Le but de cet article est d’expliquer la redondance en termes de calcul, de mise en réseau et d’hébergement. Nous fournirons des exemples concrets de solutions technologiques redondantes pour illustrer ce qu’est la redondance et son fonctionnement.
Atlantic.Net a créé plusieurs environnements d’hébergement, y compris une plate-forme cloud durable, un hébergement VPS haut débit, une infrastructure conforme à la norme HIPAA et un hébergement cloud privé géré. Tous nos systèmes sont construits avec la redondance comme facteur moteur principal du processus de conception.
Dans l’anglais de tous les jours, la redondance peut avoir une connotation négative; quelque chose de redondant n’est généralement pas nécessaire ou considéré comme superflu. Cependant, dans un environnement d’hébergement cloud, la redondance peut faire la différence entre une disponibilité transparente du système et des temps d’arrêt indésirables ou inattendus.
- Qu’est-Ce qu’un Système Redondant ?
- Types de systèmes redondants
- Exemples de Services logiciels redondants
- Réplique Hyper-V
- Clustering Hyper-V
- HAProxy
- Heartbeat
- Exemples de services matériels redondants
- RAID
- Redondance réseau
- Protocoles de redondance de premier saut (FHRP)
- Virtual Router Redundancy Protocol (VRRP)
- Protocole HSRP (Hot Standby Router Protocol)
- Gateway Load Balancing Protocol (GLBP)
- Redondance des centres de données
- Conclusion
Qu’est-Ce qu’un Système Redondant ?
Un système redondant prend en charge le basculement ou l’équilibrage de charge pour protéger un système actif en cas de panne inattendue. En cas de panne électrique, mécanique ou logicielle, un système redondant aura un composant ou une plate-forme en double sur lequel se rabattre. En général, tout composant d’un système avec un point de défaillance unique peut être considéré comme un risque pour les services de production.
Les systèmes électriques ou mécaniques ont des stratégies de repli plus simples nécessitant la simple présence d’un autre service du même type; les basculements logiciels nécessitent généralement une configuration supplémentaire sur le système hôte ou un maître ou une passerelle.
Les capacités de redondance sont recommandées pour tout système critique, mais en particulier pour les systèmes qui ont un impact significatif pendant les temps d’arrêt. Certaines entreprises peuvent conserver toutes les informations critiques de leurs clients dans une base de données; par conséquent, à des fins de continuité des activités, la protection de cette base de données par redondance protégera l’intégrité des données en cas de défaillance catastrophique.
Types de systèmes redondants
Un système redondant se compose d’au moins deux systèmes interconnectés et conçus dans le même but. Il existe de nombreux types de configurations de système redondantes disponibles, et différentes implémentations du système fournissent des approches uniques pour maintenir un système en place à tout moment.
Tous les serveurs n’ont pas besoin d’être configurés avec redondance ; au contraire, seuls les plus critiques doivent être pris en compte. Nous recommandons fortement une évaluation détaillée des risques pour comprendre la portée des serveurs et la quantité maximale de temps d’arrêt que vos serveurs peuvent gérer. Utilisez cette évaluation pour déterminer une stratégie RTO (Objectif de Temps de rétablissement) et RPO (Objectif de Point de rétablissement). RTO est la quantité maximale de temps d’arrêt acceptable. Cela peut aller de 5 secondes à 24 heures. Le RPO est le moment à partir duquel vous avez besoin de vos données; par exemple, votre entreprise peut fonctionner avec une perte maximale de 24 heures de données.
Voici quelques exemples populaires :
- Actif – Inactif /Chaud-Froid – Lorsqu’un composant d’un système est le système actif et qu’un autre est inactif ou arrêté. Le composant inactif n’est activé que lorsque le composant en cours d’exécution tombe en panne ou subit une maintenance
- Actif – Actif/Chaud-Chaud – Lorsque les deux systèmes sont sous tension et établissent des connexions. Ceci est le plus communément appelé clustering. Habituellement, le périphérique devant les deux machines déterminera comment diviser le trafic entrant
- Actif-Veille / Chaud-Chaud – Lorsque les deux systèmes sont allumés, mais qu’un seul établit des connexions. Le deuxième système est destiné à recevoir périodiquement des mises à jour ou des sauvegardes du système principal. En cas de panne, le système en veille joue le rôle principal jusqu’à ce que le système initial puisse être récupéré.
Chaque type a ses avantages et ses inconvénients.
- Les systèmes Actifs-Inactifs/Chauds-Froids peuvent fournir une plate-forme redondante simple, mais tout basculement entraînera l’affichage d’une ancienne version du système par les utilisateurs.
- Actif -Actif/Chaud-Chaud nécessitera une mise à jour constante des deux systèmes, soit manuellement, soit via un service distinct, pour s’assurer que tous les utilisateurs peuvent utiliser l’un ou l’autre système. Cette approche peut réduire considérablement la charge active d’un service que vous fournissez aux clients.
- Active-Standby / Hot-Warm fournira les capacités de basculement de hot-cold avec une copie plus à jour de votre système actif lors du basculement, mais il ne fournit aucun allégement de charge.
D’autres formes de redondance à nœuds multiples sont disponibles qui permettent une plus grande redondance et des solutions d’équilibrage de charge robustes. À ce stade, vous disposerez d’un cluster haute disponibilité, également appelé cluster HA.
Ceci peut utiliser n’importe quelle combinaison des solutions de redondance notées précédemment avec une flexibilité maximale dans l’approche ou la quantité de redondance nécessaire. Les clusters HA peuvent également être configurés sur plusieurs emplacements physiques pour permettre une disponibilité jusqu’au niveau du backbone Internet.
Exemples de Services logiciels redondants
En l’absence d’une faible disponibilité des ressources, il y a très peu de raisons de ne pas avoir de réplication propriétaire ou de services redondants configurés dans un environnement virtuel ; ainsi, de nombreux services de ce type sont disponibles par défaut dans la plupart des systèmes de virtualisation. Tous nos services cloud disposent d’une réplication, une fonctionnalité qui nous permet de répliquer n’importe quel serveur d’un nœud à un autre, qu’il se trouve dans le même centre de données ou dans des régions de centre de données distinctes.
Réplique Hyper-V
La réplique Hyper-V est une forme de redondance chaud-chaud. Une machine virtuelle principale est créée sur un hôte physique et accepte les connexions entrantes. Lors de l’activation de la réplication, les disques durs virtuels de la nouvelle machine sont transférés vers un hôte Hyper-V physique distinct. Cet hôte configure ensuite une machine virtuelle sur elle-même qui se réplique selon une planification définie par l’utilisateur pour s’assurer que l’image la plus récente du serveur actif est prise. Des points de contrôle supplémentaires peuvent également être conservés. L’hébergement privé Hyper-V avec services gérés est fourni par Atlantic.Net avec cette fonctionnalité intégrée, contactez notre équipe pour plus d’informations.
Clustering Hyper-V
Hyper-V est également capable de clustering via une connexion à d’autres hôtes Hyper-V. Les machines virtuelles sur n’importe quel hôte Hyper-V peuvent être regroupées sur cet hôte singulier pour fournir une redondance au niveau local via un réseau virtuel.
Microsoft Network Load Balancing (NLB) peut être utilisé pour créer une ressource unique composée de plusieurs hôtes qui partagent les mêmes informations afin de fournir un point d’accès simple pour le partage de fichiers. Comme cela n’est limité que par la quantité de ressources dont vous disposez, vous pouvez théoriquement configurer plusieurs hôtes avec plusieurs machines virtuelles pour une redondance maximale, ce qui vous permettrait également d’effectuer une maintenance sur des machines virtuelles individuelles sans sacrifier la disponibilité des services ou des ressources. L’hébergement privé Hyper-V avec services gérés est fourni par Atlantic.Net avec cette fonctionnalité intégrée, contactez notre équipe pour plus d’informations.
HAProxy
Mis à part Hyper-V, un périphérique de passerelle tel qu’un pare-feu peut être utilisé pour des services de basculement ou d’équilibrage de charge. Par exemple, Atlantique.Net peut fournir à pfSense un proxy haute disponibilité, également appelé HAProxy.
HAProxy agira comme un équilibreur de charge, un proxy ou une simple solution de haute disponibilité à chaud pour les applications TCP et HTTP. HAProxy est une solution open source très populaire basée sur Linux utilisée par certains des sites les plus visités au monde.
Heartbeat
Heartbeat est un service disponible sur la plupart des distributions de Linux qui est utilisé pour déterminer si les nœuds d’un cluster sont toujours actifs ou réactifs. Il est très simple à configurer et fournit des capacités de basculement à tout système fonctionnant sur TCP.
Les développeurs de Heartbeat recommandent également d’autres gestionnaires de ressources de cluster qui démarrent ou arrêtent des services selon qu’un hôte particulier est en panne ou non. Heartbeat a ceci inclus, mais d’autres gestionnaires sont disponibles. En raison de la simplicité de Heartbeat, il est hautement personnalisable. Plateformes d’hébergement Cloud fournies par Atlantic.Net cette fonctionnalité est déjà intégrée et nous pouvons vous aider à implémenter Heartbeat sur votre propre distribution Linux privée, si nécessaire.
Exemples de services matériels redondants
La meilleure partie du matériel redondant est sa simplicité. Alors que les services logiciels peuvent nécessiter une configuration excessive et sont peut-être assez sensibles, le matériel est généralement très simple à configurer et incroyablement durable. Le premier exemple que nous examinerons est la technologie RAID largement utilisée.
RAID
RAID signifie Réseau Redondant de Disques Indépendants (ou Réseau Redondant de Disques peu coûteux en fonction de la durée de votre utilisation) et possède plusieurs niveaux utilisés soit pour la protection des données, soit pour augmenter les E/S de disque.
RAID peut être configuré via un contrôleur logiciel ou matériel. Le contrôleur dispose du logiciel et de la configuration nécessaires pour gérer les disques RAID. La configuration peut être exportée vers différents systèmes avec peu ou pas de configuration supplémentaire.
RAID peut être configuré de différentes manières pour fournir un bon équilibre entre ses deux qualités :
- RAID 0 – Ce n’est essentiellement pas une redondance. Aucun disque du système ne partage de données via la mise en miroir, mais toutes les données sont rayées sur chaque disque, ce qui augmente la vitesse de lecture / écriture. Chaque disque peut toujours utiliser le stockage qui lui est fourni à son maximum, ce qui signifie que plus vous ajoutez de disques à un RAID 0, plus vous aurez d’espace.
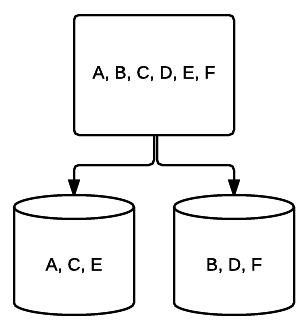
- RAID 1 – Une forme de base de mise en miroir offrant une excellente redondance au prix de l’espace. Dans un système à deux disques, une copie complète des données d’un disque est écrite sur l’autre. Cette redondance est améliorée à chaque lecteur ajouté. Étant donné que toutes les données doivent être reflétées sur tous les lecteurs, l’espace total sur le système sera limité à l’espace du plus petit lecteur du système.
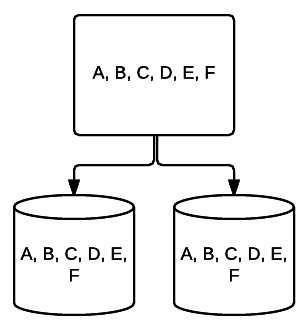
- RAID 5 – Cette forme de RAID est généralement utilisée pour augmenter la vitesse de lecture et la fiabilité. Dans ce cas, des bandes sont placées autour de chaque lecteur du système, le minimum étant de 3 lecteurs. Dans le même temps, un bloc supplémentaire de données de correction d’erreurs est placé sur chaque lecteur dans une technique appelée parité. Cela vérifie si les données sont modifiées lors du transfert d’un lecteur à un autre. Cela fournit également une forme minimale de redondance car 1 de ces lecteurs peut échouer et le système peut toujours fonctionner. Plus il y a de disques ajoutés à ce type de configuration RAID, plus votre vitesse de lecture augmente. Avec une redondance et un entrelacement minimaux sur tous les lecteurs, la quantité totale d’espace dans cette configuration est égale à la taille de votre volume RAID logique multipliée par le nombre de lecteurs que vous utilisez, moins un. Par exemple, si vous avez 5 disques 500 Go dans un RAID 5, vous auriez 2000 Go utilisables, ou 2 To (500 *(5-1)=2000).
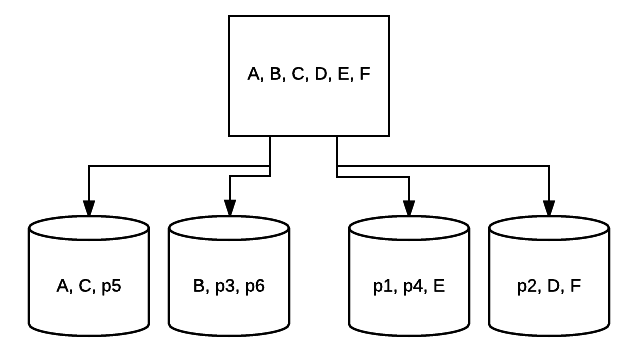
- RAID 10 – Il s’agit d’une combinaison de RAID 1 et RAID 0. Dans ce cas, toutes les données sont rayées sur chaque périphérique, des blocs de données étant également mis en miroir sur l’ensemble du système rayé. Par exemple, dans un système RAID 10 à 4 disques, 2 disques de 500 Go peuvent avoir les mêmes données, mais pas toutes les données nécessaires au bon fonctionnement du système. 2 les données d’autres lecteurs seraient nécessaires. Considérez chaque système RAID 1 comme un seul lecteur et chacun de ces systèmes placé dans une matrice RAID 0. Dans cette configuration, les performances peuvent être considérablement augmentées comme dans RAID 0, avec une certaine redondance toujours en place avec la mise en miroir. Jusqu’à la moitié des disques du système peuvent tomber en panne avant que le système ne se bloque, mais comme pour toute matrice redondante, il est préférable de remplacer les disques dès que possible. Atlantic.Net utilise RAID 10 pour tout le stockage VPS Cloud SSD.
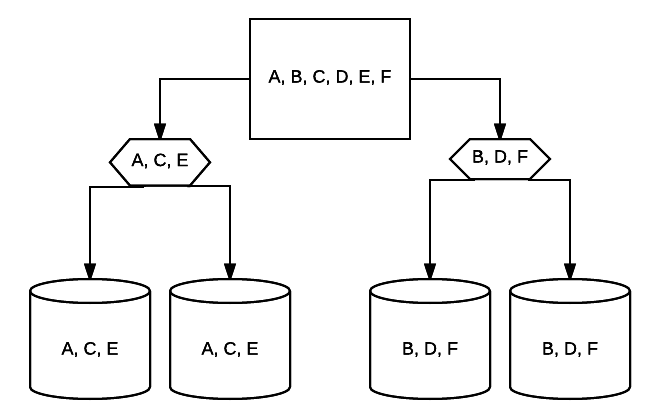
Pour une protection supplémentaire, les contrôleurs RAID sont protégés par des unités de secours sur batterie qui alimentent les puces ROM utilisées pour enregistrer la configuration en mémoire en cas de perte de puissance, etc. Une BBU alimentera une matrice RAID qui fait partie d’un système hors tension pendant une petite période de temps, permettant au contenu du cache d’un contrôleur RAID de rester intact. Cela peut être une bouée de sauvetage si les informations sont constamment introduites dans votre baie RAID et si tout temps d’arrêt peut entraîner une corruption des données.
Ainsi, votre système physique et les services qu’il contient peuvent être construits de manière redondante plutôt adéquate. Mais qu’en est-il de votre connexion à n’importe quelle partie de votre système? Comme dans, votre connexion Internet directe à votre système dans son ensemble?
Redondance réseau
Protocoles de redondance de premier saut (FHRP)
Contrairement aux protocoles de découverte de passerelle dynamique, les passerelles statiques permettent des sauts simples entre le client et leur passerelle appropriée, mais cela crée un point de défaillance unique, à savoir la passerelle elle–même.
Pour prévenir ou réduire l’impact d’une panne de passerelle, des FHRP ont été créés. Ils fournissent des passerelles redondantes, ou offrent un équilibrage de charge pour les systèmes à fort trafic, ainsi qu’une redondance. Ces protocoles incluent VRRP, HSRP et GLBP.
Virtual Router Redundancy Protocol (VRRP)
Le VRRP est une forme de redondance utilisée pour les routeurs qui nécessitent au moins deux routeurs physiquement séparés connectés via des connexions Ethernet ou fibre optique. Dans cette situation, un « routeur virtuel » contenant des routes statiques est créé et partagé entre chaque système.
Un système est considéré comme le « maître » et un autre comme la « sauvegarde ». Lorsque le maître échoue, la sauvegarde prend le relais en tant que maître suivant. Cela peut être configuré avec plusieurs sauvegardes pour une redondance supplémentaire. Le concept est très similaire à Heartbeat en ce sens que les systèmes de sauvegarde vérifieront si le maître est disponible. Une fois qu’elle ne reçoit pas de réponse, après un laps de temps prédéterminé, la sauvegarde prendra le contrôle du commutateur virtuel et acceptera les connexions pour toutes les demandes entrant pour l’adresse IP par défaut configurée pour le commutateur maître.
Protocole HSRP (Hot Standby Router Protocol)
HSRP est comme VRRP ; cependant, dans ce scénario, le commutateur virtuel configuré n’est pas un « commutateur », mais plutôt un groupe logique de plusieurs routeurs. L’adresse IP du groupe est une adresse IP non attribuée à un hôte physique. Au lieu de cela, le groupe se voit attribuer une adresse IP et l’un des routeurs est déterminé comme étant le routeur « actif « .
Un routeur de secours est prêt à prendre toutes les connexions si le routeur actif tombe en panne. Tous les routeurs en plus de l’actif et de la veille écoutent tous pour déterminer sa place en ligne. HSRP est un protocole propriétaire de Cisco et présente très peu de différences mineures avec VRRP, telles que leurs minuteries par défaut déterminant le moment du basculement. Le HSRP existe depuis un peu plus longtemps et est plus connu que le VRRP.
Gateway Load Balancing Protocol (GLBP)
Le principal avantage de GLBP par rapport au HSRP et au VRRP est sa capacité à équilibrer la charge en plus de fournir une redondance à une passerelle avec peu ou pas de configuration supplémentaire. Tout comme HSRP et VRRP, GLBP créera un groupe entre les routeurs physiques et déterminera une passerelle virtuelle active, ou AVG.
Une adresse IP virtuelle qui n’est actuellement utilisée par aucun des routeurs du groupe est affectée à l’AVG. L’AVG distribue ensuite les adresses MAC virtuelles parmi le reste des routeurs du groupe. Chaque routeur de sauvegarde est désormais considéré comme un transitaire virtuel actif, ou AVF.
Les demandes ARP envoyées à l’AVG fourniront une adresse MAC virtuelle différente au client qui envoie la demande. À ce stade, le trafic de ce client vers l’adresse IP virtuelle du groupe est transmis au routeur dont ils ont reçu l’adresse MAC virtuelle, ce qui permet à chaque routeur d’être toujours utilisé au lieu de rester les bras croisés.
En cas d’échec de l’AVG, l’élection basée sur la priorité a lieu, tout comme dans HSRP et VRRP, et la sauvegarde suivante prend sa place, distribuant les adresses MAC virtuelles normalement. Les autres routeurs conservent toujours l’adresse MAC virtuelle fournie par le MOY d’origine et les choses continuent normalement. En cas de défaillance de l’un des AVF, l’AVG empêchera le trafic de routage vers son adresse MAC virtuelle.
Tout comme HSRP, GLBP est une forme propriétaire Cisco de FHRP.
Redondance des centres de données
En plus des mesures de redondance pour vos serveurs ou routeurs personnels, les centres de données sont conçus pour résister aux défaillances du système. Les centres de données relèvent de niveaux définis par l’Uptime Institute pour fournir une tolérance aux pannes en cas de panne mécanique ou de panne de service, ce qui permet d’obtenir autant de temps de disponibilité que possible.
Il existe quatre niveaux, chacun s’appuyant les uns sur les autres pour fournir une haute disponibilité à tous les clients d’un centre de données :
- Niveau I – Capacité de base: Cela nécessite de l’espace pour un groupe informatique pour les opérations du centre de données, une alimentation sans interruption (UPS) qui surveille et filtre la consommation d’énergie et un équipement de refroidissement dédié fonctionnant en permanence 24h/ 24 et 7j/7. Cela inclut également un groupe électrogène en cas de panne de courant électrique.
- Niveau II – Composants de capacité redondants : Tout ce que le niveau I fournit, ainsi que l’alimentation et le refroidissement redondants de l’installation. Cela peut inclure des unités UPS supplémentaires ou des générateurs supplémentaires.
- Niveau III – Maintenable simultanément: Tout ce que le niveau II fournit, ainsi que de l’équipement supplémentaire en place pour éviter tout besoin d’arrêts pour le remplacement ou la maintenance de l’équipement. À ce niveau, l’alimentation et le refroidissement redondants sont appliqués directement à tous les équipements techniques, et l’équipement lui-même est configuré pour une redondance ou un basculement transparent.
- Niveau IV – Tolérance aux pannes : Tout ce que fournit le niveau III, ainsi qu’un service ininterrompu au niveau du fournisseur. Alors qu’un centre de données peut avoir de l’électricité ou de l’eau fournie par un fournisseur de ville ou d’État, une ligne secondaire de chaque service utilisé par le centre de données est requise. Cela inclut également le FAI. En cas de panne dans n’importe quelle section menant à l’équipement du client, un plan de sauvegarde est en place, prêt pour une transition transparente.
Conclusion
La redondance est devenue un terme quotidien dans l’industrie informatique en raison de la nécessité. La haute disponibilité des services offre une expérience simple et fiable à nos clients.
Que ce soit au niveau du service ou du centre de données, la redondance de votre système est un problème important et difficile à résoudre. Espérons que ce document a fait la lumière sur les options disponibles et aidera à prendre des décisions concernant la haute disponibilité à l’avenir.
Prêt à profiter de Atlantic.Net des systèmes redondants ? Contactez-nous dès aujourd’hui pour en savoir plus sur l’hébergement de serveurs dédiés avec Atlantic.Net .
=== Sources===
Concepts de base du Système redondant: http://www.ni.com/white-paper/6874/en/
Serveur froid/chaud/chaud: http://searchwindowsserver.techtarget.com/definition/cold-warm-hot-server
Clustering haute disponibilité: https://www.mulesoft.com/resources/esb/high-availability-cluster
Hyper- V Replica: https://technet.microsoft.com/en-us/library/jj134172(v=ws.11).aspx
Hyper-V and High Availability: https://technet.microsoft.com/en-us/library/hh127064.aspx
HAProxy Description: http://www.haproxy.org/#desc
HAProxy – They use it!: http://www.haproxy.org/they-use-it.html
Heartbeat: http://www.linux-ha.org/wiki/Main_Page
RAID Definition: http://searchstorage.techtarget.com/definition/RAID
Striping: http://searchstorage.techtarget.com/definition/disk-striping
RAID Battery Backup Units: https://www.thomas-krenn.com/en/wiki/Battery_Backup_Unit_(BBU/BBM)_Maintenance_for_RAID_Controllers
High-Availability – VRRP, HSRP, GLBP: http://www.freeccnastudyguide.com/study-guides/ccna/ch14/vrrp-hsrp-glbp/
Understanding VRRP: http://www.juniper.net/techpubs/en_US/junos/topics/concept/vrrp-overview-ha.html
Configuring VRRP: http://www.cisco.com/c/en/us/td/docs/ios-xml/ios/ipapp_fhrp/configuration/15-mt/fhp-15-mt-book/fhp-vrrp.html
Configuring GLBP: http://www.cisco.com/c/en/us/td/docs/ios-xml/ios/ipapp_fhrp/configuration/xe-3s/fhp-xe-3s-book/fhp-glbp.html
Explaining the Uptime Institute’s Tier Classification System: https://journal.uptimeinstitute.com/explaining-uptime-institutes-tier-classification-system/