
El aprendizaje automático se utiliza en última instancia para predecir resultados dados un conjunto de características. Por lo tanto, cualquier cosa que podamos hacer para generalizar el rendimiento de nuestro modelo se ve como una ganancia neta. La deserción es una técnica utilizada para evitar que un modelo se sobreajuste. Dropout funciona estableciendo aleatoriamente los bordes salientes de las unidades ocultas (neuronas que forman capas ocultas) a 0 en cada actualización de la fase de entrenamiento. Si echas un vistazo a la documentación de Keras para la capa de abandono, verás un enlace a un libro blanco escrito por Geoffrey Hinton y amigos, que analiza la teoría detrás del abandono.
En el procedimiento de ejemplo, vamos a utilizar Keras para construir una red neuronal con el objetivo de reconocer escrito a mano dígitos.
from keras.datasets import mnist
from matplotlib import pyplot as plt
plt.style.use('dark_background')
from keras.models import Sequential
from keras.layers import Dense, Flatten, Activation, Dropout
from keras.utils import normalize, to_categorical
utilizamos Keras para importar los datos en nuestro programa. Los datos ya están divididos en los conjuntos de entrenamiento y pruebas.
(X_train, y_train), (X_test, y_test) = mnist.load_data()
Echemos un vistazo para ver con qué estamos trabajando.
plt.imshow(x_train, cmap = plt.cm.binary)
plt.show()

Después de terminado el entrenamiento fuera del modelo, debe ser capaz de reconocer la imagen anterior como un cinco.
Hay un poco de preprocesamiento que debemos realizar de antemano. Normalizamos los píxeles (entidades) de manera que varíen de 0 a 1. Esto permitirá que el modelo converja hacia una solución mucho más rápida. A continuación, transformamos cada una de las etiquetas de destino para una muestra dada en una matriz de 1s y 0s donde el índice del número 1 indica el dígito que representa la imagen. Hacemos esto porque de lo contrario nuestro modelo interpretaría el dígito 9 como si tuviera una prioridad más alta que el número 3.
X_train = normalize(X_train, axis=1)
X_test = normalize(X_test, axis=1)
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
Sin abandono
Antes de alimentar una matriz de 2 dimensiones en una red neuronal, usamos una capa plana que la transforma en una matriz de 1 dimensión anexando cada fila posterior a la que la precedió. Vamos a usar dos capas ocultas que constan de 128 neuronas cada una y una capa de salida que consta de 10 neuronas, cada una para uno de los 10 dígitos posibles. La función de activación softmax devolverá la probabilidad de que una muestra represente un dígito dado.

Ya que estamos tratando de predecir las clases, utilizamos categórica crossentropy como nuestra función de pérdida. Mediremos el rendimiento del modelo con precisión.
model.compile(
loss='categorical_crossentropy',
optimizer='adam',
metrics=
)
Dejamos el 10% de los datos a un lado para la validación. Usaremos esto para comparar la tendencia de un modelo a sobreajustarse con y sin abandono. Un tamaño de lote de 32 implica que calcularemos el gradiente y daremos un paso en la dirección del gradiente con una magnitud igual a la tasa de aprendizaje, después de haber pasado 32 muestras a través de la red neuronal. Hacemos esto un total de 10 veces según lo especificado por el número de épocas.
history = model.fit(
X_train,
y_train,
epochs=10,
batch_size=32,
validation_split=0.1,
verbose = 1,
shuffle=True
)
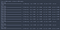
podemos trazar el entrenamiento y validación de la precisión en cada época por el uso de la historia de la variable devuelta por el ajuste de la función.
Como puede ver, sin abandono, la pérdida de validación deja de disminuir después de la tercera época.

As you can see, without dropout, the validation accuracy tends to plateau around the third epoch.

Using this simple model, we still managed to obtain an accuracy of over 97%.
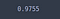
test_loss, test_acc = model.evaluate(X_test, y_test)
test_acc
Deserción
Hay cierto debate sobre si la deserción se debe colocar antes o después de la función de activación. Como regla general, coloque la opción de abandono después de la función de activación para todas las funciones de activación que no sean relu. Al pasar 0,5, cada unidad oculta (neurona) se establece en 0 con una probabilidad de 0,5. En otras palabras, hay un cambio del 50% que la salida de una neurona dada se verá forzada a 0.

de Nuevo, ya que estamos tratando de predecir las clases, utilizamos categórica crossentropy como nuestra función de pérdida.
model_dropout.compile(
loss='categorical_crossentropy',
optimizer='adam',
metrics=
)
Al proporcionar el parámetro de división de validaciones, el modelo separará una fracción de los datos de entrenamiento y evaluará la pérdida y cualquier métrica del modelo en estos datos al final de cada época. Si la premisa detrás de la deserción se mantiene, entonces deberíamos ver una diferencia notable en la precisión de validación en comparación con el modelo anterior. El parámetro barajar barajará los datos de entrenamiento antes de cada época.
history_dropout = model_dropout.fit(
X_train,
y_train,
epochs=10,
batch_size=32,
validation_split=0.1,
verbose = 1,
shuffle=True
)

Como puede ver, la validación de la pérdida es significativamente inferior a la obtenida mediante el modelo regular.

Como puede ver, el modelo convergente mucho más rápido y se obtuvo una precisión de cerca de 98% en el conjunto de validación, mientras que el modelo anterior estancado alrededor de la tercera época.

La exactitud que se obtiene en el conjunto de pruebas no es muy diferente de la obtenida a partir del modelo sin la deserción escolar. Esto se debe con toda probabilidad al número limitado de muestras.
test_loss, test_acc = model_dropout.evaluate(X_test, y_test)
test_acc

conclusión
de Deserción escolar puede ayudar a un modelo de generalizar por azar configuración de la salida de una neurona determinada a 0. Al establecer la salida en 0, la función de costo se vuelve más sensible a las neuronas vecinas, cambiando la forma en que se actualizarán los pesos durante el proceso de backpropagación.