Por: Arshad Ali | Atualizado em: 2020-07-29 | Comentários (6) | Relacionados: Mais > JUNTAR Tabelas
Problema
Na ponta do SQL Server JoinExamples, Jeremy Kadlec falou sobre diferentes lógicas operadores de associação, mas howdoes SQL Server implementá-las fisicamente? Quais são os diferentes operadores físicos? Como eles são diferentes uns dos outros e em que cenário é que um prefere ao outro? Nesta Dica, nós cobrimos estas perguntas e muito mais.
solução
usamos operadores lógicos quando escrevemos consultas para definir uma consulta relacional no nível conceitual (o que precisa ser feito). A SQL implementa estes operadores lógicos com três operadores físicos diferentes para implementar a operação definida pelos operadoresgógicos (como ela precisa ser feita). Embora haja dezenas de operadores físicos, nesta ponta vou cobrir operadores físicos específicos de juntas. Embora tenhamos diferentes tipos de ligações lógicas no nível conceitual / de consulta, mas SQL Serverimplementá-los todos com três diferentes operadores físicos de junção, como discutido abaixo.
iremos cobrir:
- laços aninhados juntar
- juntar juntar
- Hash juntar juntar
iremos analisar os planos de execução para ver estes operadores e irei explicar por que cada um deles ocorre.
para estes exemplos, estou a utilizar a base de dados AdventureWorks.
SQL Server Nested Loops Join Explained
Antes de investigar os detalhes, deixe-me dizer-lhe primeiro o que um Loops aninhado joinis se você é novo no mundo da programação.
uma junção aninhada de Loops é uma estrutura lógica na qual um loop (iteração) reside dentro de outro, ou seja, para cada iteração do loop externo todas as iterações do loop interno são executadas/processadas.
uma junção aninhada funciona da mesma forma. Uma das tabelas de junção é designada como a mesa exterior e outra como a mesa interior. Para cada linha do outertable, todas as linhas da tabela interna são correspondidas uma por uma se a linha matchesit está incluída no conjunto de resultados caso contrário, é ignorado. Em seguida, a próxima linha da mesa exterior é recolhida e o mesmo processo é repetido e assim por diante.
o Optimizador do servidor de SQL pode escolher uma junção aninhada de Loops quando uma das ligações é pequena (considerada como a tabela externa) e outra é grande (considerada como a tabela interna que é indexada na coluna que está na junção) e, portanto, requer um I/O mínimo e as comparações mais fracas.
o Optimizador considera três variantes para uma junção aninhada de Loops:
- ingênuo associação de loops aninhados, caso em que a pesquisa scansthe toda a tabela ou índice
- índice de associação de loops aninhados quando a pesquisa pode utilizar anexisting índice para realizar pesquisas
- índice temporário associação de loops aninhados se o otimizador createsa índice temporário como parte do plano de consulta e o destrói, após consulta executioncompletes
Um índice de associação de Loops Aninhados um desempenho melhor do que uma associação de mesclagem ou associação de hash ifa pequeno conjunto de linhas estão envolvidos. Considerando que, se um grande conjunto de linhas estão envolvidas, os laços aninhados podem não ser uma escolha ideal. Os laços aninhados suportam quase todos os tipos de conjuntos, excepto as juntas exteriores à direita e à direita, semi-juntas à direita e anti-semijoins à direita.
- No Script #1, estou juntando a tabela SalesOrderHeader com o SalesOrderDetailtable e especificando os critérios para filtrar o resultado do cliente witcustomerid = 670.
- este critério filtrado devolve 12 registos do tableader e, portanto, sendo o mais pequeno, esta tabela foi considerada como a tabela doouter (a primeira no plano gráfico de execução da consulta)pelo optimizador.
- Para cada linha destas 12 linhas da tabela externa, as linhas da mesa interna são correspondidas (ou a mesa interior é digitalizada 12 vezes de cada vez para cada linha usando a pesquisa de índice ou o parâmetro correlacionado da tabela externa) e 312 linhas correspondentes são devolvidas como você pode ver na segunda imagem.
- na segunda consulta abaixo, eu estou usando SET STATISTICS PROFILE para displayprofile informações da execução da consulta junto com o resultado da consulta-set.
Script #1 – Associação de Loops Aninhados Exemplo
SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader H INNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID = 670
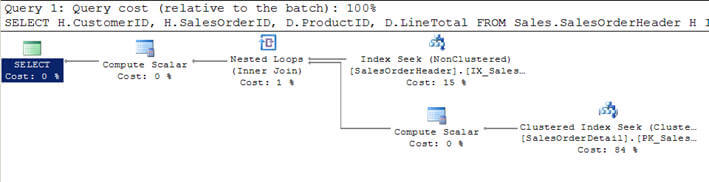
SET STATISTICS PROFILE ONSELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader HINNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderIDWHERE H.CustomerID = 670SET STATISTICS PROFILE OFF

Se o número de registros envolvidos é grande, o SQL Server pode escolher parallelizea loop aninhado, distribuindo o exterior de linhas da tabela de forma aleatória entre os availableNested Loops de threads dinamicamente. No entanto, não se aplica o mesmo para os quadros internos. Para saber mais sobre scansclick paralelo aqui.
SQL Server Merge Join Explained
a primeira coisa que você precisa saber sobre um Merge join é que ele exige que ambas as entradas sejam ordenadas com teclas de junção/colunas de junção (ou ambas as tabelas de entrada têm grupos na coluna que junta as tabelas) e também requer pelo menos uma expressão/predicado equijoin(igual a).
dado que as linhas estão pré-ordenadas, uma junção de junção inicia imediatamente o processo de acasalamento. Ele lê uma linha de uma entrada e compara-a com a linha de outra entrada.Se as linhas de correspondência, que correspondeu a linha é considerada no conjunto de resultados (em seguida, ele readsthe próxima linha da tabela de entrada, faz a mesma comparação/correspondência e assim por diante) orelse a menor das duas linhas é ignorado e o processo continua desta forma untilall linhas tiverem sido processadas..
uma junção Merge tem um melhor desempenho ao juntar grandes tabelas de entrada (pré-indexadas / ordenadas), uma vez que o custo é a soma de linhas em ambas as tabelas de entrada, em oposição às NestedLoops, onde é um produto de linhas de ambas as tabelas de entrada. Às vezes o optimizerdecides para usar uma junção Merge quando as tabelas de entrada não são ordenadas e, portanto, utiliza um operador físico de ordenação explícita, mas pode ser mais lento do que usando um índice(tabela de entrada pré-ordenada).
- No Script #2, eu estou usando uma consulta semelhante como acima, mas desta vez eu tenho liderado uma cláusula onde para obter todos os clientes maior que 100.
- Neste caso, o Optimizador decide usar uma junção de junção como ambas as entradas são elevadas em termos de linhas e também são pré-indexadas/ordenadas.
- Você também pode notar que ambas as entradas são digitalizadas apenas uma vez, em oposição às 12 digitalizações que vimos nos laços aninhados juntar acima.
Script #2 – Associação de Mesclagem Exemplo
SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader H INNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID > 100
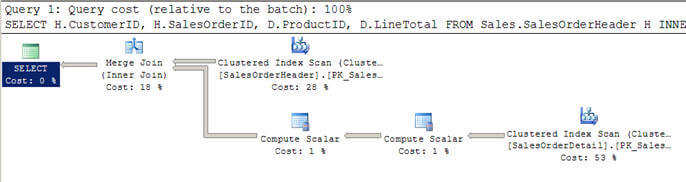
SET STATISTICS PROFILE ONSELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader HINNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderIDWHERE H.CustomerID > 100SET STATISTICS PROFILE OFF

Uma associação de impressão em Série é, muitas vezes, mais eficiente e mais rápido do operador join se o sorteddata pode ser obtido a partir de um índice de árvore-B e executa quase todos os joinoperations desde que haja pelo menos uma igualdade predicado de associação envolvidos. O Italso suporta múltiplos predicados de junção de igualdade, desde que as tabelas de entrada sejam apresentadas em todas as chaves de junção envolvidas e estejam na mesma ordem.
a presença de um operador escalar computado indica a avaliação de uma expressãopara produzir um valor escalar computado. Na consulta acima estou selecionando Linetotal que é uma coluna derivada, portanto, tem sido usado no plano de execução.
SQL Server Hash Join Explained
a hash join is normally used when input tables are quite large and no adequateindexes exist on them. Uma junta de Hash é realizada em duas fases; a fase de construção e a fase da sonda e, por conseguinte, a junção de hash tem duas entradas, ou seja, a entrada de construção e a entrada de probeinput. A menor das entradas é considerada como a entrada de construção (para minimizar o requisito de memória para armazenar uma tabela de hash discutida mais tarde) e obviamente a outra é a entrada de sonda.
durante a fase de compilação, as teclas de união de todas as linhas da tabela de compilação são digitalizadas.Hashs são gerados e colocados em uma tabela de hash em memória. Ao contrário da junção Merge,está a bloquear (não são devolvidas linhas) até este ponto.durante a fase da sonda, as teclas de junção de cada linha da tabela da sonda são escaneadas.Mais uma vez hashs are generated (using the same hash function as above) and comparedagainst the corresponding hash table for a match.
uma função Hash requer uma quantidade significativa de ciclos de CPU para gerar hash e recursos de memória para armazenar a tabela hash. Se houver pressão de memória, algumas das partições da tabela de hash são trocadas para o tempdb e sempre que há necessidade (seja para sondar ou atualizar o conteúdo), ele é trazido de volta para o cache.Para alcançar alto desempenho, o otimizador de consulta pode paralelizar uma junção de Hash toscale melhor do que qualquer outra junção, para mais detailsclick aqui.
Existem, basicamente, três diferentes tipos de junções de hash:
- Em memória de Hash Join caso em que há memória suficiente está availableto armazenar a tabela de hash
- Graça Associação de Hash, caso em que a tabela de hash não pode fitin de memória e algumas partições são despejados para tempdb
- Recursiva Associação de Hash, nesse caso, uma tabela de hash é tão largethe optimizer inclui o uso de diversos níveis de associações de impressão em série.
para mais detalhes sobre estes diferentes tipos de caracteres aqui.
- No Script # 3, eu estou criando duas novas tabelas grandes (a partir dos existentes AdventureWorkstables) sem índices.
- pode ver que o Optimizador escolheu usar uma junção de Hash neste caso. mais uma vez, ao contrário de uma junção aninhada de Loops, ela não digitaliza os multiplexes internos da tabela.
Script #3 – Associação de Hash Exemplo
--Create tables without indexes from existing tables of AdventureWorks database SELECT * INTO Sales.SalesOrderHeader1 FROM Sales.SalesOrderHeader SELECT * INTO Sales.SalesOrderDetail1 FROM Sales.SalesOrderDetail GO SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader1 H INNER JOIN Sales.SalesOrderDetail1 D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID = 670 GO
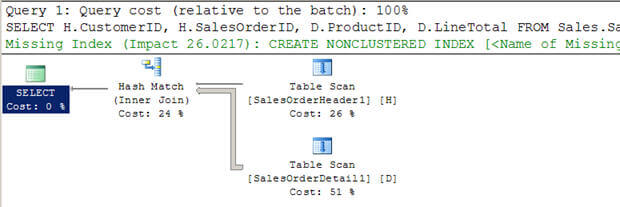
SET STATISTICS PROFILE ON SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader1 H INNER JOIN Sales.SalesOrderDetail1 D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID = 670 SET STATISTICS PROFILE OFF

--Drop the tables created for demonstration DROP TABLE Sales.SalesOrderHeader1 DROP TABLE Sales.SalesOrderDetail1
Nota: o SQL Server faz um bom trabalho decidir o que joinoperator para usar em cada condição. Compreender estas condições ajuda você a entender o que pode ser feito na sintonização de desempenho. Não é recomendado usar dicas de junção( cláusula de usingOPTION) para forçar o servidor SQL a usar um operador de junção específico (a menos que você não tenha outra saída), mas ao invés disso você pode usar outros meios como atualizar estatísticas,criar índices ou reescrever sua consulta.
próximas etapas
- ReviewSQL ServerJoin Examples tip. os operadores científicos e físicos referenciam o artigo sobre tecnologia.
última actualização: 2020-07-29


 Arshad Ali is a SQL and BI Developer focusing on Data Warehousing projects for Microsoft.
Arshad Ali is a SQL and BI Developer focusing on Data Warehousing projects for Microsoft.View all my tips
- More Database Developer Tips…