El propósito de este artículo es explicar la redundancia en términos de computación, redes y alojamiento. Proporcionaremos ejemplos reales de soluciones tecnológicas redundantes para ilustrar qué es la redundancia y cómo funciona.
Atlantic.Net ha creado múltiples entornos de alojamiento, incluida una plataforma en la nube duradera, alojamiento VPS de alta velocidad, infraestructura compatible con HIPAA y alojamiento en la nube privada administrada. Todos nuestros sistemas están construidos con redundancia como factor impulsor principal del proceso de diseño.
En inglés cotidiano, la redundancia puede tener una connotación negativa; algo redundante generalmente no se necesita o se considera superfluo. Sin embargo, en un entorno de alojamiento en la nube, la redundancia puede significar la diferencia entre la disponibilidad del sistema sin interrupciones y el tiempo de inactividad no deseado o inesperado.
- ¿Qué es un Sistema Redundante?
- Tipos de sistemas redundantes
- Ejemplos de Servicios de software Redundantes
- Réplica de Hyper-V
- Agrupación en clústeres Hyper-V
- HAProxy
- Heartbeat
- Ejemplos de Servicios de Hardware redundantes
- RAID
- Redundancia de red
- Protocolos de redundancia de primer salto (FHRP)
- El Protocolo de redundancia de enrutadores virtuales (VRRP)
- Protocolo de enrutador en espera activa (HSRP)
- Protocolo de equilibrio de carga de puerta de enlace (GLBP)
- Redundancia del centro de datos
- Conclusión
¿Qué es un Sistema Redundante?
Un sistema redundante proporcionará soporte de conmutación por error o equilibrio de carga para proteger un sistema activo en caso de un fallo inesperado. En caso de fallo de energía, mecánico o de software, un sistema redundante tendrá un componente o plataforma duplicados a los que recurrir. En general, cualquier componente de un sistema con un único punto de falla puede considerarse un riesgo para los servicios de producción.
Los sistemas de alimentación o mecánicos tienen estrategias de retroceso más simples que requieren la mera presencia de otro del mismo tipo de servicio; los failovers de software generalmente requieren una configuración adicional en el sistema host o en un maestro o puerta de enlace.
Las capacidades de redundancia se recomiendan para cualquier sistema crítico para el negocio, pero particularmente para sistemas que tienen un impacto significativo durante el tiempo de inactividad. Algunas empresas pueden mantener toda la información crítica de sus clientes en una base de datos; por lo tanto, para fines de continuidad del negocio, proteger esa base de datos con redundancia protegerá la integridad de los datos en caso de una falla catastrófica.
Tipos de sistemas redundantes
Un sistema redundante consiste en al menos dos sistemas que están interconectados y diseñados para el mismo propósito. Hay muchos tipos diferentes de configuraciones de sistema redundantes disponibles, y las diferentes implementaciones del sistema proporcionan enfoques únicos para mantener un sistema en funcionamiento en todo momento.
No es necesario configurar todos los servidores con redundancia, sino que solo se deben considerar los más críticos. Recomendamos encarecidamente una evaluación de riesgos detallada para comprender qué servidores están en el alcance y la cantidad máxima de tiempo de inactividad que sus servidores pueden manejar. Utilice esta evaluación para determinar una estrategia RTO (Objetivo de Tiempo de Recuperación) y RPO (Objetivo de Punto de Recuperación). RTO es la cantidad máxima de tiempo de inactividad aceptable. Esto puede variar de 5 segundos a 24 horas. El RPO es el punto en el tiempo desde el que necesita sus datos; por ejemplo, su negocio puede funcionar con una pérdida máxima de datos de 24 horas.
Aquí hay algunos ejemplos populares:
- Activo-Inactivo / Caliente-Frío: Cuando un componente de un sistema es el sistema activo y otro está inactivo o apagado. El componente inactivo solo se activa cuando el componente en ejecución falla o se somete a mantenimiento
- Activo-Activo/Caliente-Caliente – Cuando ambos sistemas están activos y realizan conexiones. Esto se conoce más comúnmente como agrupamiento. Por lo general, el dispositivo frente a ambas máquinas determinará cómo dividir el tráfico entrante
- Activo-En espera/Caliente-Caliente, cuando ambos sistemas están encendidos, pero solo uno está haciendo conexiones. El segundo sistema está destinado a recibir actualizaciones o copias de seguridad periódicas del sistema principal. En caso de fallo, el sistema en espera asume el papel principal hasta que se pueda recuperar el sistema inicial.
Cada tipo tiene sus propios pros y contras.
- Los sistemas Activo-Inactivo/Frío-caliente pueden proporcionar una plataforma redundante simple, pero cualquier conmutación por error hará que los usuarios vean una versión anterior del sistema.
- Active-Active / Hot-Hot requerirá una actualización constante de ambos sistemas, ya sea manualmente o a través de un servicio separado, para garantizar que todos los usuarios puedan usar cualquiera de los dos sistemas. Este enfoque puede reducir en gran medida la carga activa de un servicio que está proporcionando a los clientes.
- Active-Standby / Hot-Warm proporcionará las capacidades de conmutación por error de hot-cold con una copia más actualizada de su sistema activo en la conmutación por error, pero no proporciona ninguna facilitación de carga.
Hay disponibles otras formas de redundancia de nodos múltiples que permiten una mayor redundancia y soluciones robustas de equilibrio de carga. En ese momento, tendrá un clúster de alta disponibilidad, también conocido como clúster de HA.
Esto puede usar cualquier combinación de las soluciones de redundancia mencionadas anteriormente con la máxima flexibilidad en el enfoque o la cantidad de redundancia necesaria. Los clústeres de HA también se pueden configurar en múltiples ubicaciones físicas para permitir la disponibilidad hasta el nivel de red troncal de Internet.
Ejemplos de Servicios de software Redundantes
A falta de una baja disponibilidad de recursos, hay muy pocas razones para no tener replicación propietaria o servicios redundantes configurados en un entorno virtual; por lo tanto, muchos de estos servicios están disponibles de forma predeterminada en la mayoría de los sistemas de virtualización. Todos nuestros servicios en la nube tienen replicación disponible, una característica que nos permite replicar cualquier servidor de un nodo a otro, ya sea que se encuentren en el mismo centro de datos o en regiones de centros de datos separadas.
Réplica de Hyper-V
La réplica de Hyper-V es una forma de redundancia caliente-caliente. Se crea una máquina virtual principal en un host físico y acepta conexiones entrantes. Al habilitar la replicación, los discos duros virtuales de la nueva máquina se transfieren a un host Hyper-V físico independiente. A continuación, este host configura una máquina virtual en sí misma que se replica en una programación definida por el usuario para garantizar que se tome la imagen más reciente del servidor activo. También se pueden mantener puntos de control adicionales. El alojamiento privado Hyper-V con servicios administrados es proporcionado por Atlantic.Net con esta característica incorporada, póngase en contacto con nuestro equipo para obtener más información.
Agrupación en clústeres Hyper-V
Hyper-V también es capaz de agruparse a través de una conexión a otros hosts Hyper-V. Las máquinas virtuales de cualquier host Hyper-V se pueden agrupar en clúster en ese host singular para proporcionar redundancia a nivel local a través de redes virtuales.
Equilibrio de carga de red (NLB) de Microsoft se puede utilizar para crear un único recurso compuesto por varios hosts que comparten la misma información para proporcionar un punto de acceso sencillo para compartir archivos. Dado que esto solo está limitado por la cantidad de recursos que tiene disponibles, teóricamente puede configurar varios hosts con varias máquinas virtuales para obtener la máxima redundancia, lo que también le permitiría realizar el mantenimiento en máquinas virtuales individuales sin sacrificar la disponibilidad de servicios o recursos. El alojamiento privado Hyper-V con servicios administrados es proporcionado por Atlantic.Net con esta característica incorporada, póngase en contacto con nuestro equipo para obtener más información.
HAProxy
Además de Hyper-V, se puede usar un dispositivo de puerta de enlace, como un firewall, para conmutación por error o servicios de equilibrio de carga. Por ejemplo, Atlantic.Net puede proporcionar a pfSense un Proxy de alta disponibilidad, también conocido como HAProxy.
HAProxy actuará como un equilibrador de carga, un proxy o una solución simple de alta disponibilidad caliente y caliente para aplicaciones basadas en TCP y HTTP. HAProxy es una solución de código abierto basada en Linux muy popular utilizada por algunos de los sitios más visitados del mundo.
Heartbeat
Heartbeat es un servicio disponible en la mayoría de las distribuciones de Linux que se utiliza para determinar si los nodos de un clúster siguen activos o responden. Es muy sencillo de configurar y proporciona capacidades de conmutación por error a cualquier sistema que trabaje sobre TCP.
Los desarrolladores de Heartbeat también recomiendan otros administradores de recursos de clúster que inician o detienen servicios en función de si un host en particular está inactivo. Heartbeat incluye esto, pero hay otros gerentes disponibles. Debido a la simplicidad de Heartbeat, es altamente personalizable. Plataformas de alojamiento Cloud proporcionadas por Atlantic.Net ya tiene esta característica incorporada, y podemos ayudarlo con la implementación de Heartbeat en su propia distribución privada de Linux, si es necesario.
Ejemplos de Servicios de Hardware redundantes
La mejor parte del hardware redundante es su simplicidad. Si bien los servicios de software pueden requerir una configuración excesiva y posiblemente sean bastante sensibles, el hardware suele ser muy simple de configurar e increíblemente duradero. El primer ejemplo que veremos es la tecnología RAID ampliamente utilizada.
RAID
RAID significa Matriz Redundante de Discos Independientes (o Matriz Redundante de Discos de bajo costo, dependiendo del tiempo que lo haya estado usando) y tiene varios niveles utilizados para protección de datos o E/S de disco aumentada.
RAID se puede configurar a través de un controlador de software o hardware. El controlador tiene el software y la configuración necesarios para administrar los discos RAID. La configuración se puede exportar a diferentes sistemas con poca o ninguna configuración adicional.
RAID se puede configurar de varias maneras diferentes para proporcionar un buen equilibrio de sus dos cualidades:
- RAID 0 – Esto esencialmente no es redundancia. No hay discos en el sistema que compartan datos a través de la duplicación, pero todos los datos se rayan en cada disco, lo que aumenta la velocidad de lectura/escritura. Cada unidad aún puede usar el almacenamiento que se le proporciona al máximo, lo que significa que cuantas más unidades agregue a un RAID 0, más espacio tendrá.
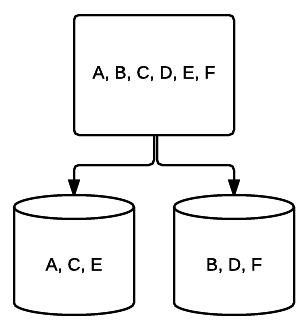
- RAID 1 – Una forma básica de duplicación que proporciona una excelente redundancia a costa de espacio. En un sistema de dos unidades, se escribe una copia completa de los datos de una unidad en la otra. Esta redundancia se mejora con cada unidad añadida. Dado que todos los datos deben reflejarse en todas las unidades, el espacio total en el sistema se limitará al espacio de la unidad más pequeña del sistema.
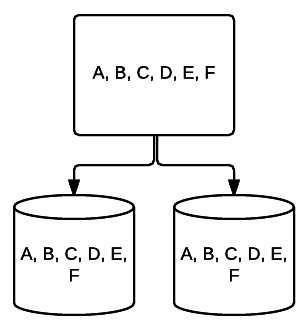
- RAID 5 – Esta forma de RAID se utiliza generalmente para aumentar la velocidad de lectura y fiabilidad. En este caso, se colocan franjas sobre cada unidad en el sistema, con un mínimo de 3 unidades. Al mismo tiempo, se coloca un bloque adicional de datos de corrección de errores sobre cada unidad en una técnica llamada paridad. Esto comprueba si los datos se cambian al transferir de una unidad a otra. Esto también proporciona una forma mínima de redundancia, ya que 1 de estas unidades puede fallar y el sistema aún puede ejecutarse. Cuantas más unidades se agreguen a este tipo de configuración RAID, más aumentará su velocidad de lectura. Con una redundancia y bandas mínimas en todas las unidades, la cantidad total de espacio en esta configuración es igual al tamaño de su volumen RAID lógico multiplicado por el número de unidades que utiliza, menos una. Por ejemplo, si tiene 5 unidades de 500 GB en un RAID 5, tendría 2000 GB utilizables o 2 TB (500 *(5-1)=2000).
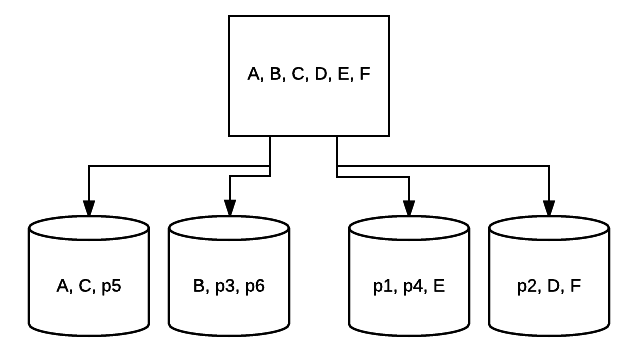
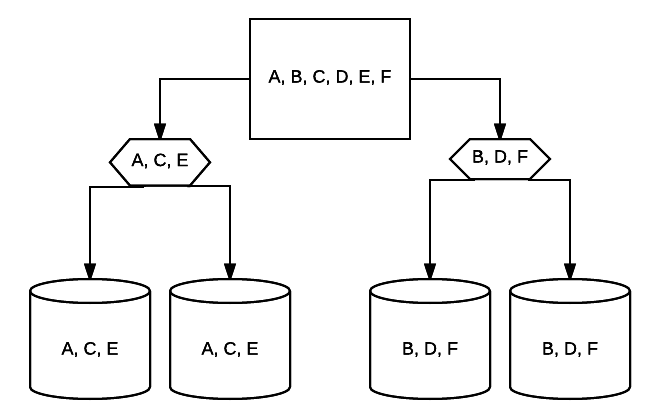
- RAID 10 – Esta es una combinación de RAID 1 y RAID 0. En este caso, todos los datos se rayan en cada dispositivo con bloques de datos que también se reflejan en la totalidad del sistema rayado. Por ejemplo, en un sistema RAID 10 de 4 unidades, 2 unidades de 500 GB pueden tener los mismos datos, pero no todos los datos necesarios para que el sistema funcione correctamente. se requerirían 2 datos de otras unidades. Piense en cada sistema RAID 1 como una sola unidad, y cada uno de esos sistemas colocados en una matriz RAID 0. En esta configuración, el rendimiento se puede aumentar drásticamente como en RAID 0, con cierta redundancia aún en su lugar con la duplicación. Hasta la mitad de las unidades del sistema pueden fallar antes de que el sistema se bloquee, pero al igual que con cualquier matriz redundante, es mejor reemplazar las unidades lo antes posible. Atlantic.Net utiliza RAID 10 para todo el almacenamiento SSD VPS en la Nube.
Para mayor protección, los controladores RAID están protegidos por unidades de respaldo de batería que alimentan los chips ROM utilizados para guardar la configuración en la memoria en caso de pérdida de energía, etc. Una BBU proporcionará energía a una matriz RAID que forma parte de un sistema apagado durante un pequeño período de tiempo, lo que permite que el contenido de la caché de un controlador RAID permanezca intacto. Esto puede ser un salvavidas si la información se alimenta constantemente a su matriz RAID y cualquier tiempo de inactividad podría causar daños en los datos.
Por lo tanto, su sistema físico y los servicios dentro de él se pueden construir de forma redundante bastante adecuada. Pero, ¿qué pasa con su conexión a cualquier parte de su sistema? Como en, su conexión directa a Internet a su sistema en su conjunto?
Redundancia de red
Protocolos de redundancia de primer salto (FHRP)
A diferencia de los protocolos de detección de puerta de enlace dinámica, las puertas de enlace estáticas permiten saltos directos entre el cliente y su puerta de enlace apropiada, pero esto crea un único punto de error, a saber, la puerta de enlace en sí.
Para prevenir o reducir el impacto de la falla de la pasarela, se crearon FHRP. Proporcionan puertas de enlace redundantes como alternativa u ofrecen equilibrio de carga para sistemas de alto tráfico, junto con redundancia. Estos protocolos incluyen VRRP, HSRP y GLBP.
El Protocolo de redundancia de enrutadores virtuales (VRRP)
VRRP es una forma de redundancia utilizada para enrutadores que requiere al menos dos enrutadores físicamente separados conectados a través de conexiones Ethernet o de fibra óptica. En esta situación, se crea un ‘enrutador virtual’ que contiene rutas estáticas y se comparte entre cada sistema.
Un sistema se considera el ‘maestro’ y otro el ‘respaldo’. Cuando el maestro falla, la copia de seguridad se hace cargo del siguiente maestro. Esto se puede configurar con múltiples copias de seguridad para una redundancia adicional. El concepto es muy similar a Heartbeat en el sentido de que los sistemas de respaldo comprobarán si el maestro está disponible. Una vez que no recibe una respuesta, después de un período de tiempo predeterminado, la copia de seguridad asumirá el control del conmutador virtual y aceptará conexiones para todas las solicitudes que lleguen para la IP predeterminada configurada para el conmutador maestro.
Protocolo de enrutador en espera activa (HSRP)
HSRP es como VRRP; sin embargo, en este escenario, el conmutador virtual configurado no es un «conmutador», sino más bien un grupo lógico de múltiples enrutadores. La IP del grupo es una IP no asignada a un host físico. En su lugar, al grupo se le asigna una IP y se determina que uno de los enrutadores es el enrutador ‘activo’.
Un enrutador en espera está listo para tomar cualquier conexión en caso de que el enrutador activo se caiga. Todos los enrutadores, además de los activos y en espera, están escuchando para determinar su lugar en la línea. HSRP es un protocolo propietario de Cisco y tiene muy pocas diferencias menores con VRRP, como sus temporizadores predeterminados que determinan cuándo se debe realizar la conmutación por error. HSRP ha existido un poco más y es más conocido en comparación con VRRP.
Protocolo de equilibrio de carga de puerta de enlace (GLBP)
La principal ventaja de GLBP sobre HSRP y VRRP es su capacidad para equilibrar la carga además de proporcionar redundancia a una puerta de enlace con poca o ninguna configuración adicional. Al igual que HSRP y VRRP, GLBP creará un grupo entre enrutadores físicos y determinará una Puerta de enlace Virtual Activa, o AVG.
Se asigna a AVG una IP virtual que no utiliza actualmente ninguno de los enrutadores del grupo. A continuación, AVG distribuye las direcciones MAC virtuales entre el resto de los enrutadores del grupo. Cada enrutador de copia de seguridad ahora se considera un Reenviador Virtual Activo, o AVF.
Las solicitudes ARP enviadas a AVG proporcionarán una dirección MAC virtual diferente al cliente que envía la solicitud. En ese momento, el tráfico de ese cliente a la IP virtual del grupo se reenvía al enrutador cuya dirección MAC virtual recibieron, lo que permite que cada enrutador se siga utilizando en lugar de quedarse de brazos cruzados.
En caso de fallo del AVG, se lleva a cabo una elección basada en prioridades, al igual que en HSRP y VRRP, y la siguiente copia de seguridad toma su lugar, distribuyendo las direcciones MAC virtuales de forma normal. Los otros enrutadores aún conservan la dirección MAC virtual proporcionada por el AVG original y las cosas continúan con normalidad. En caso de fallo de uno de los aVF, el AVG evitará el enrutamiento de tráfico a su dirección MAC virtual.
Al igual que HSRP, GLBP es una forma patentada de Cisco de FHRP.
Redundancia del centro de datos
Además de las medidas de redundancia para sus servidores o enrutadores personales, los centros de datos están diseñados para ser resistentes a los fallos del sistema. Los centros de datos pertenecen a niveles definidos por el Uptime Institute para proporcionar tolerancia a fallos en caso de fallos mecánicos o de servicio, lo que permite la mayor cantidad de tiempo de actividad posible.
Hay cuatro niveles, cada uno construido uno sobre el otro para proporcionar alta disponibilidad a todos los clientes dentro de un centro de datos:
- Tier I-Capacidad básica: Esto requiere de espacio para un grupo de operaciones del centro de datos, un sistema de alimentación ininterrumpida (SAI) que controla y filtra el uso de la energía y dedicado equipo de refrigeración que está constantemente en funcionamiento 24/7. Esto también incluye un generador de energía en caso de falla de energía eléctrica.
- Componentes de capacidad redundantes de nivel II: Todo lo que proporciona el nivel I, además de energía y refrigeración redundantes para la instalación. Esto puede incluir unidades UPS adicionales o generadores adicionales.
- Nivel III-Mantenible simultáneamente: Todo lo que ofrece Tier II, además de equipo adicional en el lugar para evitar cualquier necesidad de paradas para el reemplazo o mantenimiento del equipo. En este nivel, la energía y la refrigeración redundantes se aplican directamente a todos los equipos técnicos, y el equipo en sí está configurado para redundancia o conmutación por error sin interrupciones.
- Nivel IV – Tolerancia a fallos: Todo lo que ofrece el nivel III, además de un servicio ininterrumpido a nivel de proveedor. Si bien un centro de datos puede tener electricidad o agua proporcionada por un proveedor de la ciudad o el estado, se requiere una línea secundaria de cada servicio utilizado por el centro de datos. Esto también incluye al ISP. En caso de fallo en cualquier sección que conduzca al equipo del cliente, hay un plan de respaldo listo para una transición sin problemas.
Conclusión
La redundancia se ha convertido en un término cotidiano en la industria de TI debido a la necesidad. La alta disponibilidad de servicios proporciona una experiencia fácil y confiable para nuestros clientes.
Ya sea a nivel de servicio o de centro de datos, proporcionar redundancia a su sistema es un problema importante y difícil de abordar. Con suerte, este documento ha arrojado algo de luz sobre las opciones disponibles y ayudará en cualquier decisión que se tome con respecto a la alta disponibilidad en el futuro.
Listo para aprovechar Atlantic.Net ¿sistemas redundantes? Póngase en contacto con nosotros hoy mismo para obtener más información sobre el alojamiento de servidores Dedicados con Atlantic.Net.
===Fuentes===
Conceptos básicos del sistema redundante: http://www.ni.com/white-paper/6874/en/
Servidor frío/cálido/caliente: http://searchwindowsserver.techtarget.com/definition/cold-warm-hot-server
Agrupamiento de alta disponibilidad: https://www.mulesoft.com/resources/esb/high-availability-cluster
Réplica de Hyper-V: https://technet.microsoft.com/en-us/library/jj134172(v=ws.11).aspx
Hyper-V and High Availability: https://technet.microsoft.com/en-us/library/hh127064.aspx
HAProxy Description: http://www.haproxy.org/#desc
HAProxy – They use it!: http://www.haproxy.org/they-use-it.html
Heartbeat: http://www.linux-ha.org/wiki/Main_Page
RAID Definition: http://searchstorage.techtarget.com/definition/RAID
Striping: http://searchstorage.techtarget.com/definition/disk-striping
RAID Battery Backup Units: https://www.thomas-krenn.com/en/wiki/Battery_Backup_Unit_(BBU/BBM)_Maintenance_for_RAID_Controllers
High-Availability – VRRP, HSRP, GLBP: http://www.freeccnastudyguide.com/study-guides/ccna/ch14/vrrp-hsrp-glbp/
Understanding VRRP: http://www.juniper.net/techpubs/en_US/junos/topics/concept/vrrp-overview-ha.html
Configuring VRRP: http://www.cisco.com/c/en/us/td/docs/ios-xml/ios/ipapp_fhrp/configuration/15-mt/fhp-15-mt-book/fhp-vrrp.html
Configuring GLBP: http://www.cisco.com/c/en/us/td/docs/ios-xml/ios/ipapp_fhrp/configuration/xe-3s/fhp-xe-3s-book/fhp-glbp.html
Explaining the Uptime Institute’s Tier Classification System: https://journal.uptimeinstitute.com/explaining-uptime-institutes-tier-classification-system/