w dzisiejszym artykule przyjrzymy się zwijaniu i rozszerzaniu okien.
pod koniec postu będziesz mógł odpowiedzieć na te pytania:
- co to jest okno toczenia?
- co to jest okno rozwijające?
- dlaczego są przydatne?
co to jest okno zwijane lub rozwijane?

oto normalne okno.
używamy normalnych okien, ponieważ chcemy mieć wgląd Na Zewnątrz, im większe okno, tym więcej z zewnątrz widzimy.
również ogólną zasadą jest, że im większe okna w czyimś domu, tym lepszy był ich portfel akcji …
podobnie jak prawdziwe Okna, Okna danych oferują nam również mały wgląd w coś większego.
ruchome okno pozwala nam zbadać podzbiór naszych danych.
Toczenie okien
często chcemy poznać statystyczną właściwość naszych danych szeregów czasowych, ale ponieważ wszystkie wehikuły czasu są zamknięte w Roswell, nie możemy obliczyć statystyki na całej próbce i użyć tego, aby uzyskać wgląd.
to wprowadzałoby uprzedzenia w naszych badaniach.
oto skrajny przykład tego. Tutaj wykreśliliśmy cenę TSLA i jej średnią na podstawie pełnej próbki.
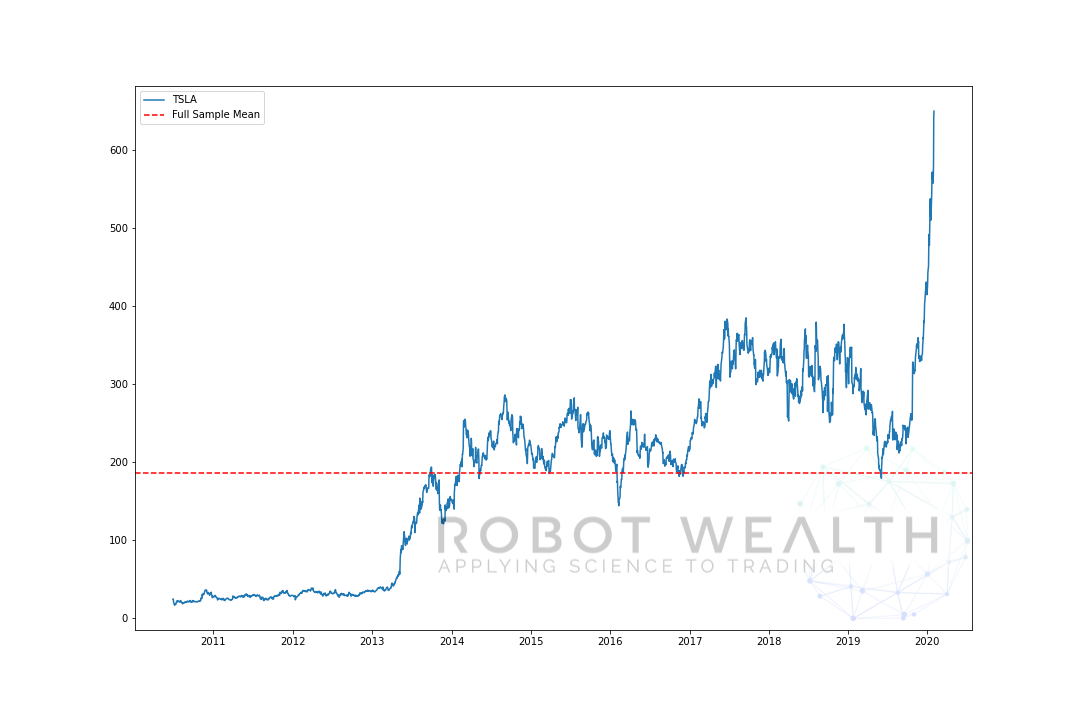
import pandas as pdimport matplotlib.pyplot as plt #Load TSLA OHLC df = pd.read_csv('TSLA.csv')#Calculate full sample meanfull_sample_mean = df.mean()#Plotplt.plot(df,label='TSLA')plt.axhline(full_sample_mean,linestyle='--',color='red',label='Full Sample Mean')plt.legend()plt.show()
w tym przypadku, gdybyśmy po prostu kupili TSLA, gdy cena była poniżej średniej i sprzedali ją Powyżej średniej, dokonalibyśmy zabójstw, przynajmniej do 2019 roku…
ale problem polega na tym, że nie znalibyśmy średniej wartości w tym momencie.
więc to dość oczywiste, dlaczego nie możemy użyć całej próbki, ale co możemy wtedy zrobić? Jednym ze sposobów podejścia do tego problemu jest użycie okien zwijanych lub rozszerzanych.
Jeśli kiedykolwiek korzystałeś z prostej średniej ruchomej, to gratuluję-korzystałeś z rolling window.
Jak działają okna dachowe?
Załóżmy, że masz 20 dni danych giełdowych i chcesz poznać średnią cenę akcji z ostatnich 5 dni. Czym się zajmujesz?
bierzesz ostatnie 5 dni, sumujesz je i dzielisz przez 5.
ale co, jeśli chcesz poznać średnią z poprzednich 5 dni dla każdego dnia w swoim zbiorze danych?
To jest miejsce, gdzie rolling windows może pomóc.
w tym przypadku nasze okno ma rozmiar 5, co oznacza, że dla każdego punktu w czasie zawiera średnią z ostatnich 5 punktów danych.
zwizualizujmy przykład z ruchomym oknem o rozmiarze 5 krok po kroku.
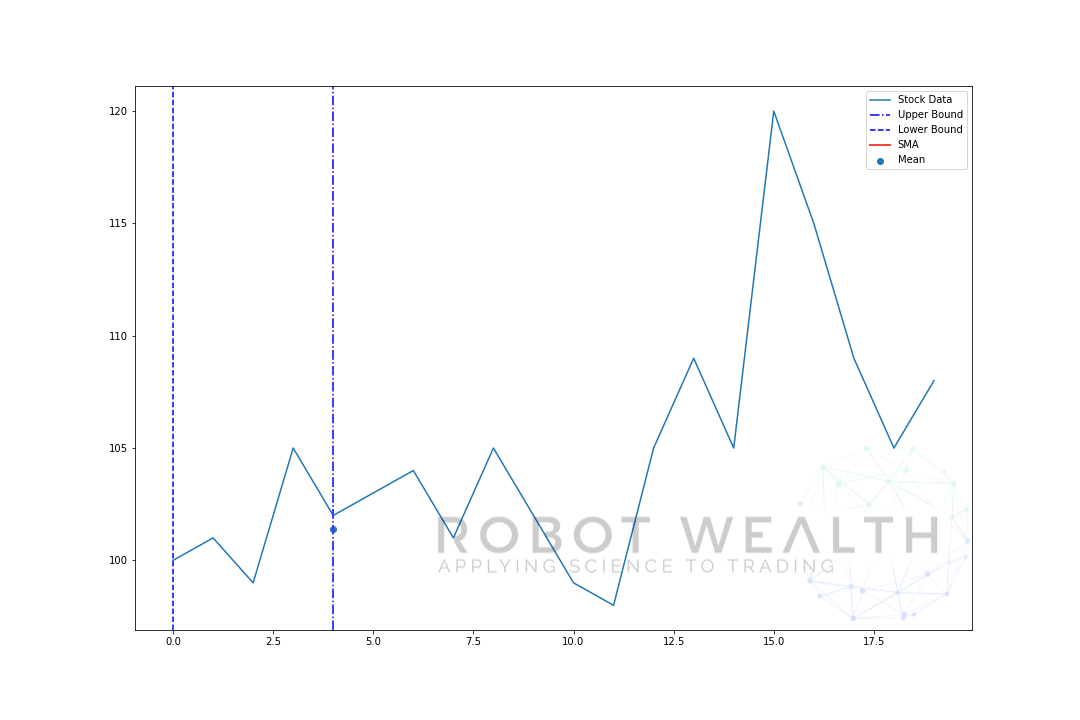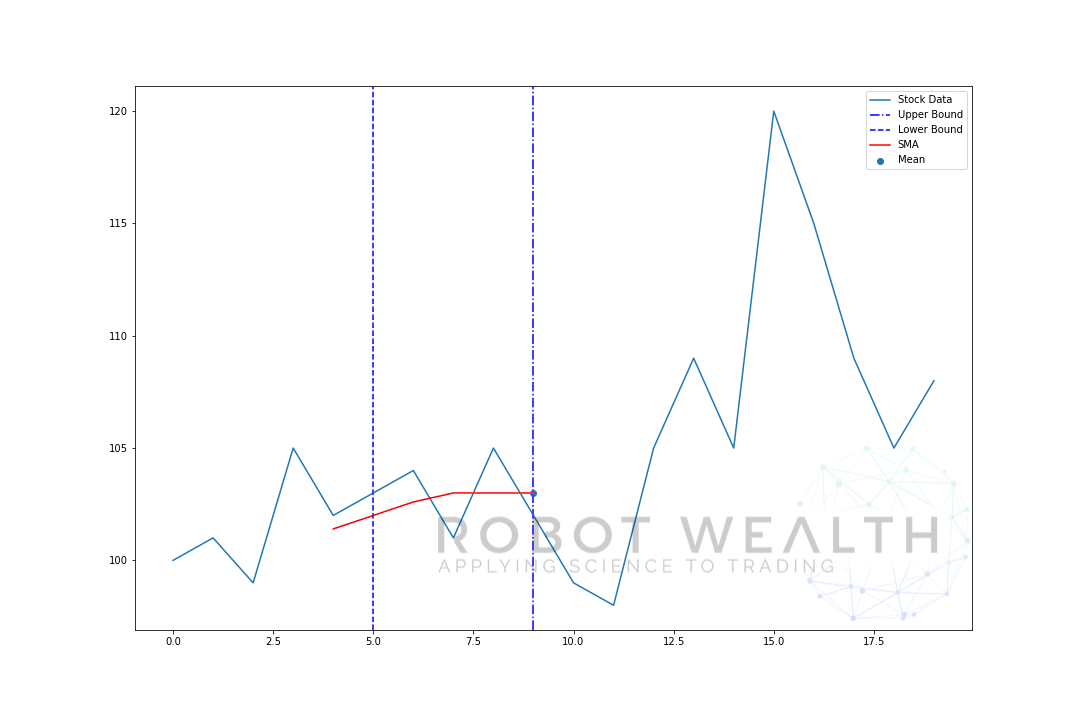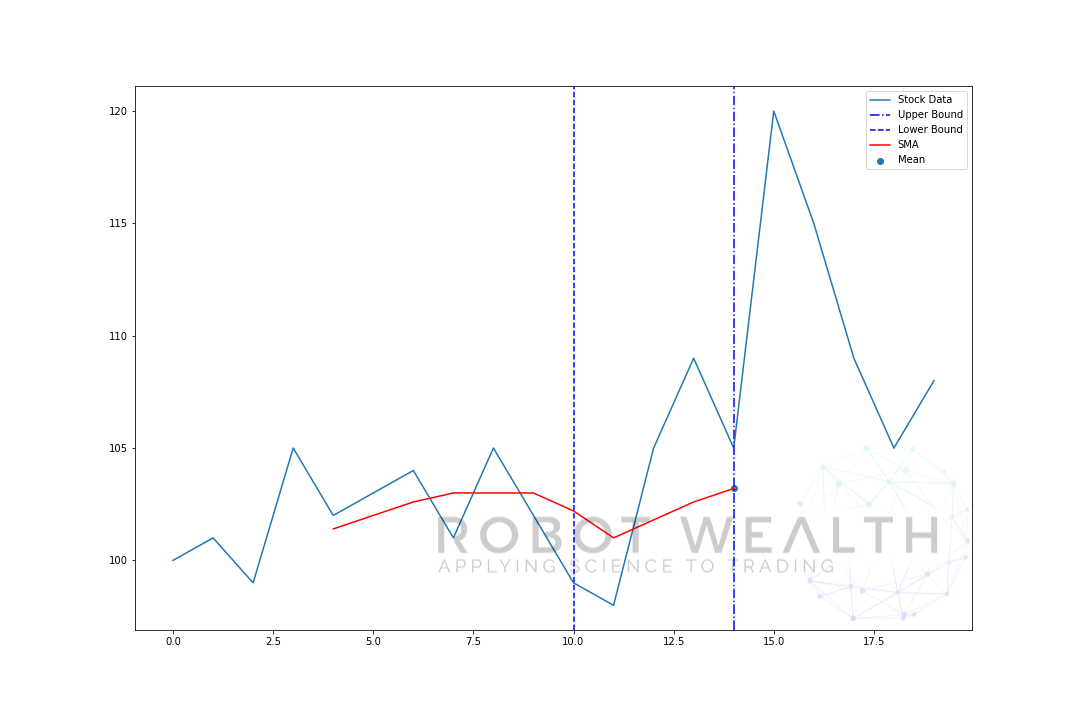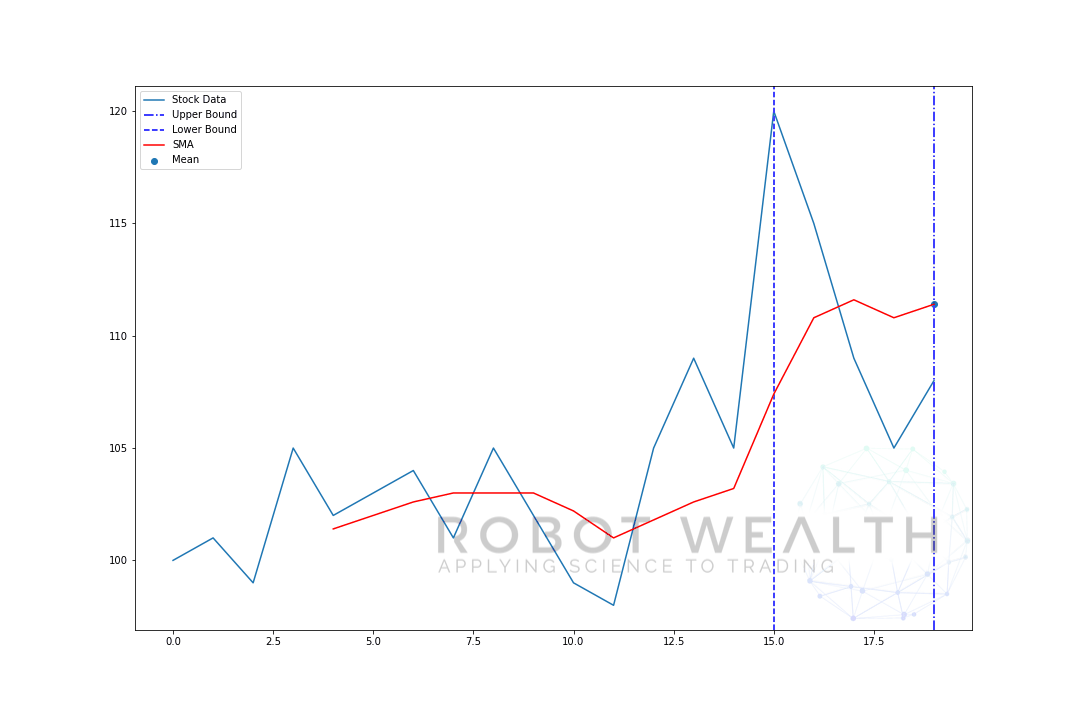
#Random stock pricesdata = #Create pandas DataFrame from listdf = pd.DataFrame(data,columns=)#Calculate a 5 period simple moving averagesma5 = df.rolling(window=5).mean()#Plotplt.plot(df,label='Stock Data')plt.plot(sma5,label='SMA',color='red')plt.legend()plt.show()
więc Podzielmy ten wykres.
- mamy 20 dni cen akcji na tym wykresie, oznaczonych danymi giełdowymi.
- dla każdego punktu w czasie (niebieska kropka) chcemy wiedzieć, jaka jest średnia cena dnia 5.
- dane giełdowe użyte do obliczeń to dane pomiędzy dwoma niebieskimi pionowymi liniami.
- po obliczeniu średniej z 0-5 Nasza średnia dla dnia 5 staje się dostępna.
- aby uzyskać średnią dla dnia 6 musimy przesunąć okno o 1 tak, okno danych staje się 1-6.
i to jest to, co jest znane jako okno rolowane, rozmiar okna jest stały. Wszystko co robimy, to przesuwamy to do przodu.
jak zapewne zauważyliście nie mamy wartości SMA dla punktów 0-4. Dzieje się tak, ponieważ nasz rozmiar okna (znany również jako okres lookback) wymaga co najmniej 5 punktów danych do obliczenia.
Rozszerzanie okien
tam, gdzie okna zwijane mają stały rozmiar, okna rozwijane mają stały punkt początkowy i zawierają nowe dane, gdy stają się dostępne.
oto sposób, w jaki lubię o tym myśleć:
„jaka jest średnia przeszłych n wartości w tym momencie w czasie?”- Użyj toczących się okien.
” jaka jest średnia wszystkich danych dostępnych do tego momentu?”- Użyj rozszerzających się okien.
okna rozwijane mają stałą dolną krawędź. Tylko górna krawędź okna jest rozwijana do przodu (okno staje się większe).
wizualizujmy rozwijające się okno z tymi samymi danymi z poprzedniego wykresu.
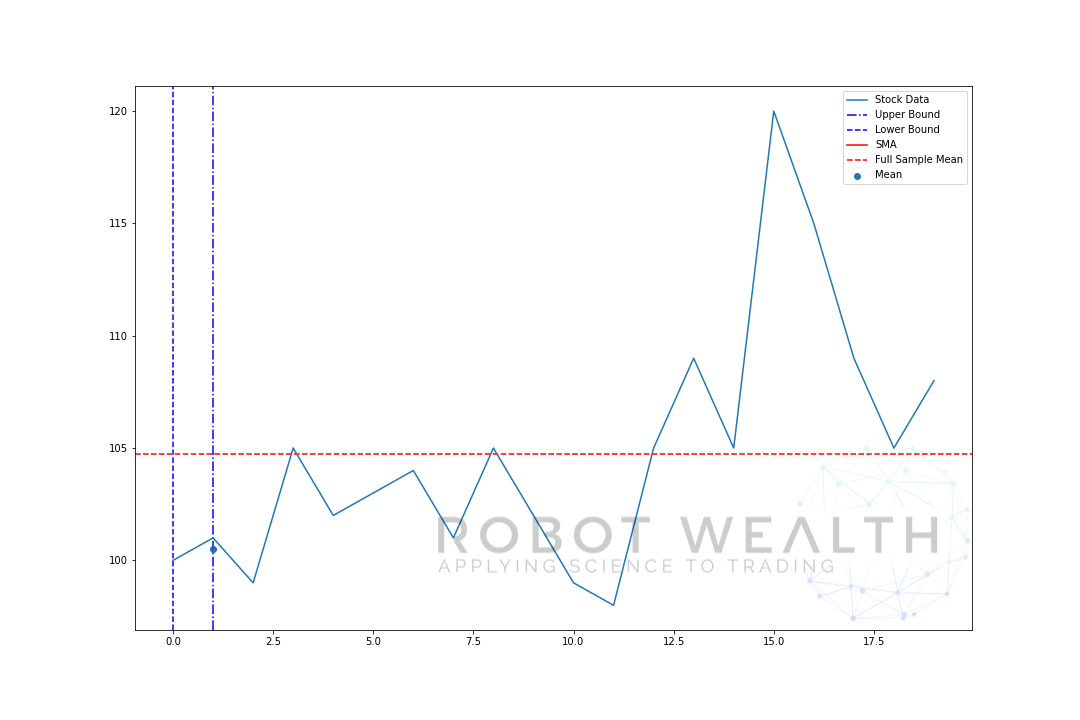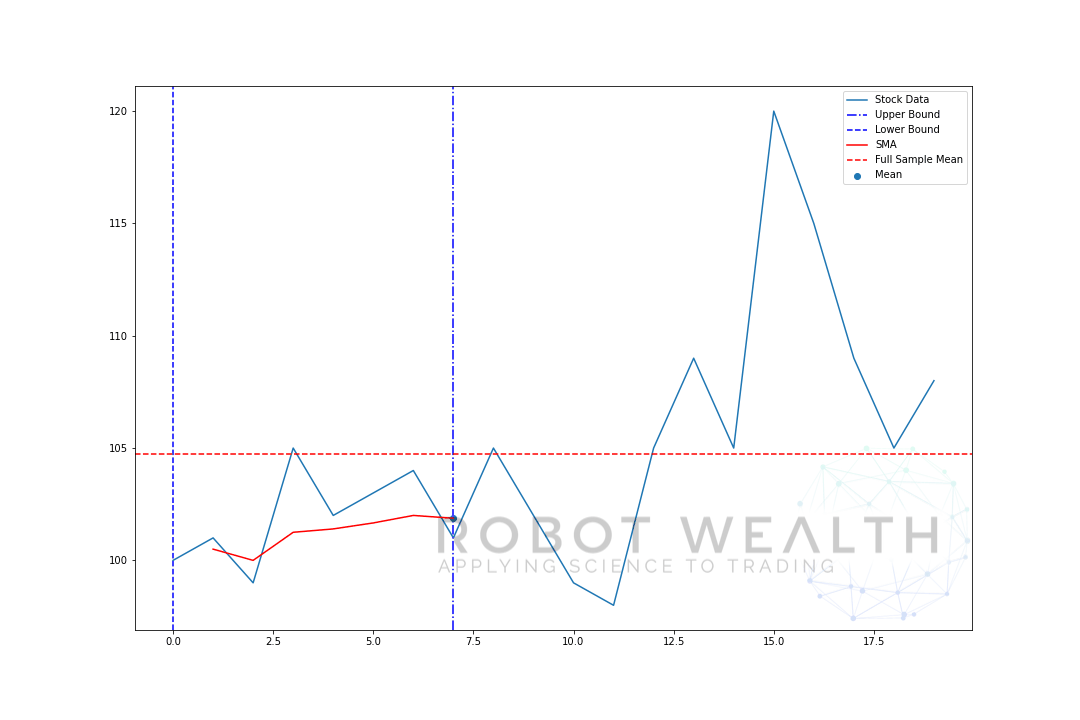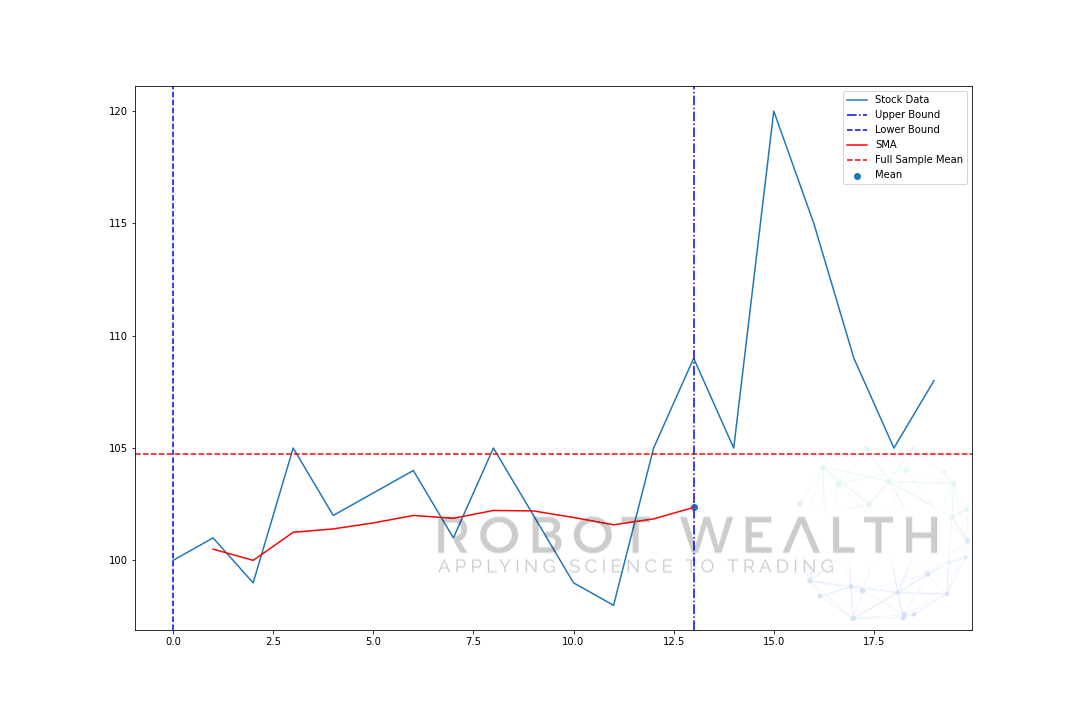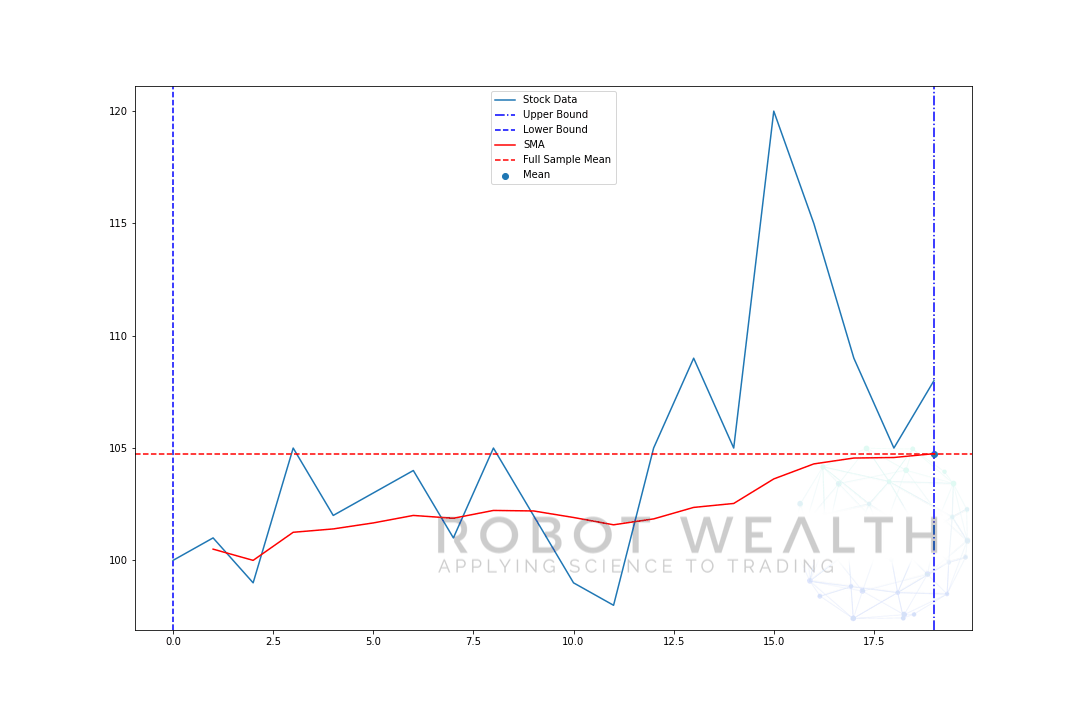
#Random stock prices data = #Create pandas DataFrame from list df = pd.DataFrame(data,columns=) #Calculate expanding window meanexpanding_mean = df.expanding(min_periods=1).mean()#Calculate full sample mean for referencefull_sample_mean = df.mean()#Plot plt.plot(df,label='Stock Data') plt.plot(expanding_mean,label='Expanding Mean',color='red')plt.axhline(full_sample_mean,label='Full Sample Mean',linestyle='--',color='red')plt.legend()plt.show()
widać, że na początku SMA jest nieco roztrzęsiony. To dlatego, że mamy mniejszą liczbę punktów danych na początku wykresu, a gdy otrzymujemy więcej danych, okno rozszerza się, aż w końcu średnia rozwijająca się zbliża się do średniej pełnej próbki, ponieważ okno osiągnęło Rozmiar całego zestawu danych.
podsumowanie
ważne jest, aby nie wykorzystywać danych z przyszłości do analizy przeszłości. Zwijanie i rozszerzanie okien to podstawowe narzędzia, które pomagają „przesyłać dane do przodu”, aby uniknąć tych problemów.
jeśli ci się to spodobało, prawdopodobnie spodoba ci się to również…
manipulacja danymi finansowymi w dplyr dla Traderów Quant
wykorzystanie cyfrowego przetwarzania sygnałów w ilościowych strategiach handlowych
błąd testowania: czuje się dobrze, dopóki nie wybuchnie