hensikten med denne artikkelen er å forklare redundans når det gjelder databehandling, nettverk og hosting. Vi vil gi reelle eksempler på redundante teknologiløsninger for å illustrere hva redundans er og hvordan det fungerer.
Atlantic.Net har skapt flere vertsmiljøer, inkludert en holdbar skyplattform, høyhastighets VPS-hosting, HIPAA-kompatibel infrastruktur og administrert privat sky-hosting. Alle våre systemer er bygget med redundans som en primær drivende faktor i designprosessen.
i daglig engelsk kan redundans ha en negativ konnotasjon; noe overflødig er vanligvis ikke nødvendig eller betraktet som overflødig. I et cloud hosting-miljø kan redundans imidlertid bety forskjellen mellom sømløs systemtilgjengelighet og uønsket eller uventet nedetid.
- Hva Er Et Redundant System?
- Typer Redundante Systemer
- Eksempler på Redundante Programvaretjenester
- Hyper-V Replica
- Hyper-V Clustering
- HAProxy
- Heartbeat
- Eksempler på Redundante Maskinvaretjenester
- RAID
- Nettverksredundans
- FIRST Hop Redundancy Protocols (Fhrp)
- VIRTUAL Router Redundancy Protocol (VRRP)
- Hot Standby Router Protocol (HSRP)
- Gateway Load Balancing Protocol (GLBP)
- Datasenterredundans
- Konklusjon
Hva Er Et Redundant System?
et redundant system vil gi failover-eller lastbalanseringsstøtte for å beskytte et levende system i tilfelle en uventet feil. I tilfelle strøm, mekanisk eller programvarefeil, vil et redundant system ha en duplikat komponent eller plattform å falle tilbake til. Generelt kan enhver komponent i et system med et enkelt feilpunkt ses som en risiko for produksjonstjenester.Kraft-eller mekaniske systemer har enklere tilbakefallsstrategier som krever bare tilstedeværelse av en annen av samme type tjeneste; programvarefeil krever vanligvis ekstra konfigurasjon på vertssystemet eller en master eller gateway.
Redundansfunksjoner anbefales for alle forretningskritiske systemer, men spesielt for systemer som har betydelig innvirkning under nedetid. Noen bedrifter kan beholde alle sine kritiske kundeinformasjon i en database; derfor, for kontinuitet formål, beskytte databasen med redundans vil beskytte dataintegritet i tilfelle en katastrofal feil.
Typer Redundante Systemer
et redundant system består av minst to systemer som er sammenkoblet og designet for samme formål. Det finnes mange forskjellige typer redundante systemkonfigurasjoner, og ulike implementeringer av systemet gir unike tilnærminger til hvordan du holder et system oppe til enhver tid.
ikke alle servere må konfigureres med redundans; snarere bør bare de mest kritiske vurderes. Vi anbefaler detaljert risikovurdering for å forstå hvilke servere som er i omfang og maksimal nedetid serverne dine kan håndtere. Bruk denne vurderingen til å bestemme en RTO (Recovery Time Objective) og Rpo (Recovery Point Objective) strategi. RTO er den maksimale mengden akseptabel nedetid. Dette kan variere fra 5 sekunder til 24 timer. RPO er det tidspunktet du trenger dataene dine fra; for eksempel kan virksomheten din fungere med maksimalt tap av data på 24 timer.
Her er noen populære eksempler:
- Aktiv-Inaktiv / Varm-Kald – Når en komponent i et system er det aktive systemet og en annen er inaktiv eller slått av. Den inaktive komponenten aktiveres bare når den kjørende komponenten mislykkes eller gjennomgår vedlikehold
- Active-Active/Hot-Hot – Når begge systemene er live og gjør tilkoblinger. Dette er mest kjent som clustering. Vanligvis vil enheten foran begge maskinene bestemme hvordan du deler innkommende trafikk
- Aktiv-Standby / Varm-Varm – når begge systemene er på, Men bare en gjør tilkoblinger. Det andre systemet er ment å periodisk motta oppdateringer eller sikkerhetskopier fra primærsystemet. I tilfelle feil, tar systemet i standby den primære rollen til det opprinnelige systemet kan gjenopprettes.
Hver type har sine egne fordeler og ulemper.
- Aktive-Inaktive / Varme-Kalde systemer kan gi en enkel redundant plattform, men enhver failover vil resultere i at brukerne ser en eldre versjon av systemet.
- Active-Active / Hot-Hot vil kreve en konstant oppdatering av begge systemene, enten manuelt eller via en egen tjeneste, for å sikre at alle brukere kan bruke begge systemene. Denne tilnærmingen kan sterkt redusere den aktive belastningen på en tjeneste du leverer til kunder.Active-Standby / Hot-Warm vil gi failover-egenskapene til hot-cold med en mer oppdatert kopi av ditt aktive system på failover, men det gir ingen last lettelse.
Andre former for multiple node redundans er tilgjengelige som gir større redundans og robuste lastbalanseringsløsninger. På det tidspunktet har du en klynge med høy tilgjengelighet, også kjent SOM EN HA-klynge.
dette kan bruke en hvilken som helst kombinasjon av de tidligere nevnte redundansløsningene med maksimal fleksibilitet i tilnærmingen eller mengden redundans som trengs. HA-klynger kan også konfigureres på tvers av flere fysiske steder for å tillate tilgjengelighet opp til internett-ryggradsnivået.
Eksempler på Redundante Programvaretjenester
Kort av lav ressurs tilgjengelighet, er det svært liten grunn til ikke å ha proprietær replikering eller redundante tjenester satt opp i et virtuelt miljø; dermed er mange slike tjenester tilgjengelige som standard i de fleste virtualiseringssystemer. Alle våre skytjenester har replikering tilgjengelig, en funksjon som gjør at vi kan replikere hvilken som helst server fra en node til en annen, enten de er i samme datasenter eller separate datasenterregioner.
Hyper-V Replica
Hyper-V Replica er en form for varm-varm redundans. En primær virtuell maskin opprettes på en fysisk vert og godtar innkommende tilkoblinger. Når du aktiverer replikering, overføres de virtuelle harddiskene til den nye maskinen til en separat fysisk Hyper-V-vert. Denne verten konfigurerer DERETTER EN VM på seg selv som replikerer på en brukerdefinert tidsplan for å sikre at det nyeste bildet av den aktive serveren er tatt. Ytterligere sjekkpunkter poeng kan holdes i tillegg. Hyper-V privat hosting med administrerte tjenester leveres av Atlantic.Net med denne funksjonen bakt inn; kontakt vårt team for ytterligere informasjon.
Hyper-V Clustering
Hyper-V er også i stand til clustering gjennom en tilkobling til Andre Hyper-V verter. VMs på En Hyper-V-vert kan grupperes sammen på den singulære verten for å gi redundans på lokalt nivå gjennom virtuelt nettverk. Microsoft Network Load Balancing (Nlb) Kan brukes Til å opprette en enkelt ressurs som består av flere verter som deler samme informasjon for å gi et enkelt tilgangspunkt for fildeling. Siden dette bare er begrenset av mengden ressurser du har tilgjengelig, kan du teoretisk sette opp flere verter med Flere Vm-Er for maksimal redundans, noe som også vil tillate deg å utføre vedlikehold på individuelle Vm-er uten å ofre service-eller ressurstilgjengelighet. Hyper-V privat hosting med administrerte tjenester leveres av Atlantic.Net med denne funksjonen bakt inn; kontakt vårt team for ytterligere informasjon.
HAProxy
bortsett Fra Hyper-V, kan en gateway-enhet som en brannmur brukes til failover-eller lastbalanseringstjenester. For Eksempel Atlanterhavet.Net kan gi pfSense Med Høy Tilgjengelighet Proxy, også kjent som HAProxy.
HAProxy vil fungere som en lastbalanser, en proxy eller en enkel varm-varm løsning med høy tilgjengelighet for TCP-og HTTP-baserte applikasjoner. HAProxy er En Veldig populær, Linux-basert åpen kildekode-løsning som brukes av noen av de mest besøkte nettstedene i verden.
Heartbeat
Heartbeat Er en tjeneste tilgjengelig på De fleste distribusjoner Av Linux som brukes til å avgjøre om noder i en klynge fortsatt er oppe eller responsive. Det er veldig enkelt å sette opp og gir failover evner til ethvert system som arbeider over TCP.
Utviklerne av Heartbeat anbefaler også andre cluster resource managers som starter eller stopper tjenester basert på om en bestemt vert er nede. Heartbeat har dette inkludert, men andre ledere er tilgjengelige. På Grunn Av Heartbeat enkelhet, er det lett å tilpasse. Cloud Hosting plattformer levert av Atlantic.Net har allerede denne funksjonen bakt inn, og vi kan hjelpe deg med å implementere Heartbeat på din egen Private Linux-distribusjon, om nødvendig.
Eksempler på Redundante Maskinvaretjenester
den beste delen om redundant maskinvare er dens enkelhet. Mens programvaretjenester kan kreve overdreven konfigurasjon og muligens er ganske følsomme, er maskinvaren vanligvis veldig enkel å sette opp og utrolig holdbar. Det første eksemplet vi vil se på er den mye brukte RAID-teknologien.
RAID
RAID står For Redundant Array Of Independent Disks (Eller Redundant Array Of Inexpensive Disks, avhengig av hvor lenge du har brukt Det) og har flere nivåer som brukes enten for databeskyttelse Eller økt disk I/O.
RAID kan enten settes opp via en programvare-eller maskinvarekontroller. Kontrolleren har programvaren og konfigurasjonen som er nødvendig for å administrere RAID-diskene. Konfigurasjonen kan eksporteres til forskjellige systemer med liten eller ingen ekstra konfigurasjon.
RAID kan settes opp på noen forskjellige måter for å gi en god balanse mellom begge sine kvaliteter:
- RAID 0-dette er egentlig ingen redundans. Ingen disker på systemet dele data gjennom speiling, men alle data er stripete over hver disk gir økt lese / skrivehastighet. Hver stasjon kan fortsatt bruke lagringsplassen som er gitt til det, noe som betyr at jo flere stasjoner du legger TIL EN RAID 0, desto mer plass har du.
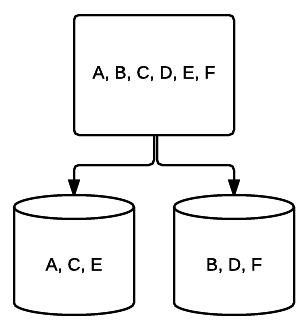
- RAID 1-en grunnleggende form for speiling som gir utmerket redundans på bekostning av plass. I et to-stasjonssystem skrives en komplett kopi av dataene på en stasjon til den andre. Denne redundansen er forbedret med hver stasjon lagt til. Siden alle data må speiles på tvers av alle stasjoner, vil total plass på systemet være begrenset til bare plassen til den minste stasjonen i systemet.
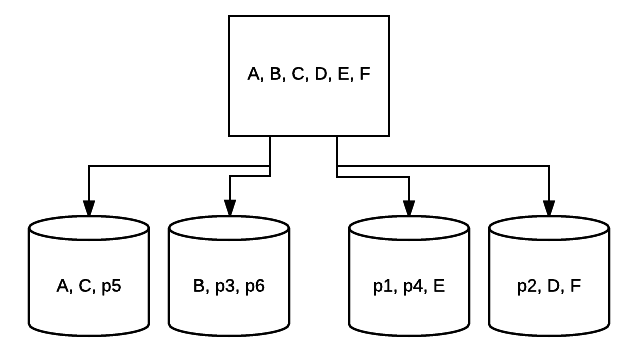
- RAID 5-DENNE FORMEN for RAID brukes vanligvis til å øke lesehastigheten og påliteligheten. I dette tilfellet plasseres striper om hver stasjon i systemet, med minimum 3 stasjoner. Samtidig plasseres en ekstra blokk med feilkorrigerende data om hver stasjon i en teknikk som kalles paritet. Dette kontrollerer om data endres ved overføring fra en stasjon til en annen. Dette gir også en minimal form for redundans siden 1 av disse stasjonene kan mislykkes og systemet kan fortsatt kjøre. Jo flere stasjoner som legges til DENNE TYPEN RAID-oppsett, desto mer øker lesehastigheten. Med minimum redundans og striping på tvers av alle stasjoner, er den totale mengden plass i dette oppsettet lik størrelsen på ditt logiske RAID-volum ganger antall stasjoner du bruker, minus en. Hvis du for eksempel har 5 500 GB-stasjoner I EN RAID 5, vil du ha 2000 GB brukbar eller 2 TB (500 *(5-1)=2000).
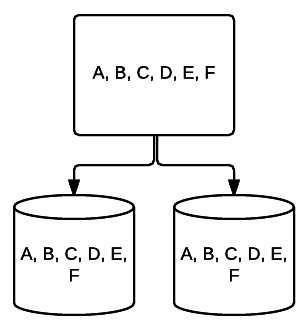
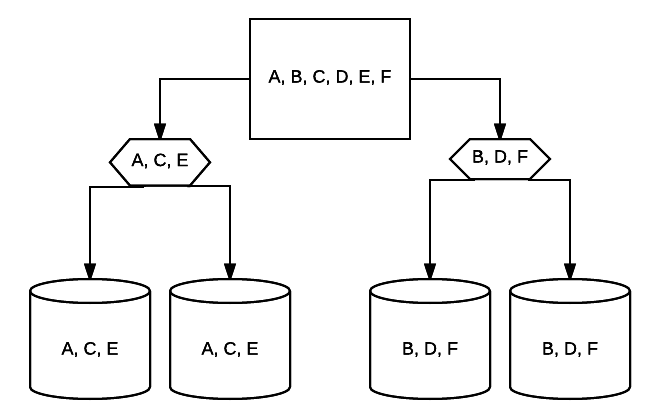
- RAID 10-DETTE er en kombinasjon AV RAID 1 og RAID 0. I dette tilfellet er alle data stripet over hver enhet med blokker av data som også speiles over hele det stripete systemet. FOR eksempel, I ET 4-stasjon RAID 10-system kan 2 500 GB-stasjoner ha de samme dataene, men ikke alle dataene som trengs for at systemet skal fungere skikkelig. 2 andre stasjoner data ville være nødvendig. Tenk på HVERT RAID 1-system som en enkelt stasjon, og hvert av disse systemene plasseres i ET RAID 0-array. I dette oppsettet kan ytelsen økes drastisk som I RAID 0, med litt redundans fortsatt på plass med speiling. Opptil halvparten av stasjonene i systemet kan mislykkes før systemet krasjer, men som med alle overflødige array, er det best å erstatte stasjoner så snart som mulig. Atlantic.Net BRUKER RAID 10 for ALL SSD Cloud VPS Lagring.
FOR ekstra beskyttelse er RAID-kontrollerne beskyttet av batteribackupenheter som driver ROM-sjetongene som brukes til å lagre konfigurasjonen i minnet i tilfelle strømbrudd, etc. EN BBU vil gi strøm til ET RAID-array som er en del av et drevet system i en liten stund, slik at innholdet i EN RAID-kontrollerens cache forblir intakt. Dette kan være en livredder hvis informasjonen blir stadig matet INN I RAID array og nedetid kan føre til data korrupsjon.
så, ditt fysiske system og tjenestene innenfor kan konstrueres overflødig ganske tilstrekkelig. Men hva med din tilkobling til noen del av systemet ditt? Som i, din direkte internett-tilkobling til systemet som helhet?
Nettverksredundans
FIRST Hop Redundancy Protocols (Fhrp)
i motsetning til dynamiske gateway discovery-protokoller, tillater statiske gateways enkle hopp mellom klienten og deres passende gateway, men dette skaper et enkelt feilpunkt-nemlig selve gatewayen.
For å forhindre eller redusere virkningen av gateway-feil, Ble FHRPs opprettet. De gir redundante gateways en fallback, eller tilbyr lastbalansering for høytrafikksystemer, sammen med redundans. Disse protokollene inkluderer VRRP, HSRP og GLBP.
VIRTUAL Router Redundancy Protocol (VRRP)
VRRP ER en form for redundans som brukes for rutere som krever minst to fysisk separate rutere koblet via Enten Ethernet eller optisk fiber tilkoblinger. I dette tilfellet opprettes en virtuell ruter som inneholder statiske ruter og deles mellom hvert system.
Ett system regnes som ‘master’ og et annet som ‘backup’. Når master mislykkes, tar backup over som neste master. Dette kan settes opp med flere sikkerhetskopier for ekstra redundans. Konseptet er svært lik Heartbeat i at backup-systemer vil sjekke for å se om master er tilgjengelig. Når den ikke mottar et svar, vil sikkerhetskopien etter en forhåndsbestemt tid ta kontroll over den virtuelle bryteren og godta tilkoblinger for alle forespørsler som kommer inn for standard IP konfigurert for hovedbryteren.
Hot Standby Router Protocol (HSRP)
HSRP er SOM VRRP; men i dette scenariet er den konfigurerte virtuelle bryteren ikke en bryter, men en logisk gruppe med flere rutere. Ip-en til gruppen er EN IP som ikke er tilordnet en fysisk vert. I stedet er gruppen tildelt EN IP, og en av ruterne er fast bestemt på å være den aktive ruteren.
en standby-ruter er klar til å ta alle tilkoblinger hvis den aktive ruteren går ned. Alle rutere i tillegg til aktiv og standby lytter alle til å bestemme sin plass i kø. HSRP ER En Cisco proprietær protokoll og har svært få, mindre forskjeller TIL VRRP som standard tidtakere bestemme når du skal failover. HSRP har eksistert litt lenger og er mer kjent i forhold TIL VRRP.
Gateway Load Balancing Protocol (GLBP)
GLBPS største fordel over HSRP og VRRP er evnen til å laste balanse på toppen av å gi redundans til en gateway med liten eller ingen ekstra konfigurasjon. Mye SOM HSRP OG VRRP, VIL GLBP opprette en gruppe mellom fysiske rutere og bestemme En Aktiv Virtuell Gateway, ELLER AVG.
en virtuell IP som for øyeblikket ikke brukes av noen av ruterne i gruppen, tilordnes GJ.SN. AVG distribuerer deretter virtuelle MAC-adresser blant resten av ruterne i gruppen. Hver backup router er nå betraktet Som En Aktiv Virtuell Speditør, eller AVF.
ARP-forespørsler sendt til AVG vil gi en annen virtuell MAC-adresse til klienten som sender forespørselen. På det tidspunktet går trafikken fra den klienten til gruppens virtuelle IP videre til ruteren hvis virtuelle MAC-adresse de mottok, slik at hver ruter fortsatt kan brukes i stedet for å sitte idiotisk av.
i TILFELLE FEIL I AVG, foregår prioritetsbasert valg, akkurat som I HSRP og VRRP, og neste backup tar sin plass, og distribuerer virtuelle MAC-adresser som normalt. De andre ruterne beholder fortsatt den virtuelle MAC-adressen fra den opprinnelige AVG, og ting fortsetter som normalt. I tilfelle feil i En Av AVFs, vil AVG forhindre ruting av trafikk til sin virtuelle MAC-adresse.AKKURAT SOM HSRP, ER GLBP En Cisco proprietær form FOR FHRP.
Datasenterredundans
i tillegg til redundansmål for dine personlige servere eller rutere, er datasentre designet for å være motstandsdyktige mot systemfeil. Datasentre faller under nivåer definert av Uptime Institute for å gi feiltoleranse for feil på mekanisk eller servicefeil, noe som gir så mye oppetid som mulig.
Det er fire nivåer, hver bygger på hverandre for å gi høy tilgjengelighet til alle klienter i et datasenter:
- Tier I-Grunnleggende Kapasitet: Dette krever plass TIL EN IT-gruppe for datasenteroperasjoner, EN avbruddsfri strømforsyning (UPS) som overvåker og filtrerer strømforbruket og dedikert kjøleutstyr som kontinuerlig kjører 24/7. Dette inkluderer også en kraftgenerator i tilfelle elektrisk strømbrudd.Tier II-Redundante Kapasitetskomponenter: Alt Som Tier I gir, pluss redundant strøm og kjøling til anlegget. DETTE kan inkludere EKSTRA UPS-enheter eller ekstra generatorer.
- Tier III – Samtidig Vedlikeholdsbar: Alt Tier II gir, pluss ekstra utstyr pa plass for a forhindre behov for stans for utskifting eller vedlikehold av utstyr. På dette nivået brukes redundant strøm og kjøling direkte på alt teknisk utstyr, og selve utstyret er konfigurert for redundans eller sømløs failover.Tier IV-Feiltoleranse: Alt Tier III gir, pluss uavbrutt service på leverandørnivå. Mens et datasenter kan ha strøm eller vann levert av en by eller statlig leverandør, er det nødvendig med en sekundær linje av hver tjeneste som brukes av datasenteret. Dette inkluderer OGSÅ ISP. I tilfelle feil i noen del som fører opp til klientutstyr, er det en reserveplan på plass klar for en sømløs overgang.
Konklusjon
Redundans har blitt en daglig term I IT-bransjen på grunn av nødvendighet. Den høye tilgjengeligheten av tjenester gir en enkel og pålitelig opplevelse for våre kunder.
enten på servicenivå eller datasenternivå, er redundans til systemet et viktig og vanskelig problem å takle. Forhåpentligvis har dette papiret kastet litt lys på de tilgjengelige alternativene og vil hjelpe til med beslutninger om høy tilgjengelighet fremover.
Klar Til å dra nytte av Atlantic.Net er redundante systemer? Kontakt oss i dag for å finne ut mer Om Dedikert Server Hosting med Atlantic.Net Redundant System Grunnleggende Begreper:http://www.ni.com/white-paper/6874/en/
Kald/Varm/Varm Server: http://searchwindowsserver.techtarget.com/definition/cold-warm-hot-server
Høy Tilgjengelighet Clustering: https://www.mulesoft.com/resources/esb/high-availability-cluster
kopi av hyper-v: https://technet.microsoft.com/en-us/library/jj134172(v=ws.11).aspx
Hyper-V and High Availability: https://technet.microsoft.com/en-us/library/hh127064.aspx
HAProxy Description: http://www.haproxy.org/#desc
HAProxy – They use it!: http://www.haproxy.org/they-use-it.html
Heartbeat: http://www.linux-ha.org/wiki/Main_Page
RAID Definition: http://searchstorage.techtarget.com/definition/RAID
Striping: http://searchstorage.techtarget.com/definition/disk-striping
RAID Battery Backup Units: https://www.thomas-krenn.com/en/wiki/Battery_Backup_Unit_(BBU/BBM)_Maintenance_for_RAID_Controllers
High-Availability – VRRP, HSRP, GLBP: http://www.freeccnastudyguide.com/study-guides/ccna/ch14/vrrp-hsrp-glbp/
Understanding VRRP: http://www.juniper.net/techpubs/en_US/junos/topics/concept/vrrp-overview-ha.html
Configuring VRRP: http://www.cisco.com/c/en/us/td/docs/ios-xml/ios/ipapp_fhrp/configuration/15-mt/fhp-15-mt-book/fhp-vrrp.html
Configuring GLBP: http://www.cisco.com/c/en/us/td/docs/ios-xml/ios/ipapp_fhrp/configuration/xe-3s/fhp-xe-3s-book/fhp-glbp.html
Explaining the Uptime Institute’s Tier Classification System: https://journal.uptimeinstitute.com/explaining-uptime-institutes-tier-classification-system/