a cikk célja a redundancia magyarázata a számítástechnika, a hálózatépítés és a tárhely szempontjából. Valós példákat adunk a redundáns technológiai megoldásokra, hogy bemutassuk, mi a redundancia és hogyan működik.
Atlantic.Net több tárhelykörnyezetet hozott létre, beleértve a tartós felhőplatformot, a nagy sebességű VPS-tárhelyet, a HIPAA-kompatibilis infrastruktúrát és a menedzselt privát felhőalapú tárhelyet. Minden rendszerünk redundanciával épül fel, mint a tervezési folyamat elsődleges mozgatórugója.
a mindennapi angol nyelvben a redundanciának negatív konnotációja lehet; valami redundánsra általában nincs szükség, vagy feleslegesnek tekintik. A felhőalapú hosting környezetben azonban a redundancia jelentheti a különbséget a zökkenőmentes rendszer rendelkezésre állása és a nem kívánt vagy váratlan leállás között.
- mi a redundáns rendszer?
- redundáns rendszerek típusai
- példák a redundáns Szoftverszolgáltatásokra
- Hyper-V replika
- Hyper-V klaszterezés
- HAProxy
- Heartbeat
- példák a redundáns Hardverszolgáltatásokra
- RAID
- hálózati redundancia
- First Hop redundancia protokollok (Fhrp)
- Virtual Router Redundancy Protocol (VRRP)
- Hot Standby Router Protocol (HSRP)
- Gateway Load Balancing Protocol (Glbp)
- adatközpont redundancia
- következtetés
mi a redundáns rendszer?
a redundáns rendszer feladatátvételi vagy terheléselosztási támogatást nyújt az élő rendszer váratlan meghibásodás esetén történő védelme érdekében. Áramellátás, mechanikai vagy szoftverhiba esetén a redundáns rendszernek lesz egy ismétlődő összetevője vagy platformja, amelyre vissza lehet térni. Általánosságban elmondható, hogy a rendszer bármely olyan összetevője, amelynek egyetlen meghibásodási pontja van, kockázatot jelent a termelési szolgáltatásokra nézve.
a teljesítmény-vagy mechanikai rendszerek egyszerűbb visszaesési stratégiákkal rendelkeznek, amelyek pusztán egy azonos típusú szolgáltatás jelenlétét igénylik; a szoftver-átkapcsolások általában extra konfigurációt igényelnek a gazdarendszeren, vagy egy mesteren vagy átjárón.
redundancia képességek ajánlott minden üzleti szempontból kritikus rendszer, de különösen a rendszerek, amelyek jelentős hatással állásidő alatt. Egyes vállalkozások az összes kritikus ügyféladatot adatbázisban tárolhatják; ezért üzletmenet-folytonosság céljából az adatbázis redundanciával történő védelme katasztrofális hiba esetén megvédi az adatok integritását.
redundáns rendszerek típusai
a redundáns rendszer legalább két, egymással összekapcsolt és ugyanarra a célra tervezett rendszerből áll. Számos különböző típusú redundáns rendszerkonfiguráció áll rendelkezésre, és a rendszer különböző implementációi egyedi megközelítéseket nyújtanak a rendszer folyamatos karbantartásához.
nem minden kiszolgálót kell redundanciával konfigurálni; inkább csak a legkritikusabbat kell figyelembe venni. Javasoljuk a részletes kockázatértékelést, hogy megértsük, milyen szerverek vannak hatályban, és a kiszolgálók maximális leállási idejét tudják kezelni. Ezzel az értékeléssel meghatározható az RTO (helyreállítási idő célkitűzés) és az RPO (helyreállítási pont célkitűzés) stratégia. Az RTO az elfogadható állásidő maximális mennyisége. Ez 5 másodperctől 24 óráig terjedhet. Az RPO az az időpont, amelytől kezdve szüksége van az adatokra; például vállalkozása legfeljebb 24 órás adatvesztéssel működhet.
íme néhány népszerű példa:
- Aktív-inaktív/meleg-hideg – amikor a rendszer egyik összetevője az aktív rendszer, a másik pedig inaktív vagy leáll. Az inaktív összetevő csak akkor aktiválódik, ha az éppen futó összetevő meghibásodik vagy karbantartáson megy keresztül
- Active-Active / Hot-Hot – amikor mindkét rendszer él és kapcsolatot létesít. Ezt leggyakrabban klaszterezésnek nevezik. Általában a két gép előtti eszköz határozza meg, hogyan kell felosztani a bejövő forgalmat
- aktív-készenléti/Meleg-Meleg – amikor mindkét rendszer be van kapcsolva, de csak az egyik csatlakozik. A második rendszer célja, hogy rendszeresen frissítéseket vagy biztonsági mentéseket kapjon az elsődleges rendszertől. Meghibásodás esetén a készenléti rendszer veszi az elsődleges szerepet, amíg a kezdeti rendszert vissza nem lehet állítani.
minden típusnak megvannak a maga előnyei és hátrányai.
- az aktív-inaktív / meleg-hideg rendszerek egyszerű redundáns platformot biztosíthatnak, de bármilyen feladatátvétel azt eredményezi, hogy a felhasználók a rendszer régebbi verzióját látják.
- Active-Active / Hot-Hot mindkét rendszer folyamatos frissítését igényli, akár manuálisan, akár külön szolgáltatáson keresztül, annak biztosítása érdekében, hogy minden felhasználó használhassa bármelyik rendszert. Ez a megközelítés nagymértékben csökkentheti az ügyfeleknek nyújtott szolgáltatás aktív terhelését.
- Az Active-Standby / Hot-Warm biztosítja a hot-cold feladatátvételi képességeit az aktív rendszer naprakészebb másolatával a feladatátvételen, de nem nyújt terheléscsökkentést.
a több csomópontos redundancia egyéb formái is rendelkezésre állnak, amelyek nagyobb redundanciát és robusztus terheléselosztási megoldásokat tesznek lehetővé. Ezen a ponton lesz egy magas rendelkezésre állású fürt, más néven HA fürt.
Ez a korábban említett redundancia megoldások bármilyen kombinációját felhasználhatja, maximális rugalmassággal a megközelítésben vagy a szükséges redundancia mennyiségében. HA klaszterek is létre több fizikai helyeken, hogy a rendelkezésre állás akár az internet gerincét szinten.
példák a redundáns Szoftverszolgáltatásokra
az alacsony erőforrás-rendelkezésre állás mellett nagyon kevés ok van arra, hogy ne legyen védett replikáció vagy redundáns szolgáltatások virtuális környezetben; így sok ilyen szolgáltatás alapértelmezés szerint elérhető a legtöbb virtualizációs rendszerben. Minden felhőszolgáltatásunk rendelkezik replikációval, amely lehetővé teszi számunkra, hogy bármely szervert replikáljunk egyik csomópontról a másikra, függetlenül attól, hogy ugyanabban az adatközpontban vagy különálló adatközpont-régiókban vannak-e.
Hyper-V replika
a Hyper-V replika a forró-meleg redundancia egyik formája. Az elsődleges virtuális gép egy fizikai gépen jön létre, és elfogadja a bejövő kapcsolatokat. A replikáció engedélyezésekor az új gép virtuális merevlemezei külön fizikai Hyper-V gazdagépre kerülnek. Ez a gazdagép ezután konfigurál egy virtuális Gépet, amely a felhasználó által megadott ütemezés szerint replikálódik annak biztosítása érdekében, hogy az aktív kiszolgáló legfrissebb képe készüljön. További ellenőrző pontok is megtarthatók. A Hyper-V privát tárhelyet a felügyelt szolgáltatásokkal a következők biztosítják Atlantic.Net ezzel a funkcióval sütve; további információkért vegye fel a kapcsolatot csapatunkkal.
Hyper-V klaszterezés
a Hyper-V más Hyper-V gazdagépekkel való kapcsolaton keresztül is képes csoportosulni. Bármely Hyper-V gazdagép virtuális gépei csoportosíthatók azon az egyedülálló gazdagépen, hogy helyi szinten redundanciát biztosítsanak a virtuális hálózaton keresztül.
a Microsoft Network Load Balancing (NLB) segítségével egyetlen erőforrás hozható létre, amely több gazdagépből áll, amelyek ugyanazokat az információkat osztják meg, hogy egyszerű hozzáférési pontot biztosítsanak a fájlmegosztáshoz. Mivel ezt csak a rendelkezésre álló erőforrások mennyisége korlátozza, elméletileg több gazdagépet is beállíthat több virtuális géppel a maximális redundancia érdekében, ami lehetővé tenné az egyes virtuális gépek karbantartását a szolgáltatás vagy az erőforrás rendelkezésre állásának feláldozása nélkül. A Hyper-V privát tárhelyet a felügyelt szolgáltatásokkal a következők biztosítják Atlantic.Net ezzel a funkcióval sütve; további információkért vegye fel a kapcsolatot csapatunkkal.
HAProxy
a Hyper-V-n kívül egy átjáró eszköz, például egy tűzfal használható feladatátvételhez vagy terheléselosztási szolgáltatásokhoz. Például az Atlanti-óceán.Net nyújthat pfSense magas rendelkezésre állású Proxy, más néven HAProxy.
a HAProxy terheléselosztóként, proxyként vagy egyszerű hot-warm magas rendelkezésre állású megoldásként működik TCP és HTTP alapú alkalmazásokhoz. A HAProxy egy nagyon népszerű, Linux alapú nyílt forráskódú megoldás, amelyet a világ leglátogatottabb webhelyei használnak.
Heartbeat
A Heartbeat a Linux legtöbb disztribúcióján elérhető szolgáltatás, amelyet annak meghatározására használnak, hogy a klaszter csomópontjai még mindig fent vannak-e vagy reszponzívak-e. Ez nagyon egyszerű, hogy hozzanak létre, és biztosítja failover képességek minden rendszer dolgozik TCP-n keresztül.
a Heartbeat fejlesztői más fürt erőforrás-kezelőket is javasolnak, amelyek elindítják vagy leállítják a szolgáltatásokat annak alapján, hogy egy adott gazdagép nem működik-e. A Heartbeat ezt tartalmazza, de más vezetők is rendelkezésre állnak. A Heartbeat egyszerűsége miatt nagymértékben testreszabható. Cloud Hosting platformok által biztosított Atlantic.Net már van ez a funkció sütött, és mi segítünk a végrehajtási Heartbeat saját privát Linux disztribúció, ha szükséges.
példák a redundáns Hardverszolgáltatásokra
a redundáns hardver legjobb része az egyszerűsége. Míg a szoftverszolgáltatások túlzott konfigurációt igényelhetnek, és valószínűleg meglehetősen érzékenyek, a hardver általában nagyon egyszerűen beállítható és hihetetlenül tartós. Az első példa, amelyet megvizsgálunk, a széles körben használt RAID technológia.
RAID
a RAID a független lemezek redundáns tömbjét jelenti (vagy olcsó lemezek redundáns tömbjét, attól függően, hogy mennyi ideig használta), és több szintje van az adatvédelemhez vagy a megnövelt lemez I/O-hoz.
a RAID szoftver vagy hardver vezérlőn keresztül is beállítható. A vezérlő rendelkezik a raid lemezek kezeléséhez szükséges szoftverrel és konfigurációval. A konfiguráció exportálható különböző rendszerekbe, kevés vagy semmilyen további konfigurációval.
RAID lehet beállítani néhány különböző módon, hogy egy jó egyensúlyt a két tulajdonság:
- RAID 0 – ez lényegében nincs redundancia. A rendszer egyetlen lemeze sem osztja meg az adatokat tükrözés útján, de az összes adat csíkos az egyes lemezeken, ami növeli az olvasási/írási sebességet. Minden meghajtó továbbra is a lehető legteljesebb mértékben használhatja a számára biztosított tárhelyet, vagyis minél több meghajtót ad hozzá a RAID 0-hoz, annál több hely lesz.
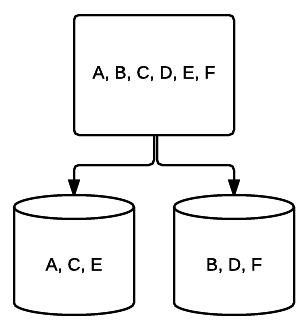
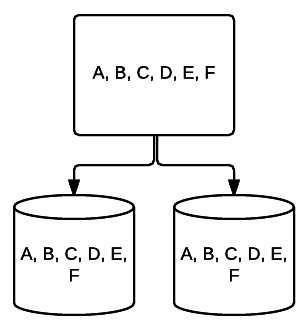
- RAID 1 – a tükrözés alapvető formája, amely kiváló redundanciát biztosít a hely költségén. Két meghajtású rendszerben az egyik meghajtón lévő adatok teljes másolatát a másikra írják. Ez a redundancia minden egyes meghajtó hozzáadásával fokozódik. Mivel minden adatot tükrözni kell az összes meghajtón, a rendszer teljes területe csak a rendszer legkisebb meghajtójának helyére korlátozódik.
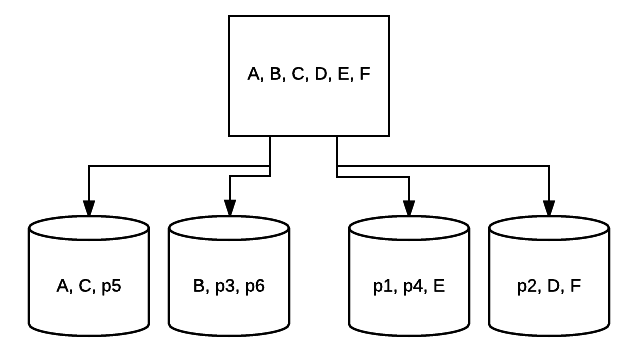
- RAID 5 – A RAID ezen formáját általában az olvasási sebesség és a megbízhatóság növelésére használják. Ebben az esetben a rendszer minden meghajtója körül csíkokat helyeznek el, a minimum 3 meghajtó. Ugyanakkor az egyes meghajtókról egy extra hibajavító adatblokk kerül elhelyezésre a paritásnak nevezett technikában. Ez ellenőrzi, hogy az adatok megváltoznak-e az egyik meghajtóról a másikra történő átvitel során. Ez a redundancia minimális formáját is biztosítja, mivel ezen meghajtók közül 1 meghibásodhat, és a rendszer továbbra is futtatható. Minél több meghajtót adnak hozzá az ilyen típusú RAID-beállításokhoz,annál nagyobb az olvasási sebesség. Minimális redundanciával és csíkozással az összes meghajtón, a teljes Hely ebben a beállításban megegyezik a logikai RAID kötet méretének a használt meghajtók számának szorzatával, mínusz eggyel. Például, ha 5 500 GB-os meghajtója van egy RAID 5-ben, akkor 2000 GB használható, vagy 2 TB (500 *(5-1)=2000).
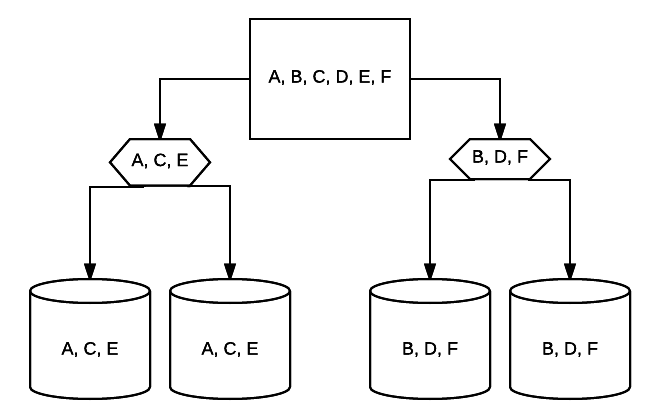
- RAID 10 – Ez a RAID 1 és RAID 0 kombinációja. Ebben az esetben az összes adat csíkos az egyes eszközökön, az adatblokkok pedig a csíkos rendszer teljes egészében tükröződnek. Például egy 4 meghajtó RAID 10 rendszerben 2 500 GB-os meghajtók rendelkezhetnek ugyanazokkal az adatokkal, de nem minden adat szükséges a rendszer megfelelő működéséhez. 2 más meghajtók adataira lenne szükség. Gondolj minden RAID 1 rendszerre egyetlen meghajtóként, és mindegyik rendszer egy RAID 0 tömbbe kerül. Ebben a beállításban a teljesítmény drasztikusan növelhető, mint a RAID 0-ban, némi redundancia még mindig érvényben van a tükrözéssel. A rendszer meghajtóinak legfeljebb fele meghibásodhat, mielőtt a rendszer összeomlik, de mint minden redundáns tömb esetében, a legjobb, ha a meghajtókat a lehető leghamarabb kicseréli. Atlantic.Net RAID 10-et használ minden SSD Cloud VPS tárolóhoz.
a további védelem érdekében a RAID vezérlőket akkumulátoros tartalék egységek védik, amelyek áramkimaradás esetén a konfiguráció memóriába mentéséhez használt ROM chipeket táplálják. A BBU energiát biztosít egy raid tömbnek, amely egy kikapcsolt rendszer része egy kis ideig, lehetővé téve a RAID vezérlő gyorsítótárának tartalmának érintetlenségét. Ez életmentő lehet, ha az információkat folyamatosan betáplálják a RAID tömbbe, és bármilyen állásidő adatsérülést okozhat.
tehát, a fizikai rendszer és a szolgáltatások belül lehet építeni redundánsan meglehetősen megfelelően. De mi a helyzet a kapcsolat bármely részét a rendszer? Mint a, a közvetlen internetkapcsolat a rendszer egészére?
hálózati redundancia
First Hop redundancia protokollok (Fhrp)
a dinamikus átjáró – felderítési protokollokkal ellentétben a statikus átjárók lehetővé teszik az egyszerű ugrást az ügyfél és a megfelelő átjáró között, de ez egyetlen hibapontot hoz létre-nevezetesen magát az átjárót.
az átjáró meghibásodásának megelőzése vagy csökkentése érdekében Fhrp-ket hoztak létre. Redundáns átjárókat biztosítanak tartalékként, vagy terheléselosztást kínálnak a nagy forgalmú rendszerek számára, redundanciával együtt. Ezek a protokollok közé tartozik a VRRP, a HSRP és a GLBP.
Virtual Router Redundancy Protocol (VRRP)
a VRRP az útválasztók redundanciájának egy olyan formája, amelyhez legalább két fizikailag különálló útválasztó szükséges, amelyek Ethernet vagy optikai szálas kapcsolatokon keresztül csatlakoznak. Ebben a helyzetben létrejön egy statikus útvonalakat tartalmazó ‘virtuális útválasztó’, amelyet minden rendszer megoszt.
az egyik rendszer a ‘master’, a másik a ‘backup’. Ha a mester meghibásodik, a biztonsági mentés átveszi a következő mestert. Ezt több biztonsági mentéssel lehet beállítani az extra redundancia érdekében. A koncepció nagyon hasonlít a Heartbeat-hez, mivel a biztonsági rendszerek ellenőrzik, hogy rendelkezésre áll-e a mester. Ha nem kap választ, egy előre meghatározott idő elteltével a biztonsági mentés átveszi a virtuális kapcsoló irányítását, és elfogadja a főkapcsolóhoz konfigurált alapértelmezett IP-címhez érkező összes kérés csatlakozását.
Hot Standby Router Protocol (HSRP)
a HSRP olyan, mint a VRRP; ebben az esetben azonban a konfigurált virtuális kapcsoló nem ‘kapcsoló’, hanem több útválasztó logikai csoportja. A csoport IP-je olyan IP, amely nincs hozzárendelve egy fizikai gazdagéphez. Ehelyett a csoport IP-t kap, és az egyik útválasztó az ‘aktív’ útválasztó lesz.
a készenléti útválasztó készen áll bármilyen kapcsolat felvételére, ha az aktív útválasztó leáll. Minden router mellett az aktív és készenléti mind hallgat, hogy meghatározza a helyét a sorban. A HSRP egy Cisco szabadalmaztatott protokoll, és nagyon kevés, kisebb különbséggel rendelkezik a VRRP-hez képest, mint például az alapértelmezett időzítők, amelyek meghatározzák a feladatátvétel idejét. HSRP már körülbelül egy kicsit hosszabb, és több jól ismert, mint VRRP.
Gateway Load Balancing Protocol (Glbp)
a GLBP fő előnye a HSRP-vel és a VRRP-vel szemben az, hogy képes az egyensúlyt betölteni a redundancia biztosítása mellett egy átjáró számára, kevés vagy semmilyen extra konfigurációval. A HSRP-hez és a VRRP-hez hasonlóan a GLBP is létrehoz egy csoportot a fizikai útválasztók között, és meghatározza az aktív virtuális átjárót vagy az AVG-t.
egy virtuális IP, amelyet a csoport egyik útválasztója sem használ, az AVG-hez van rendelve. Az AVG ezután elosztja a virtuális MAC-címeket a csoport többi útválasztója között. Minden mentési útválasztót aktív virtuális Továbbítónak vagy AVF-nek tekintünk.
az AVG-nek küldött ARP-kérések egy másik virtuális MAC-címet adnak a kérést küldő ügyfélnek. Ezen a ponton az ügyféltől a csoport virtuális IP-jéig terjedő forgalom továbbítódik az útválasztóhoz, amelynek virtuális MAC-címét megkapták, lehetővé téve az egyes útválasztók használatát, ahelyett, hogy tétlenül ülnének.
az AVG meghibásodása esetén prioritásalapú választásokra kerül sor, csakúgy, mint a HSRP-ben és a VRRP-ben, és a következő biztonsági mentés veszi át a helyét, a virtuális MAC-címeket a szokásos módon terjesztve. A többi útválasztó továbbra is megtartja az eredeti AVG által biztosított virtuális MAC-címet, és a dolgok a szokásos módon folytatódnak. Az egyik aVF meghibásodása esetén az AVG megakadályozza a forgalom átirányítását a virtuális MAC-címére.
csakúgy, mint a HSRP, a GLBP az Fhrp Cisco szabadalmaztatott formája.
adatközpont redundancia
a személyes kiszolgálók vagy útválasztók redundanciája mellett az adatközpontokat úgy tervezték, hogy ellenálljanak a rendszerhibáknak. Az adatközpontok az Uptime Institute által meghatározott szintek alá tartoznak, hogy hibatűrést biztosítsanak bármilyen mechanikai vagy szolgáltatási hiba esetén, lehetővé téve a lehető legtöbb rendelkezésre állást.
négy szint létezik, amelyek mindegyike egymásra épül, hogy magas szintű rendelkezésre állást biztosítson az adatközpontban lévő összes ügyfél számára:
- I. szint-Alapkapacitás: Ehhez egy adatközponti műveletekhez szükséges hely egy informatikai csoport számára, Szünetmentes tápegység (UPS), amely figyeli és szűri az energiafelhasználást, valamint dedikált hűtőberendezés, amely folyamatosan működik 24/7. Ez magában foglalja az áramfejlesztőt is elektromos áramkimaradás esetén.
- Tier II-redundáns Kapacitáskomponensek: minden, amit a Tier I nyújt, plusz redundáns energia és hűtés a létesítmény számára. Ez magában foglalhatja az extra UPS egységeket vagy extra generátorokat.
- Tier III-egyidejűleg karbantartható: Minden, amit a Tier II nyújt, plusz extra felszerelés a helyén, hogy megakadályozzák a berendezések cseréjének vagy karbantartásának leállítását. Ezen a szinten a redundáns energia és hűtés közvetlenül az összes műszaki berendezésre vonatkozik, és maga a berendezés redundanciára vagy zökkenőmentes feladatátvételre van konfigurálva.
- Tier IV-hibatűrés: minden, amit a Tier III nyújt, plusz folyamatos szolgáltatás a Szolgáltató szintjén. Míg az adatközpontban lehet villamos energia vagy víz, amelyet egy városi vagy állami szolgáltató biztosít, az adatközpont által igénybe vett egyes szolgáltatások másodlagos vonalára van szükség. Ez magában foglalja az ISP-t is. Az ügyfélberendezéshez vezető bármely szakasz meghibásodása esetén van egy biztonsági mentési terv, amely készen áll a zökkenőmentes átmenetre.
következtetés
a redundancia szükségszerűség miatt mindennapi kifejezéssé vált az informatikai iparban. A szolgáltatások magas rendelkezésre állása egyszerű, megbízható élményt nyújt ügyfeleink számára.
akár szolgáltatási, akár adatközponti szinten, a rendszer redundanciájának biztosítása fontos és nehezen kezelhető probléma. Remélhetőleg ez a tanulmány rávilágított a rendelkezésre álló lehetőségekre, és segít a magas rendelkezésre állással kapcsolatos döntések meghozatalában.
készen áll arra, hogy kihasználja Atlantic.Net redundáns rendszerek? Vegye fel velünk a kapcsolatot még ma, hogy többet megtudjon a dedikált szerver-tárhelyről Atlantic.Net.
===források===
redundáns rendszer alapfogalmak: http://www.ni.com/white-paper/6874/en/
hideg/meleg/forró szerver: http://searchwindowsserver.techtarget.com/definition/cold-warm-hot-server
magas rendelkezésre állású klaszterezés: https://www.mulesoft.com/resources/esb/high-availability-cluster
Hyper-V replika: https://technet.microsoft.com/en-us/library/jj134172(V=ws.11).aspx
Hyper-V and High Availability: https://technet.microsoft.com/en-us/library/hh127064.aspx
HAProxy Description: http://www.haproxy.org/#desc
HAProxy – They use it!: http://www.haproxy.org/they-use-it.html
Heartbeat: http://www.linux-ha.org/wiki/Main_Page
RAID Definition: http://searchstorage.techtarget.com/definition/RAID
Striping: http://searchstorage.techtarget.com/definition/disk-striping
RAID Battery Backup Units: https://www.thomas-krenn.com/en/wiki/Battery_Backup_Unit_(BBU/BBM)_Maintenance_for_RAID_Controllers
High-Availability – VRRP, HSRP, GLBP: http://www.freeccnastudyguide.com/study-guides/ccna/ch14/vrrp-hsrp-glbp/
Understanding VRRP: http://www.juniper.net/techpubs/en_US/junos/topics/concept/vrrp-overview-ha.html
Configuring VRRP: http://www.cisco.com/c/en/us/td/docs/ios-xml/ios/ipapp_fhrp/configuration/15-mt/fhp-15-mt-book/fhp-vrrp.html
Configuring GLBP: http://www.cisco.com/c/en/us/td/docs/ios-xml/ios/ipapp_fhrp/configuration/xe-3s/fhp-xe-3s-book/fhp-glbp.html
Explaining the Uptime Institute’s Tier Classification System: https://journal.uptimeinstitute.com/explaining-uptime-institutes-tier-classification-system/