Les acides aminés, les nucléotides ou tout autre caractère évolutif sont remplacés par d’autres à un certain rythme. Par exemple, imaginez une séquence évolutive avec trois états possibles, A, B et C. Si le modèle de substitution est réversible dans le temps, il y aura trois taux de transition, A <>B, B <>C et un <>C.
Supposons que les taux soient respectivement de 1, 1 et 0 en unités de substitution pour 100charactères par unité de temps. Après une unité de temps, dans une longue séquence de 300 caractères composée à l’origine également de As, Bs et Cs, nous nous attendons à ce qu’il y ait une substitution A à B et une substitution B à C. Si nous comparons deux séquences homologues chez des organismes vivants, car une unité de temps a dépassé pour les deux séquences, nous nous attendrions à deux Sous-institutions A à B et deux sous-institutions B à Cs entre les séquences actuelles.
Quelle que soit la durée pendant laquelle nous exécutons ce processus, il n’y aura jamais de remplacement direct de A par C. Il n’y aura jamais non plus de substitution de A à C sous le modèle aso -appelé sites infinis, où pas plus d’une substitution ne peut se produire sur un seul site.
Cependant, comme les substitutions A à B et B à C sont courantes, sous un modèle de site fini, B sera finalement remplacé par C sur un site où A était précédemment remplacé par B. Ce remplacement indirect de A par C (ou de manière équivalente dans un modèle réversible dans le temps, C par A) devient plus probable plus la période de séparation des séquences homologues est longue.
J’ai simulé l’évolution de la séquence sur la base du scénario ci-dessus, en exécutant la simulation pendant 10 unités de temps. À partir de cette substitution, j’ai observé le nombre suivant pour chaque modèle de site:
| A | B | C | |
|---|---|---|---|
| A | 91 | 9 | 0 |
| B | 5 | 86 | 9 |
| C | 0 | 9 | 91 |
Au cours de cette durée relativement courte, il ne semble pas qu’une <>Csubstitutions se soient produites. Cependant, lorsque je redirige la simulation pendant 100 unités de temps:
| A | B | C | |
|---|---|---|---|
| A | 55 | 35 | 10 |
| B | 29 | 36 | 35 |
| C | 20 | 36 | 44 |
Comme vous pouvez le voir, de nombreux caractères « A » ont été remplacés par « C » et vice-versa. Plus généralement, dans un modèle de sites finis, plusieurs substitutionsparce que la distribution des nombres de motifs de sites devient beaucoup plus plate au-delà de l’augmentation simple de la proportion de nombres hors diagonale par rapport aux nombres diagonaux.Les matrices de score PAM et BLOSUM tiennent compte de plusieurs substitutions de manière radicalement différente.
Les matrices PAM pour les acides aminés, ainsi que les abréviations à une lettre utilisées pour les acides aminés génétiquement codés, ont été développées par MargaretDayhoff. Ils ont été publiés à l’origine en 1978, et basés sur les séquences de protéines que Dayhoff compilait depuis les années 1960, publiées sous le titre Thelas of Protein Sequence and Structure.
Le nom PAM vient de « mutation ponctuelle acceptée », et fait référence à la place d’un seul acide aminé dans une protéine avec un acide aminé différent.Ces mutations ont été identifiées en comparant des séquences très similaires avec au moins 85% d’identité, et on suppose que toutes les substitutions observées étaient le résultat d’une seule mutation entre la séquence ancestrale et l’une des séquences de jour présentes.
PAM définit également une unité de temps, où 1 PAM est le temps pendant lequel 1/100 acides aminés sont censés subir une mutation. La matrice de probabilité PAM1 montre la probabilité que l’acide aminé de la colonne j soit remplacé par l’acide aminé de la ligne i. Elle a été calculée à partir des nombres PAM de Dayhoff et rééchelonnée à 1 unité de temps PAM. Comme vous pouvez le voir, les probabilités hors diagonale dans la matrice PAM1 sont toutes très petites (tous les éléments ont été mis à l’échelle de 10 000 pour la flexibilité):
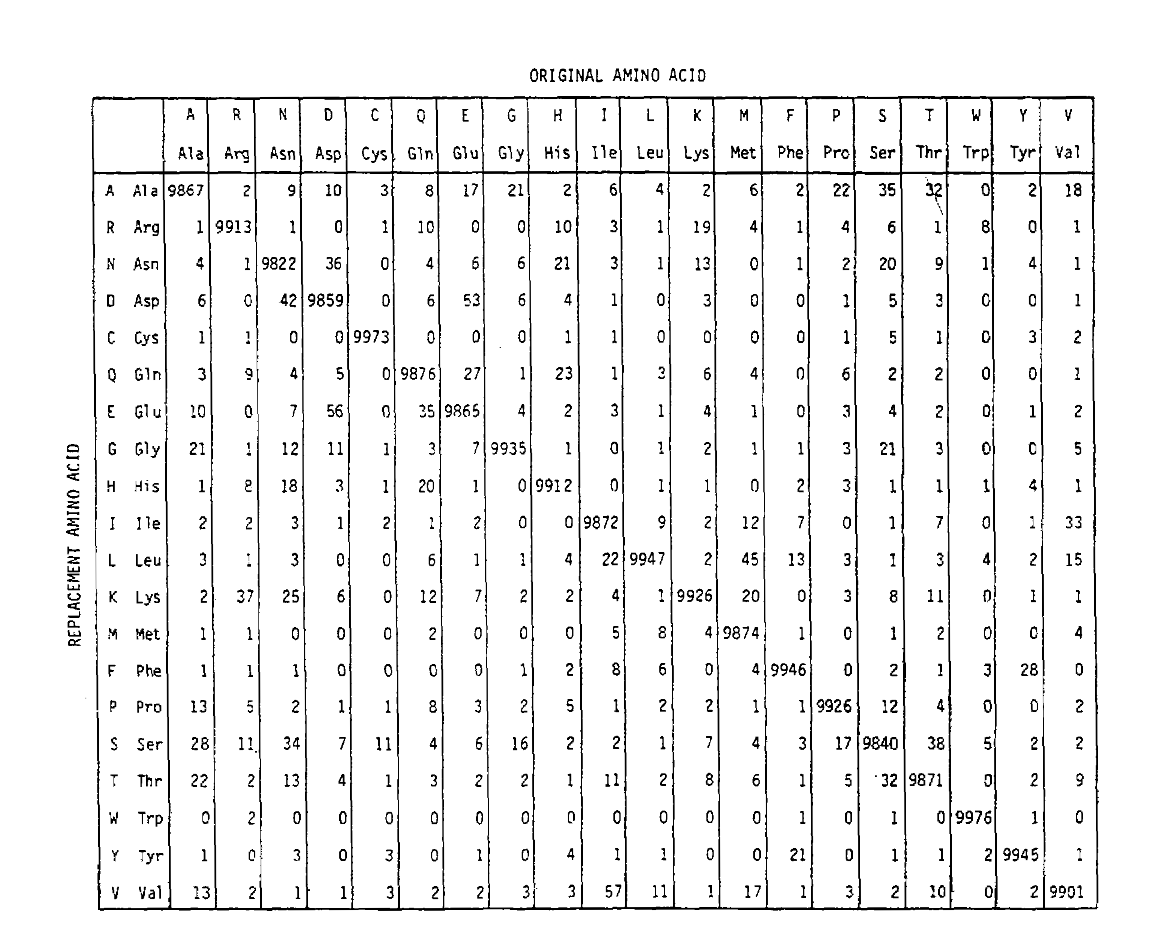
Pour calculer les probabilités de remplacement des acides aminés pour des durations plus longues, la matrice peut être multipliée par elle-même le nombre de fois correspondant. Ainsi, la matrice de probabilité PAM250, décrivant les probabilités de placement données à 250 unités de temps PAM, a été dérivée en élevant la matrice de probabilité PAM1 à la puissance 250 (tous les éléments ont été mis à l’échelle par 100 pour la lisibilité):
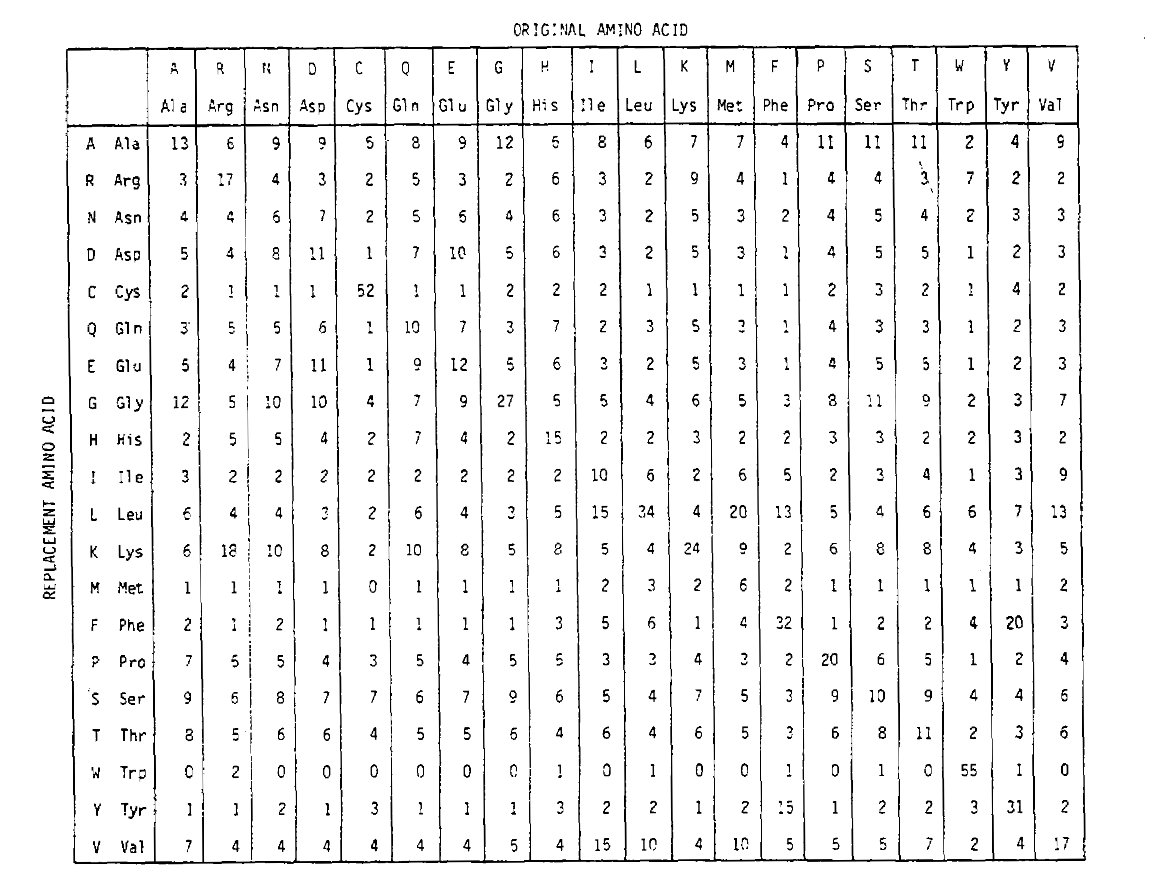
Les probabilités de remplacement dérivées en utilisant cette exponentiation comptent correctement pour plusieurs substitutions. Non seulement les probabilités hors diagonale sont proportionnellement plus grandes que vous pouvez vous y attendre pour une durée plus longue, mais elles sont plus plates. Par exemple, la probabilité d’un remplacement de la valine (V) par l’isoleucine(I) est 33× plus grande qu’un remplacement de V par l’histadine (H) dans la matrice PAM1, mais seulement 4,5× plus grande dans la matrice PAM250.
Les matrices de score peuvent alors être calculées à partir des matrices de probabilité et des fréquences de base observées.
Les matrices de BLOSUM, développées par Steven et Jorja Henikoff et publiées en1992, adoptent une approche très différente. Alors que PAM applique implicitement un modèle d’évolution des sites finis stationnaires à l’aide de l’exponentiation matricielle, l’effet de substitutions multiples est traité implicitement dans BLOSUM en construisant différentes matrices de scores pour différentes échelles de temps.
Dans des alignements de séquences multiples de séquences homologues, des blocs contigus d’acides aminés conservés sont identifiés. Dans chaque bloc, les séquences multiples sont regroupées lorsque leur identité de séquence moyenne par paire est supérieure à un certain seuil. Le seuil est de 80% pour la matrice BLOSUM80, 62% pour BLOSUM62, 50% pour BLOSUM50 et ainsi de suite.
Cela signifie que pour BLOSUM80, les blocs auront des identités par paires moyennes pas supérieures à 80%, pour BLOSUM62 pas supérieures à 62%, et cetera.
Les probabilités de remplacement des acides aminés pour les séquences homologues sont calculées à partir de comparaisons par paires entre les grappes. Ces probabilités seront le résultat de substitutions simples et multiples, les substitutions multiples ayant une plus grande influence à de plus grandes distances évolutives. Par conséquent, les matrices de score générées à partir de comparaisons par paires entre des clusters d’une distance plus grande en moyenne, comme la matrice BLOSUM50, expliqueront naturellement l’effet plus important des substitutions multiples.
Bien qu’ils empruntent des itinéraires différents, les matrices finales de score BLOSUM et PAM sont en fait assez similaires. Selon Henikoff et Henikoff, les matrices suivantesPAM et BLOSUM sont comparables:
| PAM | BLOSUM |
|---|---|
| PAM250 | BLOSUM45 |
| PAM160 | BLOSUM62 |
| PAM120 | BLOSUM80 |
For more information on PAM (Dayhoff) and BLOSUM matrices, see chapitre 2 Deanalyse des séquences biologiques par Durbin et al., et Wikipédia.
Mise à jour du 13 octobre 2019 : pour une autre perspective sur les matrices de substitution, consultez la section « Détours » à la fin du chapitre 5 de Bioinformatics Algorithms (2ème ou 3ème Édition) de Compeau et Pevzner.