i dagens artikkel skal vi se på rolling and expanding windows.
ved slutten av innlegget vil du kunne svare på disse spørsmålene:
- Hva er et rullende vindu?
- Hva er et ekspanderende vindu?
- Hvorfor er de nyttige?
Hva Er Et Rullende eller Ekspanderende vindu?

her er et vanlig vindu.
vi bruker vanlige vinduer fordi vi vil ha et glimt av utsiden, jo større vinduet jo mer av utsiden får vi se.
Også som en generell tommelfingerregel, jo større vinduer på noens hus, jo bedre deres aksjeportefølje gjorde …
akkurat som ekte vinduer, data vinduer også gi oss et lite glimt inn i noe større.
et bevegelig vindu gjør det mulig for oss å undersøke et delsett av dataene våre.
Rullende Vinduer
Ofte vil vi vite en statistisk egenskap av tidsseriedataene våre, men fordi alle tidsmaskinene er låst opp I Roswell, kan vi ikke beregne en statistikk over hele prøven og bruke den til å få innsikt.
Det ville introdusere look-ahead bias i vår forskning.
her er et ekstremt eksempel på det. Her har vi plottet TSLA-prisen og dens gjennomsnitt over hele prøven.
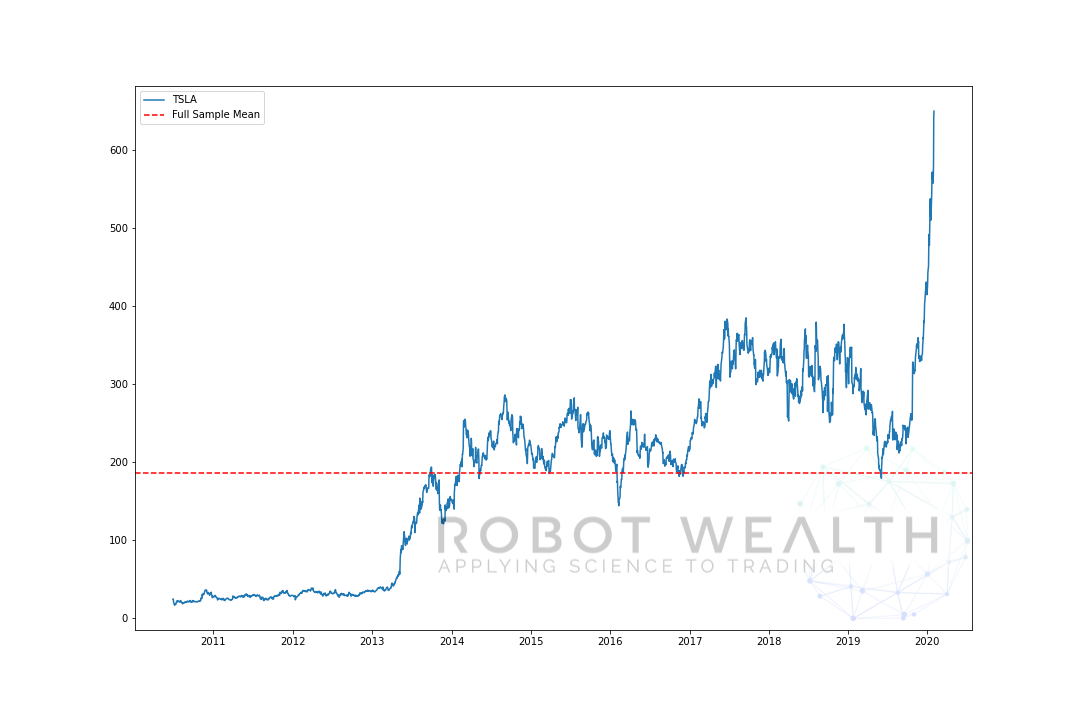
import pandas as pdimport matplotlib.pyplot as plt #Load TSLA OHLC df = pd.read_csv('TSLA.csv')#Calculate full sample meanfull_sample_mean = df.mean()#Plotplt.plot(df,label='TSLA')plt.axhline(full_sample_mean,linestyle='--',color='red',label='Full Sample Mean')plt.legend()plt.show()
I dette tilfellet, hvis VI nettopp kjøpte TSLA da prisen var under gjennomsnittet og Solgte den over gjennomsnittet, ville vi ha drept, vel i hvert fall opp til 2019…
Men problemet er at vi ikke ville ha kjent middelverdien på det tidspunktet i tid.
så det er ganske åpenbart hvorfor vi ikke kan bruke hele prøven, men hva kan vi gjøre da? En måte vi kan nærme seg dette problemet er ved å bruke rullende eller ekspanderende vinduer.
hvis du noen gang har brukt Et Enkelt Glidende Gjennomsnitt, så gratulerer-du har brukt et rullende vindu.
hvordan fungerer rullende vinduer?
La oss si at du har 20 dager med aksjedata, og du vil vite gjennomsnittlig pris på aksjen de siste 5 dagene. Hva gjør du?
du tar de siste 5 dagene, summerer dem opp og deler med 5.
men hva om du vil vite gjennomsnittet av de foregående 5 dagene for hver dag i datasettet ditt?
dette er hvor rullende vinduer kan hjelpe.
i dette tilfellet vil vinduet vårt ha en størrelse på 5, noe som betyr for hvert tidspunkt det inneholder gjennomsnittet av de siste 5 datapunktene.
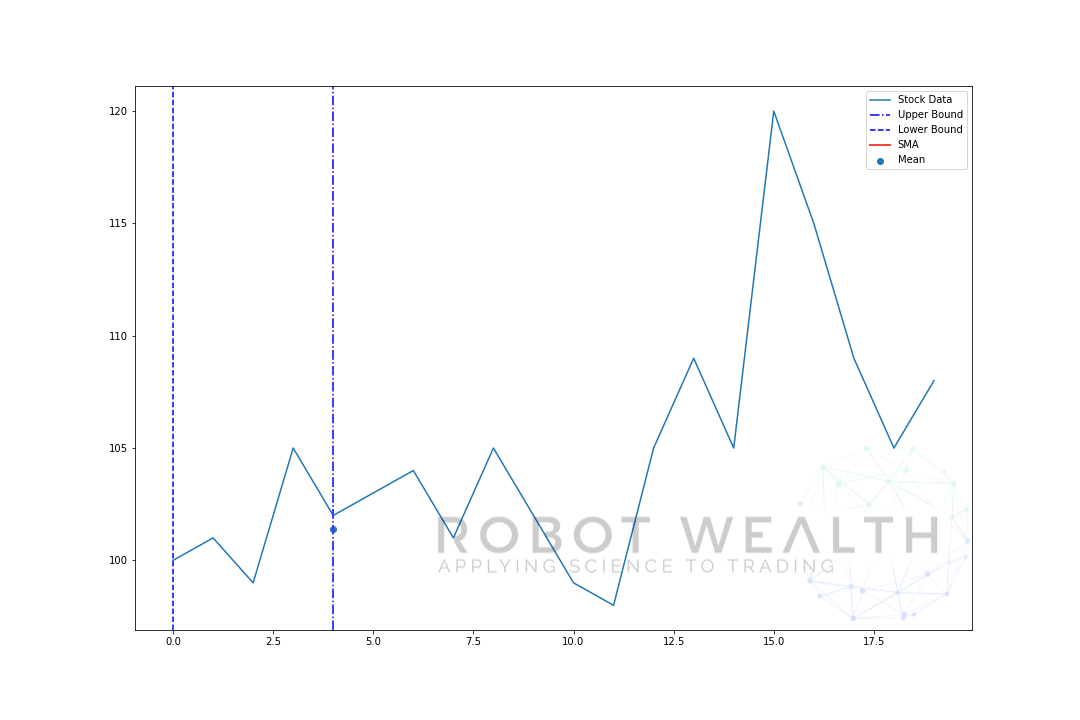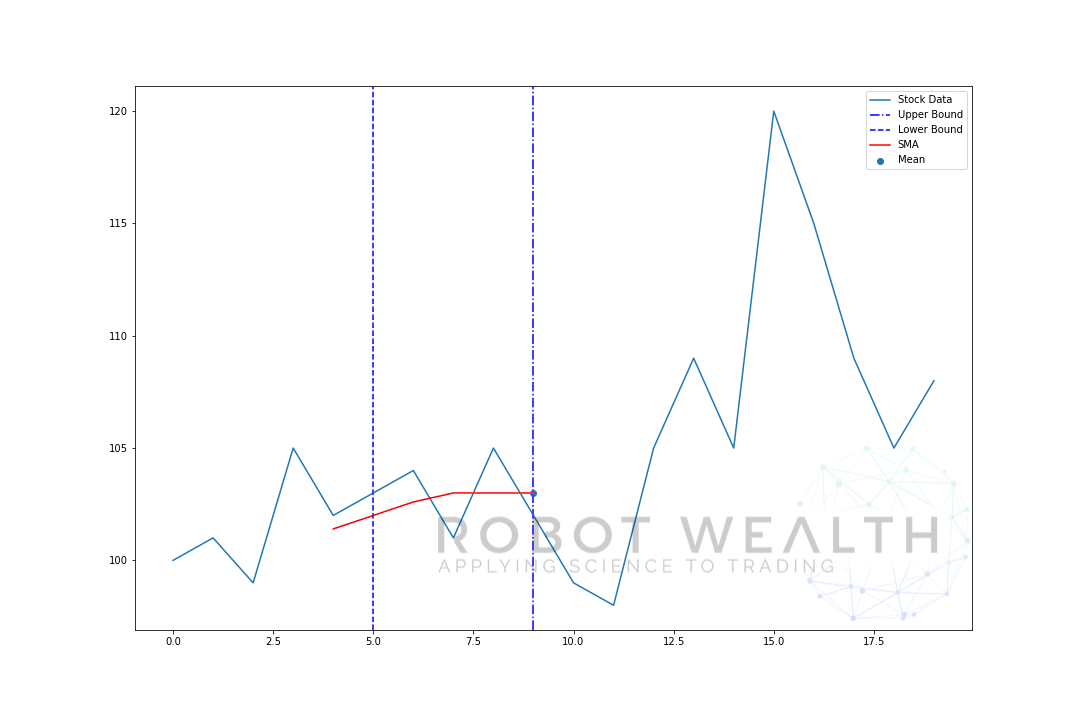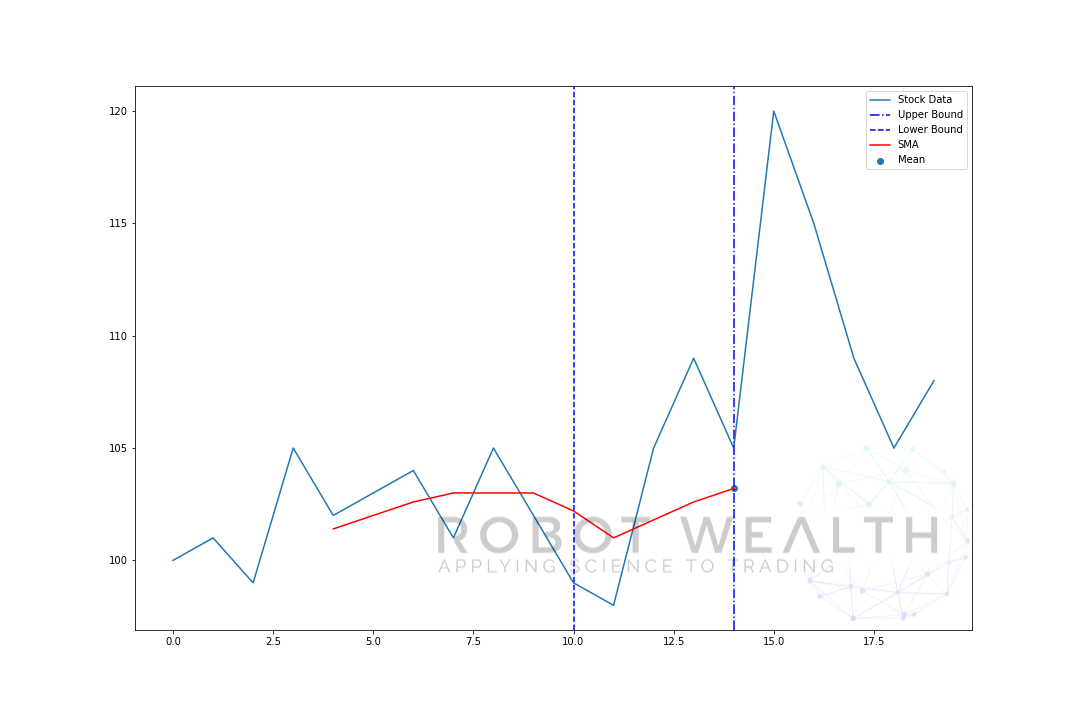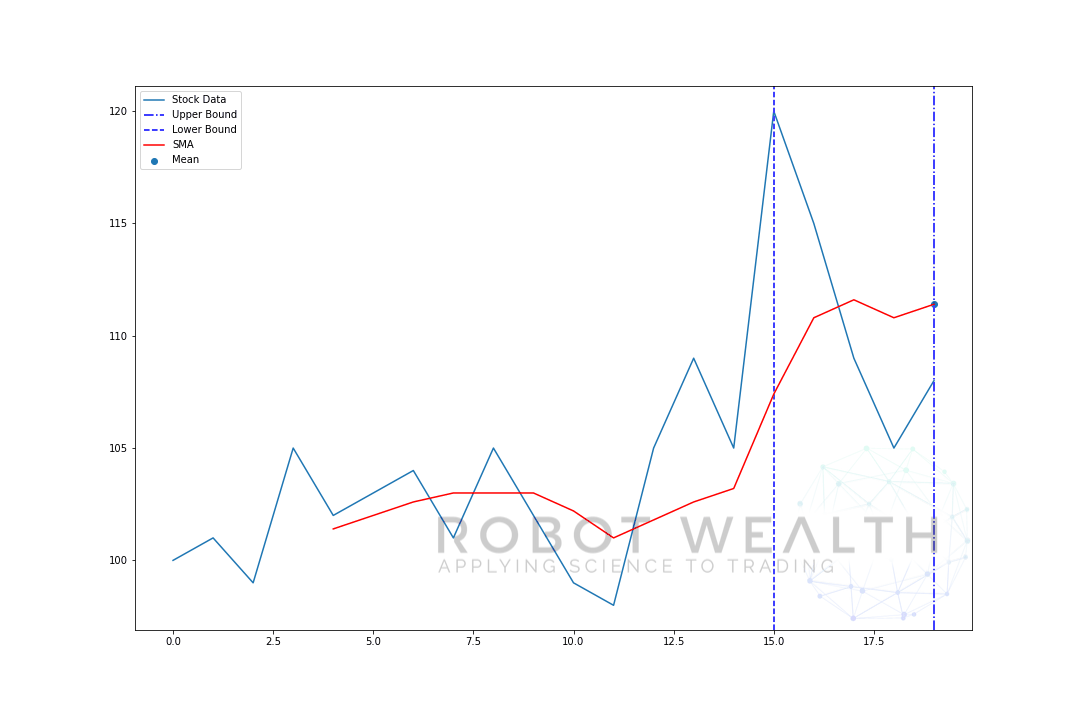
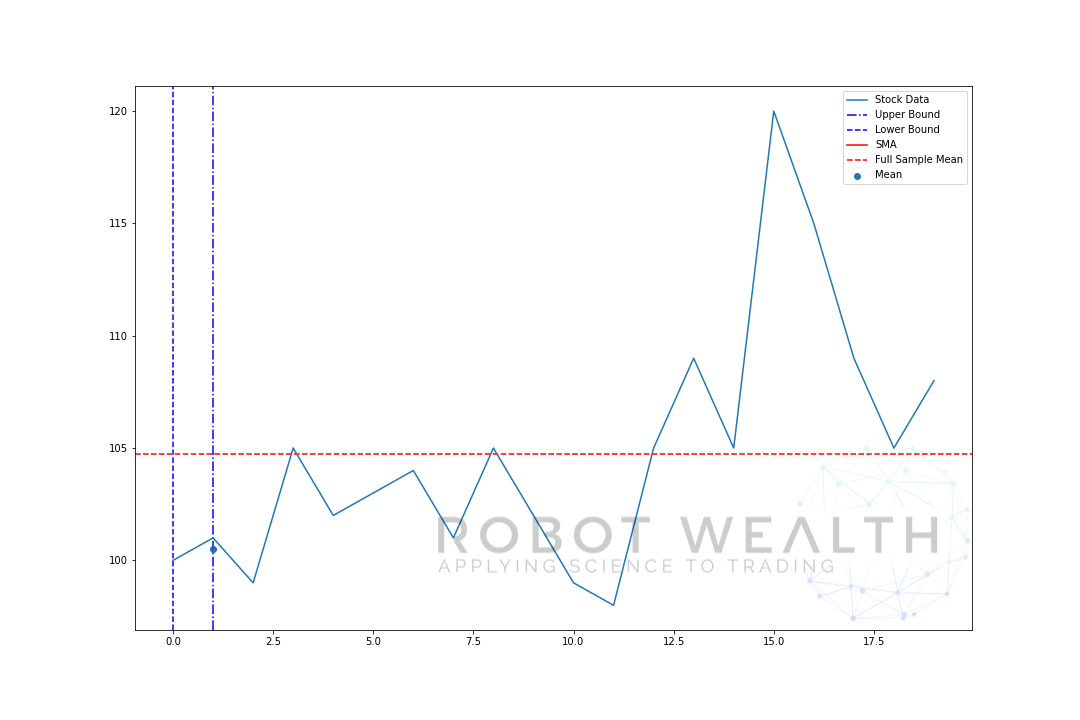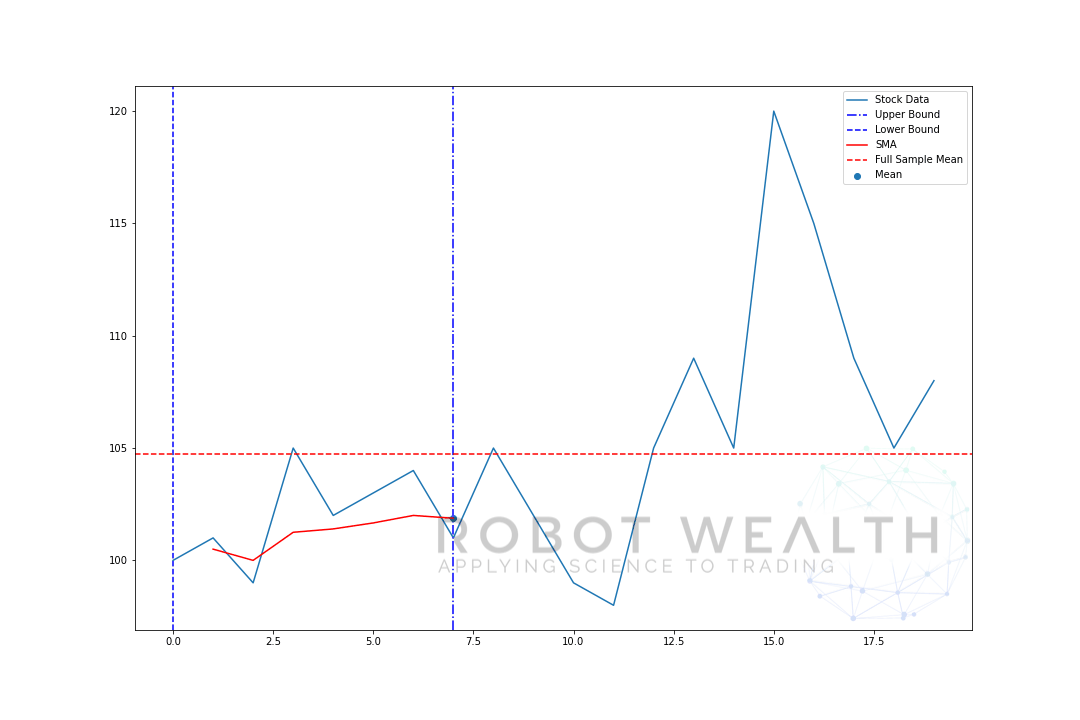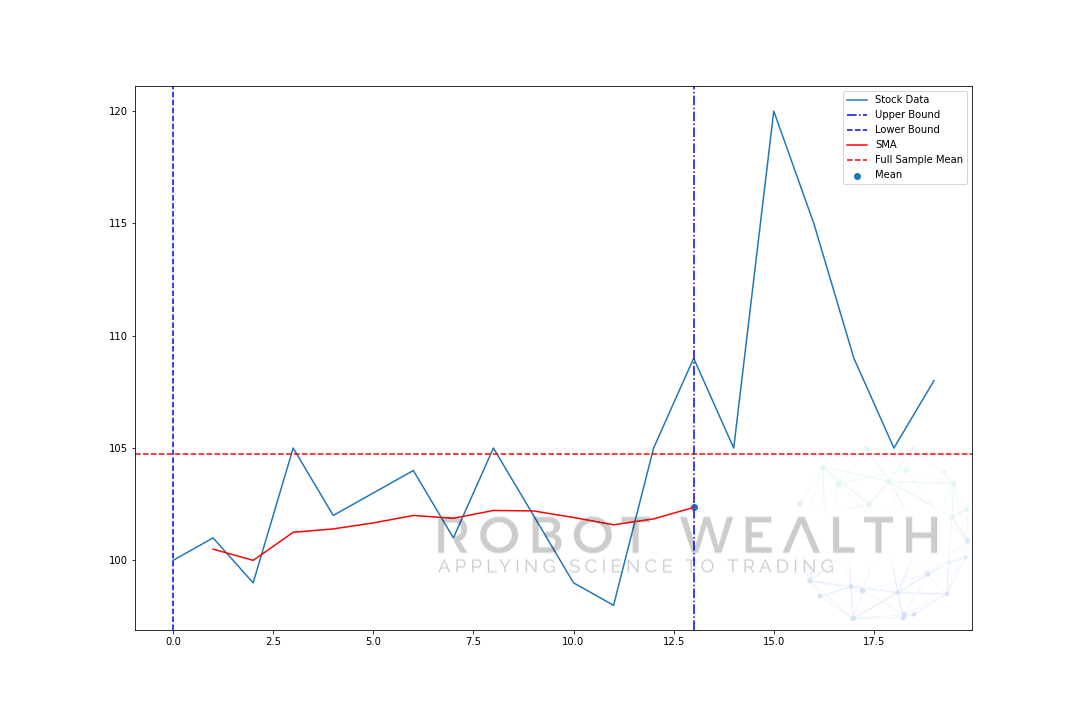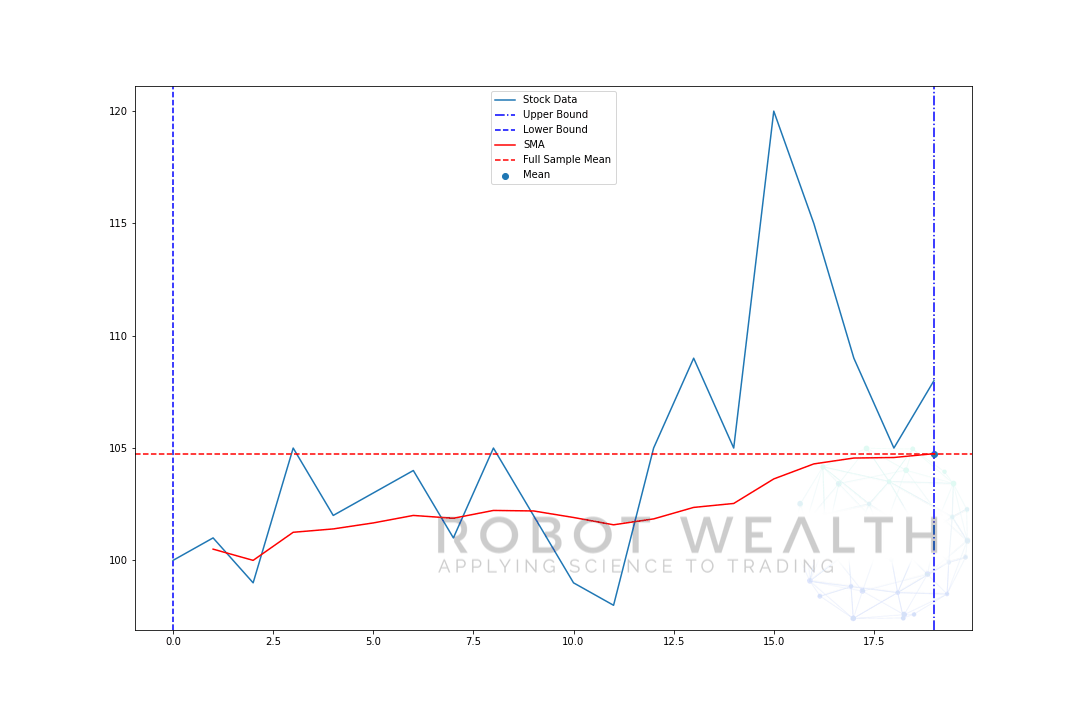
la oss visualisere et eksempel med et bevegelig vindu med størrelse 5 trinnvis.
#Random stock pricesdata = #Create pandas DataFrame from listdf = pd.DataFrame(data,columns=)#Calculate a 5 period simple moving averagesma5 = df.rolling(window=5).mean()#Plotplt.plot(df,label='Stock Data')plt.plot(sma5,label='SMA',color='red')plt.legend()plt.show()
så la oss dele dette diagrammet.
- Vi har 20 dagers aksjekurser i dette diagrammet, merkede Aksjedata.
- For hvert punkt i tid (den blå prikken) vil vi vite hva som er 5 dagers middelpris.
- lagerdataene som brukes til beregningen, er tingene mellom de 2 blå vertikale linjene.
- etter at vi beregner gjennomsnittet fra 0-5, blir vårt gjennomsnitt for dag 5 tilgjengelig.
- for å få gjennomsnittet for dag 6 må vi skifte vinduet med 1 så datavinduet blir 1-6.
og dette er det som kalles Et Rullende Vindu, størrelsen på vinduet er løst. Alt vi gjør er å rulle det fremover.
som du sikkert har lagt merke til, har vi ikke SMA-verdier for poeng 0-4. Dette skyldes at vinduets størrelse (også kjent som en tilbakeblikksperiode) krever minst 5 datapunkter for å gjøre beregningen.
Utvide Vinduer
der rullende vinduer er en fast størrelse, utvide vinduer har et fast utgangspunkt, og innlemme nye data som det blir tilgjengelig.
Her er måten jeg liker å tenke på dette:
«Hva er gjennomsnittet av de siste n-verdiene på dette tidspunktet?»- Bruk rullende vinduer her.
» Hva er gjennomsnittet av alle dataene som er tilgjengelige frem til dette tidspunktet?»- Bruk utvide vinduer her.
Utvidende vinduer har en fast nedre grense. Bare øvre grense av vinduet rulles fremover (vinduet blir større).
la oss visualisere et ekspanderende vindu med de samme dataene fra forrige tomt.
#Random stock prices data = #Create pandas DataFrame from list df = pd.DataFrame(data,columns=) #Calculate expanding window meanexpanding_mean = df.expanding(min_periods=1).mean()#Calculate full sample mean for referencefull_sample_mean = df.mean()#Plot plt.plot(df,label='Stock Data') plt.plot(expanding_mean,label='Expanding Mean',color='red')plt.axhline(full_sample_mean,label='Full Sample Mean',linestyle='--',color='red')plt.legend()plt.show()
DU kan se AT SMA i begynnelsen er litt nervøs. Det er fordi vi har et mindre antall datapunkter i begynnelsen av plottet, og når vi får flere data, utvides vinduet til slutt det ekspanderende vinduet betyr konvergerer til hele prøven, fordi vinduet har nådd størrelsen på hele datasettet.
Sammendrag
det er viktig å ikke bruke data fra fremtiden til å analysere fortiden. Rulle og utvide vinduer er viktige verktøy for å hjelpe «gå dataene fremover» for å unngå disse problemene.
hvis du likte dette vil du sannsynligvis like disse også…
Finansiell Datamanipulering i dplyr for Quant Traders
Bruke Digital Signalbehandling I Kvantitative Handelsstrategier
backtesting bias: Føles Bra, Til du blåser Opp