Av: Arshad Ali | Oppdatert: 2020-07-29 / Kommentarer (6) / Relatert: Mer > BLI Med Tabeller
Problem
I SPISSEN SQL Server Joineksempler Snakket Jeremy Kadlec om forskjellige logiske bli med operatører, men hvordanimplementerer SQL Server dem fysisk? Hva er de forskjellige fysiske joinoperators? Hvordan er de forskjellige fra hverandre og i hvilket scenario er en foretrekketover andre? I dette tipset dekker vi disse spørsmålene og mer.
Løsning
vi bruker logiske operatorer når vi skriver spørringer for å definere en relasjonsspørring på det konseptuelle nivået (hva må gjøres). SQL implementerer disse logiske operatørenemed tre forskjellige fysiske operatører for å implementere operasjonen definert avlogiske operatører (hvordan det må gjøres). Selv om det er dusinvis av fysiskeoperatører, i dette tipset vil jeg dekke bestemte fysiske bli operatører. Selv om vi har forskjellige typer logiske sammenføyninger på konsept/spørringsnivå, Men SQL Serverimplements dem alle med tre forskjellige fysiske sammenføyningsoperatører som diskutert nedenfor.Vi vil dekke:
- Nestede Looper Bli med
- Merge Bli med
- Hash Bli med
Vi vil se påutføringsplaner for å se disse operatørene, og jeg vil forklare hvorfor hver oppstår.
for disse eksemplene bruker jeg theAdventureWorks database.
SQL Server Nestede Looper Bli Forklart
før du graver inn i detaljene, la meg fortelle deg først hva En Nestede Looper joinis hvis du er ny i programmeringsverdenen. En Nestet Sløyfe er en logisk struktur der en sløyfe (iterasjon) borinne i en annen, det vil si for hver iterasjon av den ytre sløyfen utføres alle theter av den indre sløyfen / behandles.
En Nestet Loops join fungerer på samme måte. En av sammenføyningsbordene er utpektsom det ytre bordet og en annen som det indre bordet. For hver rad av yttertabellen matches alle rader fra det indre bordet en etter en hvis raden samsvarerdet er inkludert i resultatsettet ellers blir det ignorert. Så neste rad fradet ytre bordet er plukket opp og den samme prosessen gjentas og så videre.
SQL Server optimizer kan velge En Nestet Looper delta når en av joiningtables er liten (betraktet som den ytre tabellen) og en annen er stor (considedas den indre tabellen som er indeksert på kolonnen som er i join) og henceit krever minimal I/O og færrest sammenligninger.
optimizer vurderer tre varianter For En Nestet Looper delta:hele tabellen eller indeksen
en indeks Nestede Looper blir bedre enn en flettekobling eller hash-kobling hvis et lite sett med rader er involvert. Mens, hvis et stort sett med rader er involvert theNested Loops bli kanskje ikke et optimalt valg. Nestede Løkker støtter nesten allefelles typer unntatt høyre og fulle ytre sammenføyninger, høyre semi-join og høyre anti-semifelles.
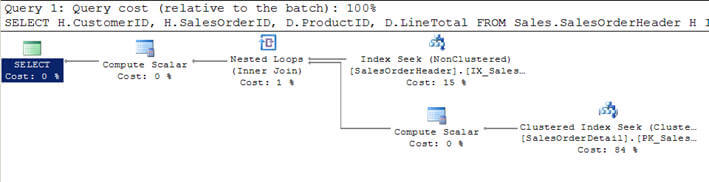
- I Script # 1 blir jeg Med I SalesOrderHeader-tabellen Med SalesOrderDetailtable og angir kriteriene for å filtrere resultatet av kunden withCustomerID = 670.
- dette filtrerte kriteriene returnerer 12 poster fra SalesOrderHeader-tabellen og dermed den minste, har denne tabellen blitt vurdert som den ekstra tabellen (øverst i den grafiske spørringsutførelsesplanen) av optimizer.
- for hver rad av disse 12 radene i den ytre tabellen, er radene fra den indre tabellen SalesOrderDetail matchet (eller innertabellen skannes 12 ganger hver gang for hver rad ved hjelp av indekssøk eller korrelertparameter fra den ytre tabellen) og 312 matchende rader returneres som du kanse i det andre bildet.
- i den andre spørringen nedenfor bruker JEG SET STATISTICS PROFILE TIL displayprofile informasjon om spørringsutførelsen sammen med spørringsresultatet.
Script #1 – Nestede Løkker Delta Eksempel
SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader H INNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID = 670
SET STATISTICS PROFILE ONSELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader HINNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderIDWHERE H.CustomerID = 670SET STATISTICS PROFILE OFF

hvis antallet involverte poster er stort, kan sql server velge å parallelisere en nestet sløyfe ved å distribuere de ytre tabellradene tilfeldig mellom de tilgjengelige looptrådene dynamisk. Det gjelder ikke det samme for de indre tablerows skjønt. For å lære mer om parallel scansclick her.
SQL Server Merge Join Explained
det første du trenger å vite om En Merge join Er at det krever at begge inngangene skal sorteres på join keys / merge columns(eller begge inndatatabellene har clusteredindexes på kolonnen som knytter seg til tabellene), og det krever også minst ett equijoin (lik) uttrykk/predikat.
fordi radene er forhåndssortert, starter en flettekobling umiddelbart matchingprocess. Den leser en rad fra en inngang og sammenligner den med raden til en annen inngang.Hvis radene samsvarer, blir den samsvarende raden vurdert i resultatsettet (så leser den neste raden fra inntastingstabellen, gjør samme sammenligning/kamp og så videre) eller den minste av de to radene ignoreres og prosessen fortsetter på denne måten til alle rader er behandlet..
En Flettekobling fungerer bedre når du kobler sammen store inndatatabeller (forhåndsindeksert / sortert), da kostnaden er summering av rader i begge inndatatabellene i motsetning til NestedLoops hvor det er et produkt av rader i begge inndatatabellene. Noen ganger optimizerdecides å bruke En Flette delta når inndatatabellene ikke er sortert og derfor ituses en eksplisitt sort fysisk operatør, men det kan være tregere enn å bruke en indeks (pre-sortert inndatatabell).I Script # 2 bruker jeg en lignende spørring som ovenfor, men denne gangen har jeg lagt TIL EN WHERE-klausul for å få all kunde større enn 100.
Script #2 – Sammenslåing Eksempel
SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader H INNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID > 100
SET STATISTICS PROFILE ONSELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader HINNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderIDWHERE H.CustomerID > 100SET STATISTICS PROFILE OFF

en merge join er ofte en mer effektiv og raskere join operator hvis sorteddata kan hentes fra en eksisterende b-tree indeks og den utfører nesten alle joinoperations så lenge det er minst ett likestillings join predikat involvert. Italso støtter flere likestillings join predikater så lenge inndatatabellene aresorted på alle sammenføyningsnøkler involvert og er i samme rekkefølge.
Tilstedeværelsen av En Compute skalar operator indikerer evalueringen av et uttrykk for å produsere en beregnet skalarverdi. I spørringen ovenfor velger Jeg Linetotalsom er en avledet kolonne, derfor har den blitt brukt i utførelsesplanen.
Sql Server Hash Join Explained
En Hash join brukes vanligvis når inndatatabeller er ganske store og det finnes ingen adequateindexes på dem. En Hash-sammenføyning utføres i to faser; Byggfasen andthe Probe-fasen og dermed hash-sammenføyningen har to innganger, dvs. bygginngang og probeinput. Den minste av inngangene betraktes som bygginngangen (for å minimere minnebehovet for å lagre et hashbord diskutert senere) og åpenbart er den andre sondeinngangen.
under byggefasen skannes sammenføyningsnøkler i alle radene i byggetabellen.Hashes genereres og plasseres i et hash-bord i minnet. I motsetning Til Flettekoblingen, blokkerer den (ingen rader returneres) til dette punktet.
under sondefasen skannes sammenføyningsnøkler i hver rad i sondebordet.Igjen genereres hashes (ved hjelp av samme hash-funksjon som ovenfor) og comparedagainst det tilsvarende hash-bordet for a matche.
En Hash-funksjon krever betydelig MENGDE CPU-sykluser for å generere hashes og minneressurser for å lagre hash-tabellen. Hvis det er minnetrykk, blir noen av partisjonene i hash-tabellen byttet til tempdb, og når det er behov for (enten å sonde eller oppdatere innholdet), blir det brakt tilbake i hurtigbufferen.For å oppnå høy ytelse, kan query optimizer parallellisere En Hash bli toscale bedre enn noen annen delta, for mer detailsclick her.
Det er i utgangspunktet tre forskjellige typer hash join:
- in-memory Hash Join i så fall nok minne er tilgjengeligå lagre hash tabellen
- Grace Hash Join i så fall hash tabellen kan ikke fitin minne og Noen partisjoner er sølt til tempdb
- Rekursiv Hash Join i så fall En hash tabellen er så storthe optimizer har til å bruke mange nivåer av merge joins.
for mer informasjon om disse forskjellige typerklikk her.
- I Script # 3 lager jeg to nye store tabeller (fra eksisterende AdventureWorkstables) uten indekser.
- du kan se optimizer valgte å bruke En Hash delta i dette tilfellet.
- igjen, i motsetning Til En Nestet Sløyfe, skanner Den ikke de indre tabellmultipletidene.
Script #3 – Hash Delta Eksempel
--Create tables without indexes from existing tables of AdventureWorks database SELECT * INTO Sales.SalesOrderHeader1 FROM Sales.SalesOrderHeader SELECT * INTO Sales.SalesOrderDetail1 FROM Sales.SalesOrderDetail GO SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader1 H INNER JOIN Sales.SalesOrderDetail1 D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID = 670 GO

--Drop the tables created for demonstration DROP TABLE Sales.SalesOrderHeader1 DROP TABLE Sales.SalesOrderDetail1
merk: sql server gjør en ganske god jobb med å bestemme hvilken joinoperator som skal brukes i hver tilstand. Å forstå disse forholdene hjelper deg å forståhva kan gjøres i ytelsesjustering. Det er ikke anbefalt å bruke join hint (usingOPTION klausul) for å tvinge SQL Server til å bruke en bestemt join operatør (med mindre du haveno annen vei ut), men heller du kan bruke andre midler som oppdaterer statistikk,opprette indekser eller re-skrive søket.
Neste Trinn
- ReviewSQL ServerJoin Eksempler tips.
- ReviewLogical Og Fysiske Operatører Referanse artikkel om technet.
Sist Oppdatert: 2020-07-29


 Arshad Ali is a SQL and BI Developer focusing on Data Warehousing projects for Microsoft.
Arshad Ali is a SQL and BI Developer focusing on Data Warehousing projects for Microsoft.View all my tips
- More Database Developer Tips…