Par: Arshad Ali | Mise à jour: 2020-07-29 |Commentaires (6) |Connexes:Plus >Tables de JOINTURE
- Problème
- Solution
- La jointure de boucles imbriquées SQL Server expliquée
- Script #1 – Exemple de jointure de boucles imbriquées
- La jointure de fusion SQL Server expliquée
- Script #2 – Exemple de jointure de fusion
- Explication de la jointure de hachage SQL Server
- Script #3 – Exemple de jointure de hachage
- Étapes suivantes
- About the author
Problème
Dans les exemples de jointures de SQL Server, Jeremy Kadlec a parlé de différents opérateurs de jointure logiques, mais comment SQL Server les implémente-t-il physiquement? Quels sont les différents joinoperators physiques ? En quoi sont-ils différents les uns des autres et dans quel scénario est-on préféréau-dessus des autres? Dans cette astuce, nous couvrons ces questions et plus encore.
Solution
Nous utilisons des opérateurs logiques lorsque nous écrivons des requêtes pour définir une requête relationnelle au niveau conceptuel (ce qui doit être fait). SQL implémente ces opérateurs logiques avec trois opérateurs physiques différents pour implémenter l’opération définie par les opérateurs logiques (comment cela doit être fait). Bien qu’il existe des dizaines de physiquesopérateurs, dans cette astuce, je couvrirai des opérateurs de jointure physiques spécifiques. Bien que nous ayons différents types de jointures logiques au niveau conceptuel / de la requête, SQL Serverimplements les applique toutes avec trois opérateurs de jointure physiques différents comme indiqué ci-dessous.
Nous couvrirons:
- Jointure de boucles imbriquées
- Jointure de fusion
- Jointure de hachage
Nous examinerons les plans d’exécution pour voir ces opérateurs et je vous expliquerai pourquoi chacun se produit.
Pour ces exemples, j’utilise la base de données Adventureworks.
La jointure de boucles imbriquées SQL Server expliquée
Avant de creuser dans les détails, laissez-moi vous dire d’abord ce qu’est une jointure de boucles imbriquées si vous êtes nouveau dans le monde de la programmation.
Une jointure de Boucles imbriquées est une structure logique dans laquelle une boucle (itération) réside à l’intérieur d’une autre, c’est-à-dire que pour chaque itération de la boucle externe toutes les itérations de la boucle interne sont exécutées/traitées.
Une jointure de boucles imbriquées fonctionne de la même manière. L’une des tables de jonction est désignéecomme table extérieure et une autre comme table intérieure. Pour chaque ligne de la table extérieure, toutes les lignes de la table intérieure sont appariées une par une si la ligne correspond àelle est incluse dans le jeu de résultats sinon elle est ignorée. Ensuite, la rangée suivante dela table extérieure est ramassée et le même processus est répété et ainsi de suite.
L’optimiseur SQL Server peut choisir une jointure de boucles imbriquées lorsque l’une des tables de jointure est petite (considérée comme la table externe) et une autre est grande (considérée comme la table interne indexée sur la colonne qui se trouve dans la jointure) et nécessite donc un minimum d’E / S et le moins de comparaisons.
L’optimiseur considère trois variantes pour une jointure de boucles imbriquées:
- les boucles imbriquées naïves se joignent dans ce cas, les écrans de recherchela table ou l’index entier
- les boucles imbriquées d’index se joignent lorsque la recherche peut utiliser un index existant pour effectuer des recherches
- les boucles imbriquées d’index temporaires se joignent si l’optimiseur crée un index temporaire dans le cadre du plan de requête et le détruit après l’exécution de la requête.
Une jointure de boucles imbriquées d’index fonctionne mieux qu’une jointure de fusion ou une jointure de hachage si un petit ensemble de lignes est impliqué. Alors que, si un grand ensemble de lignes est impliqué, la jointure des boucles testées peut ne pas être un choix optimal. Les boucles imbriquées prennent en charge presque tous les types de jointures, à l’exception des jointures externes droites et complètes, des demi-jointures droites et des demi-jointures droites.
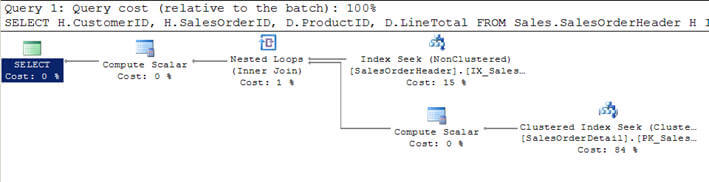
- Dans le script #1, je rejoins la table SalesOrderHeader avec SalesOrderDetailtable et je spécifie les critères pour filtrer le résultat du client avecCustomerID = 670.
- Ce critère filtré renvoie 12 enregistrements de la table SalesOrderHeader et étant donc la plus petite, cette table a été considérée comme la table supérieure (en haut du plan d’exécution de la requête graphique) par l’optimiseur.
- Pour chaque ligne de ces 12 lignes de la table externe, les lignes de la table interne SalesOrderDetail sont appariées (ou la table interne est balayée 12 fois à chaque fois pour chaque ligne en utilisant la recherche d’index ou le paramètre corrélé de la table externe) et 312 lignes correspondantes sont renvoyées comme vous pouvez le voir dans la deuxième image.
- Dans la deuxième requête ci-dessous, j’utilise SET STATISTICS PROFILE ON pour afficher les informations de profil de l’exécution de la requête avec l’ensemble de résultats de la requête.
Script #1 – Exemple de jointure de boucles imbriquées
SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader H INNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID = 670
SET STATISTICS PROFILE ONSELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader HINNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderIDWHERE H.CustomerID = 670SET STATISTICS PROFILE OFF
SET STATISTICS PROFILE ONSELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader HINNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderIDWHERE H.CustomerID = 670SET STATISTICS PROFILE OFF

Si le nombre d’enregistrements impliqués est important, SQL Server peut choisir de paralléliser une boucle imbriquée en distribuant les lignes de table externes de manière aléatoire parmi les threads de boucles disponibles. Cela ne s’applique pas de la même manière pour les tables intérieures. Pour en savoir plus sur parallel scanscliquez ici.
La jointure de fusion SQL Server expliquée
La première chose que vous devez savoir sur une jointure de fusion est qu’elle nécessite que les deux entrées soient triées sur les clés de jointure / colonnes de fusion (ou que les deux tables d’entrée ont des index en cluster sur la colonne qui joint les tables) et qu’elle nécessite également au moins une expression / prédicat equijoin (égal à).
Comme les lignes sont pré-triées, une jointure de fusion commence immédiatement le processus de correspondance. Il lit une ligne d’une entrée et la compare à la ligne d’une autre entrée.Si les lignes correspondent, cette ligne correspondante est considérée dans le jeu de résultats (elle lit la ligne suivante de la table d’entrée, fait la même comparaison / correspondance et ainsi de suite) ou la moindre des deux lignes est ignorée et le processus continue de cette façon jusqu’à ce que toutes les lignes aient été traitées..
Une jointure de fusion fonctionne mieux lors de la jonction de grandes tables d’entrée (pré-indexées / triées) car le coût est la somme des lignes dans les deux tables d’entrée par opposition aux boucles imbriquées où il s’agit d’un produit de lignes des deux tables d’entrée. Parfois, l’optimiseur décide d’utiliser une jointure de fusion lorsque les tables d’entrée ne sont pas triées et utilise donc un opérateur physique de tri explicite, mais cela peut être plus lent que d’utiliser un index (table d’entrée pré-triée).
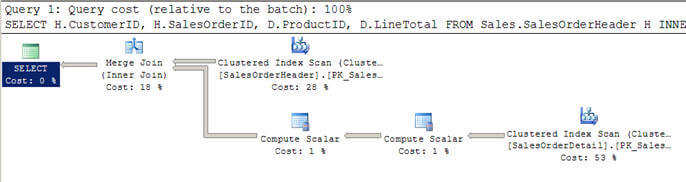
- Dans le script #2, j’utilise une requête similaire à celle ci-dessus, mais cette fois, j’ai ajouté une clause WHERE pour obtenir tous les clients supérieurs à 100.
- Dans ce cas, l’optimiseur décide d’utiliser une jointure de fusion car les deux entrées sont grandes en termes de lignes et elles sont également pré-indexées/triées.
- Vous pouvez également remarquer que les deux entrées ne sont analysées qu’une seule fois par opposition aux 12 scans que nous avons vus dans les boucles imbriquées se joindre ci-dessus.
Script #2 – Exemple de jointure de fusion
SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader H INNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID > 100
SET STATISTICS PROFILE ONSELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader HINNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderIDWHERE H.CustomerID > 100SET STATISTICS PROFILE OFF
SET STATISTICS PROFILE ONSELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader HINNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderIDWHERE H.CustomerID > 100SET STATISTICS PROFILE OFF

Une jointure de fusion est souvent un opérateur de jointure plus efficace et plus rapide si les données de tri peuvent être obtenues à partir d’un index d’arbre B existant et qu’il effectue presque toutes les opérations de jointure tant qu’il y a au moins un prédicat de jointure d’égalité impliqué. Italso prend en charge plusieurs prédicats de jointure d’égalité tant que les tables d’entrée sont triées sur toutes les clés de jointure impliquées et sont dans le même ordre.
La présence d’un opérateur scalaire de calcul indique l’évaluation d’une expressionpour produire une valeur scalaire calculée. Dans la requête ci-dessus, je sélectionne Linetotalqui est une colonne dérivée, elle a donc été utilisée dans le plan d’exécution.
Explication de la jointure de hachage SQL Server
Une jointure de hachage est normalement utilisée lorsque les tables d’entrée sont assez volumineuses et qu’il n’y a pas d’index adéquats sur elles. Une jointure de hachage est effectuée en deux phases; la phase de construction et la phase de sonde et donc la jointure de hachage ont deux entrées, c’est-à-dire l’entrée de construction et l’entrée de probeinput. La plus petite des entrées est considérée comme l’entrée de construction (pour minimiser l’exigence de mémoire pour stocker une table de hachage discutée plus loin) et l’autre est évidemment l’entrée de sonde.
Pendant la phase de construction, les clés de jonction de toutes les lignes de la table de construction sont analysées.Les hachages sont générés et placés dans une table de hachage en mémoire. Contrairement à la jointure de fusion, elle bloque (aucune ligne n’est renvoyée) jusqu’à ce point.
Pendant la phase de sonde, les touches de jonction de chaque ligne de la table de sonde sont balayées.De nouveau, des hachages sont générés (en utilisant la même fonction de hachage que ci-dessus) et comparés à la table de hachage correspondante pour une correspondance.
Une fonction de hachage nécessite une quantité importante de cycles CPU pour générer des ressources de hachage et de mémoire pour stocker la table de hachage. S’il y a une pression de mémoire, certaines partitions de la table de hachage sont échangées vers tempdb et chaque fois qu’il y a un besoin (soit de sonder ou de mettre à jour le contenu), il est ramené dans le cache.Pour atteindre des performances élevées, l’optimiseur de requête peut paralléliser une jointure de hachage à une échelle meilleure que toute autre jointure, pour plus de détails, cliquez ici.
Il existe essentiellement trois types de jointures de hachage différents:
- Jointure de hachage en mémoire, auquel cas il y a suffisamment de mémoire disponible pour stocker la table de hachage
- Jointure de hachage de grâce, auquel cas la table de hachage ne peut pas être en mémoire et certaines partitions sont déversées dans tempdb
- Jointure de hachage récursive, auquel cas une table de hachage est si grandel’optimiseur doit utiliser plusieurs niveaux de jointures de fusion.
Pour plus de détails sur ces différents typescliquez ici.
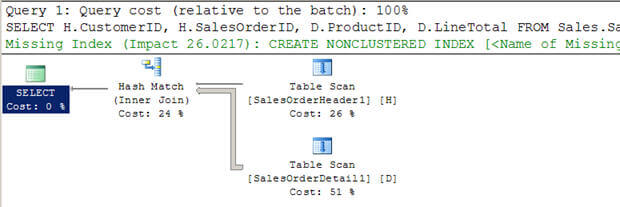
- Dans le script #3, je crée deux nouvelles grandes tables (à partir des tables AdventureWorkstables existantes) sans index.
- Vous pouvez voir que l’optimiseur a choisi d’utiliser une jointure de hachage dans ce cas.
- Encore une fois, contrairement à une jointure de boucles imbriquées, elle n’analyse pas la table interne plusieurs fois.
Script #3 – Exemple de jointure de hachage
--Create tables without indexes from existing tables of AdventureWorks database SELECT * INTO Sales.SalesOrderHeader1 FROM Sales.SalesOrderHeader SELECT * INTO Sales.SalesOrderDetail1 FROM Sales.SalesOrderDetail GO SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader1 H INNER JOIN Sales.SalesOrderDetail1 D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID = 670 GO
SET STATISTICS PROFILE ON SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader1 H INNER JOIN Sales.SalesOrderDetail1 D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID = 670 SET STATISTICS PROFILE OFF

--Drop the tables created for demonstration DROP TABLE Sales.SalesOrderHeader1 DROP TABLE Sales.SalesOrderDetail1
Remarque: SQL Server fait un très bon travail pour décider quel joinoperator utiliser dans chaque condition. Comprendre ces conditions vous aide à comprendrece qui peut être fait dans le réglage des performances. Il n’est pas recommandé d’utiliser des astuces de jointure (clause usingOPTION) pour forcer SQL Server à utiliser un opérateur de jointure spécifique (sauf si vous n’avez pas d’autre moyen), mais vous pouvez utiliser d’autres moyens comme la mise à jour des statistiques, la création d’index ou la réécriture de votre requête.
Étapes suivantes
- Commentaireserveur QQL Joignez des exemples de conseils.
- Revue des opérateurs logiques et physiques Article de référence sur technet.
Dernière mise à jour: 2020-07-29


 Arshad Ali is a SQL and BI Developer focusing on Data Warehousing projects for Microsoft.
Arshad Ali is a SQL and BI Developer focusing on Data Warehousing projects for Microsoft.View all my tips
- More Database Developer Tips…