formålet med denne artikel er at forklare redundans med hensyn til computing, netværk og hosting. Vi vil give eksempler på redundante teknologiløsninger i den virkelige verden for at illustrere, hvad redundans er, og hvordan det fungerer.
Atlantic.Net har skabt flere hostingmiljøer, herunder en holdbar skyplatform, højhastigheds VPS-hosting, HIPAA-kompatibel infrastruktur og administreret privat cloud-hosting. Alle vores systemer er bygget med redundans som en primær drivende faktor i designprocessen.
på daglig engelsk kan redundans have en negativ konnotation; noget overflødigt er normalt ikke nødvendigt eller betragtes som overflødigt. I et cloud-hostingmiljø kan redundans imidlertid betyde forskellen mellem problemfri systemtilgængelighed og uønsket eller uventet nedetid.
- Hvad er et Redundant System?
- typer af redundante systemer
- eksempler på redundante Programmeltjenester
- Hyper-V Replica
- Hyper-V Clustering
- Heartbeat
- eksempler på Redundant udstyr
- RAID
- Netværksredundans
- første Hop – Redundansprotokoller (FHRP)
- Virtual Router Redundancy Protocol (VRRP)
- Hot Standby Router Protocol (HSRP)
- Port Load Balancing Protocol (GLBP)
- Datacenterredundans
- konklusion
Hvad er et Redundant System?
et redundant system vil give failover eller load balancing support for at beskytte et live system i tilfælde af en uventet fejl. I tilfælde af strøm -, mekanisk-eller programfejl vil et redundant system have en duplikatkomponent eller platform at falde tilbage til. Generelt kan enhver komponent i et system med et enkelt fejlpunkt ses som en risiko for produktionstjenester.strøm-eller mekaniske systemer har enklere nedfaldsstrategier, der blot kræver tilstedeværelse af en anden af samme type tjeneste; programfejl kræver normalt ekstra konfiguration på værtssystemet eller en master eller port.
Redundansfunktioner anbefales til ethvert forretningskritisk system, men især til systemer, der har en betydelig indvirkning under nedetid. Nogle virksomheder kan opbevare alle deres kritiske kundeoplysninger i en database; derfor, for forretningskontinuitetsformål, beskyttelse af denne database med redundans vil beskytte dataintegriteten i tilfælde af en katastrofal fiasko.
typer af redundante systemer
et redundant system består af mindst to systemer, der er sammenkoblet og designet til samme formål. Der er mange forskellige typer redundante systemkonfigurationer tilgængelige, og forskellige implementeringer af systemet giver unikke tilgange til, hvordan man til enhver tid holder et system op.
ikke alle servere skal konfigureres med redundans; snarere bør kun de mest kritiske overvejes. Vi anbefalede stærkt detaljeret risikovurdering for at forstå, hvilke servere der er inden for rækkevidde og den maksimale nedetid, som dine servere kan håndtere. Brug denne vurdering til at bestemme en RTO (Recovery Time Objective) og RPO (Recovery Point Objective) strategi. RTO er den maksimale mængde acceptabel nedetid. Dette kan variere fra 5 sekunder til 24 timer. RPO er det tidspunkt, hvorfra du har brug for dine data; for eksempel kan din virksomhed fungere med et maksimalt tab på 24 timers værdi af data.
Her er et par populære eksempler:
- aktiv-inaktiv/varm-kold – når en komponent i et system er det aktive system, og en anden er inaktiv eller lukket ned. Den inaktive komponent aktiveres kun, når den aktuelt kørende komponent fejler eller gennemgår vedligeholdelse
- Aktiv-Aktiv/Hot-Hot – når begge systemer er live og opretter forbindelser. Dette er mest almindeligt kendt som clustering. Normalt bestemmer enheden foran begge maskiner, hvordan man opdeler indgående trafik
- aktiv-Standby/varm-varm – når begge systemer er tændt, men kun en opretter forbindelser. Det andet system er beregnet til periodisk at modtage opdateringer eller sikkerhedskopier fra det primære system. I tilfælde af en fejl tager systemet i standby den primære rolle, indtil det oprindelige system kan gendannes.
hver type har sine egne fordele og ulemper.
- Active-inaktive / varme-kolde systemer kan give en simpel redundant platform, men enhver failover vil resultere i, at brugerne ser en ældre version af systemet.
- Active-Active / Hot-Hot kræver en konstant opdatering af begge systemer, enten manuelt eller via en separat tjeneste, for at sikre, at alle brugere kan bruge begge systemer. Denne tilgang kan kraftigt reducere den aktive belastning på en service, du leverer til kunderne.
- Active-Standby / Hot-varm vil give failover kapaciteter af hot-cold med en mere up-to-date kopi af dit aktive system på failover, men det giver ikke nogen belastning lempelse.
andre former for multiple node redundans er tilgængelige, der giver mulighed for større redundans og robuste belastningsbalanceringsløsninger. På det tidspunkt har du en klynge med høj tilgængelighed, også kendt som en HA-klynge.
dette kan bruge enhver kombination af de tidligere bemærkede redundansløsninger med maksimal fleksibilitet i tilgangen eller mængden af redundans, der er nødvendig. HA-klynger kan også oprettes på tværs af flere fysiske placeringer for at give mulighed for tilgængelighed op til internet-backbone-niveauet.
eksempler på redundante Programmeltjenester
Der er meget lidt grund til ikke at have proprietære replikering eller redundante tjenester oprettet i et virtuelt miljø; således er mange sådanne tjenester tilgængelige som standard i de fleste virtualiseringssystemer. Alle vores skytjenester har replikering tilgængelig, en funktion, der giver os mulighed for at replikere enhver server fra en node til en anden, uanset om de er i det samme datacenter eller separate datacenterregioner.
Hyper-V Replica
Hyper-V Replica er en form for varm-varm redundans. En primær virtuel maskine oprettes på en fysisk vært og accepterer indgående forbindelser. Når replikering aktiveres, overføres de virtuelle harddiske på den nye maskine til en separat fysisk Hyper-V-vært. Denne vært konfigurerer derefter en VM på sig selv, der replikerer på en brugerdefineret tidsplan for at sikre, at det seneste billede af den aktive server er taget. Yderligere checkpoints punkter kan holdes så godt. Hyper-V privat hosting med administrerede tjenester leveres af Atlantic.Net med denne funktion bagt i; kontakt vores team for yderligere information.
Hyper-V Clustering
Hyper-V er også i stand til clustering gennem en forbindelse til andre Hyper-V værter. VM ‘ er på enhver Hyper-V-vært kan grupperes sammen på den enestående vært for at give redundans på lokalt niveau gennem virtuelt netværk.
Microsoft Netværksbelastningsbalancering (NLB) kan bruges til at oprette en enkelt ressource, der består af flere værter, der deler de samme oplysninger for at give et simpelt adgangspunkt til fildeling. Da dette kun er begrænset af mængden af ressourcer, du har til rådighed, kan du teoretisk oprette flere værter med flere VM ‘er for maksimal redundans, hvilket også giver dig mulighed for at udføre vedligeholdelse på individuelle VM’ er uden at ofre service eller ressourcetilgængelighed. Hyper-V privat hosting med administrerede tjenester leveres af Atlantic.Net med denne funktion bagt i; kontakt vores team for yderligere information.
bortset fra Hyper-V kan en portenhed som f.eks. en brandvæg bruges til failover-eller belastningsbalanceringstjenester. For eksempel Atlanterhavet.Net kan give Pfsense med høj tilgængelighed fuldmagt, også kendt som Haproksy. det vil fungere som en belastningsbalancer, en fuldmagt eller en simpel varm-varm høj tilgængelighedsløsning til TCP-og HTTP-baserede applikationer. Det er en meget populær open source-løsning, der bruges af nogle af de mest besøgte steder i verden.
Heartbeat
Heartbeat er en tjeneste, der er tilgængelig på de fleste distributioner af Heartbeat, der bruges til at bestemme, om noder i en klynge stadig er op eller lydhør. Det er meget simpelt at konfigurere og giver failover-funktioner til ethvert system, der arbejder over TCP.
udviklerne af Heartbeat anbefaler også andre cluster resource managers, der starter eller stopper tjenester baseret på, om en bestemt vært er nede. Heartbeat har dette inkluderet, men andre ledere er tilgængelige. På grund af Heartbeats enkelhed er det meget tilpasseligt. Cloud Hosting platforme leveret af Atlantic.Net har allerede denne funktion bagt ind, og vi kan hjælpe dig med at implementere Heartbeat på din egen private distribution, hvis det er nødvendigt.
eksempler på Redundant udstyr
det bedste ved redundant udstyr er dets enkelhed. Selvom programmeltjenester kan kræve overdreven konfiguration og muligvis er ret følsomme, er udstyret normalt meget enkelt at konfigurere og utroligt holdbart. Det første eksempel, vi vil se på, er den meget anvendte RAID-teknologi.
RAID
RAID står for Redundant Array af uafhængige diske (eller Redundant Array af billige diske afhængigt af hvor længe du har brugt det) og har flere niveauer, der bruges enten til databeskyttelse eller øget disk I/O. Controlleren har det program og den konfiguration, der er nødvendig for at styre RAID-diske. Konfigurationen kan eksporteres til forskellige systemer med lidt eller ingen yderligere konfiguration.
RAID kan konfigureres på et par forskellige måder for at give en god balance mellem begge dets kvaliteter:
- RAID 0 – Dette er i det væsentlige ingen redundans. Ingen diske på systemet deler data gennem spejling, men alle data er stribet på tværs af hver disk, hvilket giver øget læse – /skrivehastighed. Hvert drev kan stadig bruge det lager, der leveres til det fuldt ud, hvilket betyder, at jo flere drev du tilføjer til et RAID 0, jo mere plads har du.
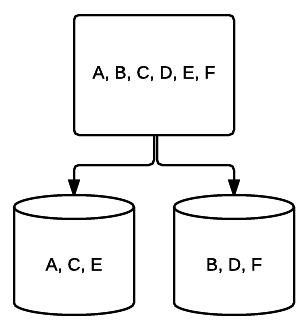
- RAID 1 – en grundlæggende form for spejling, der giver fremragende redundans på bekostning af plads. I et to-drevsystem skrives en komplet kopi af dataene på det ene drev til det andet. Denne redundans forbedres med hvert drev tilføjet. Da alle data skal spejles på tværs af alle drev, vil den samlede plads på systemet være begrænset til kun pladsen på det mindste drev i systemet.
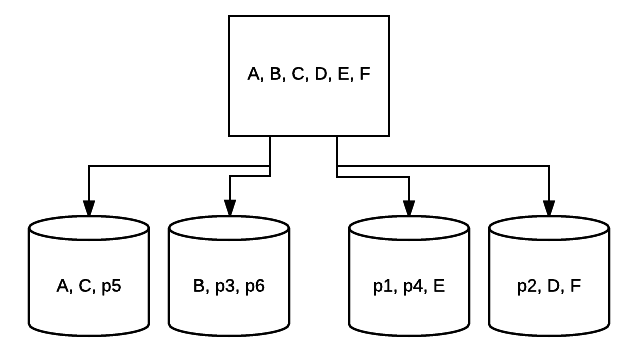
- RAID 5 – Denne form for RAID bruges normalt til at øge læsehastigheden og pålideligheden. I dette tilfælde placeres striber omkring hvert drev i systemet, hvor minimumet er 3 drev. Samtidig placeres en ekstra blok af fejlkorrigerende data om hvert drev i en teknik kaldet paritet. Dette kontrollerer, om data ændres, når de overføres fra et drev til et andet. Dette giver også en minimal form for redundans, da 1 af disse drev kan mislykkes, og systemet kan stadig køre. Jo flere drev, der føjes til denne type RAID-opsætning, jo mere øges din læsehastighed. Med minimal redundans og striping på tværs af alle drev er den samlede mængde plads i denne opsætning lig med størrelsen på din logiske RAID-lydstyrke gange antallet af drev, du bruger, minus en. For eksempel, hvis du har 5 500 GB drev i en RAID 5, ville du have 2000 GB brugbar eller 2 TB (500 *(5-1)=2000).
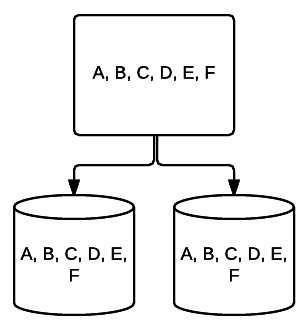
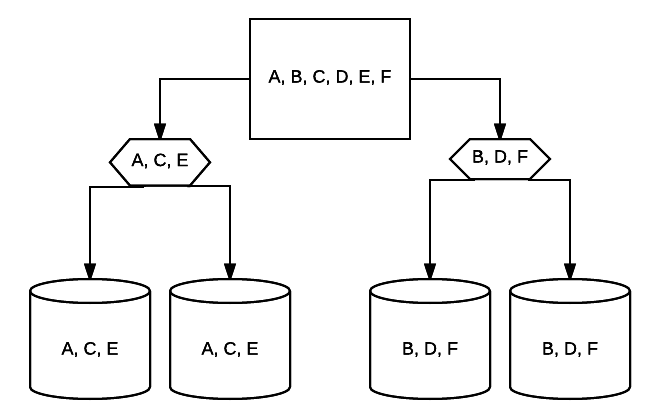
- RAID 10 – Dette er en kombination af RAID 1 og RAID 0. I dette tilfælde er alle data stribet på tværs af hver enhed med datablokke, der også spejles over hele det stribede system. For eksempel kan I et 4-drev RAID 10-system 2 500 GB-drev have de samme data, men ikke alle de data, der er nødvendige for, at systemet fungerer korrekt. 2 andre drevdata ville være påkrævet. Tænk på hvert RAID 1-system som et enkelt drev, og hvert af disse systemer placeres i et RAID 0-array. I denne opsætning kan ydeevnen øges drastisk som i RAID 0, med en vis redundans stadig på plads med spejlingen. Op til halvdelen af drevene i systemet kan mislykkes, før systemet går ned, men som med ethvert overflødigt array er det bedst at udskifte drev så hurtigt som muligt. Atlantic.Net bruger RAID 10 for alle SSD Cloud VPS opbevaring.
for ekstra beskyttelse er RAID-controllerne beskyttet af batteribackupenheder, der driver de ROM-chips, der bruges til at gemme konfigurationen i hukommelsen i tilfælde af strømtab osv. En BBU vil give strøm til et RAID-array, der er en del af et slukket system i en lille mængde tid, så indholdet af en RAID-controllers cache forbliver intakt. Dette kan være en livredder, hvis oplysningerne konstant bliver fodret ind i dit RAID-array, og enhver nedetid kan forårsage datakorruption.
så dit fysiske system og tjenesterne inden for kan konstrueres overflødigt ret tilstrækkeligt. Men hvad med din forbindelse til nogen del af dit system? Som i, din direkte internetforbindelse til dit system som helhed?
Netværksredundans
første Hop – Redundansprotokoller (FHRP)
i modsætning til dynamiske portopdagelsesprotokoller giver statiske porte mulighed for ligetil humle mellem klienten og deres passende port, men dette skaber et enkelt fejlpunkt-nemlig selve porten.
for at forhindre eller reducere virkningen af portfejl blev Fhrp ‘ er oprettet. De giver redundante porte en tilbagegang eller tilbyder belastningsbalancering for systemer med høj trafik sammen med redundans. Disse protokoller omfatter VRRP, HSRP og GLBP.
Virtual Router Redundancy Protocol (VRRP)
VRRP er en form for redundans, der bruges til routere, der kræver mindst to fysisk separate routere tilsluttet via enten Ethernet-eller optiske fiberforbindelser. I denne situation oprettes og deles en ‘virtuel router’, der indeholder statiske ruter, mellem hvert system.
et system betragtes som ‘master’ og et andet ‘backup’. Når masteren fejler, overtager backupen som den næste master. Dette kan konfigureres med flere sikkerhedskopier for ekstra redundans. Konceptet ligner meget Heartbeat, idet backupsystemerne kontrollerer, om masteren er tilgængelig. Når det ikke modtager et svar, vil backupen efter en forudbestemt tid overtage kontrollen over den virtuelle kontakt og acceptere forbindelser for alle anmodninger, der kommer ind for standard IP konfigureret til masterkontakten.
Hot Standby Router Protocol (HSRP)
HSRP er som VRRP; i dette scenario er den konfigurerede virtuelle kontakt imidlertid ikke en ‘kontakt’, men snarere en logisk gruppe af flere routere. Gruppens IP er en IP, der ikke er tildelt en fysisk vært. I stedet tildeles gruppen en IP, og en af routerne er bestemt til at være den ‘aktive’ router.
en standby-router er klar til at tage forbindelser, hvis den aktive router går ned. Alle routere udover den aktive og standby lytter alle til at bestemme sin plads i køen. HSRP er en Cisco proprietær protokol og har meget få, mindre forskelle i forhold til VRRP, såsom deres standardtimere, der bestemmer, hvornår de skal failover. HSRP har eksisteret lidt længere og er mere kendt sammenlignet med VRRP.
Port Load Balancing Protocol (GLBP)
GLBPS største fordel i forhold til HSRP og VRRP er dens evne til at indlæse balance oven på at give redundans til en port med ringe eller ingen ekstra konfiguration. Ligesom HSRP og VRRP vil GLBP oprette en gruppe mellem fysiske routere og bestemme en aktiv virtuel port eller AVG.
en virtuel IP, der i øjeblikket ikke bruges af nogen af routerne i gruppen, tildeles AVG. AVG distribuerer derefter virtuelle MAC-adresser blandt resten af routerne i gruppen. Hver backup router betragtes nu som en aktiv virtuel speditør eller AVF.
ARP-anmodninger, der sendes til AVG, giver en anden virtuel MAC-adresse til klienten, der sender anmodningen. På det tidspunkt videresender trafik fra denne klient til den virtuelle IP i gruppen til routeren, hvis virtuelle MAC-adresse De modtog, så hver router stadig kan bruges i stedet for at sidde ledigt ved.
i tilfælde af en fejl i AVG finder prioritetsbaseret valg sted, ligesom i HSRP og VRRP, og den næste sikkerhedskopi tager sin plads og distribuerer virtuelle MAC-adresser som normalt. De andre routere bevarer stadig den virtuelle MAC-adresse, der leveres af den originale AVG, og tingene fortsætter som normalt. I tilfælde af en fejl i en af AVF ‘ erne forhindrer AVG at dirigere trafik til sin virtuelle MAC-adresse.ligesom HSRP er GLBP en Cisco proprietær form for FHRP.
Datacenterredundans
ud over redundanstiltag for dine personlige servere eller routere er datacentre designet til at være modstandsdygtige over for systemfejl. Datacentre falder ind under niveauer defineret af Uptime Institute for at give fejltolerance for fejl i enhver mekanisk fejl eller servicefejl, hvilket giver mulighed for så meget oppetid som muligt.
Der er fire niveauer, der hver bygger på hinanden for at give høj tilgængelighed til alle klienter i et datacenter:
- Tier i – Basic Capacity: Dette kræver plads til en IT-gruppe til datacenteroperationer, en uafbrydelig strømforsyning (UPS), der overvåger og filtrerer strømforbrug og dedikeret køleudstyr, der konstant kører 24/7. Dette inkluderer også en strømgenerator i tilfælde af elektrisk strømsvigt.Tier II-redundante Kapacitetskomponenter: alt, hvad Tier I leverer, plus redundant strøm og køling til anlægget. Dette kan omfatte ekstra UPS-enheder eller ekstra generatorer.
- Tier III – samtidig vedligeholdes: Alt, hvad Tier II leverer, plus ekstra udstyr på plads for at forhindre ethvert behov for nedlukninger til udskiftning eller vedligeholdelse af udstyr. På dette niveau anvendes overflødig strøm og køling direkte på alt teknisk udstyr, og selve udstyret er konfigureret til redundans eller problemfri failover.Tier IV-fejltolerance: alt, hvad Tier III giver, Plus uafbrudt service på udbyderniveau. Mens et datacenter kan have elektricitet eller vand leveret af en by-eller statsudbyder, kræves en sekundær linje for hver tjeneste, der bruges af datacentret. Dette inkluderer også internetudbyderen. I tilfælde af en fejl i ethvert afsnit, der fører op til klientudstyr, er der en backup-plan på plads klar til en problemfri overgang.
konklusion
redundans er blevet et dagligdags udtryk i IT-branchen på grund af nødvendighed. Den høje tilgængelighed af tjenester giver en nem, pålidelig oplevelse for vores kunder.
uanset om det er på serviceniveau eller datacenterniveau, at give redundans til dit system er et vigtigt og vanskeligt problem at tackle. Forhåbentlig, dette papir har kastet lys over de tilgængelige muligheder og vil hjælpe med alle beslutninger, der træffes vedrørende høj tilgængelighed fremover.
klar til at drage fordel af Atlantic.Net redundante systemer? Kontakt os i dag for at finde ud af mere om dedikeret Server Hosting med Atlantic.Net.
===kilder===
Redundant system grundlæggende begreber: http://www.ni.com/white-paper/6874/en/
kold/varm/varm Server: http://searchwindowsserver.techtarget.com/definition/cold-warm-hot-server
høj tilgængelighed Clustering: https://www.mulesoft.com/resources/esb/high-availability-cluster
Hyper-V Replica: https://technet.microsoft.com/en-us/library/jj134172(V=vs.11).aspx
Hyper-V and High Availability: https://technet.microsoft.com/en-us/library/hh127064.aspx
HAProxy Description: http://www.haproxy.org/#desc
HAProxy – They use it!: http://www.haproxy.org/they-use-it.html
Heartbeat: http://www.linux-ha.org/wiki/Main_Page
RAID Definition: http://searchstorage.techtarget.com/definition/RAID
Striping: http://searchstorage.techtarget.com/definition/disk-striping
RAID Battery Backup Units: https://www.thomas-krenn.com/en/wiki/Battery_Backup_Unit_(BBU/BBM)_Maintenance_for_RAID_Controllers
High-Availability – VRRP, HSRP, GLBP: http://www.freeccnastudyguide.com/study-guides/ccna/ch14/vrrp-hsrp-glbp/
Understanding VRRP: http://www.juniper.net/techpubs/en_US/junos/topics/concept/vrrp-overview-ha.html
Configuring VRRP: http://www.cisco.com/c/en/us/td/docs/ios-xml/ios/ipapp_fhrp/configuration/15-mt/fhp-15-mt-book/fhp-vrrp.html
Configuring GLBP: http://www.cisco.com/c/en/us/td/docs/ios-xml/ios/ipapp_fhrp/configuration/xe-3s/fhp-xe-3s-book/fhp-glbp.html
Explaining the Uptime Institute’s Tier Classification System: https://journal.uptimeinstitute.com/explaining-uptime-institutes-tier-classification-system/