Ce n’est pas maintenant un jour Big data.. »histoire qui a donné naissance à cette ère du big data mais ‘Il y a longtemps… » les humains ont commencé à collecter des informations via des enquêtes manuelles, des sites Web, des capteurs, des fichiers et d’autres méthodes de collecte de données. Même cela inclut des organisations internationales comme l’OMS, l’ONU qui ont collecté au niveau international tous les ensembles d’informations possibles pour le suivi et le suivi des activités non seulement liées aux humains mais à la végétation et aux espèces animales afin de prendre des décisions importantes et de mettre en œuvre les actions requises.
Ainsi, les grandes multinationales, en particulier les entreprises de commerce électronique et de marketing, ont commencé à utiliser la même stratégie pour suivre et surveiller les activités des clients afin de promouvoir les marques et les produits, ce qui a donné naissance à la branche analytique. Maintenant, il ne va pas saturer si facilement que les entreprises ont réalisé la valeur réelle des données pour prendre des décisions fondamentales à chaque phase du projet du début à la fin afin de créer les meilleures solutions optimisées en termes de coût, de quantité, de marché, de ressources et d’améliorations.
Les V du Big Data sont le volume, la vitesse, la variété, la véracité, la valence et la valeur et chacun a un impact sur la collecte, la surveillance, le stockage, l’analyse et le reporting des données. L’écosystème en termes d’acteurs technologiques du système big data est comme indiqué ci-dessous.

Maintenant, je vais discuter de chaque technologie une par une pour donner un aperçu de ce que les composants et les interfaces importants.
Comment extraire des données de médias sociaux de Facebook, Twitter et linkedin dans un simple fichier csv pour un traitement ultérieur.Facebook Pour pouvoir extraire des données à l’aide d’un code python, vous devez vous inscrire en tant que développeur sur Facebook, puis disposer d’un jeton d’accès. Voici les étapes pour cela.
1. Aller au lien developers.facebook.com , créez-y un compte.
2. Aller au lien developers.facebook.com/tools/explorer .
3. Allez dans la liste déroulante « Mes applications » dans le coin supérieur droit et sélectionnez « Ajouter une nouvelle application ». Choisissez un nom d’affichage et une catégorie, puis « Créer un ID d’application » »
4. Revenez au même lien developers.facebook.com/tools/explorer . Vous verrez « Explorateur d’API graphique » sous « Mes applications » dans le coin supérieur droit. Dans le menu déroulant « Explorateur d’API graphique », sélectionnez votre application.
5. Ensuite, sélectionnez « Obtenir un jeton ». Dans ce menu déroulant, sélectionnez « Obtenir un jeton d’accès utilisateur » » Sélectionnez autorisations dans le menu qui apparaît, puis sélectionnez « Obtenir un jeton d’accès. »
6. Aller au lien developers.facebook.com/tools/accesstoken . Sélectionnez « Déboguer » correspondant à « Jeton utilisateur ». Allez dans « Étendre l’accès aux jetons « . Cela garantira que votre jeton n’expire pas toutes les deux heures.
Code Python pour accéder aux données publiques de Facebook:
Allez sur le lien https://developers.facebook.com/docs/graph-api si vous souhaitez collecter des données sur tout ce qui est disponible publiquement. Voir https://developers.facebook.com/docs/graph-api/reference/v2.7/. Dans cette documentation, choisissez le champ de votre choix à partir duquel vous souhaitez extraire des données telles que « groupes » ou « pages », etc. Accédez à des exemples de codes après les avoir sélectionnés, puis sélectionnez « api graphique facebook » et vous obtiendrez des conseils sur la façon d’extraire des informations. Ce blog est principalement sur l’obtention de données d’événements.
Tout d’abord, importez ‘urllib3’, ‘facebook’, ‘requests’ si elles sont déjà disponibles. Sinon, téléchargez ces bibliothèques. Définissez un jeton variable et définissez sa valeur sur ce que vous avez ci-dessus en tant que « Jeton d’accès utilisateur ».

Extraction des données de Twitter:
2 étapes simples peuvent être suivies comme ci-dessous
- Vous prêterez sur la page de détails de l’application; passez à l’onglet « Clés et jetons d’accès », faites défiler vers le bas et cliquez sur « Créer mon jeton d’accès ». Notez les valeurs de la clé de l’API et du secret de l’API pour une utilisation future. Tu ne les partageras avec personne, on peut accéder à votre compte s’ils obtiennent les clés.
- Pour extraire les tweets, vous devrez établir une connexion sécurisée entre R et Twitter comme suit,
# Effacer l’environnement R
rm(list=ls())
# Charger les bibliothèques requises
installer.paquets (« twitteR »)
installer.packages(« ROAuth »)
library(« twitteR »)
library(« ROAuth »)
# Téléchargez le fichier et stockez-le dans votre répertoire de travail
download.le fichier (url= »http://curl.haxx.se/ca/cacert.pem », destfile= »cacert.pem »)
# Insérez votre consumerKey et consumerSecret ci-dessous
informations d’identification < – OAuthFactory$new(consumerKey=’XXXXXXXXXXXXXXXXXX’,
consumerSecret=’XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX’,
requestURL=’e n’ai pas de problème avec le fait que je n’ai pas de problème avec le fait que je n’ai pas de problème avec le fait que je n’ai pas de problème avec le fait que je n’ai pas de problème avec le fait que je n’ai pas de problème avec le fait que je n’ai pas de problème avec le fait que je n’ai pas de problème avec le fait que je n’ai pas de problème avec le fait que je n’ai pas de problème avec le fait que je n’ai pas de problème avec le fait que je n’ai pas de problème avec le fait que je n’ai pas de problème avec le fait que je n’ai pas de problème avec le fait que je n’ai pas de problème avec le fait que je n’ai pas de problème avec le fait que je n’ai pas de problème avec le fait que je n’ai pas de problème avec le fait que je n’ai pas de problème avec le fait que je n’ai pas de problème avec le fait que je n’ai pas de problème avec le fait que je n’ai pas de problème.pem »)
# Charger les données d’authentification
load(« authentification twitter.Rdata »)
# Enregistrer l’authentification Twitter
setup_twitter_oauth(credentials$consumerKey, credentialsconsumconsumerSecret, credentialsooauthKey, credentialsooauthSecret)
# Extraire les Tweets avec la chaîne concernée (premier argument), suivi du nombre de tweets (n) et de la langue (lang)
tweets < – searchTwitter(‘#DataLove’, n=10 , lang= »fr »)
Vous pouvez maintenant rechercher n’importe quel mot dans la fonction de recherche Twitter pour extraire les tweets contenant le mot.
Extraction de données à partir d’Oracle ERP
Vous pouvez visiter le lien pour vérifier l’extraction étape par étape du fichier csv à partir de la base de données oracle ERP cloud.
Acquisition et stockage des données:
Maintenant, une fois les données extraites, elles doivent être stockées et traitées, ce que nous faisons dans l’étape d’acquisition et de stockage des données.
Voyons comment fonctionne Spark, Cassandra, Flume, HDFS, HBASE.
Spark
Spark peut être déployé de différentes manières, fournit des liaisons natives pour les langages de programmation Java, Scala, Python et R, et prend en charge SQL, le streaming de données, l’apprentissage automatique et le traitement de graphiques.
RDD est le framework de spark qui aidera au traitement parallèle des données en les divisant en trames de données.
Pour lire les données de la plate-forme Spark, utilisez la commande ci-dessous
results=spark.sql(« Select* From people »)
noms = résultats.carte (lambda p: p.name )
Connectez-vous à n’importe quelle source de données comme json, JDBC, Hive à Spark en utilisant des commandes et des fonctions simples. Comme vous pouvez lire les données json comme ci-dessous
spark.lire.json(« s3n://… »).registerTempTable(« json »)
results=spark.sql(« SELECT * FROM people JOIN json JOIN »)
Spark se compose de plus de fonctionnalités comme le streaming à partir de sources de données en temps réel que nous avons vu ci-dessus en utilisant la source R et python.
Dans le site Web principal d’apache spark, vous trouverez de nombreux exemples qui montrent comment spark peut jouer un rôle dans l’extraction de données, la modélisation.
https://spark.apache.org/examples.html
Cassandra:
Cassandra est également une technologie Apache comme spark pour le stockage et la récupération de données et le stockage dans plusieurs nœuds pour fournir une tolérance aux pannes de 0. Il utilise des commandes de base de données normales telles que les opérations de création, de sélection, de mise à jour et de suppression. Vous pouvez également créer des index, une vue matérialisée et normale avec des commandes simples comme dans SQL. L’extension est que vous pouvez utiliser le type de données JSON pour effectuer des opérations supplémentaires comme ci-dessous
Insérer dans mytable JSON ‘{« \ »MyKey \ » »: 0, « value »: 0}’
Il fournit des pilotes open source git hub à utiliser avec .net, Python, Java, PHP, NodeJS, Scala, Perl, ROR.
Lors de la configuration de la base de données, vous devez configurer le nombre de nœuds par noms de nœuds, allouer un jeton en fonction de la charge sur chaque nœud. Vous pouvez également utiliser les commandes d’autorisation et de rôle pour gérer l’autorisation au niveau des données sur un nœud donné.
Pour plus de détails, vous pouvez vous référer au lien donné
http://cassandra.apache.org/doc/latest/configuration/cassandra_config_file.html
Casandra promet d’atteindre une tolérance aux pannes de 0 car il fournit plusieurs options pour gérer les données sur un nœud donné par la mise en cache, la gestion des transactions, la réplication, la concurrence pour la lecture et l’écriture, les commandes d’optimisation du disque, gérer le transport et la longueur de la taille des trames de données.
HDFS
Ce que j’aime le plus chez HDFS, c’est son icône, un éléphant géant puissant et résilient comme HDFS lui-même.
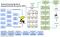
Comme on le voit dans le diagramme ci-dessus, le système HDFS pour le big data est similaire à Cassandra mais fournit une interface très simple avec des systèmes externes.
Les données sont découpées dans des trames de données de taille différente ou similaire qui sont stockées dans un système de fichiers distribué. Les données sont ensuite transférées vers divers nœuds en fonction des résultats de requête optimisés pour stocker les données. L’architecture de base est un modèle centralisé du modèle Hadoop if Map reduce.
1. Les données sont divisées en blocs de disons 128 Mo
2. Ces données sont ensuite réparties sur différents nœuds
3. HDFS supervise le traitement
4. La réplication et la mise en cache sont effectuées pour obtenir une tolérance aux pannes maximale.
5. une fois la carte et la réduction effectuées et les travaux calculés avec succès, ils retournent au serveur principal
Hadoop est principalement codé en Java, donc c’est génial si vous mettez la main sur Java, il sera rapide et facile à configurer et à exécuter toutes ces commandes.
Un guide rapide pour tout le concept lié à Hadoop peut être trouvé au lien ci-dessous
https://www.tutorialspoint.com/hadoop/hadoop_quick_guide.html
Reporting et visualisation
Parlons maintenant de SAS, R studio et Kime qui sont utilisés pour analyser de grands ensembles de données à l’aide d’algorithmes complexes qui sont des algorithmes d’apprentissage automatique basés sur des modèles mathématiques complexes qui analysent un ensemble de données complet et créent la représentation graphique pour atteindre l’objectif commercial spécifique souhaité. Exemples de données de vente, potentiel du marché client, utilisation des ressources, etc.
SAS, R et Kinme les trois outils offrent un large éventail de fonctionnalités allant de l’analyse avancée, l’IOT, l’apprentissage automatique, les méthodologies de gestion des risques, l’intelligence de sécurité.
Mais comme parmi eux l’un est commercial et les 2 autres sont open source, ils présentent des différences majeures entre eux.
Au lieu de les parcourir un par un, j’ai résumé chacune des différences logicielles et quelques conseils utiles qui en parlent.
