeJS, Scala, Perl, ROR.
podczas konfigurowania bazy danych należy skonfigurować liczbę węzłów według nazw węzłów, przydzielić token na podstawie obciążenia każdego węzła. Można również użyć poleceń autoryzacji i roli do zarządzania uprawnieniami na poziomie danych w danym węźle.
Więcej szczegółów można znaleźć pod podanym linkiem
http://cassandra.apache.org/doc/latest/configuration/cassandra_config_file.html
Casandra obiecuje osiągnąć 0 odporność na błędy, ponieważ zapewnia wiele opcji zarządzania danymi na danym węźle poprzez buforowanie, zarządzanie transakcjami, replikację, współbieżność do odczytu i zapisu, polecenia optymalizacji dysku, zarządzanie transportem i długością ramki danych.
HDFS
to, co najbardziej podoba mi się w HDFS, to jego ikona, olbrzymi słoń potężny i odporny jak sam HDFS.
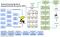
jak widać na powyższym diagramie, system HDFS dla dużych zbiorów danych jest podobny do Cassandry, ale zapewnia bardzo prosty interfejs z zewnętrznymi systemami.
dane są dzielone na ramki danych o różnych lub podobnych rozmiarach, które są przechowywane w rozproszonym systemie plików. Dane są dalej przesyłane do różnych węzłów w oparciu o zoptymalizowane wyniki zapytań do przechowywania danych. Podstawową architekturą jest scentralizowany model Hadoop if Map reduce model.
1. Dane są podzielone na bloki po powiedzmy 128 MB
2. Dane te są rozproszone po różnych węzłach
3. HDFS nadzoruje przetwarzanie
4. Replikacja i buforowanie są wykonywane w celu uzyskania maksymalnej tolerancji błędów.
5. po map i reduce jest wykonywana i zadania pomyślnie obliczone, wracają do głównego serwera
Hadoop jest głównie kodowany w Javie, więc jego wielki, jeśli masz jakieś ręce na Javie, niż będzie to szybkie i łatwe do konfiguracji i uruchomienia wszystkich tych poleceń.
krótki przewodnik po wszystkich koncepcjach związanych z Hadoop można znaleźć pod poniższym linkiem
https://www.tutorialspoint.com/hadoop/hadoop_quick_guide.html
raportowanie i wizualizacja
teraz porozmawiajmy o SAS, R studio i Kime, które są używane do analizy dużych zbiorów danych za pomocą złożonych algorytmów, które są algorytmami uczenia maszynowego, które są oparte na niektórych złożonych modelach matematycznych, które analizują kompletny zestaw danych i tworzą graficzną reprezentację, aby wziąć udział w konkretnym pożądanym celu biznesowym. Przykładowe dane sprzedażowe, potencjał rynkowy klienta, wykorzystanie zasobów itp.
SAS, R I Kinme wszystkie trzy narzędzia oferują szeroki zakres funkcji, od zaawansowanej analizy, IOT, uczenia maszynowego, metod zarządzania ryzykiem, inteligencji bezpieczeństwa.
ale ponieważ jeden z nich jest komercyjny, a drugi to open source, mają one między sobą duże różnice.
zamiast przeglądać każdy z nich jeden po drugim, podsumowałem każdą z różnic w oprogramowaniu i kilka przydatnych wskazówek, które mówią o nich.
