
Jeśli chodzi o operacjonalizację danych dziennika, HAProxy zapewnia bogactwo informacji. W tym poście na blogu pokazujemy, jak skonfigurować rejestrowanie HAProxy, celować w serwer Syslog, rozumieć pola dziennika i sugerować kilka przydatnych narzędzi do parsowania plików dziennika.
głębokie zanurzenie w logowaniu HAProxy
HAProxy znajduje się w krytycznej ścieżce Twojej infrastruktury. Niezależnie od tego, czy używany jest jako edge load balancer, sidecar, czy jako kontroler Kubernetes ingress, uzyskiwanie znaczących logów z HAProxy jest koniecznością.
Logowanie daje wgląd w każde połączenie i żądanie. Umożliwia obserwację potrzebną do rozwiązywania problemów, a nawet może być używana do wczesnego wykrywania problemów. Jest to jeden z wielu sposobów na uzyskanie informacji od HAProxy. Inne sposoby obejmują uzyskiwanie metryk za pomocą strony statystyk lub interfejsu API Runtime, konfigurowanie alertów e-mail i korzystanie z różnych integracji open-source do przechowywania danych dziennika lub statystyk w czasie. HAProxy zapewnia bardzo szczegółowe dzienniki z dokładnością do milisekund i generuje bogactwo informacji o ruchu przepływającym do Twojej infrastruktury. Obejmuje to:
- metryki dotyczące ruchu: dane czasowe, liczniki połączeń, rozmiar ruchu itp.
- Informacje o decyzjach HAProxy: przełączanie treści, filtrowanie, trwałość itp.
- Informacje o żądaniach i odpowiedziach: nagłówki, kody statusu, ładunki itp.
- Status zakończenia sesji i możliwość śledzenia, gdzie występują awarie (po stronie klienta, po stronie serwera?)
w tym poście dowiesz się, jak skonfigurować logowanie HAProxy i jak odczytać generowane przez nie komunikaty dziennika. Następnie podamy listę narzędzi, które będą pomocne przy operacjonalizacji danych dziennika.
Serwer Syslog
HAProxy może wysyłać komunikaty dziennika do przetwarzania przez serwer syslog. Jest to zgodne ze znanymi narzędziami syslog, takimi jak Rsyslog, a także nowszą usługą systemd journald. Możesz również korzystać z różnych spedytorów dzienników, takich jak Logstash i Fluentd, aby otrzymywać wiadomości Syslog od HAProxy i wysyłać je do centralnego agregatora dzienników.
Jeśli pracujesz w środowisku kontenerów, HAProxy obsługuje natywne Logowanie w chmurze, które pozwala na wysyłanie wiadomości dziennika do stdout i stderr. W takim przypadku przejdź do następnej sekcji, w której zobaczysz, jak to zrobić.
zanim przyjrzysz się, jak włączyć logowanie za pomocą pliku konfiguracyjnego HAProxy, powinieneś najpierw upewnić się, że masz serwer Syslog, taki jak rsyslog, skonfigurowany do odbierania dzienników. Na Ubuntu zainstalowałbyś rsyslog używając menedżera pakietów apt, tak:
Po zainstalowaniu rsyslog, edytuj jego konfigurację, aby obsłużyć przechwytywanie komunikatów dziennika HAProxy. Dodaj następujące elementy do /etc/rsyslog.conf lub do nowego pliku w rsyslog.katalog d, Jak/etc / rsyslog.d / haproxy.conf:
następnie uruchom ponownie usługę rsyslog. W powyższym przykładzie rsyslog nasłuchuje na adresie pętli IP, 127.0.0.1, na domyślnym porcie UDP 514. Ta konkretna konfiguracja zapisuje do dwóch plików dziennika. Wybrany plik jest oparty na poziomie ważności, z którym wiadomość została zalogowana. Aby to zrozumieć, przyjrzyj się bliżej dwóm ostatnim liniom w pliku. Zaczynają się tak:
standard syslog określa, że każdemu zalogowanemu komunikatowi należy przypisać kod obiektu i poziom ważności. Biorąc pod uwagę przykładową konfigurację rsyslog powyżej, możesz założyć,że będziemy konfigurować HAProxy, aby wysyłał wszystkie swoje komunikaty dziennika z kodem local0.
poziom ważności jest określony po kodzie obiektu, oddzielony kropką. Tutaj pierwsza linia przechwytuje wiadomości na wszystkich poziomach ważności i zapisuje je do pliku o nazwie haproxy-traffic.dziennik. Druga linia przechwytuje tylko wiadomości na poziomie powiadomień i powyżej, logując je do pliku o nazwie haproxy-admin.dziennik.
HAProxy jest zakodowany na stałe, aby używać pewnych poziomów ważności podczas wysyłania niektórych wiadomości. Na przykład kategoryzuje komunikaty dziennika związane z połączeniami i żądaniami HTTP z poziomem ważności informacji. Inne zdarzenia są klasyfikowane za pomocą jednego z innych, mniej gadatliwych poziomów. Od najbardziej do najmniej ważnych, poziomy ważności są następujące:
| poziom ważności | HAProxy Logs |
| emerg | błędy, takie jak wyczerpanie deskryptorów plików systemu operacyjnego. |
| alert | niektóre rzadkie przypadki, w których wydarzyło się coś nieoczekiwanego, na przykład brak możliwości buforowania odpowiedzi. |
| crit | nie jest używany. |
| err | błędy, takie jak brak możliwości przeanalizowania pliku mapy, Brak możliwości przeanalizowania pliku konfiguracyjnego HAProxy oraz niepowodzenie operacji na tabeli pamięci podręcznej. |
| Ostrzeżenie | niektóre ważne, ale niekrytyczne błędy, takie jak brak ustawienia nagłówka żądania lub brak połączenia z serwerem nazw DNS. |
| Uwaga | zmienia stan serwera, na przykład w górę lub w dół lub gdy serwer jest wyłączony. Dołączone są również inne zdarzenia podczas uruchamiania, takie jak uruchamianie serwerów proxy i moduły ładowania. Rejestrowanie kontroli stanu, Jeśli jest włączone, również korzysta z tego poziomu. |
| info | szczegóły połączenia TCP i żądania HTTP oraz błędy. | debugowanie | możesz napisać własny kod Lua, który rejestruje wiadomości debugowania |
nowoczesne dystrybucje Linuksa są dostarczane z menedżerem usług systemd, który wprowadza journald do zbierania i przechowywania dzienników. Usługa journald nie jest implementacją Syslog, ale jest kompatybilna z Syslog, ponieważ będzie nasłuchiwać na tym samym gnieździe / dev / log. Pobiera otrzymane logi i pozwala użytkownikowi filtrować je według kodu obiektu i / lub poziomu ważności za pomocą równoważnych pól journald (SYSLOG_FACILITY, PRIORITY).
Konfiguracja logowania HAProxy
instrukcja konfiguracji HAProxy wyjaśnia, że logowanie można włączyć w dwóch krokach: pierwszym jest określenie serwera Syslog w sekcjiglobal za pomocą dyrektywylog:
log div > dyrektywa nakazuje HAProxy wysyłanie logów do serwera syslog nasłuchującego w 127.0.0.1:514. Wiadomości są wysyłane za pomocą facility local0, która jest jedną ze standardowych, zdefiniowanych przez użytkownika funkcji Syslog. Jest to również obiekt, którego oczekuje nasza konfiguracja rsyslog. Możesz dodać więcej niż jedną instrukcję log, aby wysłać dane wyjściowe do wielu serwerów Syslog.
możesz kontrolować, ile informacji jest rejestrowanych, dodając poziom Syslog na końcu linii:
drugim krokiem do skonfigurowania logowania jest aktualizacja różnych serwerów proxy (frontendbackend I listen sekcje), aby wysłać wiadomości do serwera(ów) syslog skonfigurowanego w sekcji global. Odbywa się to poprzez dodanie dyrektywy log global. Możesz dodać go do sekcji defaults, jak pokazano:
dyrektywa log global zasadniczo mówi, Użyj linii log, która została ustawiona w sekcji global. Umieszczenie dyrektywylog global w sekcjidefaults jest równoznaczne z umieszczeniem jej we wszystkich kolejnych sekcjach proxy. Umożliwi to logowanie na wszystkich serwerach proxy. Możesz przeczytać więcej o sekcjach pliku konfiguracyjnego HAProxy w naszym poście na blogu cztery podstawowe sekcje konfiguracji HAProxy.
domyślnie wyjście z HAProxy jest minimalne. Dodanie linii option httplog do sekcji defaults umożliwi bardziej szczegółowe rejestrowanie HTTP, co wyjaśnimy bardziej szczegółowo później.
typowa konfiguracja HAProxy wygląda tak:
używanie globalnych reguł logowania jest najczęstszą konfiguracją HAProxy, ale możesz umieścić je bezpośrednio w sekcjifrontend. Może być przydatne mieć inną konfigurację logowania jako jednorazową. Na przykład możesz wskazać inny docelowy serwer Syslog, użyć innej funkcji rejestrowania lub uchwycić różne poziomy ważności w zależności od przypadku użycia aplikacji zaplecza. Rozważ następujący przykład, w którym sekcje frontend, fe_site1 i fe_site2, ustawiają różne adresy IP i poziomy ważności:
podczas logowania do lokalnej usługi Syslog, zapis do gniazda UNIX może być szybszy niż kierowanie na adres pętli TCP. Ogólnie rzecz biorąc, w systemach Linux Gniazdo UNIX nasłuchujące wiadomości Syslog jest dostępne w /dev / log, ponieważ to tam funkcja syslog () biblioteki GNU C domyślnie wysyła wiadomości. Skieruj Gniazdo UNIX w ten sposób:
jednak powinieneś pamiętać, że jeśli zamierzasz używać gniazda UNIX do logowania i jednocześnie uruchamiasz HAProxy w środowisku chrootowanym—lub pozwolisz HAProxy utworzyć katalog chroot, używając dyrektywy konfiguracyjnej chroot—wtedy Gniazdo UNIX musi być udostępnione w tym katalogu chroot. Można to zrobić na jeden z dwóch sposobów.
Po pierwsze, po uruchomieniu rsyslog, może utworzyć nowe gniazdo nasłuchujące w systemie plików chroot. Dodaj następujący plik konfiguracyjny HAProxy rsyslog:
drugim sposobem jest ręczne dodanie gniazda do systemu plików chroot za pomocą poleceniamount z opcją--bind.
pamiętaj, aby dodać wpis do pliku/etc / fstab lub do pliku jednostki systemd, tak aby montowanie trwało po ponownym uruchomieniu. Po skonfigurowaniu logowania będziesz chciał zrozumieć strukturę wiadomości. W następnej sekcji zobaczysz pola, które tworzą dzienniki poziomu TCP i HTTP.
Jeśli chcesz ograniczyć ilość przechowywanych danych, jednym ze sposobów jest próbkowanie tylko części wiadomości dziennika. Ustaw poziom dziennika na cichy dla losowej liczby żądań, w ten sposób:
zauważ, że jeśli to możliwe, lepiej jest przechwycić jak najwięcej danych. W ten sposób nie masz brakujących informacji, gdy ich najbardziej potrzebujesz. Można również zmodyfikować wyrażenie ACL tak, aby pewne warunki nadpisywały regułę.
innym sposobem ograniczenia liczby rejestrowanych wiadomości jest ustawienieoption dontlog-normal w Twoimdefaults lubfrontend. W ten sposób rejestrowane są tylko limity czasu, powtórzenia i błędy. Prawdopodobnie nie chcesz włączać tego przez cały czas, ale tylko w określonych okresach, na przykład podczas wykonywania testów porównawczych.
Jeśli używasz HAProxy wewnątrz kontenera Docker i używasz HAProxy w wersji 1.9, to zamiast wysyłać dane wyjściowe dziennika do serwera Syslog możesz wysłać je do stdout i/lub stderr. Ustaw adres odpowiednio na stdoutlubstderr. W takim przypadku lepiej jest również ustawić format wiadomości na raw, w ten sposób:
HAProxy Log Format
typ logowania, który zobaczysz, zależy od trybu proxy ustawionego w HAProxy. HAProxy może działać jako serwer proxy warstwy 4 (TCP) lub jako serwer proxy warstwy 7 (HTTP). Tryb TCP jest domyślny. W tym trybie nawiązywane jest połączenie typu full-duplex między klientami a serwerami i nie jest przeprowadzane badanie warstwy 7. Jeśli Ustawiłeś konfigurację rsyslog na podstawie naszej dyskusji w pierwszej sekcji, plik dziennika znajdziesz w /var / log / haproxy-traffic.dziennik.
w trybie TCP, który jest ustawiany przez dodaniemode tcp, należy również dodać opcję tcplog. Dzięki tej opcji format dziennika domyślnie zawiera strukturę, która dostarcza użytecznych informacji, takich jak Szczegóły połączenia warstwy 4, timery, liczba bajtów itp. Jeśli chcesz ponownie utworzyć ten format za pomocą log-format, który jest używany do ustawiania niestandardowego formatu, wyglądałby on następująco:
opisy tych pól można znaleźć w dokumentacji formatu dziennika TCP, chociaż kilka z nich opiszemy w nadchodzącej sekcji.
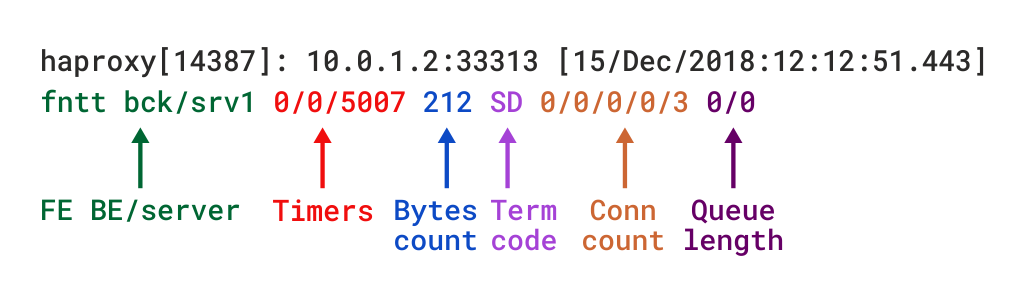
format dziennika TCP w HAProxy
gdy HAProxy jest uruchamiany jako serwer proxy warstwy 7 poprzezmode http, należy dodać opcję dyrektywa httplog. Zapewnia to dogłębną analizę żądań i odpowiedzi HTTP oraz to, że żadna zawartość zgodna z RFC nie zostanie usunięta. Jest to tryb, który naprawdę podkreśla wartość diagnostyczną HAProxy. Format dziennika HTTP zapewnia taki sam poziom informacji jak format TCP, ale z dodatkowymi danymi specyficznymi dla protokołu HTTP. Jeśli chcesz ponownie utworzyć ten format za pomocą log-format, wyglądałoby to tak:
Szczegółowe opisy różnych pól można znaleźć w dokumentacji formatu dziennika HTTP.
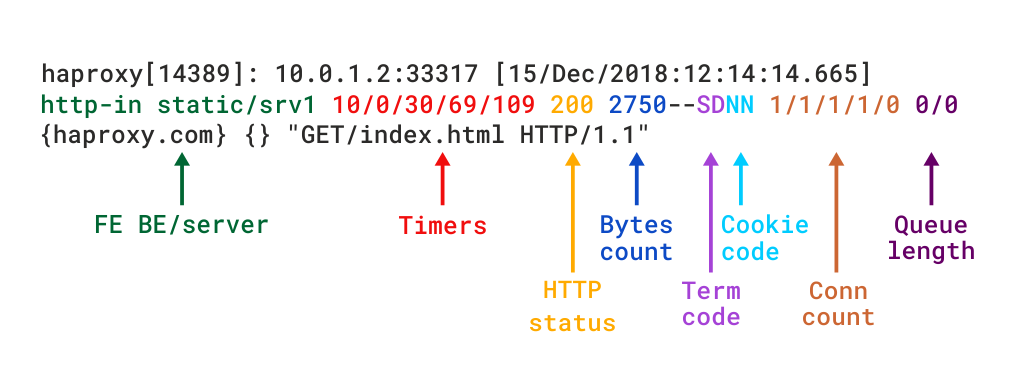
http log format w HAProxy
Możesz również zdefiniować własny format dziennika, przechwytując tylko to, czego potrzebujesz. Użyj dyrektywy log-format (lub log-format-sd dla syslogu danych strukturalnych) w swoim defaults lub frontend. Przeczytaj nasz wpis na blogu Personalizacja logu HAProxy, aby dowiedzieć się więcej i zobaczyć kilka przykładów.
w kilku następnych sekcjach zapoznasz się z polami, które są zawarte, gdy używaszoption tcplog luboption httplog.
Proxy
w wygenerowanym pliku dziennika każda linia zaczyna się od nakładki, zaplecza i serwera, do którego wysłano żądanie. Na przykład, jeśli masz następującą konfigurację HAProxy, zobaczysz linie opisujące żądania jako kierowane przez interfejs http-in do statycznego zaplecza, a następnie do serwera srv1.
staje się to istotną informacją, gdy musisz wiedzieć, gdzie zostało wysłane żądanie, na przykład gdy widzisz błędy, które dotyczą tylko niektórych serwerów.
timery
są dostarczane w milisekundach i obejmują zdarzenia zachodzące podczas sesji. Timery przechwycone przez domyślny format dziennika TCP to Tw / Tc / Tt. Te dostarczane przez domyślny format dziennika HTTP to TR/ Tw / Tc / Tr / Ta. Są one tłumaczone jako:
| Timer | Znaczenie |
| tr | całkowity czas uzyskania żądania klienta (tylko tryb HTTP). |
| Tw | całkowity czas spędzony w kolejkach oczekujących na gniazdo połączenia. |
| Tc | całkowity czas nawiązania połączenia TCP z serwerem. |
| tr | Czas odpowiedzi serwera (tylko tryb HTTP). |
| Ta | całkowity czas aktywności żądania HTTP (tylko tryb HTTP). |
| TT | całkowity czas trwania sesji TCP, między momentem zaakceptowania przez proxy a momentem zamknięcia obu końców. |
szczegółowy opis wszystkich dostępnych timerów znajdziesz w dokumentacji HAProxy. Poniższy diagram pokazuje również, gdzie czas jest rejestrowany podczas pojedynczej transakcji end-to-end. Zauważ, że fioletowe linie na krawędziach oznaczają timery.
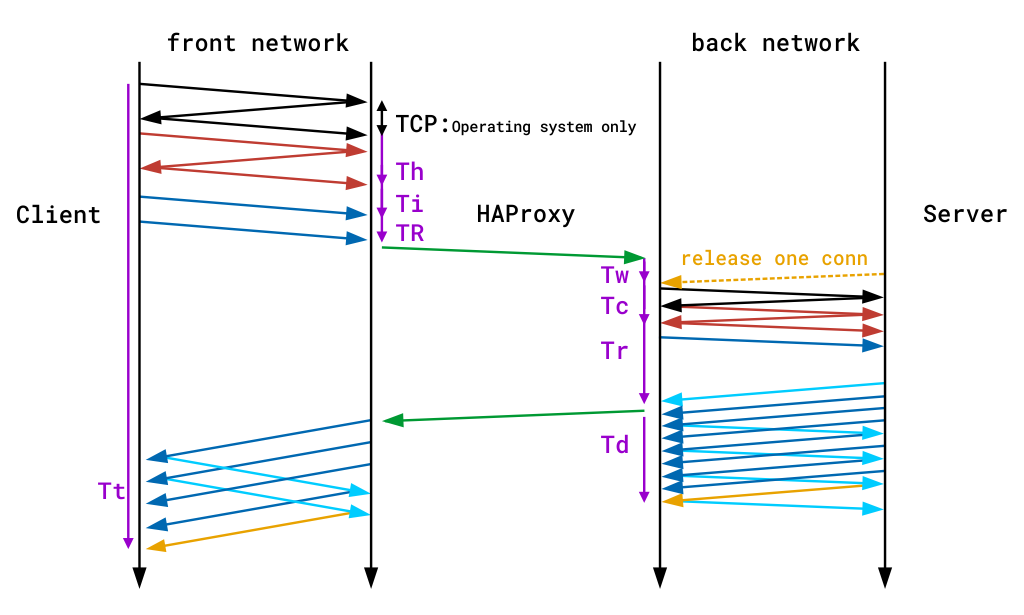
time recording during a single end-to-end transaction
Session State at Disconnection
zarówno logi TCP, jak i HTTP zawierają kod stanu zakończenia, który informuje o sposobie zakończenia sesji TCP lub HTTP. To dwuznakowy kod. Pierwszy znak raportuje pierwsze zdarzenie, które spowodowało zakończenie sesji, podczas gdy drugi raportuje stan sesji TCP lub HTTP podczas jej zamknięcia.
oto kilka przykładów kodu zakończenia:
| Dwuznakowy kod | Znaczenie |
| – | normalne zakończenie po obu stronach. |
| cD | klient nie wysłał ani nie potwierdził żadnych danych i ostatecznie timeout client wygasł. |
| SC | serwer wyraźnie odmówił połączenia TCP. |
| PC | serwer proxy odmówił nawiązania połączenia z serwerem, ponieważ limit gniazd procesu został osiągnięty podczas próby połączenia. |
istnieje wiele powodów, dla których połączenie mogło zostać zamknięte. Szczegółowe informacje na temat wszystkich możliwych kodów zakończenia można znaleźć w dokumentacji HAProxy.
liczniki
liczniki wskazują stan systemu w momencie wysłania żądania. HAProxy rejestruje pięć liczników dla każdego połączenia lub żądania. Mogą być nieocenione w określaniu, ile obciążenia jest umieszczane w systemie, gdzie system jest opóźniony i czy limity zostały przekroczone. Patrząc na linię w dzienniku, zobaczysz liczniki wymienione jako pięć liczb oddzielonych ukośnikami: 0/0/0/0/0.
w trybie TCP lub HTTP rozkładają się one jako:
- całkowita liczba jednoczesnych połączeń w procesie HAProxy podczas rejestrowania sesji.
- całkowita liczba jednoczesnych połączeń kierowanych przez to
frontendpodczas rejestrowania sesji. - całkowita liczba jednoczesnych połączeń kierowanych do tego
backendpodczas rejestrowania sesji. - całkowita liczba jednoczesnych połączeń nadal aktywnych na tym
server, gdy sesja była rejestrowana. - liczba prób powtórzenia podczas próby połączenia z serwerem zaplecza.
inne pola
HAProxy nie rejestruje wszystkiego po wyjęciu z pudełka, ale możesz go dostosować, aby uchwycić to, czego potrzebujesz. Nagłówek żądania HTTP może być rejestrowany przez dodanie dyrektywyhttp-request capture:
dziennik pokaże nagłówki między nawiasami klamrowymi i oddzielone symbolami potoku. Tutaj możesz zobaczyć nagłówki Host i User-Agent dla żądania:
nagłówek odpowiedzi może być rejestrowany przez dodanie dyrektywyhttp-response capture:
w tym przypadku należy również dodać dyrektywędeclare capture response, która przydziela Gniazdo przechwytywania, w którym nagłówek odpowiedzi może być przechowywany po jego przybyciu. Każdemu dodanemu slotowi automatycznie przypisywany jest identyfikator zaczynający się od zera. Reference this ID when calling http-response capture. Nagłówki odpowiedzi są rejestrowane po nagłówkach żądania, w oddzielnym zestawie nawiasów klamrowych.
wartości plików Cookie można rejestrować w podobny sposób za pomocą dyrektywyhttp-request capture.
wszystko przechwycone za pomocąhttp-request capture, w tym nagłówki HTTP i pliki cookie, pojawi się w tym samym zestawie nawiasów klamrowych. To samo odnosi się do wszystkiego przechwyconego za pomocą http-response capture.
Możesz również użyćhttp-request capture do logowania próbkowanych danych z tabel stick. Jeśli śledzisz stawki żądań użytkowników za pomocą stick-table, możesz je zapisać w następujący sposób:
więc złożenie żądania na stronie internetowej zawierającej dokument HTML i dwa obrazy pokazywałoby współbieżną szybkość żądania użytkownika zwiększoną do trzech:
Możesz również rejestrować wartości metod pobierania, np. do zapisu wersji SSL/TLS, która została użyta (zauważ, że istnieje wbudowana zmienna dziennika o nazwie %sslv):
zmienne ustawione za pomocą http-request set-var mogą być również rejestrowane.
wyrażenia ACL obliczają wartość true lub false. Nie można logować ich bezpośrednio, ale można ustawić zmienną na podstawie tego, czy wyrażenie jest prawdziwe. Na przykład, jeśli użytkownik odwiedza /api, możesz ustawić zmienną o nazwie req. is_api na wartość is API, a następnie przechwycić ją w dziennikach.
Włączanie profilowania HAProxy
wraz z wydaniem HAProxy 1.9 możesz rejestrować czas procesora spędzony na przetwarzaniu żądania w HAProxy. Dodaj dyrektywę profiling.tasks do sekcji global:
istnieją nowe metody pobierania, które ujawniają metryki profilowania:
| metoda pobierania | opis |
| mikrosekundowa część daty. | |
| liczba wywołań zadania przetwarzającego strumień lub bieżące żądanie od momentu jego przydzielenia. Jest resetowany dla każdego nowego żądania na tym samym połączeniu. | |
| średnia liczba nanosekund spędzonych w każdym wywołaniu zadania przetwarzającego strumień lub bieżące żądanie. | |
| całkowita liczba nanosekund spędzonych w każdym wywołaniu zadania przetwarzającego strumień lub bieżące żądanie. | |
| średnia liczba nanosekund spędzonych między momentem obudzenia zadania obsługującego strumień a momentem jego skutecznego wywołania. | |
| całkowita liczba nanosekund pomiędzy momentem obudzenia zadania obsługującego strumień a momentem jego skutecznego wywołania. |
dodaj je do swoich wiadomości dziennika w następujący sposób:
jest to świetny sposób, aby ocenić, które żądania kosztują najwięcej do przetworzenia.
parsowanie logów HAProxy
Jak się nauczyłeś, HAProxy ma wiele pól, które zapewniają ogromną ilość wglądu w połączenia i żądania. Jednak czytanie ich bezpośrednio może prowadzić do przeciążenia informacji. Często łatwiej jest je analizować i agregować za pomocą zewnętrznych narzędzi. W tej sekcji zobaczysz niektóre z tych narzędzi i jak mogą one wykorzystać informacje logowania dostarczane przez HAProxy.
HALog
HALog to małe, ale potężne narzędzie do analizy logów, które jest dostarczane z HAProxy. Został zaprojektowany do wdrożenia na serwerach produkcyjnych, gdzie może pomóc w ręcznym rozwiązywaniu problemów, na przykład w przypadku problemów na żywo. Jest niezwykle szybki i potrafi analizować dzienniki TCP i HTTP z prędkością od 1 do 2 GB na sekundę. Przekazując kombinację FLAG, możesz wyodrębnić informacje statystyczne z dzienników, w tym żądania na adres URL i żądania na adres IP źródła. Następnie możesz sortować według czasu odpowiedzi, współczynnika błędów i kodu zakończenia.
na przykład, jeśli chcesz wyodrębnić statystyki poszczególnych serwerów z dzienników, możesz użyć następującego polecenia:
jest to przydatne, gdy trzeba przeanalizować linie dziennika według kodu stanu i szybko odkryć, czy dany serwer jest niezdrowy (np. zwracając zbyt wiele odpowiedzi 5xx). Lub serwer może odmawiać zbyt wielu żądań (odpowiedzi 4xx), co jest oznaką ataku brute-force. Możesz również uzyskać średni czas odpowiedzi na serwer za pomocą kolumnyavg_rt, która jest pomocna w rozwiązywaniu problemów.
dzięki HALog możesz uzyskać statystyki dla poszczególnych adresów URL za pomocą następującego polecenia:
wyjście pokazuje liczbę żądań, liczbę błędów, całkowity czas obliczeniowy, średni czas obliczeniowy, całkowity czas obliczeniowy pomyślnych żądań, średni czas obliczeniowy pomyślnych żądań, średnią liczbę wysłanych bajtów i całkowitą liczbę wysłanych bajtów. Oprócz analizowania statystyk serwera i adresu URL, możesz zastosować wiele filtrów do dopasowania dzienników z danym czasem odpowiedzi, kodem stanu HTTP, kodem zakończenia sesji itp.
strona statystyk HAProxy
parsowanie dzienników za pomocą HALog nie jest jedynym sposobem na uzyskanie metryk z HAProxy. Strona statystyk HAProxy może być włączona przez dodanie dyrektywy stats enable do sekcji frontend lub listen. Wyświetla statystyki na żywo Twoich serwerów. Sekcja listen rozpoczyna nasłuchiwanie strony statystyk na porcie 8404:
strona statystyk jest bardzo przydatna do uzyskiwania natychmiastowych informacji o ruchu przepływającym przez HAProxy. Nie przechowuje jednak tych danych i wyświetla dane tylko dla pojedynczego Load balancera.
Pulpit Nawigacyjny HAProxy Enterprise w czasie rzeczywistym
Jeśli używasz HAProxy Enterprise, masz dostęp do Pulpitu Nawigacyjnego w czasie rzeczywistym. Podczas gdy strona statystyki pokazuje statystyki dla pojedynczej instancji HAProxy, Pulpit nawigacyjny w czasie rzeczywistym agreguje i wyświetla informacje w klastrze równoważenia obciążenia. Ułatwia to obserwowanie kondycji wszystkich serwerów z jednego ekranu. Dane można przeglądać do 30 minut.
pulpit nawigacyjny przechowuje i wyświetla informacje o kondycji usługi, stawkach żądań i obciążeniu. Ułatwia również wykonywanie zadań administracyjnych, takich jak włączanie, wyłączanie i opróżnianie zaplecza. Na pierwszy rzut oka możesz zobaczyć, które serwery działają i na jak długo. Możesz także wyświetlić dane stick table, które w zależności od tego, co śledzi stick table, mogą wyświetlać wskaźniki błędów, stawki żądań i inne informacje w czasie rzeczywistym o użytkownikach. Dane Stick table mogą być również agregowane.
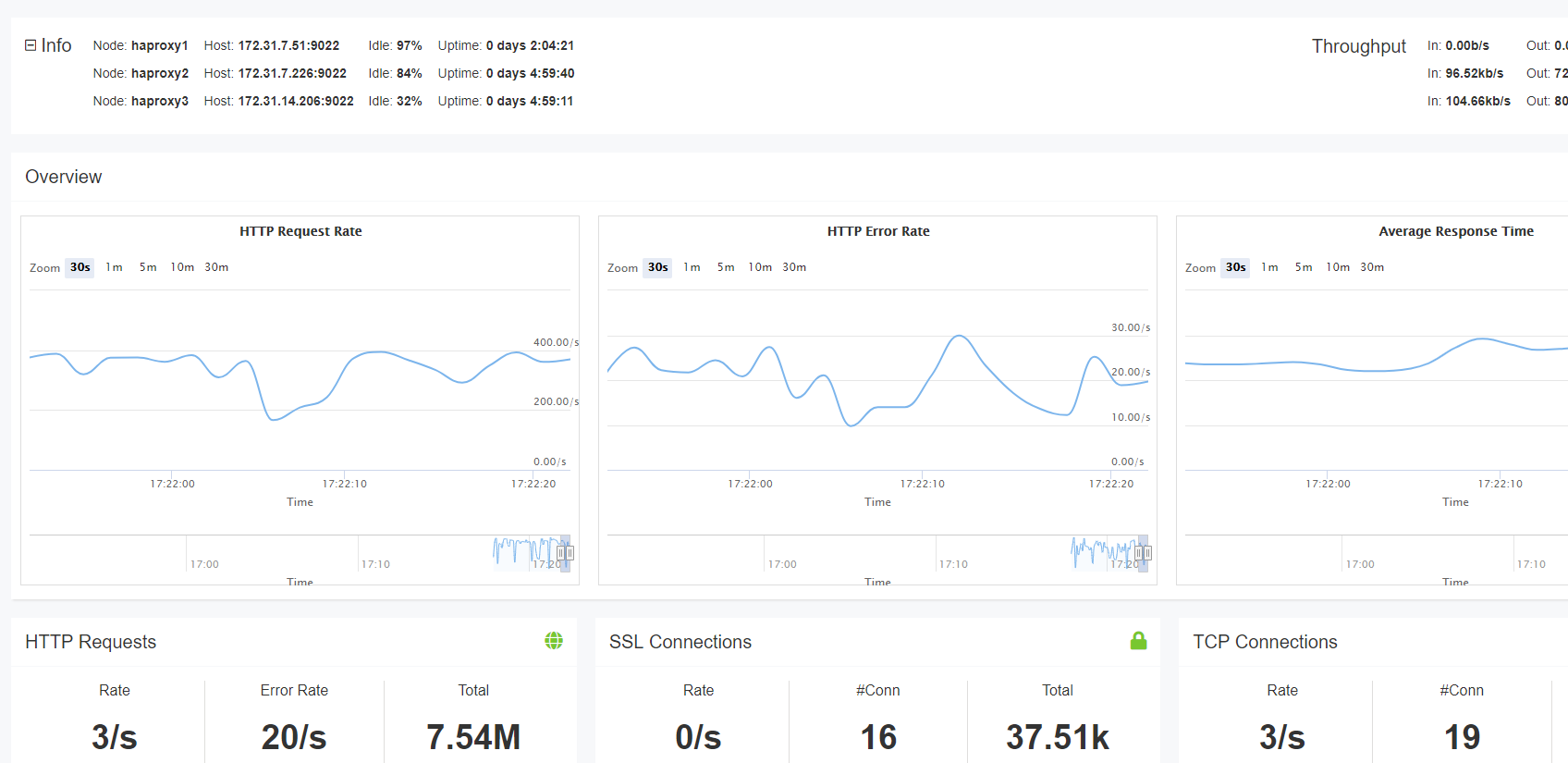
Pulpit nawigacyjny w czasie rzeczywistym w HAProxy Enterprise
Pulpit nawigacyjny w czasie rzeczywistym jest jednym z wielu dodatków dostępnych w HAProxy Enterprise.
podsumowanie
w tym poście na blogu nauczyłeś się, jak skonfigurować rejestrowanie HAProxy, aby uzyskać widoczność nad Twoim load balancer, który jest kluczowym komponentem w Twojej infrastrukturze. HAProxy emituje szczegółowe komunikaty Syslog podczas pracy w trybie TCP i HTTP. Mogą one być wysyłane do wielu narzędzi rejestrujących, takich jak rsyslog.
HAProxy jest dostarczany z narzędziem wiersza poleceń HALog, które upraszcza przetwarzanie danych dziennika, gdy potrzebujesz informacji o typach odpowiedzi otrzymywanych przez użytkowników i obciążeniu serwerów. Możesz również uzyskać obraz stanu swoich serwerów za pomocą strony statystyk HAProxy lub Pulpitu Nawigacyjnego HAProxy Enterprise w czasie rzeczywistym.
chcesz wiedzieć kiedy taka treść zostanie opublikowana? Zapisz się do tego bloga lub Śledź nas na Twitterze. Możesz również dołączyć do rozmowy na Slack! HAProxy Enterprise łączy HAProxy z funkcjami klasy korporacyjnej, takimi jak Pulpit nawigacyjny w czasie rzeczywistym i wsparcie premium. Skontaktuj się z nami, aby dowiedzieć się więcej lub zapisz się na bezpłatny okres próbny już dziś!