Von: Arshad Ali / Aktualisiert: 2020-07-29 / Kommentare (6) / Verwandt: Mehr > JOIN-Tabellen
Problem
In der Spitze SQL Server JoinExamples, Jeremy Kadlec sprach über verschiedene logische Join-Operatoren, aber wie implementiert SQL Server sie physisch? Was sind die verschiedenen physischen Joinoperatoren? Wie unterscheiden sie sich voneinander und in welchem Szenario wird das eine bevorzugtüber andere? In diesem Tipp behandeln wir diese und weitere Fragen.
Lösung
Wir verwenden logische Operatoren, wenn wir Abfragen schreiben, um eine relationale Abfrage auf konzeptioneller Ebene zu definieren (was zu tun ist). SQL implementiert diese logischen Operatoren mit drei verschiedenen physikalischen Operatoren, um die von den logischen Operatoren definierte Operation zu implementieren (wie sie ausgeführt werden muss). Obwohl es Dutzende von physicaloperators gibt, werde ich in diesem Tipp bestimmte physikalische Join-Operatoren behandeln. Obwohl wir verschiedene Arten von logischen Verknüpfungen auf konzeptioneller / Abfrageebene haben, implementiert SQL Server sie alle mit drei verschiedenen physischen Verknüpfungsoperatoren, wie unten beschrieben.
Wir werden Folgendes behandeln:
- Nested Loops Join
- Merge Join
- Hash Join
Wir werden uns die Ausführungspläne ansehen, um diese Operatoren zu sehen, und ich werde erklären, warum jeder auftritt.
Für diese Beispiele verwende ich dieAdventureWorks-Datenbank.
SQL Server Nested Loops Join Explained
Bevor ich mich mit den Details befasse, möchte ich Ihnen zuerst sagen, was ein Nested Loops Join ist, wenn Sie neu in der Programmierwelt sind.
Ein Nested Loops Join ist eine logische Struktur, in der sich eine Schleife (Iteration) in einer anderen befindet, dh für jede Iteration der äußeren Schleife werden alle Iterationen der inneren Schleife ausgeführt / verarbeitet.
Ein verschachtelter Schleifen-Join funktioniert auf die gleiche Weise. Eine der Verbindungstabellen wird als äußere Tabelle und eine andere als innere Tabelle bezeichnet. Für jede Zeile der outertable werden alle Zeilen aus der inneren Tabelle einzeln abgeglichen, wenn die Zeile matchesit in der Ergebnismenge enthalten ist, andernfalls wird sie ignoriert. Dann die nächste Zeile vondie äußere Tabelle wird aufgenommen und der gleiche Vorgang wird wiederholt und so weiter.
Der SQL Server-Optimierer wählt möglicherweise einen Join mit verschachtelten Schleifen, wenn eine der Joiningtables klein ist (als äußere Tabelle betrachtet) und eine andere groß ist (als innere Tabelle betrachtet, die in der Spalte indiziert ist, die sich im Join befindet) und daher minimale E / A und die wenigsten Vergleiche erfordert.
Der Optimierer berücksichtigt drei Varianten für einen Nested Loops Join:
- Index nested loops Join In diesem Fall scannt die Suche die gesamte Tabelle oder den Index
- index nested loops Join, wenn die Suche einen vorhandenen Index verwenden kann, um Lookups durchzuführen
- temporärer Index nested loops Join Wenn der Optimierer einen temporären Index als Teil des Abfrageplans erstellt und nach Abschluss der Abfrageausführung zerstört
Ein Index Nested Loops Join ist besser als ein Merge Join oder Hash Join, wenn eine kleine Menge von Zeilen beteiligt ist. Wenn jedoch eine große Anzahl von Zeilen beteiligt ist, ist der Join von Schleifen möglicherweise keine optimale Wahl. Verschachtelte Schleifen unterstützen fast alle Join-Typen außer right und full outer Joins, right Semi-Join und right Anti-Semijoins.
- In Skript # 1 verbinde ich die SalesOrderHeader-Tabelle mit SalesOrderDetailtable und gebe die Kriterien an, nach denen das Ergebnis des Kunden Mitcustomerid = 670 gefiltert werden soll.
- Dieses gefilterte Kriterium gibt 12 Datensätze aus der SalesOrderHeader-Tabelle zurück, und daher wurde diese Tabelle vom Optimierer als äußere Tabelle (oberste im grafischen Abfrageausführungsplan) betrachtet.
- Für jede Zeile dieser 12 Zeilen der äußeren Tabelle werden rowsfrom der inneren Tabelle SalesOrderDetail (oder die innertable wird jedes Mal 12 Mal für jede Zeile mit dem Index seek oder correlatedparameter aus der äußeren Tabelle gescannt) und 312 übereinstimmende Zeilen werden zurückgegeben, wie Sie im zweiten Bild sehen können.
- In der zweiten Abfrage unten verwende ich SET STATISTICS PROFILE ON , um Profilinformationen der Abfrageausführung zusammen mit der Abfrageergebnismenge anzuzeigen.
Skript #1 – Beispiel für verschachtelte Schleifen
SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader H INNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID = 670
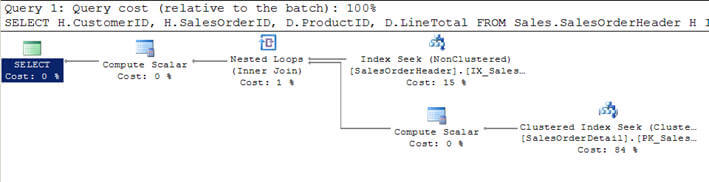
SET STATISTICS PROFILE ONSELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader HINNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderIDWHERE H.CustomerID = 670SET STATISTICS PROFILE OFF

Wenn die Anzahl der beteiligten Datensätze groß ist, kann SQL Server eine verschachtelte Schleife parallelisieren, indem die äußeren Tabellenzeilen zufällig dynamisch auf die verfügbaren verschachtelten Schleifen verteilt werden. Es gilt jedoch nicht dasselbe für die inneren Tablerows. Um mehr über parallele Scans zu erfahren, klicken Sie hier.
SQL Server Merge Join Explained
Das erste, was Sie über einen Merge-Join wissen müssen, ist, dass beide Eingaben nach Join-Schlüsseln / Merge-Spalten sortiert werden müssen (oder beide Eingabetabellen haben clusteredindexes in der Spalte, die die Tabellen verbindet) und es erfordert auch mindestens einen equijoin(equals to) Ausdruck / Prädikat.
Da die Zeilen vorsortiert sind, beginnt ein Merge Join sofort mit dem matchingprocess. Es liest eine Zeile aus einer Eingabe und vergleicht sie mit der Zeile einer anderen Eingabe.Wenn die Zeilen übereinstimmen, wird diese übereinstimmende Zeile in der Ergebnismenge berücksichtigt (dann liest sie die nächste Zeile aus der Eingabetabelle, führt denselben Vergleich / dieselbe Übereinstimmung usw. durch) oder umgekehrt Die kleinere der beiden Zeilen wird ignoriert und der Prozess wird auf diese Weise fortgesetzt, bis alle Zeilen verarbeitet wurden..
Ein Merge-Join funktioniert besser, wenn große Eingabetabellen (vorindexiert / sortiert) verbunden werden, da die Kosten die Summe der Zeilen in beiden Eingabetabellen sind, im Gegensatz zu NestedLoops, bei denen es sich um ein Produkt der Zeilen beider Eingabetabellen handelt. Manchmal beschließt der Optimierer, einen Merge-Join zu verwenden, wenn die Eingabetabellen nicht sortiert sind, und verwendet daher einen expliziten physikalischen Sortieroperator, der jedoch möglicherweise langsamer ist als die Verwendung eines Index (vorsortierte Eingabetabelle).
- In Skript # 2 verwende ich eine ähnliche Abfrage wie oben, aber dieses Mal habe ich eine WHERE-Klausel hinzugefügt, um alle Kunden größer als 100 zu erhalten.
- In diesem Fall entscheidet sich der Optimierer für einen Merge-Join, da beide Eingaben in Bezug auf Zeilen groß sind und auch vorindexiert / sortiert sind.
- Sie können auch feststellen, dass beide Eingaben nur einmal gescannt werden, im Gegensatz zu den 12 Scans, die wir in den verschachtelten Schleifen oben gesehen haben.
Skript #2 – Merge Join Beispiel
SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader H INNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID > 100
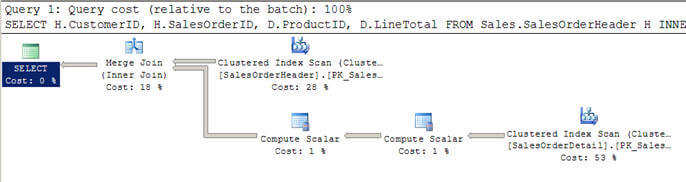
SET STATISTICS PROFILE ONSELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader HINNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderIDWHERE H.CustomerID > 100SET STATISTICS PROFILE OFF

Ein Merge Join ist häufig ein effizienterer und schnellerer Join-Operator, wenn die sortierten Daten aus einem vorhandenen B-Tree-Index abgerufen werden können und fast alle Joinoperationen ausgeführt werden, solange mindestens ein Equality Join-Prädikat beteiligt ist. Es unterstützt auch mehrere Gleichheits-Join-Prädikate, solange die Eingabetabellen nach allen beteiligten Join-Schlüsseln sortiert sind und sich in derselben Reihenfolge befinden.
Das Vorhandensein eines Compute Scalar Operators zeigt die Auswertung eines Ausdrucks an, um einen berechneten Skalarwert zu erzeugen. In der obigen Abfrage wähle ich LineTotalwhich ist eine abgeleitete Spalte, daher wurde sie im Ausführungsplan verwendet.
SQL Server Hash Join Explained
Ein Hash-Join wird normalerweise verwendet, wenn Eingabetabellen recht groß sind und keine adäquaten Indizes vorhanden sind. Ein Hash-Join wird in zwei Phasen durchgeführt; die Build-Phase und die Probe-Phase und damit der Hash-Join haben zwei Eingänge, dh Build input und probeinput . Die kleinere der Eingaben wird als Build-Eingabe betrachtet (um die Speicheranforderung zum Speichern einer später diskutierten Hash-Tabelle zu minimieren), und die andere ist offensichtlich die Testeingabe.
Während der Build-Phase werden die Verbindungsschlüssel aller Zeilen der Build-Tabelle gescannt.Hashes werden generiert und in einer In-Memory-Hash-Tabelle abgelegt. Im Gegensatz zum Merge-Join blockiert er bis zu diesem Zeitpunkt (es werden keine Zeilen zurückgegeben).
Während der Probe-Phase werden die Schlüssel jeder Zeile der Probe-Tabelle abgetastet.Wieder werden Hashes generiert (mit der gleichen Hash-Funktion wie oben) und mit der entsprechenden Hash-Tabelle für eine Übereinstimmung verglichen.
Eine Hash-Funktion benötigt eine erhebliche Anzahl von CPU-Zyklen, um Hash-Werte zu generieren, und Speicherressourcen, um die Hash-Tabelle zu speichern. Wenn Speicherdruck besteht, werden einige der Partitionen der Hash-Tabelle in tempdb getauscht und bei Bedarf (entweder zum Testen oder Aktualisieren des Inhalts) wieder in den Cache gebracht.Um eine hohe Leistung zu erzielen, kann der Abfrageoptimierer einen Hash-Join zu parallelisierenskalieren Sie besser als jeder andere Join, für mehr Detailsklicken Sie hier.
Es gibt grundsätzlich drei verschiedene Arten von Hash-Joins:
- In-Memory-Hash-Join in diesem Fall ist genügend Speicher verfügbar, um die Hash-Tabelle zu speichern
- In-Hash-Join In diesem Fall kann die Hash-Tabelle nicht in den Speicher passen und einige Partitionen werden an tempdb verschüttet
- Rekursiver Hash-Join In diesem Fall ist eine Hash-Tabelle so groß, dass der Optimierer viele Ebenen von Merge-Joins verwenden muss.
Für weitere Details zu diesen verschiedenen Typenklicken Sie hier.
- In Skript # 3 erstelle ich zwei neue große Tabellen (aus den vorhandenen AdventureWorkstables) ohne Indizes.
- Sie können sehen, dass der Optimierer in diesem Fall einen Hash-Join verwendet hat.
- Im Gegensatz zu einem verschachtelten Schleifen-Join wird die innere Tabelle nicht mehrmals gescannt.
Skript # 3 – Hash-Join-Beispiel
--Create tables without indexes from existing tables of AdventureWorks database SELECT * INTO Sales.SalesOrderHeader1 FROM Sales.SalesOrderHeader SELECT * INTO Sales.SalesOrderDetail1 FROM Sales.SalesOrderDetail GO SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader1 H INNER JOIN Sales.SalesOrderDetail1 D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID = 670 GO
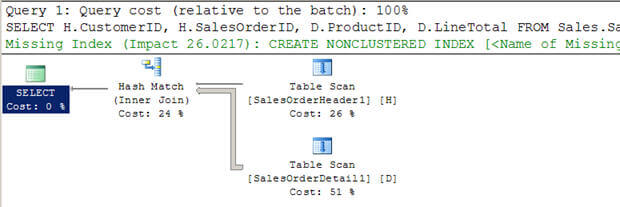
SET STATISTICS PROFILE ON SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader1 H INNER JOIN Sales.SalesOrderDetail1 D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID = 670 SET STATISTICS PROFILE OFF

--Drop the tables created for demonstration DROP TABLE Sales.SalesOrderHeader1 DROP TABLE Sales.SalesOrderDetail1
Hinweis: SQL Server macht einen ziemlich guten Job bei der Entscheidung, welche joinoperator in jeder Bedingung zu verwenden. Das Verständnis dieser Bedingungen hilft Ihnen zu verstehenwas bei der Leistungsoptimierung getan werden kann. Es wird nicht empfohlen, Join-Hinweise (usingOPTION Klausel) zu verwenden, um SQL Server zu zwingen, einen bestimmten Join-Operator zu verwenden (es sei denn, Sie haben keinen anderen Ausweg), sondern Sie können andere Mittel verwenden, z. B. Statistiken aktualisieren, Indizes erstellen oder Ihre Abfrage neu schreiben.
Nächste Schritte
- ReviewSQL ServerJoin Beispiele Tipp.
- Reviewlogische und physikalische Operatoren Referenzartikel auf Technet.
Zuletzt aktualisiert: 2020-07-29


 Arshad Ali is a SQL and BI Developer focusing on Data Warehousing projects for Microsoft.
Arshad Ali is a SQL and BI Developer focusing on Data Warehousing projects for Microsoft.View all my tips
- More Database Developer Tips…