Der Zweck dieses Artikels ist es, Redundanz in Bezug auf Computing, Networking und Hosting zu erklären. Wir werden reale Beispiele für redundante Technologielösungen bereitstellen, um zu veranschaulichen, was Redundanz ist und wie sie funktioniert.
Atlantic.Net hat mehrere Hosting-Umgebungen erstellt, darunter eine dauerhafte Cloud-Plattform, Hochgeschwindigkeits-VPS-Hosting, HIPAA-konforme Infrastruktur und Managed Private Cloud-Hosting. Alle unsere Systeme sind mit Redundanz als primärer treibender Faktor des Designprozesses gebaut.Im Alltagsenglisch kann Redundanz eine negative Konnotation haben; Etwas Redundantes wird normalerweise nicht benötigt oder als überflüssig angesehen. In einer Cloud-Hosting-Umgebung kann Redundanz jedoch den Unterschied zwischen nahtloser Systemverfügbarkeit und unerwünschten oder unerwarteten Ausfallzeiten bedeuten.
- Was ist ein redundantes System?
- Arten redundanter Systeme
- Beispiele für redundante Softwaredienste
- Hyper-V-Replik
- Hyper-V-Clustering
- HAProxy
- Heartbeat
- Beispiele für redundante Hardwaredienste
- RAID
- Netzwerkredundanz
- First Hop Redundancy Protocols (FHRP)
- Virtual Router Redundancy Protocol (VRRP)
- Hot Standby Router Protocol (HSRP)
- Gateway Load Balancing Protocol (GLBP)
- Rechenzentrumsredundanz
- Fazit
Was ist ein redundantes System?
Ein redundantes System bietet Failover- oder Lastausgleichsunterstützung, um ein Live-System im Falle eines unerwarteten Ausfalls zu schützen. Im Falle eines Strom-, Mechanik- oder Softwarefehlers verfügt ein redundantes System über eine doppelte Komponente oder Plattform, auf die zurückgegriffen werden kann. Im Allgemeinen kann jede Komponente eines Systems mit einem Single Point of Failure als Risiko für Produktionsdienste angesehen werden.Stromversorgungs- oder mechanische Systeme haben einfachere Rückfallstrategien, die das bloße Vorhandensein eines anderen Dienstes derselben Art erfordern; Software-Failovers erfordern normalerweise eine zusätzliche Konfiguration auf dem Hostsystem oder einem Master oder Gateway.Redundanzfunktionen werden für jedes geschäftskritische System empfohlen, insbesondere jedoch für Systeme, die während Ausfallzeiten erhebliche Auswirkungen haben. Einige Unternehmen können alle ihre kritischen Kundeninformationen in einer Datenbank aufbewahren; Aus Gründen der Geschäftskontinuität schützt der redundante Schutz dieser Datenbank daher die Datenintegrität im Falle eines katastrophalen Ausfalls.
Arten redundanter Systeme
Ein redundantes System besteht aus mindestens zwei Systemen, die miteinander verbunden und für denselben Zweck ausgelegt sind. Es gibt viele verschiedene Arten redundanter Systemkonfigurationen, und verschiedene Implementierungen des Systems bieten einzigartige Ansätze, um ein System jederzeit auf dem neuesten Stand zu halten.
Nicht alle Server müssen redundant konfiguriert werden, sondern nur die kritischsten. Wir empfehlen dringend eine detaillierte Risikobewertung, um zu verstehen, welche Server im Umfang sind und wie viele Ausfallzeiten Ihre Server maximal bewältigen können. Verwenden Sie diese Bewertung, um eine RTO- (Recovery Time Objective) und RPO- (Recovery Point Objective) Strategie zu bestimmen. RTO ist die maximal zulässige Ausfallzeit. Dies kann zwischen 5 Sekunden und 24 Stunden liegen. Der RPO ist der Zeitpunkt, ab dem Sie Ihre Daten benötigen; Beispielsweise kann Ihr Unternehmen mit einem maximalen Datenverlust von 24 Stunden funktionieren.
Hier sind einige beliebte Beispiele:
- Aktiv-Inaktiv/Heiß-Kalt – Wenn eine Komponente eines Systems das aktive System ist und eine andere inaktiv oder heruntergefahren ist. Die inaktive Komponente wird nur aktiviert, wenn die aktuell laufende Komponente ausfällt oder gewartet wird
- Aktiv-Aktiv/Heiß-Heiß – Wenn beide Systeme unter Spannung stehen und Verbindungen herstellen. Dies wird am häufigsten als Clustering bezeichnet. Normalerweise bestimmt das Gerät vor beiden Computern, wie der eingehende Datenverkehr aufgeteilt wird
- Aktiv-Standby / Heiß-Warm – Wenn beide Systeme eingeschaltet sind, aber nur eines Verbindungen herstellt. Das zweite System soll regelmäßig Updates oder Backups vom primären System erhalten. Im Falle eines Ausfalls übernimmt das System im Standby-Modus die primäre Rolle, bis das ursprüngliche System wiederhergestellt werden kann.
Jeder Typ hat seine eigenen Vor- und Nachteile.
- Aktiv-Inaktiv / Heiß-Kalt-Systeme können eine einfache redundante Plattform bieten, aber jedes Failover führt dazu, dass Benutzer eine ältere Version des Systems sehen.
- Active-Active/Hot-Hot erfordert eine ständige Aktualisierung beider Systeme, entweder manuell oder über einen separaten Dienst, um sicherzustellen, dass alle Benutzer beide Systeme verwenden können. Dieser Ansatz kann die aktive Belastung eines Dienstes, den Sie Kunden bereitstellen, erheblich reduzieren.
- Active-Standby/Hot-Warm bietet die Failover-Funktionen von Hot-Cold mit einer aktuelleren Kopie Ihres aktiven Systems beim Failover, bietet jedoch keine Lastentlastung.
Es stehen andere Formen der Redundanz mehrerer Knoten zur Verfügung, die eine größere Redundanz und robuste Lastausgleichslösungen ermöglichen. Zu diesem Zeitpunkt verfügen Sie über einen Hochverfügbarkeitscluster, der auch als HA-Cluster bezeichnet wird.
Dies kann eine beliebige Kombination der zuvor genannten Redundanzlösungen mit maximaler Flexibilität im Ansatz oder Umfang der benötigten Redundanz verwenden. HA-Cluster können auch an mehreren physischen Standorten eingerichtet werden, um die Verfügbarkeit bis zur Internet-Backbone-Ebene zu ermöglichen.
Beispiele für redundante Softwaredienste
Aufgrund der geringen Ressourcenverfügbarkeit gibt es kaum einen Grund, keine proprietäre Replikation oder redundante Dienste in einer virtuellen Umgebung einzurichten. Alle unsere Cloud-Dienste verfügen über Replikation, eine Funktion, mit der wir jeden Server von einem Knoten auf einen anderen replizieren können, unabhängig davon, ob er sich im selben Rechenzentrum oder in separaten Rechenzentrumsregionen befindet.
Hyper-V-Replik
Hyper-V-Replik ist eine Form der Hot-Warm-Redundanz. Eine primäre virtuelle Maschine wird auf einem physischen Host erstellt und akzeptiert eingehende Verbindungen. Beim Aktivieren der Replikation werden die virtuellen Festplatten der neuen Maschine auf einen separaten physischen Hyper-V-Host übertragen. Dieser Host konfiguriert dann eine VM auf sich selbst, die nach einem benutzerdefinierten Zeitplan repliziert wird, um sicherzustellen, dass das neueste Image des aktiven Servers erstellt wird. Zusätzliche Checkpoints Punkte können auch gehalten werden. Hyper-V Private Hosting mit Managed Services wird bereitgestellt von Atlantic.Net mit dieser Funktion gebacken; Kontaktieren Sie unser Team für weitere Informationen.
Hyper-V-Clustering
Hyper-V kann auch über eine Verbindung zu anderen Hyper-V-Hosts clustern. VMs auf einem beliebigen Hyper-V-Host können auf diesem einzelnen Host zusammengefasst werden, um Redundanz auf lokaler Ebene durch virtuelle Netzwerke bereitzustellen.
Microsoft Network Load Balancing (NLB) kann verwendet werden, um eine einzelne Ressource zu erstellen, die aus mehreren Hosts besteht, die dieselben Informationen gemeinsam nutzen, um einen einfachen Zugriffspunkt für die Dateifreigabe bereitzustellen. Da dies nur durch die Menge der verfügbaren Ressourcen begrenzt ist, können Sie theoretisch mehrere Hosts mit mehreren VMs für maximale Redundanz einrichten, sodass Sie auch Wartungsarbeiten an einzelnen VMs durchführen können, ohne die Service- oder Ressourcenverfügbarkeit zu beeinträchtigen. Hyper-V Private Hosting mit Managed Services wird bereitgestellt von Atlantic.Net mit dieser Funktion gebacken; Kontaktieren Sie unser Team für weitere Informationen.
HAProxy
Abgesehen von Hyper-V kann ein Gateway-Gerät wie eine Firewall für Failover- oder Lastausgleichsdienste verwendet werden. Zum Beispiel Atlantic.Net kann pfSense einen Hochverfügbarkeits-Proxy bereitstellen, der auch als HAProxy bezeichnet wird.
HAProxy fungiert als Load Balancer, Proxy oder als einfache Hot-Hot-Hochverfügbarkeitslösung für TCP- und HTTP-basierte Anwendungen. HAProxy ist eine sehr beliebte, Linux-basierte Open-Source-Lösung, die von einigen der meistbesuchten Websites der Welt verwendet wird.
Heartbeat
Heartbeat ist ein auf den meisten Linux-Distributionen verfügbarer Dienst, mit dem ermittelt wird, ob Knoten in einem Cluster noch aktiv sind oder nicht. Es ist sehr einfach einzurichten und bietet Failover-Funktionen für jedes System, das über TCP arbeitet.
Die Entwickler von Heartbeat empfehlen auch andere Cluster-Ressourcenmanager, die Dienste starten oder stoppen, je nachdem, ob ein bestimmter Host ausgefallen ist. Heartbeat hat dies enthalten, aber andere Manager sind verfügbar. Aufgrund der Einfachheit von Heartbeat ist es in hohem Maße anpassbar. Cloud-Hosting-Plattformen zur Verfügung gestellt von Atlantic.Net wir haben diese Funktion bereits integriert und können Sie bei Bedarf bei der Implementierung von Heartbeat in Ihrer eigenen privaten Linux-Distribution unterstützen.
Beispiele für redundante Hardwaredienste
Das Beste an redundanter Hardware ist ihre Einfachheit. Während Softwaredienste eine übermäßige Konfiguration erfordern und möglicherweise sehr empfindlich sind, ist die Hardware normalerweise sehr einfach einzurichten und unglaublich langlebig. Das erste Beispiel, das wir betrachten werden, ist die weit verbreitete RAID-Technologie.
RAID
RAID steht für Redundant Array of Independent Disks (oder Redundant Array of Independent Disks, je nachdem, wie lange Sie es verwenden) und verfügt über mehrere Ebenen, die entweder für den Datenschutz oder für erhöhte Festplatten-E / A verwendet werden.
RAID kann entweder über einen Software- oder Hardware-Controller eingerichtet werden. Der Controller verfügt über die Software und Konfiguration, die zum Verwalten der RAID-Festplatten erforderlich sind. Die Konfiguration kann mit wenig bis gar keiner zusätzlichen Konfiguration in verschiedene Systeme exportiert werden.
RAID kann auf verschiedene Arten eingerichtet werden, um ein ausgewogenes Verhältnis beider Eigenschaften zu gewährleisten:
- RAID 0 – Dies ist im Wesentlichen keine Redundanz. Keine Festplatten auf dem System teilen Daten durch Spiegelung, aber alle Daten werden über jede Festplatte gestreift, wodurch die Lese- / Schreibgeschwindigkeit erhöht wird. Jedes Laufwerk kann den ihm zur Verfügung gestellten Speicher weiterhin in vollem Umfang nutzen, dh je mehr Laufwerke Sie einem RAID 0 hinzufügen, desto mehr Speicherplatz haben Sie.
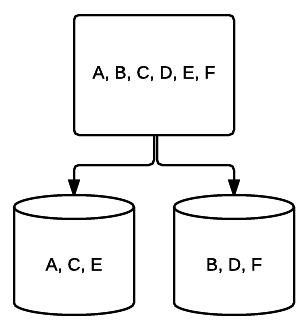
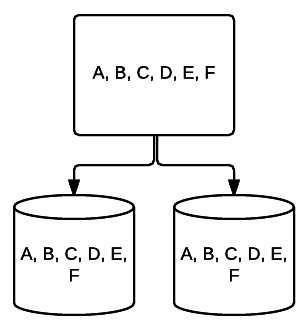
- RAID 1 – Eine grundlegende Form der Spiegelung, die hervorragende Redundanz auf Kosten des Platzes bietet. In einem System mit zwei Laufwerken wird eine vollständige Kopie der Daten auf einem Laufwerk in das andere geschrieben. Diese Redundanz wird mit jedem hinzugefügten Laufwerk erhöht. Da alle Daten auf allen Laufwerken gespiegelt werden müssen, ist der gesamte Speicherplatz auf dem System auf den Speicherplatz des kleinsten Laufwerks im System beschränkt.
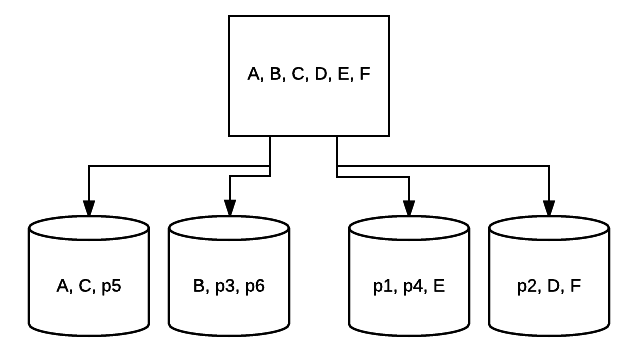
- RAID 5 – Diese Form von RAID wird normalerweise verwendet, um die Lesegeschwindigkeit und Zuverlässigkeit zu erhöhen. In diesem Fall werden Streifen um jedes Laufwerk im System platziert, wobei das Minimum 3 Laufwerke beträgt. Gleichzeitig wird ein zusätzlicher Block fehlerkorrigierender Daten über jedes Laufwerk in einer Technik namens Parität platziert. Dadurch wird überprüft, ob Daten beim Übertragen von einem Laufwerk auf ein anderes geändert werden. Dies bietet auch eine minimale Form der Redundanz, da 1 dieser Laufwerke ausfallen kann und das System weiterhin ausgeführt werden kann. Je mehr Laufwerke zu dieser Art von RAID-Setup hinzugefügt werden, desto mehr erhöht sich Ihre Lesegeschwindigkeit. Bei minimaler Redundanz und Striping über alle Laufwerke hinweg entspricht der Gesamtspeicherplatz in diesem Setup der Größe Ihres logischen RAID-Volumes mal der Anzahl der verwendeten Laufwerke abzüglich eins. Wenn Sie beispielsweise 5 500-GB-Laufwerke in einem RAID 5 haben, können Sie 2000 GB oder 2 TB verwenden (500 *(5-1)=2000).
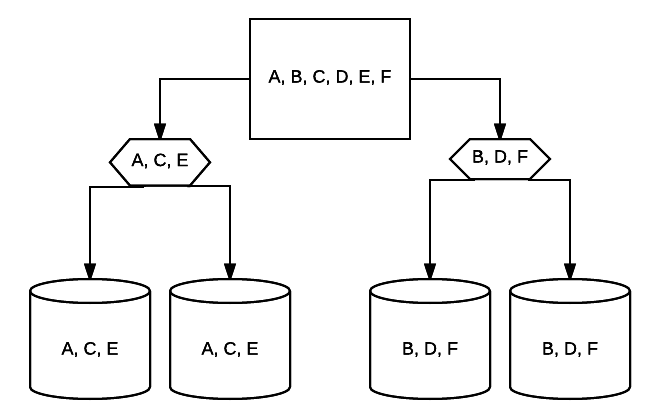
- RAID 10 – Dies ist eine Kombination aus RAID 1 und RAID 0. In diesem Fall werden alle Daten über jedes Gerät gestreift, wobei Datenblöcke auch über das gesamte gestreifte System gespiegelt werden. In einem RAID-10-System mit 4 Laufwerken verfügen beispielsweise 2 500-GB-Laufwerke möglicherweise über dieselben Daten, jedoch nicht über alle Daten, die für die ordnungsgemäße Funktion des Systems erforderlich sind. 2 Daten anderer Laufwerke wären erforderlich. Stellen Sie sich jedes RAID 1-System als ein einzelnes Laufwerk vor, und jedes dieser Systeme wird in einem RAID 0-Array platziert. In diesem Setup kann die Leistung wie bei RAID 0 drastisch erhöht werden, wobei bei der Spiegelung noch eine gewisse Redundanz besteht. Bis zur Hälfte der Laufwerke im System können ausfallen, bevor das System abstürzt, aber wie bei jedem redundanten Array ist es am besten, die Laufwerke so schnell wie möglich auszutauschen. Atlantic.Net verwendet RAID 10 für alle SSD-Cloud-VPS-Speicher.
Für zusätzlichen Schutz sind die RAID-Controller durch Batterie-Backup-Einheiten geschützt, die die ROM-Chips versorgen, die verwendet werden, um die Konfiguration im Falle eines Stromausfalls usw. im Speicher zu speichern. Eine BBU versorgt ein RAID-Array, das Teil eines heruntergefahrenen Systems ist, für eine kurze Zeit mit Strom, sodass der Inhalt des Cache eines RAID-Controllers intakt bleibt. Dies kann ein Lebensretter sein, wenn die Informationen ständig in Ihr RAID-Array eingespeist werden und Ausfallzeiten zu Datenbeschädigungen führen können.
Ihr physisches System und die darin enthaltenen Dienste können also redundant und ausreichend aufgebaut sein. Aber was ist mit Ihrer Verbindung zu irgendeinem Teil Ihres Systems? Wie in, Ihre direkte Internetverbindung zu Ihrem System als Ganzes?
Netzwerkredundanz
First Hop Redundancy Protocols (FHRP)
Im Gegensatz zu dynamischen Gateway Discovery–Protokollen ermöglichen statische Gateways einfache Hops zwischen dem Client und dem entsprechenden Gateway, wodurch jedoch ein einziger Fehlerpunkt entsteht – nämlich das Gateway selbst.
Um die Auswirkungen eines Gateway-Ausfalls zu verhindern oder zu verringern, wurden FHRPs erstellt. Sie bieten redundante Gateways als Fallback oder bieten Load-Balancing für Systeme mit hohem Datenverkehr sowie Redundanz. Diese Protokolle umfassen VRRP, HSRP und GLBP.
Virtual Router Redundancy Protocol (VRRP)
VRRP ist eine Form der Redundanz für Router, die mindestens zwei physisch getrennte Router erfordert, die entweder über Ethernet- oder Glasfaserverbindungen verbunden sind. In dieser Situation wird ein ‚virtueller Router‘ mit statischen Routen erstellt und von jedem System gemeinsam genutzt.
Ein System gilt als ‚Master‘ und ein anderes als ‚Backup‘. Wenn der Master ausfällt, übernimmt das Backup als nächster Master. Dies kann mit mehreren Backups für zusätzliche Redundanz eingerichtet werden. Das Konzept ist dem Heartbeat sehr ähnlich, da die Backup-Systeme prüfen, ob der Master verfügbar ist. Sobald es keine Antwort erhält, übernimmt das Backup nach einer vorgegebenen Zeit die Kontrolle über den virtuellen Switch und akzeptiert Verbindungen für alle Anforderungen, die für die für den Master-Switch konfigurierte Standard-IP eingehen.
Hot Standby Router Protocol (HSRP)
HSRP ist wie VRRP; in diesem Szenario ist der konfigurierte virtuelle Switch jedoch kein ‚Switch‘, sondern eine logische Gruppe mehrerer Router. Die IP der Gruppe ist eine IP, die keinem physischen Host zugewiesen ist. Stattdessen wird der Gruppe eine IP zugewiesen und einer der Router als ‚aktiver‘ Router bestimmt.
Ein Standby-Router ist bereit, alle Verbindungen aufzunehmen, sollte der aktive Router ausfallen. Alle Router neben dem aktiven und Standby sind alle hören seinen Platz in der Leitung zu bestimmen. HSRP ist ein proprietäres Protokoll von Cisco und weist nur sehr wenige geringfügige Unterschiede zu VRRP auf, z. B. die Standard-Timer, die bestimmen, wann ein Failover durchgeführt werden soll. HSRP gibt es schon etwas länger und ist im Vergleich zu VRRP bekannter.
Gateway Load Balancing Protocol (GLBP)
Der Hauptvorteil von GLBP gegenüber HSRP und VRRP ist seine Fähigkeit, zusätzlich zur Redundanz eines Gateways mit wenig bis gar keiner zusätzlichen Konfiguration einen Lastausgleich durchzuführen. Ähnlich wie HSRP und VRRP erstellt GLBP eine Gruppe zwischen physischen Routern und bestimmt ein aktives virtuelles Gateway oder AVG.
Dem AVG wird eine virtuelle IP-Adresse zugewiesen, die derzeit von keinem der Router in der Gruppe verwendet wird. Der AVG verteilt dann virtuelle MAC-Adressen auf die übrigen Router in der Gruppe. Jeder Backup-Router wird jetzt als aktiver virtueller Forwarder oder AVF betrachtet.
An den AVG gesendete ARP-Anforderungen stellen dem Client, der die Anforderung sendet, eine andere virtuelle MAC-Adresse zur Verfügung. Zu diesem Zeitpunkt wird der Datenverkehr von diesem Client zur virtuellen IP der Gruppe an den Router weitergeleitet, dessen virtuelle MAC-Adresse sie erhalten haben, sodass jeder Router weiterhin verwendet werden kann, anstatt untätig zu sitzen.
Im Falle eines Ausfalls des AVG findet eine prioritätsbasierte Wahl statt, genau wie bei HSRP und VRRP, und die nächste Sicherung tritt an ihre Stelle, wobei virtuelle MAC-Adressen wie gewohnt verteilt werden. Die anderen Router behalten weiterhin die vom ursprünglichen AVG bereitgestellte virtuelle MAC-Adresse bei, und die Dinge laufen normal weiter. Im Falle eines Ausfalls eines der AVFs verhindert der AVG das Weiterleiten des Datenverkehrs an seine virtuelle MAC-Adresse.
Genau wie HSRP ist GLBP eine von Cisco proprietäre Form von FHRP.
Rechenzentrumsredundanz
Zusätzlich zu den Redundanzmaßnahmen für Ihre persönlichen Server oder Router sind Rechenzentren so konzipiert, dass sie widerstandsfähig gegen Systemausfälle sind. Rechenzentren fallen unter die vom Uptime Institute definierten Stufen, um Fehlertoleranz für den Ausfall von mechanischen oder Servicefehlern zu bieten und so viel Verfügbarkeit wie möglich zu ermöglichen.
Es gibt vier Ebenen, die jeweils aufeinander aufbauen, um allen Clients innerhalb eines Rechenzentrums eine hohe Verfügbarkeit zu bieten:
- Tier I – Basiskapazität: Dies erfordert Platz für eine IT-Gruppe für den Betrieb von Rechenzentren, eine unterbrechungsfreie Stromversorgung (USV), die den Stromverbrauch überwacht und filtert, und dedizierte Kühlgeräte, die ständig 24/7 laufen. Dazu gehört auch ein Stromerzeuger im Falle eines Stromausfalls.
- Tier II – Redundante Kapazitätskomponenten: Alles, was Tier I bietet, sowie redundante Stromversorgung und Kühlung der Anlage. Dies kann zusätzliche USV-Einheiten oder zusätzliche Generatoren umfassen.
- Tier III – Gleichzeitig wartbar: Alles, was Tier II bietet, sowie zusätzliche Ausrüstung, um Abschaltungen für den Austausch oder die Wartung von Geräten zu verhindern. Auf dieser Ebene werden redundante Stromversorgung und Kühlung direkt auf alle technischen Geräte angewendet, und die Geräte selbst sind für Redundanz oder nahtloses Failover konfiguriert.
- Tier IV – Fehlertoleranz: Alles, was Tier III bietet, plus ununterbrochenen Service auf Anbieterebene. Während ein Rechenzentrum über Strom oder Wasser verfügen kann, das von einem städtischen oder staatlichen Anbieter bereitgestellt wird, ist für jeden vom Rechenzentrum genutzten Dienst eine Sekundärleitung erforderlich. Dazu gehört auch der ISP. Im Falle eines Ausfalls in einem Abschnitt, der zu den Client-Geräten führt, ist ein Backup-Plan vorhanden, der für einen nahtlosen Übergang bereit ist.
Fazit
Redundanz ist in der IT-Branche aus Notwendigkeit zum Alltagsbegriff geworden. Die hohe Verfügbarkeit der Dienste bietet unseren Kunden ein einfaches und zuverlässiges Erlebnis.
Ob auf Service- oder Rechenzentrumsebene, die Bereitstellung von Redundanz für Ihr System ist ein wichtiges und schwieriges Problem. Hoffentlich hat dieses Papier etwas Licht in die verfügbaren Optionen gebracht und wird bei zukünftigen Entscheidungen in Bezug auf Hochverfügbarkeit hilfreich sein.
Bereit, die Vorteile von Atlantic.Net redundante Systeme? Kontaktieren Sie uns noch heute, um mehr über Dedicated Server Hosting mit zu erfahren Atlantic.Net .
===Quellen===
Redundante Systemgrundkonzepte: http://www.ni.com/white-paper/6874/en/
Kalt / Warm / Heiß Server: http://searchwindowsserver.techtarget.com/definition/cold-warm-hot-server
Hochverfügbarkeits-Clustering: https://www.mulesoft.com/resources/esb/high-availability-cluster
Hyper-V-Replikat: https://technet.microsoft.com/en-us/library/jj134172(v=ws.11).aspx
Hyper-V and High Availability: https://technet.microsoft.com/en-us/library/hh127064.aspx
HAProxy Description: http://www.haproxy.org/#desc
HAProxy – They use it!: http://www.haproxy.org/they-use-it.html
Heartbeat: http://www.linux-ha.org/wiki/Main_Page
RAID Definition: http://searchstorage.techtarget.com/definition/RAID
Striping: http://searchstorage.techtarget.com/definition/disk-striping
RAID Battery Backup Units: https://www.thomas-krenn.com/en/wiki/Battery_Backup_Unit_(BBU/BBM)_Maintenance_for_RAID_Controllers
High-Availability – VRRP, HSRP, GLBP: http://www.freeccnastudyguide.com/study-guides/ccna/ch14/vrrp-hsrp-glbp/
Understanding VRRP: http://www.juniper.net/techpubs/en_US/junos/topics/concept/vrrp-overview-ha.html
Configuring VRRP: http://www.cisco.com/c/en/us/td/docs/ios-xml/ios/ipapp_fhrp/configuration/15-mt/fhp-15-mt-book/fhp-vrrp.html
Configuring GLBP: http://www.cisco.com/c/en/us/td/docs/ios-xml/ios/ipapp_fhrp/configuration/xe-3s/fhp-xe-3s-book/fhp-glbp.html
Explaining the Uptime Institute’s Tier Classification System: https://journal.uptimeinstitute.com/explaining-uptime-institutes-tier-classification-system/