By: Arshad Ali | Updated: 2020-07-29 | Comments (6) | Related: More > JOIN Tables
Problem
w tip SQL Server JoinExamples Jeremy Kadlec mówił o różnych operatorach logicznych join, ale jak SQL Server implementuje je fizycznie? Jakie są różne fizyczne joinoperators? Czym się od siebie różnią i w jakim scenariuszu preferuje się inne? W tej poradzie omówimy te pytania i nie tylko.
rozwiązanie
podczas pisania zapytań używamy operatorów logicznych, aby zdefiniować zapytanie relacyjne na poziomie koncepcyjnym (co należy zrobić). SQL implementuje te operatory logiczne z trzema różnymi operatorami fizycznymi, aby zaimplementować operację zdefiniowaną przez operatory logiczne (w jaki sposób należy to zrobić). Chociaż istnieją dziesiątki fizycznych operatorów, w tej końcówce omówię konkretne fizyczne operatory join. Chociaż mamy różne rodzaje połączeń logicznych na poziomie koncepcyjnym/zapytań, ale SQL Server implementuje je wszystkie za pomocą trzech różnych fizycznych operatorów połączeń, jak omówiono poniżej.
omówimy:
- zagnieżdżone pętle dołączają
- Merge Join
- Hash Join
przyjrzymy się planom zabezpieczeń, aby zobaczyć te operatory i wyjaśnię, dlaczego każdy z nich występuje.
do tych przykładów używam bazy danych AdventureWorks.
SQL Server zagnieżdżone pętle dołączają wyjaśnione
zanim zagłębisz się w szczegóły, pozwól, że najpierw powiem ci, do czego dołączają zagnieżdżone pętle, jeśli jesteś nowy w świecie programowania.
połączenie pętli zagnieżdżonych jest strukturą logiczną, w której jedna pętla (iteracja) znajduje się przy drugiej, to znaczy dla każdej iteracji pętli zewnętrznej wszystkie iteracje pętli wewnętrznej są wykonywane / przetwarzane.
zagnieżdżone pętle łączą się w ten sam sposób. Jeden ze stołów łączących jest oznaczony jako stół zewnętrzny, a drugi jako stół wewnętrzny. Dla każdego wiersza tabeli zewnętrznej wszystkie wiersze z tabeli wewnętrznej są dopasowywane jeden po drugim, jeśli wiersz matchesit jest zawarty w zestawie wyników, w przeciwnym razie jest ignorowany. Następnie następny wiersz zzewnętrzna tabela jest pobierana i ten sam proces jest powtarzany i tak dalej.
optymalizator SQL Server może wybrać zagnieżdżone pętle, gdy jedna z tabel joiningtables jest mała (uważana za zewnętrzną tabelę), a druga jest duża (uważana za wewnętrzną tabelę indeksowaną w kolumnie, która jest w join) i wymaga minimalnego We/Wy i najmniejszej liczby porównań.
optymalizator rozważa trzy warianty połączenia zagnieżdżonych pętli:
- naiwne zagnieżdżone pętle łączą się w takim przypadku przeszukiwanie skanuje całą tabelę lub indeks
- indeks zagnieżdżone pętle łączą się, gdy wyszukiwanie może wykorzystać istniejący indeks do wykonywania wyszukiwań
- tymczasowy indeks zagnieżdżone pętle łączą się, jeśli optymalizator utworzy tymczasowy indeks jako część planu zapytania i zniszczy go po wykonaniu zapytaniapełnia
indeks zagnieżdżone pętle łączą się lepiej niż połączenie scalające lub połączenie hashowe i mały zestaw wierszy jest zaangażowany. Natomiast jeśli w grę wchodzi duży zbiór wierszy, to dołączenie pętli może nie być optymalnym wyborem. Zagnieżdżone pętle obsługują prawie wszystkie typy join, z wyjątkiem prawego i pełnego złączenia zewnętrznego, prawego semi-join i prawego anti-semijoina.
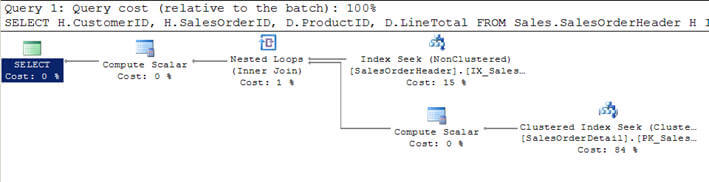
- w skrypcie #1 dołączam tabelę SalesOrderHeader z salesorderdetailtable i określam kryteria filtrowania wyniku klienta za pomocą CustomerID = 670.
- to filtrowane kryteria zwracają 12 rekordów z tabeli SalesOrderHeader, a zatem jest to mniejsza tabela, ta tabela została uznana przez optymalizator za tabelę Outer (górną w graficznym planie wykonywania zapytań).
- dla każdego wiersza z tych 12 wierszy tabeli zewnętrznej, wiersze z tabeli wewnętrznej SalesOrderDetail są dopasowywane (lub wewnętrzna tabela jest skanowana 12 razy za każdym razem dla każdego wiersza za pomocą wyszukiwania indeksu lub korelowanego parametru z tabeli zewnętrznej) i zwracane jest 312 pasujących wierszy, jak można zobaczyć na drugim obrazku.
- w drugim zapytaniu poniżej używam SET STATISTICS PROFILE on do wyświetlania informacji o wykonaniu zapytania wraz z zestawem wyników zapytania.
skrypt #1 – zagnieżdżone pętle dołączają do przykładu
SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader H INNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID = 670
SET STATISTICS PROFILE ONSELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader HINNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderIDWHERE H.CustomerID = 670SET STATISTICS PROFILE OFF

jeśli liczba zaangażowanych rekordów jest duża, SQL Server może wybrać równoległą zagnieżdżoną pętlę, rozdzielając zewnętrzne wiersze tabeli losowo pomiędzy dostępne wątki pętli. Nie dotyczy to jednak wewnętrznych stołów. Aby dowiedzieć się więcej o parallel scansclick tutaj.
SQL Server Merge Join Explained
pierwszą rzeczą, którą musisz wiedzieć o połączeniu scalającym, jest to, że wymaga on sortowania danych wejściowych na klawiszach join/kolumnach merge (lub obie tabele wejściowe mają clusteredindexes na kolumnie, która łączy się z tabelami), a także wymaga co najmniej jednego wyrażenia / predykatu equijoin(równego).
ponieważ wiersze są wstępnie posortowane, połączenie scalające natychmiast rozpoczyna proces dopasowywania. Odczytuje wiersz z jednego wejścia i porównuje go z wierszem innego wejścia.Jeśli wiersze pasują, to ten dopasowany wiersz jest brany pod uwagę w zestawie wyników (wtedy odczytuje następny wiersz z tabeli wejściowej, robi to samo porównanie / dopasowanie itd.) lub mniejszy z dwóch wierszy jest ignorowany i proces kontynuuje w ten sposób, aż wszystkie wiersze zostaną przetworzone..
połączenie scalające działa lepiej podczas łączenia dużych tabel wejściowych (wstępnie indeksowanych / posortowanych), ponieważ koszt jest sumacją wierszy w obu tabelach wejściowych, w przeciwieństwie do NestedLoops, gdzie jest iloczynem wierszy obu tabel wejściowych. Czasami optymalizator decyduje o użyciu połączenia scalającego, gdy tabele wejściowe nie są posortowane i dlatego używa jawnego operatora fizycznego sortowania, ale może być wolniejszy niż użycie indeksu(wstępnie posortowanej tabeli wejściowej).
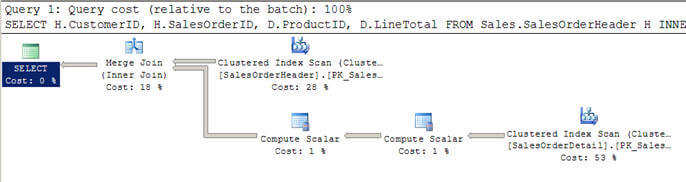
- w skrypcie #2 używam podobnego zapytania jak wyżej, ale tym razem dodałem klauzulę WHERE, aby uzyskać wszystkich klientów powyżej 100.
- w tym przypadku optymalizator decyduje się na użycie połączenia scalającego, ponieważ oba wejścia są duże pod względem wierszy i są również wstępnie indeksowane/posortowane.
- można również zauważyć, że oba wejścia są skanowane tylko raz, w przeciwieństwie do 12 skanów, które widzieliśmy w zagnieżdżonych pętlach połączonych powyżej.
skrypt #2 – Merge Join przykład
SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader H INNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID > 100
SET STATISTICS PROFILE ONSELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader HINNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderIDWHERE H.CustomerID > 100SET STATISTICS PROFILE OFF

merge join jest często bardziej wydajnym i szybszym operatorem join, jeśli sorteddata można uzyskać z istniejącego indeksu B-tree i wykonuje prawie wszystkie operacje joinoperacji, o ile dotyczy co najmniej jednego predykatu równości join. Italso obsługuje wiele predykatów equality join tak długo, jak tabele wejściowe są sortowane na wszystkich zaangażowanych klawiszach łączenia i są w tej samej kolejności.
obecność obliczeniowego operatora skalarnego wskazuje na obliczenie wyrażenia w celu wytworzenia obliczonej wartości skalarnej. W powyższym zapytaniu wybieram Linetotal, który jest pochodną kolumny, stąd został użyty w planie wykonania.
SQL Server Hash Join Explained
Hash join jest zwykle używany, gdy tabele wejściowe są dość duże i nie istnieją na nich odpowiednie indeksy. Połączenie Hashowe odbywa się w dwóch fazach; Faza Build I faza Probe, a co za tym idzie połączenie hashowe ma dwa wejścia tj. build input i probeinput. Mniejsze z wejść jest uważane za wejście kompilacji (aby zminimalizować wymóg przechowywania tabeli skrótu omówionej później) i oczywiście drugim jest wejście sondy.
w fazie budowania skanowane są klucze łączące wszystkich wierszy tabeli budowania.Hashe są generowane i umieszczane w tabeli skrótów w pamięci. W przeciwieństwie do merge join, blokuje (żadne wiersze nie są zwracane) do tego momentu.
podczas fazy sondy skanowane są klucze łączące każdego rzędu stołu sondy.Ponownie generowane są skróty (przy użyciu tej samej funkcji skrótu jak powyżej) i porównywane z odpowiednią tabelą skrótów dla dopasowania.
funkcja skrótu wymaga dużej ilości cykli procesora do generowania hashów i zasobów pamięci do przechowywania tabeli skrótu. Jeśli istnieje presja pamięci, niektóre partycje tabeli hash są zamieniane na tempdb i ilekroć jest to konieczne (do badania lub aktualizacji zawartości), jest ona przywracana do pamięci podręcznej.Aby osiągnąć wysoką wydajność, optymalizator zapytań może paralelizować połączenie Hashowe do skali lepiej niż jakiekolwiek inne połączenie, aby uzyskać więcej szczegółówkliknij tutaj.
istnieją zasadniczo trzy różne typy łączenia skrótów:
- in-memory Hash Join, w którym to przypadku dostępna jest wystarczająca ilość pamięci, aby zapisać tabelę skrótów
- Grace Hash Join, w którym to przypadku tabela skrótów nie może pomieścić pamięci, a niektóre partycje są rozlane do tempdb
- rekursywne łączenie skrótów, w którym to przypadku tabela skrótów jest tak duża, że optymalizator musi używać wielu poziomów łączenia.
aby uzyskać więcej informacji na temat tych różnych typówkliknij tutaj.
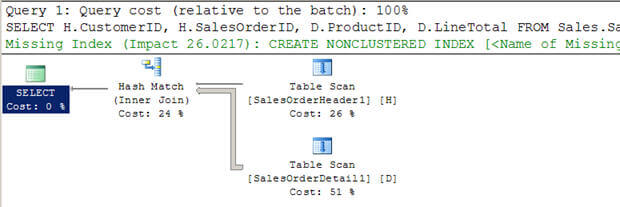
- w skrypcie #3 tworzę dwie nowe duże tabele (z istniejących AdventureWorkstables) bez indeksów.
- w tym przypadku widać, że optymalizator wybrał połączenie skrótu.
- ponownie w przeciwieństwie do zagnieżdżonych pętli, nie skanuje ona wielokrotnie wewnętrznej tabeli.
skrypt #3 – Przykład łączenia skrótów
--Create tables without indexes from existing tables of AdventureWorks database SELECT * INTO Sales.SalesOrderHeader1 FROM Sales.SalesOrderHeader SELECT * INTO Sales.SalesOrderDetail1 FROM Sales.SalesOrderDetail GO SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader1 H INNER JOIN Sales.SalesOrderDetail1 D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID = 670 GO
SET STATISTICS PROFILE ON SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader1 H INNER JOIN Sales.SalesOrderDetail1 D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID = 670 SET STATISTICS PROFILE OFF

--Drop the tables created for demonstration DROP TABLE Sales.SalesOrderHeader1 DROP TABLE Sales.SalesOrderDetail1
Uwaga: SQL Server wykonuje całkiem dobrą robotę decydując, którego joinoperatora użyć w każdym warunku. Zrozumienie tych warunków pomaga zrozumieć, co można zrobić w strojeniu wydajności. Nie zaleca się używania podpowiedzi join (klauzula usingOPTION), aby zmusić SQL Server do użycia określonego operatora join (chyba że masz inne wyjście), ale raczej możesz użyć innych środków, takich jak aktualizacja statystyk, tworzenie indeksów lub ponowne pisanie zapytania.
kolejne kroki
- Recenzjesql ServerJoin przykłady wskazówka.
- Recenzjaoperatory logiczne i fizyczne artykuł referencyjny o technecie.
Ostatnia aktualizacja: 2020-07-29


 Arshad Ali is a SQL and BI Developer focusing on Data Warehousing projects for Microsoft.
Arshad Ali is a SQL and BI Developer focusing on Data Warehousing projects for Microsoft.View all my tips
- More Database Developer Tips…