Por: Arshad Ali | Actualizado: 2020-07-29 | Comentarios (6)/Relacionado: Más > Tablas DE unión
- Problema
- Solución
- Explicación de la unión de Bucles anidados de SQL Server
- Script #1 – Ejemplo de unión de bucles anidados
- Explicación de la combinación de SQL Server
- Script #2 – Ejemplo de combinación de combinación
- Explicación de la combinación Hash de SQL Server
- Script #3 – Hash Join Ejemplo
- Pasos siguientes
- About the author
Problema
En los ejemplos de uniones de SQL Server de tip, Jeremy Kadlec habló sobre diferentes operadores de unión lógica, pero ¿cómo los implementa SQL Server físicamente? ¿Cuáles son los diferentes cooperadores físicos? ¿En qué se diferencian unos de otros y en qué escenario se prefiere uno a otro? En este consejo, cubrimos estas preguntas y más.
Solución
Utilizamos operadores lógicos cuando escribimos consultas para definir una consulta relacional a nivel conceptual (lo que hay que hacer). SQL implementa estos operadores lógicos con tres operadores físicos diferentes para implementar la operación definida por los operadores lógicos (cómo debe hacerse). Aunque hay docenas de operadores físicos, en este consejo cubriré operadores de unión física específicos. Aunque tenemos diferentes tipos de uniones lógicas a nivel conceptual / de consulta, SQL Server las implementa todas con tres operadores de unión física diferentes, como se explica a continuación.
Cubriremos:
- Bucles anidados Join
- Merge Join
- Hash Join
Buscaremos en los planes de ejecución para ver estos operadores y explicaré por qué ocurre cada uno.
Para estos ejemplos, estoy utilizando la base de datos de AdventureWorks.
Explicación de la unión de Bucles anidados de SQL Server
Antes de profundizar en los detalles, déjeme decirle primero qué es una unión de Bucles anidados si es nuevo en el mundo de la programación.
Una unión de bucles anidados es una estructura lógica en la que un bucle (iteración) reside en otro, es decir, para cada iteración del bucle externo se ejecutan/procesan todas las versiones del bucle interno.
Una combinación de Bucles Anidados funciona de la misma manera. Una de las mesas de unión está designada como la mesa exterior y otra como la mesa interior. Para cada fila de la tabla externa, todas las filas de la tabla interna se comparan una por una si la fila coincide se incluye en el conjunto de resultados, de lo contrario se ignora. Luego, se recoge la siguiente fila de la mesa exterior y se repite el mismo proceso, etc.
El optimizador de SQL Server puede elegir una combinación de bucles anidados cuando una de las tablas de unión es pequeña (considerada como la tabla externa) y otra es grande (considerada como la tabla interna que está indexada en la columna que está en la combinación) y, por lo tanto, requiere una E/S mínima y la menor cantidad de comparaciones.
El optimizador considera tres variantes para una combinación de Bucles Anidados:
- se unen bucles anidados ingenuos en cuyo caso la búsqueda escanea toda la tabla o índice
- se unen bucles anidados de índice cuando la búsqueda puede utilizar un índice existente para realizar búsquedas
- Se unen bucles anidados de índice temporal si el optimizador crea un índice temporal como parte del plan de consulta y lo destruye después de la ejecución de la consulta Se completa
Una unión de bucles anidados de índice funciona mejor que una unión de fusión o una unión hash si se trata de un pequeño conjunto de filas. Mientras que, si un gran conjunto de filas está involucrado, los bucles anidados podrían no ser una opción óptima. Los bucles anidados admiten casi todos los tipos de unión, excepto las uniones exteriores derechas y completas, las semi-uniones derechas y las anti-semijoinas derechas.
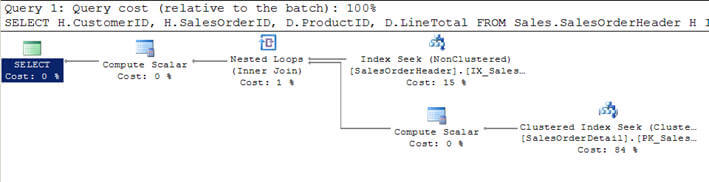
- En el script #1, me uniré a la tabla SalesOrderHeader con SalesOrderDetailtable y especificaré los criterios para filtrar el resultado del cliente con CustomerID = 670.
- Este criterio filtrado devuelve 12 registros de la tabla SalesOrderHeader y, por lo tanto, al ser la más pequeña, esta tabla ha sido considerada como la tabla más externa (la superior en el plan de ejecución de consultas gráficas)por el optimizador.
- Para cada fila de estas 12 filas de la tabla externa, las filas de la lista de ventas de la tabla interna se comparan (o la tabla interna se escanea 12 veces cada vez para cada fila utilizando la búsqueda de índice o el parámetro correlacionado de la tabla externa) y se devuelven 312 filas coincidentes como puede ver en la segunda imagen.
- En la segunda consulta a continuación, estoy usando ESTABLECER PERFIL DE ESTADÍSTICAS para mostrar la información del archivo de la ejecución de la consulta junto con el conjunto de resultados de la consulta.
Script #1 – Ejemplo de unión de bucles anidados
SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader H INNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID = 670
SET STATISTICS PROFILE ONSELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader HINNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderIDWHERE H.CustomerID = 670SET STATISTICS PROFILE OFF

Si el número de registros involucrados es grande, SQL Server puede optar por paralelizar un bucle anidado distribuyendo las filas de la tabla externa aleatoriamente entre los hilos de bucles anidados disponibles de forma dinámica. Sin embargo, no se aplica lo mismo para las mesetas interiores. Para obtener más información sobre los escaneos paralelos, haga clic aquí.
Explicación de la combinación de SQL Server
Lo primero que debe saber sobre una combinación de combinación es que requiere que ambas entradas se ordenen en claves de combinación/columnas de combinación (o ambas tablas de entrada tienen índices en clúster en la columna que une las tablas) y también requiere al menos una expresión/predicado equijuin(igual a).
Debido a que las filas están pre-ordenadas, una combinación de combinación comienza inmediatamente el proceso de coincidencia. Lee una fila de una entrada y la compara con la fila de otra entrada.Si las filas coinciden, esa fila coincidente se considera en el conjunto de resultados (luego lee la siguiente fila de la tabla de entrada, hace la misma comparación/coincidencia, etc.) o se ignora la menor de las dos filas y el proceso continúa de esta manera hasta que se hayan procesado todas las filas..
Una combinación de combinación funciona mejor al unir tablas de entrada grandes (preindiciadas / ordenadas), ya que el costo es la suma de filas en ambas tablas de entrada, en lugar de las anidadas, donde es un producto de filas de ambas tablas de entrada. A veces, el optimizador decide usar una combinación cuando las tablas de entrada no están ordenadas y, por lo tanto, utiliza un operador físico de ordenación explícito, pero puede ser más lento que usar un índice(tabla de entrada pre-ordenada).
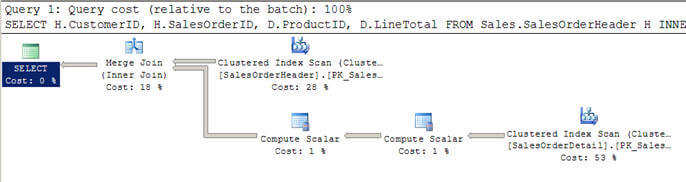
- En el script # 2, estoy usando una consulta similar a la anterior, pero esta vez he añadido una cláusula WHERE para obtener todos los clientes mayores de 100.
- En este caso, el optimizador decide usar una combinación de combinación ya que ambas entradas son grandes en términos de filas y también están preindiciadas/ordenadas.
- También puede notar que ambas entradas se escanean solo una vez, en lugar de los 12 escaneos que vimos en los Bucles anidados que se unen arriba.
Script #2 – Ejemplo de combinación de combinación
SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader H INNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID > 100
SET STATISTICS PROFILE ONSELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader HINNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderIDWHERE H.CustomerID > 100SET STATISTICS PROFILE OFF

Una combinación de combinación es a menudo un operador de combinación más eficiente y rápido si los datos de clasificación se pueden obtener de un índice de árbol B existente y realiza casi todas las operaciones de combinación siempre que haya al menos un predicado de unión de igualdad involucrado. Ital también admite múltiples predicados de unión de igualdad siempre que las tablas de entrada estén ordenadas en todas las claves de unión involucradas y estén en el mismo orden.
La presencia de un operador Escalar de Cálculo indica la evaluación de una expresión para producir un valor escalar calculado. En la consulta anterior estoy seleccionando Linetotal, que es una columna derivada, por lo que se ha utilizado en el plan de ejecución.
Explicación de la combinación Hash de SQL Server
Normalmente se utiliza una combinación Hash cuando las tablas de entrada son bastante grandes y no existen índices adecuados en ellas. Una unión Hash se realiza en dos fases; la fase de construcción y la fase de sondeo y, por lo tanto, la unión hash tiene dos entradas, es decir, entrada de construcción y entrada de probeta. La más pequeña de las entradas se considera como la entrada de compilación (para minimizar el requisito de memoria para almacenar una tabla hash discutida más adelante) y, obviamente, la otra es la entrada de sonda.
Durante la fase de compilación, se escanean las claves de unión de todas las filas de la tabla de compilación.Los hashes se generan y se colocan en una tabla de hash en memoria. A diferencia de la combinación,está bloqueando (no se devuelven filas) hasta este punto.
Durante la fase de sonda, se escanean las teclas de unión de cada fila de la tabla de sonda.De nuevo se generan hashes (utilizando la misma función hash que la anterior) y se comparan con la tabla hash correspondiente para una coincidencia.
Una función Hash requiere una cantidad significativa de ciclos de CPU para generar hash y recursos de memoria para almacenar la tabla hash. Si hay presión de memoria, algunas de las particiones de la tabla hash se intercambian a tempdb y siempre que sea necesario (ya sea para sondear o actualizar el contenido) se devuelve a la caché.Para lograr un alto rendimiento, el optimizador de consultas puede paralelizar una combinación de Hash toscale mejor que cualquier otra combinación, para obtener más detalles, haga clic aquí.
Básicamente hay tres tipos diferentes de uniones hash:
- Unión Hash en memoria en cuyo caso hay suficiente memoria disponible para almacenar la tabla hash
- Unión Hash de gracia en cuyo caso la tabla hash no puede caber en la memoria y algunas particiones se derraman en tempdb
- Unión Hash recursiva en cuyo caso una tabla hash es tan grande que el optimizador tiene que usar muchos niveles de uniones merge.
Para obtener más detalles sobre estos tipos diferentes, haga clic aquí.
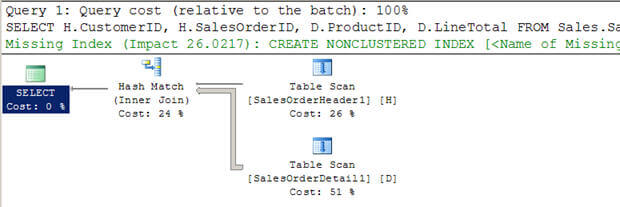
- En el script # 3, estoy creando dos nuevas tablas grandes (a partir de las tablas de AdventureWorkstables existentes) sin índices.
- Puede ver que el optimizador eligió usar una unión Hash en este caso.
- De nuevo, a diferencia de una unión de Bucles anidados, no escanea la tabla interna varias veces.
Script #3 – Hash Join Ejemplo
--Create tables without indexes from existing tables of AdventureWorks database SELECT * INTO Sales.SalesOrderHeader1 FROM Sales.SalesOrderHeader SELECT * INTO Sales.SalesOrderDetail1 FROM Sales.SalesOrderDetail GO SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader1 H INNER JOIN Sales.SalesOrderDetail1 D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID = 670 GO
SET STATISTICS PROFILE ON SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader1 H INNER JOIN Sales.SalesOrderDetail1 D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID = 670 SET STATISTICS PROFILE OFF

--Drop the tables created for demonstration DROP TABLE Sales.SalesOrderHeader1 DROP TABLE Sales.SalesOrderDetail1
Nota: SQL Server hace un trabajo bastante bueno en la decisión de qué joinoperator a utilizar en cada condición. Comprender estas condiciones le ayuda a comprender lo que se puede hacer en el ajuste del rendimiento. No se recomienda usar sugerencias de unión (usando la cláusula Option) para forzar a SQL Server a usar un operador de unión específico (a menos que no tenga otra salida), sino que puede usar otros medios como actualizar estadísticas,crear índices o reescribir su consulta.
Pasos siguientes
- Consejo de ejemplos de Revisión de servidor SQL.
- Artículo de referencia de Operadores físicos y de revisión en technet.
Última actualización: 2020-07-29


 Arshad Ali is a SQL and BI Developer focusing on Data Warehousing projects for Microsoft.
Arshad Ali is a SQL and BI Developer focusing on Data Warehousing projects for Microsoft.View all my tips
- More Database Developer Tips…