By: Arshad Ali | Frissítve: 2020-07-29 | Comments (6) | Related: More > csatlakozzon a táblákhoz
probléma
a tippben SQL Server Csatlakozáspéldák, Jeremy Kadlec beszélt a különböző logikai csatlakozási operátorokról, de hogyanaz SQL Server fizikailag megvalósítja őket? Melyek a különböző fizikai csatlakozókoperátorok? Hogyan különböznek egymástól, és milyen forgatókönyv szerint részesítik előnyben az egyiketa másikkal szemben? Ebben a tippben kitérünk ezekre a kérdésekre és még sok másra.
megoldás
logikai operátorokat használunk, amikor lekérdezéseket írunk egy relációs lekérdezés definiálásáhozfogalmi szinten (mit kell tenni). Az SQL végrehajtja ezeket a logikai operátorokathárom különböző fizikai operátorral a logikai operátorok által meghatározott művelet végrehajtásához (hogyan kell ezt megtenni). Bár több tucat fizikai vanoperátorok, ebben a tippben konkrét fizikai csatlakozási operátorokat fogok lefedni. Bár különböző típusú logikai illesztések vannak a fogalmi / lekérdezési szinten, de az SQL szerver mindegyiket három különböző fizikai illesztési operátorral hajtja végre, amint azt az alábbiakban tárgyaljuk.
fogjuk fedezni:
- Nested Loops Join
- Merge Join
- Hash Join
megnézzük a végrehajtási terveket, hogy lássuk ezeket az operátorokat, és elmagyarázom, miért fordul elő mindegyik.
ezekre a példákra a theAdventureWorks adatbázist használom.
az SQL Server Nested Loops Join magyarázata
mielőtt belemerülne a részletekbe, hadd mondjam el először, hogy mi a beágyazott Loops joinis, ha új vagy a programozási világban.
a beágyazott hurkok összekapcsolása egy logikai struktúra, amelyben az egyik hurok (iteráció) egy másikban marad, vagyis a külső hurok minden iterációjára a belső hurok összes teiterációját végrehajtják/feldolgozzák.
a beágyazott hurkok összekapcsolása ugyanúgy működik. Az egyik összekötő asztal van kijelölvemint a külső asztal, a másik pedig a belső asztal. Az outertable minden sorához a belső táblázat összes sorát egyenként illeszti, ha a sor matchesit szerepel az eredménykészletben, különben figyelmen kívül hagyja. Ezután a következő sora külső asztal fel van véve, ugyanaz a folyamat megismétlődik, és így tovább.
az SQL Server optimalizáló lehet választani egy beágyazott hurkok csatlakozik, ha az egyik joiningtables kicsi (tekinthető a külső tábla), és egy másik nagy (considered as a belső tábla, amely indexelt az oszlop, amely a join) és henceit igényel minimális I/O és a legkevesebb összehasonlítást.
az optimalizáló három változatot vesz figyelembe a beágyazott hurkok összekapcsolásához:
- naiv beágyazott hurkok csatlakoznak, ebben az esetben a keresés beolvassa az egész táblát vagy indexet
- index beágyazott hurkok csatlakoznak, amikor a keresés egy létező indexet használhat a keresések végrehajtásához
- ideiglenes index beágyazott hurkok csatlakoznak, ha az optimalizáló ideiglenes indexet hoz létre a lekérdezési terv részeként, és megsemmisíti azt a lekérdezés végrehajtása után
az index beágyazott hurkok összekapcsolása jobban teljesít, mint egy egyesítés vagy hash csatlakozás, ha kis sorokból áll. Mivel, ha egy nagy sor sor van szó theNested hurkok csatlakozni lehet, hogy nem az optimális választás. A beágyazott hurkok szinte minden join típust támogatnak, kivéve a jobb és a teljes külső illesztéseket, a jobb félcsatlakozást és a jobb anti-félcsatlakozásokat.
- az 1.szkriptben csatlakozom a SalesOrderHeader táblához a SalesOrderDetailtable segítségével, és megadom a feltételeket az ügyfél eredményének szűréséhez a következővel: ügyfélid = 670.
- ez a szűrt feltétel 12 rekordot ad vissza a SalesOrderHeader tableand-ből, ezért mivel ez a kisebb, ezt a táblázatot az optimalizáló theouter table-nek (a grafikus lekérdezés végrehajtási tervének első része)tekintette.
- a külső táblázat ezen 12 sorának minden sorában a belső táblázat salesorderdetail sorai egyeznek (vagy a belső táblázatot minden sorhoz 12 alkalommal szkennelik be a külső táblázat indexkeresésével vagy korreláltparaméterével), és 312 egyező Sort adnak vissza, amint a második képen láthatja.
- az alábbi második lekérdezésben a SET STATISTICS PROFILE on-t használom a lekérdezés végrehajtásának profilinformációinak megjelenítésére a lekérdezés eredménykészletével együtt.
Script #1 – beágyazott hurkok csatlakoznak példa
SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader H INNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID = 670
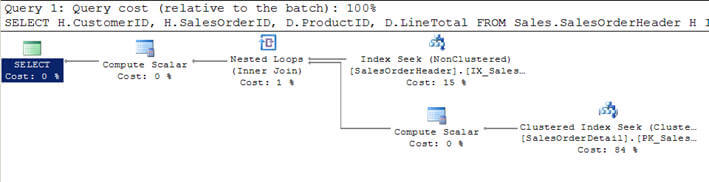
SET STATISTICS PROFILE ONSELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader HINNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderIDWHERE H.CustomerID = 670SET STATISTICS PROFILE OFF

Ha az érintett rekordok száma nagy, az SQL Server dönthet úgy, hogy párhuzamosítja a beágyazott hurkot azáltal, hogy a külső táblázatsorokat véletlenszerűen elosztja a rendelkezésre álló hurok szálak között dinamikusan. Ez nem vonatkozik ugyanaz a belső tablerows bár. Ha többet szeretne megtudni a párhuzamos szkennelésrőlkattintson ide.
az SQL Server Merge Join magyarázata
az első dolog, amit tudni kell a Merge join, hogy requiresboth bemenetek kell rendezni a join keys/merge oszlopok (vagy mindkét bemeneti táblák clusteredindexes az oszlop, amely csatlakozik a táblázatok), és azt is megköveteli, legalább egy equijoin(egyenlő) kifejezés/állítmány.
mivel a sorok előre vannak rendezve, az Egyesítési csatlakozás azonnal megkezdi a matchingprocess-t. Az egyik bemenetből kiolvassa a sort, majd összehasonlítja egy másik bemenet sorával.Ha a sorok egyeznek, akkor az egyező Sort figyelembe veszi az eredményhalmaz (akkor a bemeneti táblázat következő sorát olvassa, ugyanazt az összehasonlítást/egyezést végzi stb.), vagy a két sor közül a kisebbet figyelmen kívül hagyja, és a folyamat így folytatódik, amíg az összes sor feldolgozásra nem kerül..
az Egyesítési csatlakozás jobban teljesít, ha nagy bemeneti táblákat csatlakoztat (előre indexelt / rendezett), mivel a költség a sorok összegzése mindkét bemeneti táblában, szemben a NestedLoops-szal, ahol mindkét bemeneti tábla sorainak szorzata. Néha az Optimizer úgy dönt, hogy egy egyesítési csatlakozást használ, amikor a bemeneti táblák nincsenek rendezve, ezért explicit rendezési fizikai operátort használ, de lehet, hogy lassabb, mint egy index(előre rendezett bemeneti tábla) használata.
- a 2. szkriptben hasonló lekérdezést használok, mint fent, de ezúttal hozzáadtam egy WHERE záradékot, hogy az összes ügyfél nagyobb legyen, mint 100.
- ebben az esetben az optimalizáló úgy dönt, hogy egyesítési csatlakozást használ, mivel mindkét bemenet nagy a sorok szempontjából, és előre indexelve/rendezve is vannak.
- azt is észreveheti, hogy mindkét bemenetet csak egyszer szkennelik, szemben a fenti beágyazott hurkokban látott 12 szkenneléssel.
Script #2 – Merge Join példa
SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader H INNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID > 100
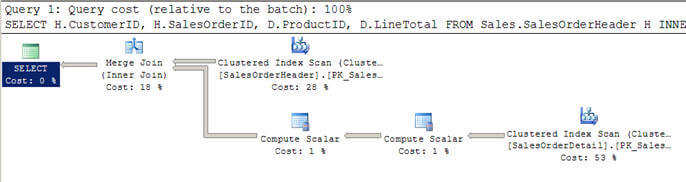
SET STATISTICS PROFILE ONSELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader HINNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderIDWHERE H.CustomerID > 100SET STATISTICS PROFILE OFF

a Merge join gyakran hatékonyabb és gyorsabb join operátor, ha a sorteddata egy meglévő B-fa indexből nyerhető, és szinte az összes join műveletet végrehajtja, amíg legalább egy egyenlőség join predikátum van benne. Támogatja a többszörös egyenlőségi összekapcsolási predikátumokat is, amennyiben a bemeneti táblák az összes érintett összekötő kulcson ugyanabban a sorrendben vannak.
a számítási skalár operátor jelenléte jelzi a kifejezés értékelésétkiszámított skalárérték előállításához. A fenti lekérdezésben kiválasztom Linetotalamely származtatott oszlop, ezért a végrehajtási tervben használták.
az SQL Server Hash Join magyarázata
A Hash join általában akkor használatos, ha a bemeneti táblák elég nagyok, és nincs rajtuk megfelelőindex. A Hash Csatlakozás két fázisban történik; a Build fázis és a Probe fázis, és így a hash join két bemenettel rendelkezik: build input és probeinput. A bemenetek közül a kisebbik a build bemenet (a később tárgyalt hash tábla tárolásának memóriaigényének minimalizálása érdekében), a másik pedig nyilvánvalóan a probe bemenet.
a build fázis során a build táblázat összes sorának összekapcsoló kulcsai beolvasásra kerülnek.A kivonatok generálódnak és egy memóriában lévő hash táblába kerülnek. Az Egyesítési csatlakozással ellentétben ez blokkolja (a sorok nem kerülnek vissza) addig a pontig.
a szondafázis során a szondatábla minden sorának összekötő gombjait beolvassa.Ismét hash generálódik (ugyanazt a hash függvényt használja, mint fent), és összehasonlítja a megfelelő hash táblával.
a Hash függvény jelentős mennyiségű CPU ciklust igényel a hashesand memória erőforrások előállításához a hash tábla tárolásához. Ha van memória nyomás, néhány a partíciók a hash tábla cserélik tempdb, és ha van isa szükség (akár szonda vagy frissíteni a tartalmát), hogy hozza vissza a cache.A nagy teljesítmény elérése érdekében a lekérdezésoptimalizáló párhuzamosíthatja a Hash csatlakozást a skálához, mint bármely más csatlakozás, további részletekért kattintson ide.
alapvetően három különböző típusú hash csatlakozás létezik:
- in-memory Hash Join ebben az esetben elegendő memória áll rendelkezésre a hash tábla tárolásához
- Grace Hash Join ebben az esetben a hash tábla nem fér el a memóriában, és néhány partíció kiömlött a tempdb-be
- rekurzív Hash Join ebben az esetben a hash tábla olyan nagy, hogy az optimalizálónak több szintű egyesítési illesztést kell használnia.
további részletekért ezekről a különböző típusokrólkattintson ide.
- a 3.szkriptben két új nagy táblát hozok létre (a meglévő AdventureWorkstables-ből) indexek nélkül.
- láthatjuk az optimalizáló úgy döntött, hogy egy Hash csatlakozni ebben az esetben.
- ismét ellentétben a beágyazott hurkok csatlakozik, nem vizsgálja a belső tábla többszörösen.
Script #3 – Hash Join Example
--Create tables without indexes from existing tables of AdventureWorks database SELECT * INTO Sales.SalesOrderHeader1 FROM Sales.SalesOrderHeader SELECT * INTO Sales.SalesOrderDetail1 FROM Sales.SalesOrderDetail GO SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader1 H INNER JOIN Sales.SalesOrderDetail1 D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID = 670 GO
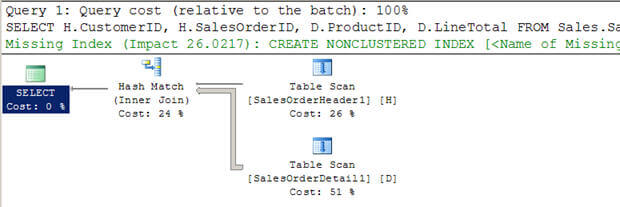
SET STATISTICS PROFILE ON SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader1 H INNER JOIN Sales.SalesOrderDetail1 D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID = 670 SET STATISTICS PROFILE OFF

--Drop the tables created for demonstration DROP TABLE Sales.SalesOrderHeader1 DROP TABLE Sales.SalesOrderDetail1
megjegyzés: az SQL Server nagyon jó munkát végez annak eldöntésében, hogy melyik joinoperátort használja az egyes feltételekhez. Ezeknek a Feltételeknek a megértése segít megértenimit lehet tenni a teljesítmény hangolásában. Nem ajánlott a csatlakozási tippek használata (usingOPTION záradék) arra kényszeríteni az SQL Server-t, hogy egy adott csatlakozási operátort használjon (hacsak nincs más kiút), hanem más eszközöket is használhat, például statisztikák frissítését, indexek létrehozását vagy a lekérdezés újraírását.
következő lépések
- ReviewSQL ServerJoin példák tipp.
- ReviewLogical and Physical Operators Reference cikk a technet-ről.
Utolsó frissítés: 2020-07-29


 Arshad Ali is a SQL and BI Developer focusing on Data Warehousing projects for Microsoft.
Arshad Ali is a SQL and BI Developer focusing on Data Warehousing projects for Microsoft.View all my tips
- More Database Developer Tips…