i dagens artikel skal vi se på rullende og ekspanderende vinduer.
i slutningen af indlægget vil du være i stand til at besvare disse spørgsmål:
- hvad er et rullende vindue?
- hvad er et ekspanderende vindue?
- Hvorfor er de nyttige?
Hvad er et rullende eller ekspanderende vindue?

Her er et normalt vindue.
Vi bruger normale vinduer, fordi vi vil have et glimt af ydersiden, jo større vinduet jo mere udefra får vi at se.
også som en generel tommelfingerregel, jo større vinduerne på nogens hus, jo bedre gjorde deres aktieportefølje …
ligesom rigtige vinduer giver datavinduer os også et lille indblik i noget større.
et vindue i bevægelse giver os mulighed for at undersøge en delmængde af vores data.
rullende vinduer
ofte vil vi gerne vide en statistisk egenskab af vores tidsseriedata, men fordi alle tidsmaskinerne er låst op i Rosvell, kan vi ikke beregne en statistik over hele prøven og bruge den til at få indsigt.
det ville introducere look-ahead bias i Vores forskning.
Her er et ekstremt eksempel på det. Her har vi plottet TSLA-prisen og dens gennemsnit over hele prøven.
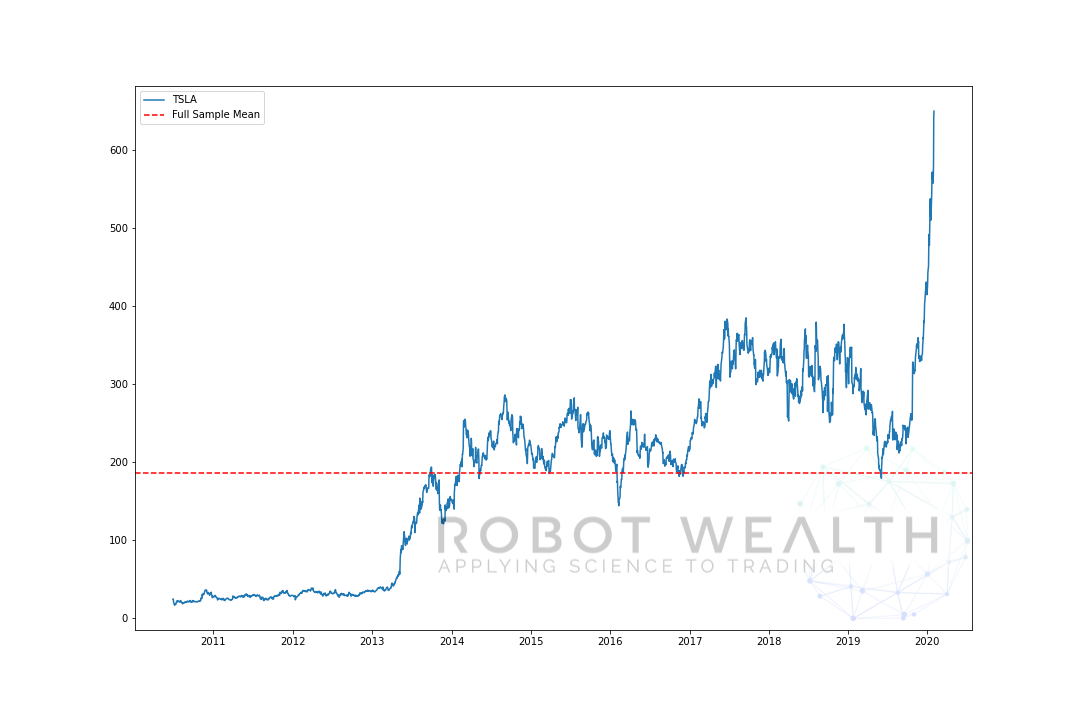
import pandas as pdimport matplotlib.pyplot as plt #Load TSLA OHLC df = pd.read_csv('TSLA.csv')#Calculate full sample meanfull_sample_mean = df.mean()#Plotplt.plot(df,label='TSLA')plt.axhline(full_sample_mean,linestyle='--',color='red',label='Full Sample Mean')plt.legend()plt.show()
i dette tilfælde, hvis vi lige købte TSLA, da prisen var under gennemsnittet og solgte den over gennemsnittet, ville vi have dræbt, godt i det mindste op til 2019…
men problemet er, at vi ikke ville have kendt middelværdien på det tidspunkt i tid.
så det er ret indlysende, hvorfor vi ikke kan bruge hele prøven, men hvad kan vi så gøre? En måde, vi kunne nærme os dette problem på, er ved at bruge rullende eller ekspanderende vinduer.
Hvis du nogensinde har brugt et simpelt glidende gennemsnit, så tillykke – du har brugt et rullende vindue.
hvordan fungerer rullende vinduer?
lad os sige, at du har 20 dages lagerdata, og du vil vide den gennemsnitlige pris på bestanden i de sidste 5 dage. Hvad laver du?
du tager de sidste 5 dage, opsummerer dem og deler med 5.
men hvad nu hvis du vil vide gennemsnittet af de foregående 5 dage for hver dag i dit datasæt?
det er her rullende vinduer kan hjælpe.
i dette tilfælde ville vores vindue have en størrelse på 5, hvilket betyder for hvert tidspunkt, det indeholder gennemsnittet af de sidste 5 datapunkter.
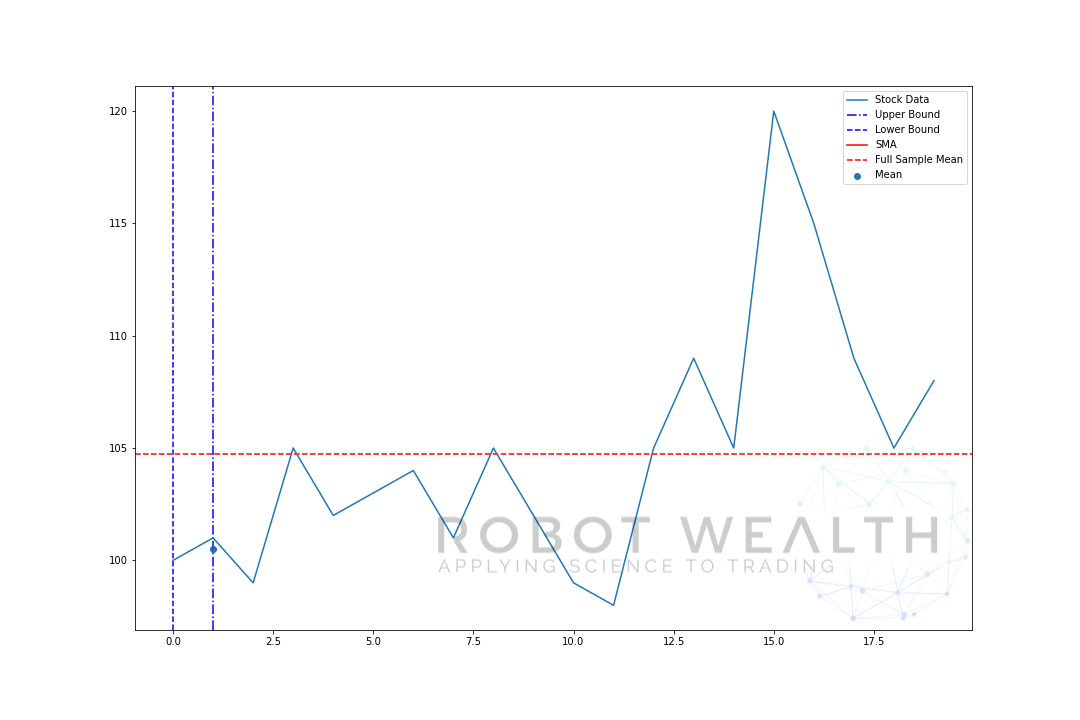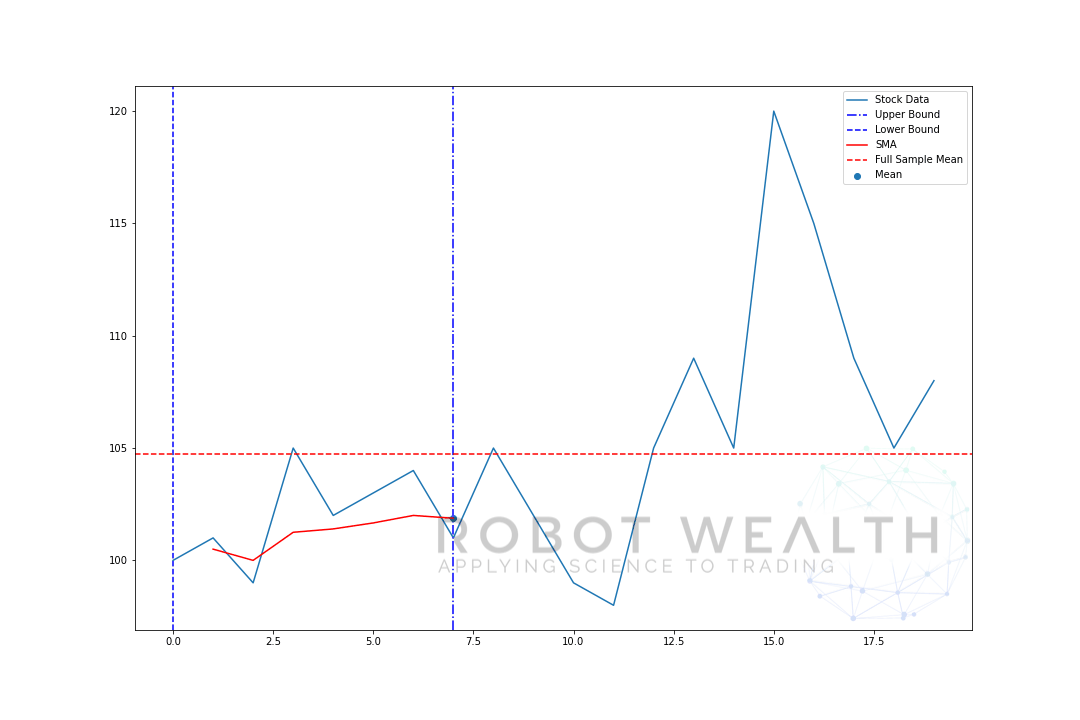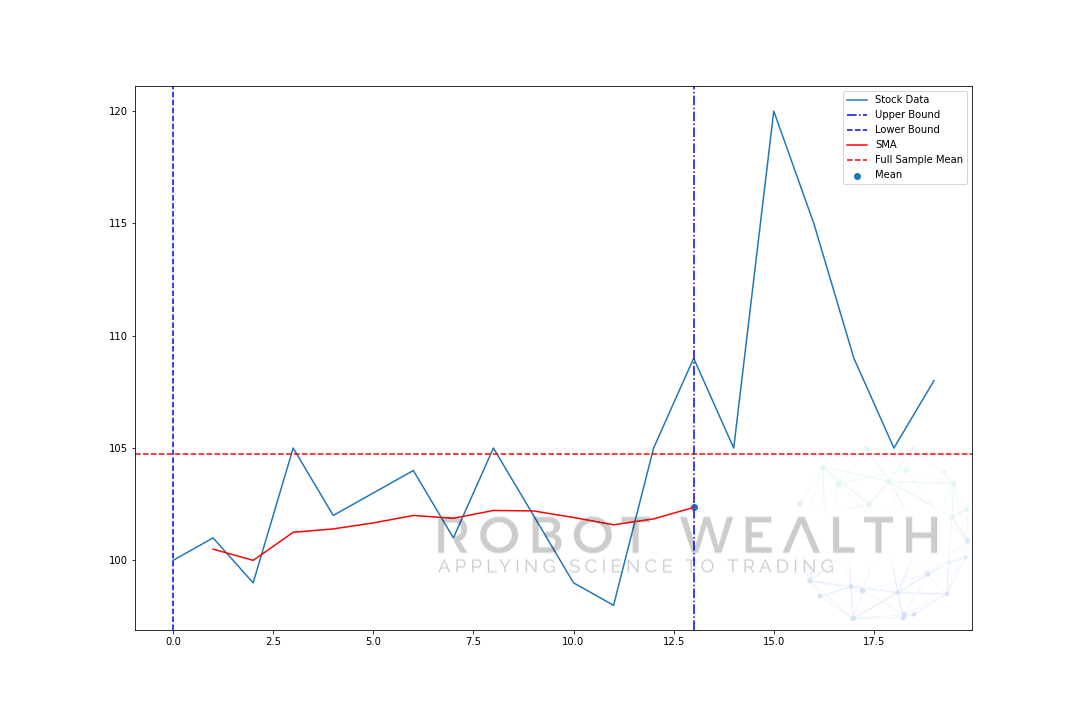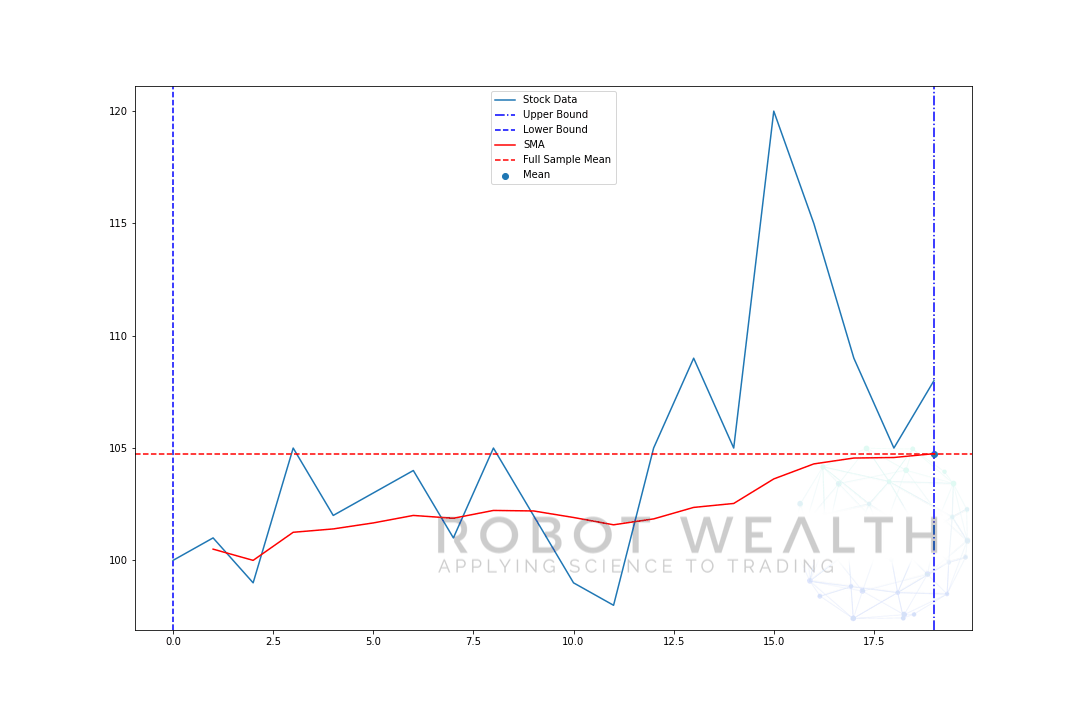
lad os visualisere et eksempel med et bevægeligt vindue i størrelse 5 trin for trin.
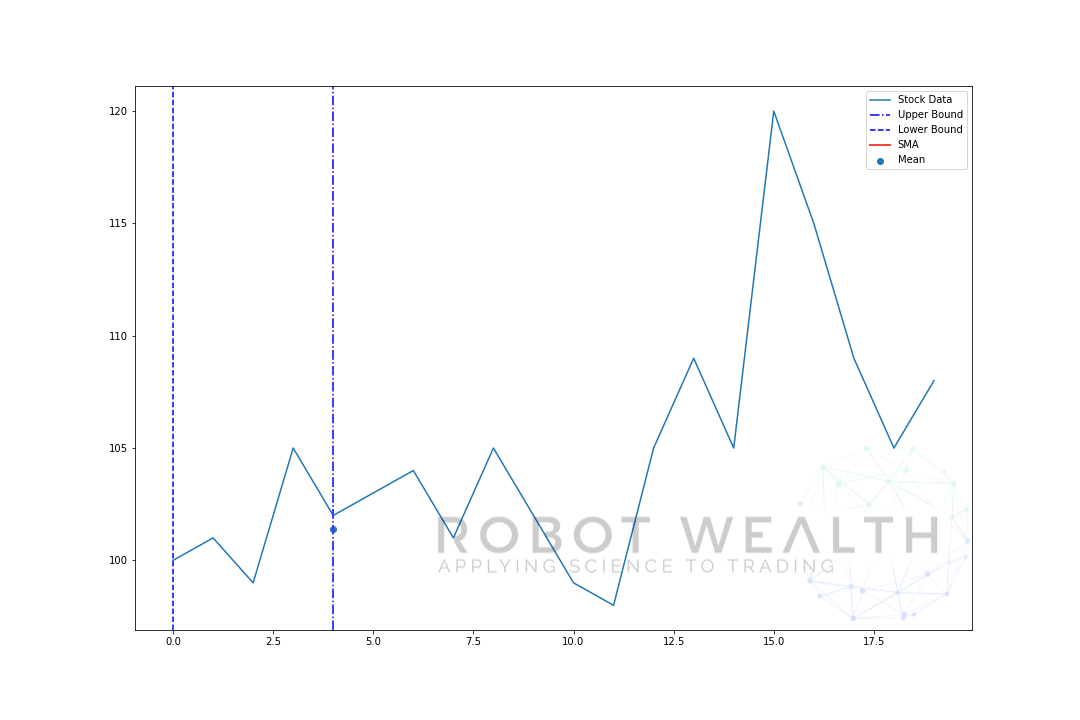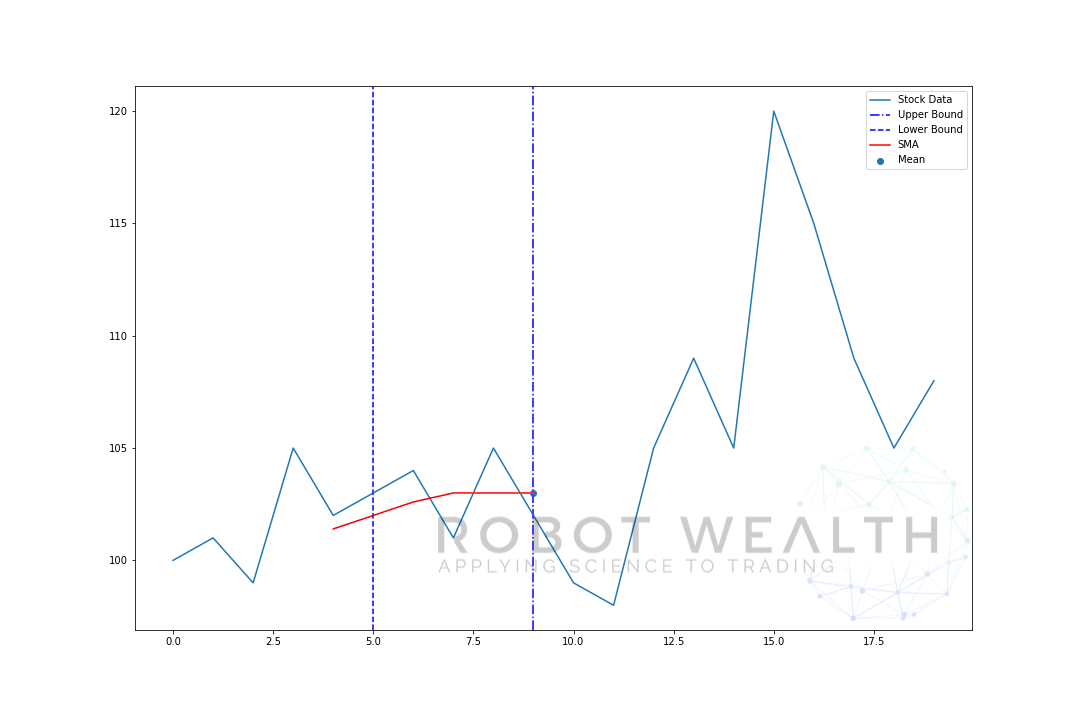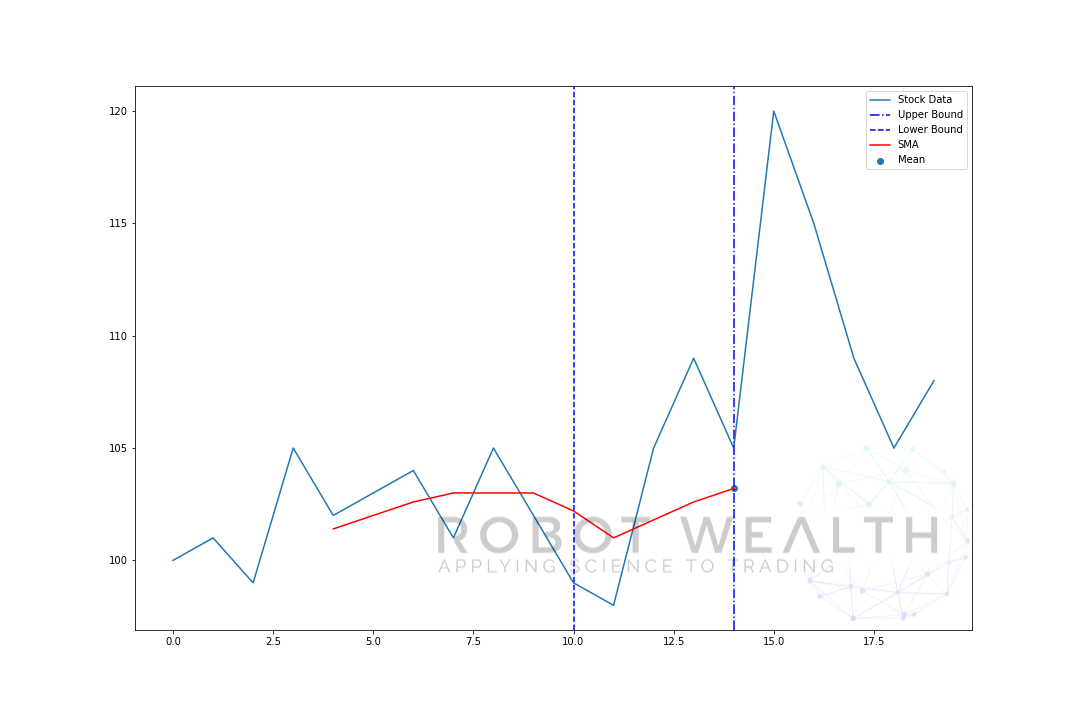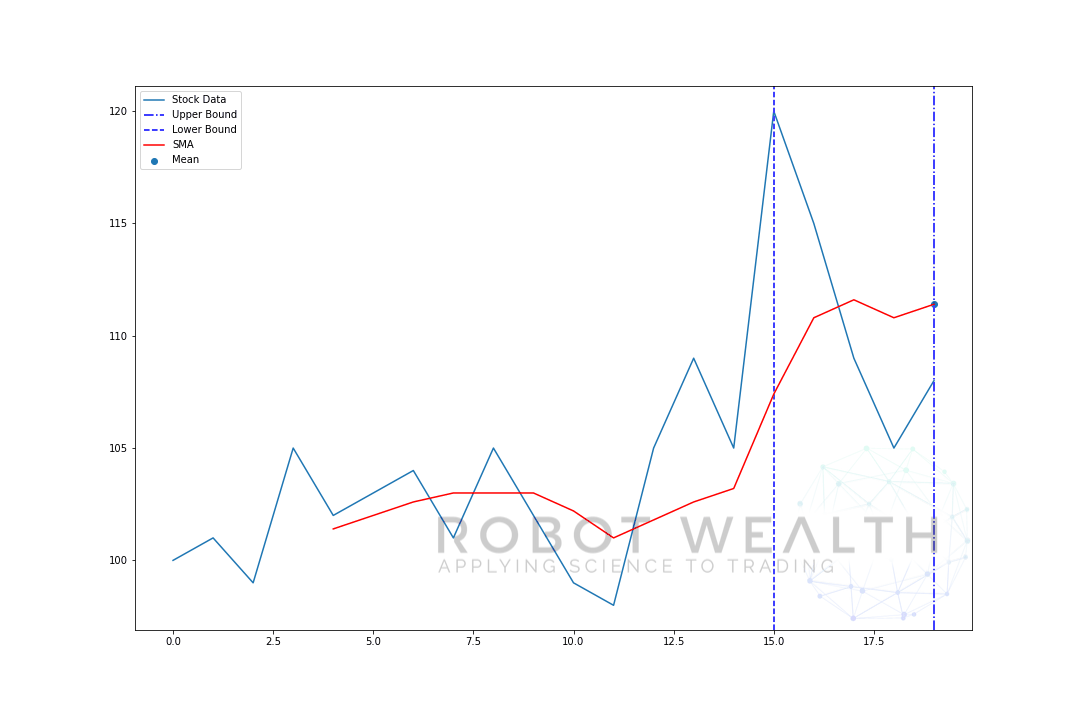
#Random stock pricesdata = #Create pandas DataFrame from listdf = pd.DataFrame(data,columns=)#Calculate a 5 period simple moving averagesma5 = df.rolling(window=5).mean()#Plotplt.plot(df,label='Stock Data')plt.plot(sma5,label='SMA',color='red')plt.legend()plt.show()
så lad os opdele dette diagram.
- Vi har 20 dages aktiekurser i dette diagram, mærket lagerdata.
- for hvert tidspunkt (den blå prik) vil vi vide, hvad der er 5 dages gennemsnitspris.
- de lagerdata, der bruges til beregningen, er tingene mellem de 2 blå lodrette linjer.
- når vi har beregnet gennemsnittet fra 0-5, bliver vores gennemsnit for dag 5 tilgængelig.
- for at få gennemsnittet for dag 6 skal vi flytte vinduet med 1 så datavinduet bliver 1-6.
og det er det, der er kendt som et rullende vindue, vinduets størrelse er fast. Alt, hvad vi gør, er at rulle det fremad.
som du sikkert har bemærket, har vi ikke SMA-værdier for point 0-4. Dette skyldes, at vores vinduesstørrelse (også kendt som en tilbagebliksperiode) kræver mindst 5 datapunkter for at udføre beregningen.
udvidelse af vinduer
hvor rullende vinduer har en fast størrelse, har ekspanderende vinduer et fast udgangspunkt og inkorporerer nye data, når de bliver tilgængelige.
Her er den måde, jeg kan lide at tænke på dette:
“hvad er gennemsnittet af de tidligere n-værdier på dette tidspunkt?”- Brug rullende vinduer her.
” Hvad er middelværdien af alle de tilgængelige data indtil dette tidspunkt?”- Brug ekspanderende vinduer her.
udvidende vinduer har en fast nedre grænse. Kun vinduets øvre grænse rulles fremad (vinduet bliver større).
lad os visualisere et ekspanderende vindue med de samme data fra det foregående plot.
#Random stock prices data = #Create pandas DataFrame from list df = pd.DataFrame(data,columns=) #Calculate expanding window meanexpanding_mean = df.expanding(min_periods=1).mean()#Calculate full sample mean for referencefull_sample_mean = df.mean()#Plot plt.plot(df,label='Stock Data') plt.plot(expanding_mean,label='Expanding Mean',color='red')plt.axhline(full_sample_mean,label='Full Sample Mean',linestyle='--',color='red')plt.legend()plt.show()
Du kan se, at SMA i begyndelsen er lidt nervøs. Det skyldes, at vi har et mindre antal datapunkter i begyndelsen af plottet, og når vi får flere data, udvides vinduet, indtil det ekspanderende vinduesgennemsnit til sidst konvergerer til det fulde eksempelgennemsnit, fordi vinduet har nået størrelsen på hele datasættet.
Resume
det er vigtigt ikke at bruge data fra fremtiden til at analysere fortiden. Rullende og ekspanderende vinduer er vigtige værktøjer til at hjælpe med at “gå dine data fremad” for at undgå disse problemer.
hvis du kunne lide dette, vil du sandsynligvis også lide disse…
finansiel datamanipulation i Dplyr for Kvantehandlere
brug af Digital signalbehandling i kvantitative handelsstrategier
backtesting bias: føles godt, indtil du sprænger