
Uczenie maszynowe jest ostatecznie wykorzystywane do przewidywania wyników w oparciu o zestaw funkcji. Dlatego wszystko, co możemy zrobić, aby uogólnić wydajność naszego modelu, jest postrzegane jako zysk netto. Dropout jest techniką stosowaną w celu zapobieżenia przepełnieniu modelu. Dropout działa poprzez losowe ustawienie wychodzących krawędzi ukrytych jednostek (neuronów tworzących ukryte warstwy) na 0 przy każdej aktualizacji fazy treningowej. Jeśli spojrzysz na dokumentację Keras dla warstwy dropout, zobaczysz link do białej księgi napisanej przez Geoffreya Hintona i przyjaciół, która odnosi się do teorii stojącej za porzuceniem.
w poniższym przykładzie użyjemy Keras do zbudowania sieci neuronowej w celu rozpoznawania ręcznie pisanych cyfr.
from keras.datasets import mnist
from matplotlib import pyplot as plt
plt.style.use('dark_background')
from keras.models import Sequential
from keras.layers import Dense, Flatten, Activation, Dropout
from keras.utils import normalize, to_categorical
używamy Keras do importowania danych do naszego programu. Dane są już podzielone na zestawy treningowe i testowe.
(X_train, y_train), (X_test, y_test) = mnist.load_data()
zobaczmy, z czym pracujemy.
plt.imshow(x_train, cmap = plt.cm.binary)
plt.show()

Po zakończeniu szkolenia model powinien być w stanie rozpoznać poprzedni obraz jako pięć.
jest małe wstępne przetwarzanie, które musimy wykonać wcześniej. Normalizujemy piksele (cechy) tak, aby mieściły się w zakresie od 0 do 1. Umożliwi to modelowi szybszą konwergencję w kierunku rozwiązania. Następnie przekształcamy każdą z etykiet docelowych dla danej próbki w tablicę 1s i 0s, gdzie indeks liczby 1 wskazuje cyfrę, którą reprezentuje obraz. Robimy to, ponieważ w przeciwnym razie nasz model zinterpretowałby cyfrę 9 jako mającą wyższy priorytet niż liczba 3.
X_train = normalize(X_train, axis=1)
X_test = normalize(X_test, axis=1)
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
bez przerwania
przed wprowadzeniem macierzy dwuwymiarowej do sieci neuronowej używamy spłaszczonej warstwy, która przekształca ją w 1-wymiarową tablicę, dodając każdy kolejny wiersz do tego, który go poprzedzał. Użyjemy dwóch ukrytych warstw składających się ze 128 neuronów każda i warstwy wyjściowej składającej się z 10 neuronów, każdy dla jednej z 10 możliwych cyfr. Funkcja aktywacji softmax zwróci prawdopodobieństwo, że próbka reprezentuje daną cyfrę.

ponieważ próbujemy przewidzieć klasy, używamy crossentropii kategorycznej jako funkcji strat. Będziemy mierzyć wydajność modelu za pomocą dokładności.
model.compile(
loss='categorical_crossentropy',
optimizer='adam',
metrics=
)
odkładamy 10% danych na walidację. Wykorzystamy to do porównania tendencji modelu do przepełniania się z rezygnacją i bez niej. Wielkość partii 32 oznacza, że obliczymy gradient i zrobimy krok w kierunku gradientu z wielkością równą szybkości uczenia się, po przejściu 32 próbek przez sieć neuronową. Robimy to łącznie 10 razy zgodnie z liczbą epok.
history = model.fit(
X_train,
y_train,
epochs=10,
batch_size=32,
validation_split=0.1,
verbose = 1,
shuffle=True
)
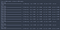
możemy wykreślić dokładność treningu i walidacji w każdej epoce za pomocą zmiennej History zwracanej przez funkcję fit.
jak widać, bez przerwania, utrata walidacji przestaje maleć po trzeciej epoce.

As you can see, without dropout, the validation accuracy tends to plateau around the third epoch.

Using this simple model, we still managed to obtain an accuracy of over 97%.
test_loss, test_acc = model.evaluate(X_test, y_test)
test_acc
Dropout
toczy się dyskusja, czy Dropout powinien być umieszczony przed czy po funkcji aktywacji. Z reguły umieść rezygnację po funkcji aktywacji dla wszystkich funkcji aktywacji innych niż relu. Przy przechodzeniu 0.5, każda ukryta Jednostka (neuron) jest ustawiona na 0 z prawdopodobieństwem 0.5. Innymi słowy, istnieje 50% Zmiana, że wyjście danego neuronu będzie wymuszone na 0.

ponownie, ponieważ próbujemy przewidzieć klasy, używamy crossentropii kategorycznej jako funkcji utraty.
model_dropout.compile(
loss='categorical_crossentropy',
optimizer='adam',
metrics=
)
podając parametr dzielenia walidacji, model oddzieli ułamek danych treningowych i oceni straty i wszelkie metryki modelu na tych danych na końcu każdej epoki. Jeśli przesłanka stojąca za porzuceniem jest zachowana, powinniśmy zauważyć zauważalną różnicę w dokładności walidacji w porównaniu z poprzednim modelem. Parametr shuffle przetasuje dane treningowe przed każdą epoką.
history_dropout = model_dropout.fit(
X_train,
y_train,
epochs=10,
batch_size=32,
validation_split=0.1,
verbose = 1,
shuffle=True
)

jak widać, utrata walidacji jest znacznie niższa niż uzyskana przy użyciu modelu zwykłego.

jak widać, model zbiegał się znacznie szybciej i uzyskał dokładność zbliżoną do 98% na zestawie walidacji, podczas gdy poprzedni model plateaued około trzeciej epoki.

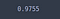
dokładność uzyskana na zestawie testowym nie różni się zbytnio od tej uzyskanej z modelu bez rezygnacji. Jest to najprawdopodobniej spowodowane ograniczoną liczbą próbek.
test_loss, test_acc = model_dropout.evaluate(X_test, y_test)
test_acc

końcowe myśli
porzucenie może pomóc modelowi uogólnić, losowo ustawiając wyjście dla danego neuronu na 0. Przy ustawieniu wyjścia na 0, funkcja kosztowa staje się bardziej wrażliwa na sąsiednie neurony, zmieniając sposób aktualizacji wag podczas procesu backpropagacji.