Na prática da máquina e aprendizagem profunda, Parâmetros de Modelo são as propriedades de dados de treinamento que irá aprender sobre a sua própria, durante o treino, o classificador ou outros ML modelo. Por exemplo, pesos e vieses, ou pontos divididos na árvore de decisão.
Hyperparametros modelo são propriedades que governam todo o processo de treinamento. Eles incluem variáveis que determinam a estrutura da rede (por exemplo, número de unidades ocultas) e as variáveis que determinam como a rede é treinada (por exemplo, taxa de aprendizagem). Hyperparameters modelo são definidos antes do treinamento (antes de otimizar os pesos e viés).
Por exemplo, aqui estão algumas modelo embutido variáveis de configuração :
- a velocidade de Aprendizagem
- Número de Épocas
- Camadas Ocultas
- Oculto Unidades
- as Ativações de Funções
Hiperparâmetros são importantes, pois eles controlam diretamente o comportamento da formação de algo, ter impacto importante sobre o desempenho do modelo em formação.
escolher hiperparametros apropriados desempenha um papel fundamental no sucesso das arquiteturas de redes neurais, dado o impacto no modelo aprendido. Por exemplo, se a taxa de aprendizagem é muito baixa, o modelo perderá os padrões importantes nos dados; inversamente, se for alta, pode ter colisões.
escolher um bom hiperparâmetro proporciona dois benefícios principais:
- pesquisa eficiente através do espaço de possíveis hiperparâmetros; e
- gestão mais fácil de um grande conjunto de experimentos para a sintonização do hiperparâmetro.
os hiperparâmetros podem ser divididos em 2 categorias:
1. Hyperparameters de optimizador,
2. Hiperparametros específicos do Modelo
eles estão relacionados mais com o processo de otimização e treinamento.
1, 1. Taxa de aprendizagem:
Se a taxa de aprendizagem modelo é muito menor do que os valores ideais, levará muito mais tempo (centenas ou milhares) de épocas para alcançar um estado ideal. Por outro lado, se a taxa de aprendizagem é muito maior do que o valor ideal, então ele excederia o estado ideal e o algoritmo não poderia convergir. Uma taxa de aprendizagem inicial razoável = 0,001.
Importante considerar que:
a) o modelo terá de ter centenas e milhares de parâmetros, cada um com seu próprio erro curva. And learning rate has to shepherd all of them
b) error curves are not clean u-shapes; instead, they tend to have more complex shapes with local minima.
1, 2. Tamanho Do Mini-Lote:
O tamanho do lote tem um efeito sobre as necessidades de recursos do processo de treinamento, velocidade e número de iterações de uma forma não trivial.
Historicamente, tem havido um debate para fazer estocástico de treinamento onde você se encaixa um único exemplo de conjunto de dados para o modelo e, usando apenas um exemplo, executar um passe para a frente, calcular o erro / backpropagate & conjunto de valores ajustados para todos os hiperparâmetros. E então fazer isso novamente para cada exemplo no conjunto de dados.
ou, talvez melhor para alimentar todos os dados para a etapa de treinamento e calcular o gradiente usando o erro gerado ao olhar para todos os exemplos no conjunto de dados. Isto chama-se Formação em lote.
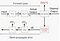
técnica usada hoje é a definição de um mini-tamanho do lote. Treinamento estocástico é quando o tamanho do minibatch =1, e treinamento em lote é quando o tamanho do mini-lote = Número de exemplos no conjunto de treinamento. Valores iniciais recomendados para a experimentação: 1, 2, 4, 8, 16, 32, 64, 128, 256.
a larger mini-batch size allows computational boosts that utilizes matrix multiplication in the training calculations . No entanto, ele vem em detrimento da necessidade de mais memória para o processo de treinamento. Um tamanho menor de mini-lote induz mais ruído nos cálculos de erros, muitas vezes mais útil na prevenção do processo de treinamento de parar nos mínimos locais. Um justo valor para o tamanho do mini-lote = 32.
assim, enquanto o impulso computacional nos leva a aumentar o tamanho do mini-lote, este benefício algorítmico prático incentiva a torná-lo realmente menor.
1, 3. Número de Epochs:
para escolher o número certo de epochs para o passo de treinamento, a métrica que devemos prestar atenção é o erro de validação.
O manual intuitiva maneira é ter o modelo de treinar por muitos o número de iterações enquanto erro de validação continua a diminuir.
Há uma técnica que pode ser usada chamada parada precoce para determinar quando parar de treinar o modelo; trata-se de parar o processo de treinamento no caso do erro de validação não ter melhorado nos últimos 10 ou 20 epochs.2. Hiperparâmetros modelo
eles estão mais envolvidos na estrutura do modelo:
2.1. Número de unidades escondidas:
número de unidades escondidas é um dos hiperparâmetros mais misteriosos. Vamos lembrar que as redes neurais são aproximadores de funções universais , e para que eles aprendam a aproximar uma função (ou uma tarefa de previsão), eles precisam ter “capacidade” suficiente para aprender a função. O número de unidades ocultas é a principal medida da capacidade de aprendizagem do modelo.
para uma função simples, pode precisar de menos número de unidades ocultas. Quanto mais complexa a função, mais capacidade de aprendizagem o modelo vai precisar.
um Pouco mais número de unidades número ideal não é um problema, mas um número muito maior levará para overfitting (i.e. se você fornecer um modelo com excesso de capacidade, que tendem a overfit, tentando “memorizar” o conjunto de dados, afetando, portanto, a capacidade de generalizar)
2.2. Primeira camada escondida:
outra heurística envolvendo a primeira camada oculta é que definir o número de unidades ocultas maiores do que o número de entradas tende a permitir melhores resultados em número de tarefas, de acordo com a observação empírica.
2, 3. Número de camadas:
é frequentemente o caso de Redes Neurais de 3 camadas superarem uma de 2 camadas. Mas ir ainda mais fundo raramente ajuda muito mais. (exceções são redes neurais convolucionais, onde quanto mais profundas elas são, melhor elas executam).
Hyperparameters Optimisation Techniques
the process of finding most optimal hyperparameters in machine learning is called hyperparameter optimisation.
Comum algoritmos incluem:
- Grelha de Pesquisa
- Busca Aleatória
- de Otimização Bayesiano
a Grade de Pesquisa
a Grade de pesquisa é uma técnica tradicional para a implementação de hiperparâmetros. É um pouco sobre Força bruta todas as combinações. A pesquisa na grelha necessita de criar dois conjuntos de hiperparametros:
- a velocidade de Aprendizagem
- Número de Camadas
a Grade de pesquisa treina o algoritmo para todas as combinações utilizando os dois conjunto de hiperparâmetros (velocidade de aprendizagem e o número de camadas) e mede o desempenho usando validação cruzada técnica. Esta técnica de validação garante que o modelo treinado obtém a maioria dos padrões a partir do conjunto de dados (um dos melhores métodos para realizar a validação usando “K-Fold Cross Validation”, que ajuda a fornecer dados amplos para treinar o modelo e dados amplos para validações).
O Método de busca em grade é um algoritmo mais simples de usar, mas sofre se os dados têm espaço dimensional elevado chamado de maldição de dimensionalidade.
pesquisa aleatória
amostras aleatórias do espaço de pesquisa e avalia conjuntos a partir de uma distribuição de probabilidade especificada. Em vez de tentar verificar todas as 100.000 amostras, por exemplo, podemos verificar 1.000 parâmetros aleatórios.
a desvantagem de usar o algoritmo de pesquisa aleatória, no entanto, é que ele não usa informações de experimentos anteriores para selecionar o próximo conjunto. Além disso, é difícil prever a próxima experiência.

de Otimização Bayesiano
Hyperparameter definição maximiza o desempenho do modelo em um conjunto de validação. ML algos requerem frequentemente afinação fina dos hiper-parâmetros do modelo. Infelizmente, essa afinação é muitas vezes chamada de “função negra” porque não pode ser escrita em uma fórmula (derivados da função são desconhecidos).
uma forma mais apelativa de otimizar & hiper-parâmetros de afinação de afinação de linhas finas implica a habilitação de abordagem de afinação de modelos automatizados — por exemplo, usando a otimização Bayesiana. O modelo usado para aproximar a função objetiva é chamado modelo substituto. Um modelo substituto popular para a otimização Bayesiana é o processo Gaussiano (GP). A otimização Bayesiana normalmente funciona assumindo que a função desconhecida foi amostrada a partir de um processo Gaussiano (GP) e mantém uma distribuição posterior para esta função como observações são feitas.
Existem duas opções principais a serem feitas ao executar a otimização Bayesiana:
- selecione previamente sobre as funções que expressarão suposições sobre a função que está sendo otimizada. Para isso, escolhemos o processo Gaussiano anterior;
- seguinte, devemos escolher uma função de aquisição que é usada para construir uma função de utilidade a partir do modelo posterior, permitindo-nos determinar o próximo ponto a avaliar.
processo Gaussiano
um processo Gaussiano define a distribuição prévia sobre as funções que podem ser convertidas em funções posteriores, uma vez que tenhamos visto alguns dados. O processo Gaussiano usa matriz de covariância para garantir que os valores que estão próximos juntos. A matriz de covariância, juntamente com uma função µ média para produzir o valor esperado ƒ(x) define um processo Gaussiano.1. O processo gaussiano será usado como um prior para a inferência bayesiana;
2. Computando o posterior permite que ele seja usado para fazer previsões para casos de teste invisíveis.

Acquisition Function
Introducing sampling data into the search space is done by acquisition functions. It helps to maximize the acquisition function to determine the next sampling point. Popular de aquisição de funções
- o Máximo de Probabilidade de Melhoria (IPM)
- Melhoria Esperada (EI)
- Superior de Confiança Vinculados (UCB)
que A Esperada Melhoria (EI) é um popular e definido como:
EI(x)=𝔼
onde ƒ(x ) é o atual melhor conjunto de hiperparâmetros. Maximizar os hiper-parâmetros irá melhorar sobre ƒ.
