o objetivo deste artigo é explicar a redundância em termos de computação, rede e hospedagem. Forneceremos exemplos reais de soluções tecnológicas redundantes para ilustrar o que é a redundância e como ela funciona.
Atlantic.Net criou vários ambientes de hospedagem, incluindo uma plataforma de nuvem durável, hospedagem VPS de alta velocidade, infra-estrutura compatível com HIPAA, e gerenciou hospedagem privada em nuvem. Todos os nossos sistemas são construídos com redundância como um fator principal de condução do processo de design.
em Inglês diário, a redundância pode ter uma conotação negativa; algo redundante geralmente não é necessário ou considerado supérfluo. No entanto, em um ambiente de hospedagem em nuvem, redundância pode significar a diferença entre disponibilidade de sistema sem costura e tempo de inatividade indesejado ou inesperado.o que é um sistema redundante?
um sistema redundante irá fornecer suporte de compensação de falhas ou cargas para proteger um sistema ao vivo em caso de falha inesperada. Em caso de falha de energia, mecânica ou de software, um sistema redundante terá um componente ou plataforma duplicado para onde voltar. Em geral, qualquer componente de um sistema com um único ponto de falha pode ser visto como um risco para os Serviços de produção.
Sistemas de potência ou mecânicos têm estratégias de recuo mais simples, exigindo a mera presença de outro do mesmo tipo de serviço; falhas de software geralmente requerem configuração extra no sistema hospedeiro ou um mestre ou gateway.as capacidades de redundância são recomendadas para qualquer sistema crítico de negócios, mas particularmente para sistemas que têm um impacto significativo durante o tempo de inatividade. Algumas empresas podem manter todas as suas informações críticas ao cliente em um banco de dados; portanto, para fins de continuidade de Negócio, proteger esse banco de dados com redundância irá proteger a integridade de dados em caso de uma falha catastrófica.
- tipos de sistemas redundantes
- Exemplos de Software Redundante Serviços
- A réplica Hiper-V
- Hyper-V Clustering
- HAProxy
- Heartbeat
- exemplos de Serviços de Hardware redundantes
- RAID
- redundância de rede
- primeiros protocolos de redundância do Hop (FHRP)
- Virtual Router Redundancy Protocol (VRRP)
- Hot Standby Router Protocol (HSRP)
- Gateway Load Balancing Protocol (GLBP)
- redundância do centro de dados
- conclusão
tipos de sistemas redundantes
um sistema redundante consiste em, pelo menos, dois sistemas interligados e concebidos para o mesmo fim. Existem muitos tipos diferentes de Configurações redundantes do sistema disponíveis, e diferentes implementações do sistema fornecem abordagens únicas de como manter um sistema em cima em todos os momentos.
nem todos os servidores precisam ser configurados com redundância; em vez disso, apenas os mais críticos devem ser considerados. Recomendamos uma avaliação detalhada do risco para entender quais servidores estão no escopo e a quantidade máxima de tempo de inatividade que seus servidores podem lidar. Utilizar esta avaliação para determinar uma estratégia RTO (objectivo do tempo de recuperação) e RPO (objectivo do ponto de recuperação). RTO é a quantidade máxima de tempo de inatividade aceitável. Isto pode variar de 5 segundos a 24 horas. O RPD é o ponto no tempo a partir do qual você precisa de seus dados; por exemplo, seu negócio pode funcionar com uma perda máxima de 24 horas de dados.
Aqui estão alguns exemplos populares:
- activo-inactivo/A Quente-Frio – Quando um componente de um sistema é o sistema activo e outro está inactivo ou desligado. O componente inativo só é ativado quando o componente em execução de momento falha ou sofre manutenção
- Ativo-Ativo/quente-quente – quando ambos os sistemas estão vivos e fazendo conexões. Isto é mais conhecido como agrupamento. Normalmente, o dispositivo na frente de ambas as máquinas irá determinar como dividir o tráfego de entrada
- Active-Standby/Hot-Warm – quando ambos os sistemas estão ligados, mas apenas um está a fazer ligações. O segundo sistema é destinado a receber periodicamente atualizações ou backups do sistema primário. Em caso de falha, o sistema em standby assume o papel principal até que o sistema inicial possa ser recuperado.
cada tipo tem os seus prós e contras.
- Active-inative / Hot-Cold systems can provide a simple redundant platform, but any failover will result in users seeing an older version of the system.
- Active-Active/Hot-Hot exigirá uma actualização constante de ambos os sistemas, quer manualmente, quer através de um serviço separado, para garantir que todos os utilizadores possam utilizar qualquer um dos sistemas. Esta abordagem pode reduzir fortemente a carga ativa em um serviço que você está fornecendo aos clientes.
- Active-Standby/Hot-Warm irá fornecer as capacidades de failover do hot-cold com uma cópia mais actualizada do seu sistema activo na falha, mas não fornece qualquer alívio da carga.
outras formas de redundância de múltiplos nós estão disponíveis que permitem maior redundância e soluções robustas de balanceamento de carga. Nesse ponto, você terá um grupo de alta disponibilidade, também conhecido como um grupo HA.
isto pode usar qualquer combinação das soluções de redundância anteriormente mencionadas com a máxima flexibilidade na abordagem ou quantidade de redundância necessária. Ha clusters também podem ser criados em vários locais físicos para permitir a disponibilidade até o nível de backbone da internet.
Exemplos de Software Redundante Serviços
Curta de baixa disponibilidade de recursos, há muito pouca razão para não ter de replicação de propriedade ou redundantes serviços em um ambiente virtual; assim, muitos destes serviços estão disponíveis por padrão na maioria dos sistemas de virtualização. Todos os nossos serviços na nuvem têm replicação disponível, uma característica que nos permite replicar qualquer servidor de um nó para outro, quer estejam no mesmo centro de dados ou em regiões separadas do centro de dados.
A réplica Hiper-V
a réplica Hiper-V é uma forma de redundância quente. Uma máquina virtual primária é criada em um host físico e aceita conexões de entrada. Ao permitir a replicação,os discos rígidos virtuais da nova máquina são transferidos para um host físico separado Hyper-V. Este host configura então um VM em si mesmo que se replica em um programa definido pelo Usuário para garantir que a imagem mais recente do servidor ativo é tomada. Pontos de controle adicionais também podem ser mantidos. Hyper-V hospedagem privada com serviços gerenciados é fornecido por Atlantic.Net com este recurso cozido em; Contate nossa equipe para mais informações.
Hyper-V Clustering
Hyper-V is also capable of clustering through a connection to other Hyper-V. hosts. VMs em qualquer host Hyper-V pode ser agrupado em conjunto naquele host singular para fornecer redundância em um nível local através de rede virtual.
Microsoft Network Load balanceamento (NLB) pode ser usado para criar um único recurso composto por várias máquinas que compartilham a mesma informação para fornecer um ponto de acesso simples para a partilha de arquivos. Uma vez que este é limitado apenas pela quantidade de recursos que você tem disponíveis, você pode teoricamente configurar vários hosts com VMs múltiplos para redundância máxima, o que também lhe permitiria realizar manutenção em VMs individuais sem sacrificar o serviço ou disponibilidade de recursos. Hyper-V hospedagem privada com serviços gerenciados é fornecido por Atlantic.Net com este recurso cozido em; Contate nossa equipe para mais informações.
HAProxy
além de Hyper-V, um dispositivo de gateway, como uma firewall pode ser usado para serviços de compensação de cargas ou falhas. Por exemplo, Atlantic.Net pode fornecer pfSense com Proxy de Alta Disponibilidade, também conhecido como HAProxy.
HAProxy will act as a load balancer, a proxy, or a simple hot-warm high availability solution for TCP and HTTP-based applications. HAProxy é uma solução de código aberto muito popular, baseada em Linux, usada por alguns dos sites mais visitados do mundo.
Heartbeat
Heartbeat é um serviço disponível na maioria das distribuições do Linux que é usado para determinar se os nós em um cluster ainda estão ligados ou responsivos. É muito simples de configurar e fornece capacidades de failover para qualquer sistema que funcione sobre TCP.
os desenvolvedores do Heartbeat também recomendam outros gerentes de recursos de cluster que iniciam ou param os serviços com base em se um determinado host está em baixo. O batimento cardíaco está incluído, mas outros gerentes estão disponíveis. Devido à simplicidade do batimento cardíaco, é altamente personalizável. Plataformas de hospedagem em nuvem fornecidas por Atlantic.Net já temos este recurso cozido, e podemos ajudá-lo com a implementação do batimento cardíaco na sua própria distribuição privada Linux, se necessário.
exemplos de Serviços de Hardware redundantes
a melhor parte sobre hardware redundante é a sua simplicidade. Enquanto os Serviços de software podem exigir configuração excessiva e são possivelmente bastante sensíveis, o hardware é geralmente muito simples de configurar e incrivelmente durável. O primeiro exemplo que vamos analisar é a tecnologia RAID amplamente utilizada.
RAID
RAID representa uma matriz redundante de discos independentes (ou uma matriz redundante de discos baratos, dependendo de quanto tempo você está usando) e tem vários níveis usados tanto para proteção de dados ou aumento do disco I/O
RAID pode ser configurado através de um software ou controlador de hardware. O controlador tem o software e configuração necessários para gerenciar os discos RAID. A configuração pode ser exportada para diferentes sistemas com pouca ou nenhuma configuração adicional.
RAID pode ser configurado de algumas maneiras diferentes para fornecer um bom equilíbrio de ambas as suas qualidades:
- RAID 0 – isto é essencialmente nenhuma redundância. Nenhum disco no sistema compartilha dados através de espelhamento, mas todos os dados são listados através de cada disco proporcionando maior velocidade de leitura/escrita. Cada unidade ainda pode usar o armazenamento fornecido a ele ao máximo, o que significa que quanto mais unidades você adicionar a um RAID 0, mais espaço você terá.
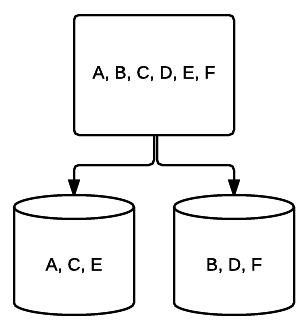
- RAID 1 – UMA forma básica de espelhamento de proporcionar uma excelente redundância no custo do espaço. Em um sistema de duas unidades, uma cópia completa dos dados em uma unidade é escrita para a outra. Esta redundância é reforçada com cada unidade adicionada. Uma vez que todos os dados devem ser espelhados em todas as unidades, o espaço total no sistema será limitado apenas ao espaço da menor unidade no sistema.
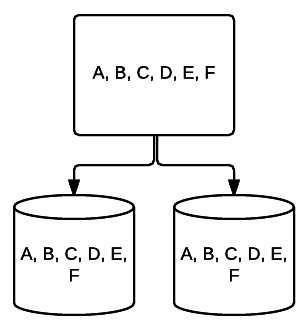
- RAID 5 – Esta forma de ataque é geralmente usado para aumentar a velocidade de leitura e confiabilidade. Neste caso, listras são colocadas sobre cada unidade no sistema, com o mínimo sendo 3 unidades. Ao mesmo tempo, um bloco extra de dados corrigindo erros é colocado sobre cada unidade em uma técnica chamada paridade. Isto verifica se os dados são alterados ao transferir de uma unidade para outra. Isso também fornece uma forma mínima de redundância, uma vez que 1 dessas unidades pode falhar e o sistema ainda pode funcionar. Quanto mais unidades adicionadas a este tipo de configuração RAID, mais sua velocidade de leitura aumenta. Com redundância mínima e listagem em todas as unidades, a quantidade total de espaço nesta configuração é igual ao tamanho de seu volume RAID lógico vezes o número de unidades que você usa, menos um. Por exemplo, se você tem 5 500 GB drives em um RAID 5, Você teria 2000 GB utilizável, ou 2 TB (500 *(5-1)=2000).
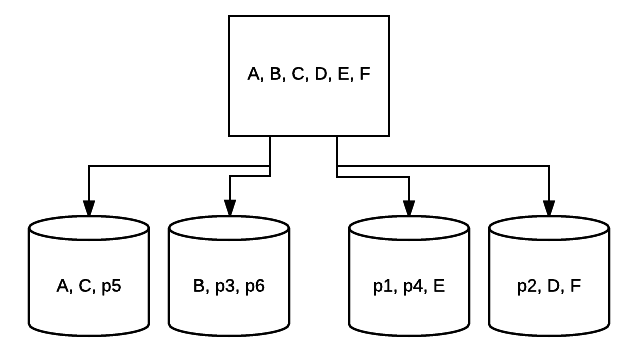
- RAID 10 – Esta é uma combinação de RAID 1 e RAID 0. Neste caso, todos os dados são listados em cada dispositivo com blocos de dados também sendo espelhados em toda a totalidade do sistema listrado. Por exemplo, em um 4 drive RAID 10 sistema 2 500 GB unidades podem ter os mesmos dados, mas não todos os dados necessários para o sistema funcionar corretamente. 2 dados de outras unidades seriam necessários. Pense em cada sistema RAID 1 como uma única unidade, e cada um desses sistemas colocados em uma matriz RAID 0. Nesta configuração, o desempenho pode ser drasticamente aumentado como no RAID 0, com alguma redundância ainda no lugar com o espelhamento. Até metade das unidades no sistema pode falhar antes que o sistema cai, mas como com qualquer matriz redundante, é melhor substituir unidades o mais rápido possível. Atlantic.Net usa o RAID 10 para todo o armazenamento de VPS na nuvem SSD.
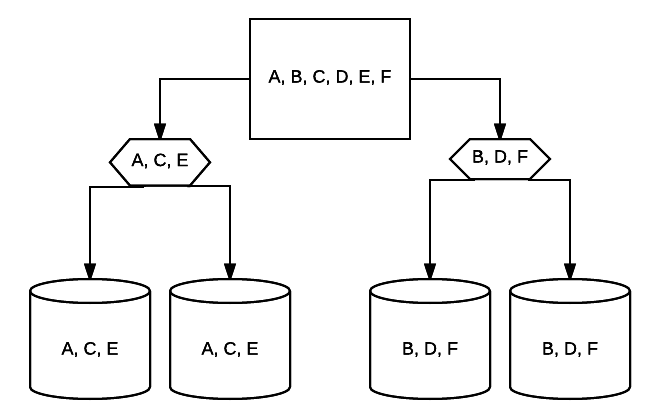
Para protecção adicional, os controladores de RAID estão protegidas por uma bateria de backup de unidades que o poder ROM fichas utilizadas para salvar a configuração na memória em caso de perda de potência, etc. Um BBU irá fornecer energia para um array RAID que faz parte de um sistema desligado por um pequeno período de tempo, permitindo que o conteúdo do cache de um controlador RAID permaneça intacto. Isto pode ser um salva-vidas se a informação está constantemente sendo introduzida em seu array RAID e qualquer tempo de inatividade pode causar corrupção de dados.assim, o seu sistema físico e os serviços internos podem ser construídos redundantemente de forma bastante adequada. Mas e a sua ligação a qualquer parte do seu sistema? Como em, a sua ligação directa à internet com o seu sistema como um todo?
redundância de rede
primeiros protocolos de redundância do Hop (FHRP)
em contraste com os protocolos dinâmicos de descoberta de gateway, gateways estáticos permitem lúpulo simples entre o cliente e a sua gateway apropriada, mas isso cria um único ponto de falha – nomeadamente a gateway propriamente dita.
para prevenir ou reduzir o impacto da falha do gateway, FHRPs foram criados. Eles fornecem gateways redundantes um recuo, ou oferecem balanceamento de carga para sistemas de tráfego elevado, juntamente com redundância. Estes protocolos incluem VRRP, HSRP e GLBP.
Virtual Router Redundancy Protocol (VRRP)
VRRP é uma forma de redundância usada para roteadores que requer pelo menos dois roteadores fisicamente separados conectados através de ligações Ethernet ou fibra óptica. Nesta situação, um’ roteador virtual ‘ contendo rotas estáticas é criado e compartilhado entre cada sistema.
um sistema é considerado o ‘ master ‘e outro o’backup’. Quando o mestre falha, o backup assume como o próximo mestre. Isto pode ser configurado com múltiplos backups para redundância extra. O conceito é muito semelhante ao batimento cardíaco em que os sistemas de backup irá verificar para ver se o mestre está disponível. Uma vez que não recebe uma resposta, após uma quantidade pré-determinada de tempo, o backup assumirá o controle do interruptor virtual e aceitará conexões para todos os pedidos que vêm para o IP padrão configurado para o interruptor principal.
Hot Standby Router Protocol (HSRP)
HSRP é como VRRP; no entanto, neste cenário, o switch virtual configurado não é um “switch”, mas sim um grupo lógico de vários roteadores. O IP do grupo é um IP não atribuído a um host físico. Em vez disso, ao grupo é atribuído um IP e um dos roteadores é determinado para ser o roteador ‘ativo’.
um roteador de standby está pronto para tomar quaisquer conexões caso o roteador ativo desça. Todos os roteadores, além do ativo e do standby, estão todos à escuta para determinar o seu lugar na linha. HSRP é um protocolo proprietário da Cisco e tem muito poucas, pequenas diferenças para VRRP, como seus timers padrão determinando quando falhar. HSRP tem sido em torno de um pouco mais longo e é mais bem conhecido em comparação com VRRP.
Gateway Load Balancing Protocol (GLBP)
GLBP’s main advantage over HSRP and VRRP is its ability to load balance on top of providing redundancy to a gateway with little to no extra configuration. Assim como HSRP e VRRP, o GLBP irá criar um grupo entre roteadores físicos e determinar um Gateway Virtual ativo, ou AVG.
um IP virtual não usado atualmente por nenhum dos roteadores do grupo é atribuído ao AVG. O AVG então distribui endereços MAC virtuais entre os outros roteadores do grupo. Cada roteador de backup é agora considerado um transitário Virtual ativo, ou AVF.
ARP pedidos enviados para o AVG irá fornecer um endereço virtual MAC diferente para o cliente que envia o pedido. Nesse ponto, o tráfego desse cliente para o IP virtual do grupo encaminha-se para o roteador cujo endereço MAC virtual eles receberam, permitindo que cada roteador ainda seja usado em vez de ficar parado.
no caso de uma falha do AVG, eleição baseada em prioridade ocorre, assim como no HSRP e VRRP, e o próximo backup toma seu lugar, distribuindo endereços MAC virtuais como normal. Os outros roteadores ainda mantêm o endereço MAC virtual fornecido pelo AVG original e as coisas continuam como normais. Em caso de falha de um dos AVFs, o AVG impedirá o tráfego de encaminhamento para o seu endereço MAC virtual.
assim como HSRP, GLBP é uma forma proprietária da Fhrp da Cisco.
redundância do centro de dados
além de medidas de redundância para seus servidores pessoais ou roteadores, os centros de dados são projetados para ser resilientes à falha do sistema. Data centers fall under tiers defined by the Uptime Institute to provide fault tolerance for failure of any mechanical or service failure, allowing for as much uptime as possible.
Existem quatro níveis, cada um baseado no outro para proporcionar alta disponibilidade a todos os clientes dentro de um centro de dados:
- Nível I-capacidade básica: Isso requer espaço para um grupo de TI para operações de centros de dados, uma fonte de alimentação ininterrupta (UPS) que monitora e filtra o uso de energia e equipamentos de refrigeração dedicados que está constantemente funcionando 24/7. Isto também inclui um gerador de energia em caso de falha de energia elétrica.componentes de capacidade redundantes da fase II: tudo o que a fase I fornece, mais potência e arrefecimento redundantes para a instalação. Isto pode incluir unidades extra UPS ou geradores extras.
- Nível III – concomitantemente: Tudo o que a Tier II oferece, além de equipamentos extras no lugar para evitar qualquer necessidade de paralisações para substituição ou manutenção de equipamentos. Neste nível, potência redundante e resfriamento são aplicados diretamente a todos os equipamentos técnicos, e o próprio equipamento é configurado para redundância ou falha contínua.Nível IV-tolerância à falha: tudo o que o Nível III oferece, mais serviço ininterrupto a nível do prestador. Enquanto um centro de dados pode ter eletricidade ou água fornecida por um provedor da cidade ou do estado, uma linha secundária de cada serviço utilizado pelo centro de dados é necessária. Isto inclui o ISP também. No caso de uma falha em qualquer seção que leva até o equipamento do cliente, há um plano de backup no lugar pronto para uma transição sem descontinuidades.
conclusão
redundância tornou-se um termo diário na indústria de TI devido à necessidade. A alta disponibilidade de serviços proporciona uma experiência fácil e confiável para os nossos clientes.
se no nível de serviço ou no nível de centro de dados, proporcionando redundância para o seu sistema é uma questão importante e difícil de resolver. Esperemos que este documento esclareça as opções disponíveis e ajude em quaisquer decisões tomadas em relação à elevada disponibilidade a avançar.
pronto para aproveitar Atlantic.Net sistemas redundantes? Contacte-nos hoje para saber mais sobre o Servidor Dedicado de Hospedagem com Atlantic.Net.
===Fontes===
Sistema Redundante Conceitos Básicos: http://www.ni.com/white-paper/6874/en/
Frio/Morno/Quente Servidor: http://searchwindowsserver.techtarget.com/definition/cold-warm-hot-server
de Alta Disponibilidade do Cluster: https://www.mulesoft.com/resources/esb/high-availability-cluster
o Hyper-V Réplica: https://technet.microsoft.com/en-us/library/jj134172(v=ws.11).aspx
Hyper-V and High Availability: https://technet.microsoft.com/en-us/library/hh127064.aspx
HAProxy Description: http://www.haproxy.org/#desc
HAProxy – They use it!: http://www.haproxy.org/they-use-it.html
Heartbeat: http://www.linux-ha.org/wiki/Main_Page
RAID Definition: http://searchstorage.techtarget.com/definition/RAID
Striping: http://searchstorage.techtarget.com/definition/disk-striping
RAID Battery Backup Units: https://www.thomas-krenn.com/en/wiki/Battery_Backup_Unit_(BBU/BBM)_Maintenance_for_RAID_Controllers
High-Availability – VRRP, HSRP, GLBP: http://www.freeccnastudyguide.com/study-guides/ccna/ch14/vrrp-hsrp-glbp/
Understanding VRRP: http://www.juniper.net/techpubs/en_US/junos/topics/concept/vrrp-overview-ha.html
Configuring VRRP: http://www.cisco.com/c/en/us/td/docs/ios-xml/ios/ipapp_fhrp/configuration/15-mt/fhp-15-mt-book/fhp-vrrp.html
Configuring GLBP: http://www.cisco.com/c/en/us/td/docs/ios-xml/ios/ipapp_fhrp/configuration/xe-3s/fhp-xe-3s-book/fhp-glbp.html
Explaining the Uptime Institute’s Tier Classification System: https://journal.uptimeinstitute.com/explaining-uptime-institutes-tier-classification-system/