Ya no es un Big data de día..»historia que dio origen a esta era de big data, pero» hace mucho tiempo humans » los humanos comenzaron a recopilar información a través de encuestas manuales, sitios web, sensores, archivos y otras formas de métodos de recopilación de datos. Incluso esto incluye organizaciones internacionales como la OMS, la ONU, que recopiló a nivel internacional todos los conjuntos de información posibles para monitorear y rastrear actividades no solo relacionadas con los seres humanos, sino también con la vegetación y las especies animales para tomar decisiones importantes e implementar las acciones necesarias.
Así que las grandes multinacionales, especialmente las empresas de comercio electrónico y marketing, comenzaron a utilizar la misma estrategia para rastrear y monitorear las actividades de los clientes para promocionar marcas y productos, lo que dio lugar a la rama de análisis. Ahora no se saturará tan fácilmente, ya que las empresas se han dado cuenta del valor real de los datos para tomar decisiones fundamentales en cada fase del proyecto de principio a fin para crear las mejores soluciones optimizadas en términos de costo, cantidad, mercado, recursos y mejoras.
Las V de Big Data son volumen, velocidad, variedad, veracidad, valencia y valor, y cada una afecta la recopilación, el monitoreo, el almacenamiento, el análisis y la presentación de informes de datos. El Ecosistema en términos de actores tecnológicos del sistema de big data es como se ve a continuación.

Ahora voy a hablar de cada tecnología, uno por uno para dar una idea de lo importante de los componentes e interfaces.
Cómo extraer datos de los datos de redes sociales de Facebook, Twitter y linkedin en un simple archivo csv para su posterior procesamiento.
Para poder extraer datos de Facebook utilizando un código python, debe registrarse como desarrollador en Facebook y luego tener un token de acceso. Aquí están los pasos para ello.
1. Ir al enlace developers.facebook.com, crea una cuenta allí.
2. Ir al enlace developers.facebook.com/tools/explorer.
3. Ve al menú desplegable » Mis aplicaciones «en la esquina superior derecha y selecciona»agregar una nueva aplicación». Elija un nombre para mostrar y una categoría y, a continuación, «Crear ID de aplicación».
4. Volver el mismo enlace developers.facebook.com/tools/explorer. Usted verá «Graph API Explorer» por debajo de «Mis Aplicaciones» en la esquina superior derecha. En el menú desplegable» Explorador de API de gráficos», selecciona tu aplicación.
5. A continuación, seleccione «Obtener token». En este menú desplegable, seleccione «Obtener token de acceso de usuario». Seleccione Permisos en el menú que aparece y, a continuación, seleccione «Obtener token de acceso».»
6. Ir al enlace developers.facebook.com/tools/accesstoken. Seleccione «Depurar» correspondiente a «Token de usuario». Vaya a «Extender el acceso a tokens». Esto asegurará que su token no caduque cada dos horas.
Código Python para Acceder a Datos públicos de Facebook:
Vaya a enlace https://developers.facebook.com/docs/graph-api si desea recopilar datos sobre cualquier cosa que esté disponible públicamente. Véase https://developers.facebook.com/docs/graph-api / reference / v2. 7/. En esta documentación, elija cualquier campo del que desee extraer datos, como «grupos»o » páginas», etc. Vaya a ejemplos de códigos después de seleccionarlos y luego seleccione «api de gráficos de facebook» y obtendrá consejos sobre cómo extraer información. Este blog trata principalmente de obtener datos de eventos.
En primer lugar, importa ‘urllib3’, ‘facebook’, ‘solicitudes’ si ya están disponibles. Si no, descargue estas bibliotecas. Defina un token de variable y establezca su valor en lo que obtuvo anteriormente como «Token de acceso de usuario».

la Extracción de datos de Twitter:
Simple de 2 pasos se puede seguir la siguiente
- Usted prestará en la página de detalles de la aplicación; ve a la pestaña «Claves y tokens de acceso», desplázate hacia abajo y haz clic en «Crear mi token de acceso». Tenga en cuenta los valores de Clave de API y Secreto de API para uso futuro. No compartirás esto con nadie, uno puede acceder a tu cuenta si recibe las llaves.
- Para extraer tweets, deberá establecer una conexión segura entre R y Twitter de la siguiente manera,
#Borrar entorno R
rm(list=ls())
#Cargar bibliotecas requeridas
instalar.instalación de paquetes («twitteR»).packages («ROAuth»)
biblioteca («twitteR»)
biblioteca («ROAuth»)
# Descarga el archivo y guárdalo en tu directorio de trabajo
descarga.archivo (url = «http://curl.haxx.se/ca/cacert.pem», destfile = » cacert.pem»)
#Insert your consumerKey y consumerSecret a continuación
credenciales < OAuthFactory$new(consumerKey=’XXXXXXXXXXXXXXXXXX’,
consumerSecret=’XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX’,
requestURL=’https://api.twitter.com/oauth/request_token’,
accessURL=’https://api.twitter.com/oauth/access_token’,
authURL=’https://api.twitter.com/oauth/authorize’)
cred$apretón de manos(cainfo=»cacert.pem»)
#Cargar datos de autenticación
cargar («autenticación de Twitter.Rdata»)
#Registrar autenticación de Twitter
setup_twitter_oauth(credenciales consum consumerKey, credenciales consum consumerSecret, credenciales o oauthKey, credenciales credentials oauthSecret)
#Extraer Tweets con la cadena correspondiente(primer argumento), seguido del número de tweets (n) y el idioma (lang)
tweets <- searchTwitter(‘#DataLove’, n=10, lang=»en»)
Ahora puede buscar cualquier palabra en la función de búsqueda de Twitter para extraer los tweets que contienen la palabra.
Extracción de datos de Oracle ERP
Puede visitar el enlace para comprobar paso a paso la extracción del archivo csv de la base de datos oracle ERP cloud.
Adquisición y almacenamiento de datos:
Ahora, una vez extraídos los datos, deben almacenarse y procesarse, lo que hacemos en el paso de adquisición y almacenamiento de datos.Veamos cómo funciona Spark, Cassandra, Flume, HDFS, HBASE.
Spark
Spark se puede implementar de varias maneras, proporciona enlaces nativos para los lenguajes de programación Java, Scala, Python y R, y admite SQL, transmisión de datos, aprendizaje automático y procesamiento de gráficos.RDD es el framework para spark que ayudará en el procesamiento paralelo de datos dividiéndolos en marcos de datos. Para leer datos de la plataforma Spark, utilice el siguiente comando
results = spark.sql («Seleccionar * De personas»)
nombres = resultados.mapa (lambda p: p.name)
Conéctese a cualquier fuente de datos como json, JDBC, Hive to Spark utilizando comandos y funciones simples. Al igual que puede leer los datos json de la siguiente manera
spark.Leer.json («s3n://…»).registerTempTable («json»)
results = spark.sql («SELECT * FROM people JOIN json j»)
Spark consiste en más funciones como la transmisión desde fuentes de datos en tiempo real que vimos anteriormente utilizando fuentes R y python.
En el sitio web principal de apache spark puede encontrar muchos ejemplos que muestran cómo spark puede desempeñar un papel en la extracción de datos y el modelado.
https://spark.apache.org/examples.html
Cassandra:
Cassandra también es una tecnología Apache como spark para el almacenamiento y recuperación de datos y el almacenamiento en múltiples nodos para proporcionar tolerancia a errores 0. Utiliza comandos de base de datos normales, como operaciones de creación, selección, actualización y eliminación. También puede crear índices, vista materializada y normal con comandos simples como en SQL. La extensión es que puede usar el tipo de datos JSON para realizar operaciones adicionales como las que se muestran a continuación
Insert into mytable JSON ‘ {«\»MyKey\»»: 0, «value»: 0}’
Proporciona controladores de código abierto git hub para ser utilizados con.net, Python, Java, PHP, NodeJS, Scala, Perl, ROR.
Al configurar la base de datos, es necesario configurar el número de nodos por nombres de nodo, asignar token en función de la carga en cada nodo. También puede usar comandos de autorización y de rol para administrar los permisos de nivel de datos en un nodo determinado.
Para obtener más detalles, puede consultar el enlace dado
http://cassandra.apache.org/doc/latest/configuration/cassandra_config_file.html
Casandra promete lograr una tolerancia a errores de 0, ya que proporciona múltiples opciones para administrar los datos en un nodo dado mediante almacenamiento en caché, administración de transacciones, replicación, concurrencia para lectura y escritura, comandos de optimización de disco, administración del transporte y la longitud del tamaño del marco de datos.
HDFS
Lo que más me gusta de HDFS es su Icono, un elefante gigante potente y resistente como el propio HDFS.
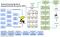
Como se ve en el diagrama anterior, el HDFS sistema de grandes volúmenes de datos es similar a como Cassandra, pero ofrece muy simple interfaz con sistemas externos.Los datos se cortan en marcos de datos de tamaño diferente o similar que se almacenan en un sistema de archivos distribuido. Los datos se transfieren a varios nodos en función de los resultados de consulta optimizados para almacenar datos. La arquitectura básica es de modelo centralizado de Hadoop if Map reduce el modelo.
1. Los datos se dividen en bloques de, por ejemplo,128 MB
2. Estos datos se distribuyen a través de varios nodos
3. HDFS supervisa el procesamiento
4. La replicación y el almacenamiento en caché se realizan para obtener la máxima tolerancia a fallos.
5. una vez que map and reduce se realiza y los trabajos se calculan correctamente, vuelven al servidor principal
Hadoop está codificado principalmente en Java, por lo que es genial si tiene algunas manos en Java, de lo que será rápido y fácil configurar y ejecutar todos esos comandos.
Se puede encontrar una guía rápida para todo el concepto relacionado con Hadoop en el siguiente enlace
https://www.tutorialspoint.com/hadoop/hadoop_quick_guide.html
Presentación de informes y visualización
Ahora hablemos de SAS, R studio y Kime, que se utilizan para analizar grandes conjuntos de datos con ayuda de algoritmos complejos que son algoritmos de aprendizaje automático que se basan en algunos modelos matemáticos complejos que analizan el conjunto de datos completo y crean la representación gráfica para atender el objetivo comercial específico deseado. Ejemplo de datos de ventas, potencial de mercado del cliente, utilización de recursos, etc.
SAS, R y Kinme las tres herramientas ofrecen una amplia gama de funciones, desde análisis avanzados, IOT, aprendizaje automático, metodologías de gestión de riesgos e inteligencia de seguridad.
Pero como de ellos uno es comercial y otros 2 son de código abierto, tienen algunas diferencias importantes entre ellos.
En lugar de repasar cada una de ellas una por una, he resumido cada una de las diferencias de software y algunos consejos útiles que hablan de ellas.
