de: Arshad Ali | actualizat: 2020-07-29 | Comentarii (6) | înrudit: mai multe> Alăturați-vă tabele
problemă
în vârful SQL Server JoinExamples, Jeremy Kadlec a vorbit despre diferiți operatori logici de asociere, dar cum SQL Server le implementează fizic? Care sunt diferitele joinoperators fizice? Cum sunt diferite unele de altele și în ce scenariu este preferatpeste altul? În acest sfat, acoperim aceste întrebări și multe altele.
soluție
folosim operatori logici atunci când scriem interogări pentru a defini o interogare relațională la nivel conceptual (ce trebuie făcut). SQL implementează acești operatori logici cu trei operatori fizici diferiți pentru a implementa operația definită de operatorii logici (cum trebuie făcută). Deși există zeci de fiziceoperatori,în acest sfat voi acoperi anumiți operatori fizici. Deși wehave diferite tipuri de logică se alătură la nivel conceptual / interogare, dar SQL Serverimplements-le pe toate cu trei operatori fizice se alăture diferite așa cum sa discutat mai jos.
vom acoperi:
- imbricate Loops Join
- Merge Join
- hash Join
ne vom uita laexecution planuri pentru a vedea acești operatori și voi explica de ce apare fiecare.
pentru aceste exemple, utilizezbaza de date AdventureWorks.
SQL Server imbricate bucle alătura explicat
înainte de săpat în detalii, permiteți-mi să vă spun mai întâi ce un imbricate bucle joinis dacă sunteți nou în lumea de programare.
o îmbinare a buclelor imbricate este o structură logică în care o buclă (iterație) se află în alta, adică pentru fiecare iterație a buclei exterioare toate iterațiile buclei interioare sunt executate / procesate.
o bucle imbricate se alăture funcționează în același mod. Una dintre mesele de îmbinare este desemnatăca masa exterioară și alta ca masa interioară. Pentru fiecare rând al exterioruluitabel, toate rândurile din tabelul interior sunt potrivite unul câte unul dacă rândul se potriveșteeste inclus în rezultat-setați altfel este ignorat. Apoi rândul următor de latabelul exterior este preluat și același proces este repetat și așa mai departe.
SQL Server optimizer ar putea alege un bucle imbricate se alăture atunci când unul dintre joiningtables este mic (considerat ca tabelul exterior) și altul este mare (consideredas tabelul interior care este indexat pe coloana care este în join) și henceeit necesită minim I / O și cele mai puține comparații.
Optimizatorul consideră trei variante pentru o bucle imbricate se alăture:
- buclele imbricate naive se alătură, caz în care căutarea scanează întregul tabel sau index
- buclele imbricate index se alătură atunci când căutarea poate utiliza un index existent pentru a efectua căutări
- buclele imbricate index temporar se alătură dacă Optimizatorul creează un index temporar ca parte a planului de interogare și îl distruge după executarea interogăriicompletează
Un index imbricate Loops join funcționează mai bine decât un merge join sau hash join dacă sunt implicate un set mic de rânduri. Întrucât, în cazul în care un set mare de rânduri sunt implicate bucle theNested se alăture ar putea să nu fie o alegere optimă. Buclele imbricate suportă aproape toatetipuri de îmbinare, cu excepția îmbinărilor exterioare drepte și complete, semi-alăturarea dreaptă și antisemijoinele drepte.
- în Script #1, mă alătur tabelului SalesOrderHeader cu SalesOrderDetailtable și specificând criteriile pentru a filtra rezultatul clientului withCustomerID = 670.
- acest criteriu filtrat returnează 12 înregistrări din tabelul Salesorderheaderși, prin urmare, fiind cel mai mic, acest tabel a fost considerat ca tabelul de exterior (cel de sus în planul de execuție a interogării grafice)de către optimizator.
- pentru fiecare rând din aceste 12 rânduri ale tabelului exterior, rândurile din tabelul interior SalesOrderDetail sunt potrivite (sau inertable este scanat de 12 ori de fiecare dată pentru fiecare rând folosind index seek or correlatedparameter din tabelul exterior) și 312 rânduri potrivite sunt returnate după cum putețiVedeți în a doua imagine.
- în a doua interogare de mai jos, eu sunt folosind set statistici profil pe displayprofile informații de execuție interogare împreună cu interogarea rezultat-set.
Script #1 – bucle imbricate se alăture exemplu
SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader H INNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID = 670
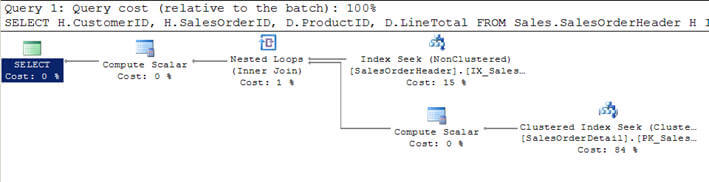
SET STATISTICS PROFILE ONSELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader HINNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderIDWHERE H.CustomerID = 670SET STATISTICS PROFILE OFF

dacă numărul de înregistrări implicate este mare, sql server ar putea alege să parallelizea buclă imbricată distribuind rândurile tabelului exterior aleatoriu între firele bucle availablenested dinamic. Nu se aplică același lucru pentru tablerows interior, deși. Pentru a afla mai multe despre scanările paralelefaceți clic aici.
SQL Server Merge Join Explained
primul lucru pe care trebuie să-l cunoașteți despre un join Merge este că necesită ambele intrări pentru a fi sortate pe join keys/merge columns (sau ambele tabele de intrare au clusteredindexes pe coloana care se alătură tabelelor) și necesită, de asemenea, cel puțin o expresie / predicat equijoin(egal cu).
deoarece rândurile sunt pre-sortate, o îmbinare se alăture imediat începe matchingprocess. Citește un rând dintr-o intrare și îl compară cu rândul unei alte intrări.Dacă rândurile se potrivesc, acel rând potrivit este considerat în setul de rezultate (apoi citește următorul rând din tabelul de intrare, face aceeași comparație/potrivire și așa mai departe) orelse cea mai mică dintre cele două rânduri este ignorată și procesul continuă în acest fel până când toate rândurile au fost procesate..
o îmbinare de îmbinare funcționează mai bine atunci când se alătură tabelelor de intrare mari (preindexate / sortate), deoarece costul este însumarea rândurilor din ambele tabele de intrare, spre deosebire de NestedLoops, unde este un produs al rândurilor ambelor tabele de intrare. Uneori optimizerdecides pentru a utiliza o îmbinare se alăture atunci când tabelele de intrare nu sunt sortate și, prin urmare, ituses un operator fizic sortare explicit, dar ar putea fi mai lent decât folosind un index(tabel de intrare pre-sortate).
- în Script #2, Eu sunt folosind o interogare similară ca mai sus, dar de data aceasta am haveadded o clauză în cazul în care pentru a obține toate client mai mare de 100.
- în acest caz, Optimizatorul decide să utilizeze o îmbinare, deoarece ambele intrări sunt mari în ceea ce privește rândurile și sunt, de asemenea, pre-indexate/sortate.
- de asemenea, puteți observa că ambele intrări sunt scanate o singură dată, spre deosebire de cele 12 scanări pe care le-am văzut în buclele imbricate se alătură mai sus.
Script #2 – Merge Join Example
SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader H INNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID > 100
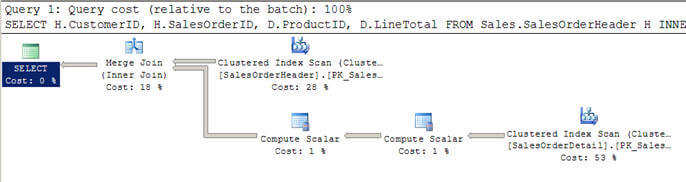
SET STATISTICS PROFILE ONSELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader HINNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderIDWHERE H.CustomerID > 100SET STATISTICS PROFILE OFF

un join merge este adesea un operator de join mai eficient și mai rapid dacă sorteddata poate fi obținută dintr-un indice B-Tree existent și efectuează aproape toate joinoperations atâta timp cât există cel puțin un predicat de join equality implicat. Italso sprijină egalitatea multiple se alăture predicate, atâta timp cât tabelele de intrare aresorted pe toate cheile de îmbinare implicate și sunt în aceeași ordine.
prezența unui operator scalar de calcul indică evaluarea unei expresii pentru a produce o valoare scalară calculată. În interogarea de mai sus selectez Linetotalcare este o coloană derivată, prin urmare a fost utilizată în planul de execuție.
SQL Server hash Join Explained
un hash join este utilizat în mod normal atunci când tabelele de intrare sunt destul de mari și nu există indexuri adecvate pe ele. Un hash join se realizează în două faze; faza de construire și faza sondei și, prin urmare, îmbinarea hash are două intrări, adică intrare de construire și probeinput. Cea mai mică dintre intrări este considerată intrarea de construire (pentru a minimiza cerința memoriei de a stoca un tabel hash discutat mai târziu) și, evident, cealaltă este intrarea sondei.
în timpul fazei de compilare, sunt scanate cheile de îmbinare ale tuturor rândurilor tabelului de compilare.Hash-urile sunt generate și plasate într-un tabel hash în memorie. Spre deosebire de îmbinarea îmbinării,se blochează (nu se returnează rânduri) până în acest moment.
în timpul fazei sondei, sunt scanate cheile de îmbinare ale fiecărui rând al tabelului sondei.Din nou, sunt generate hash-uri (folosind aceeași funcție hash ca mai sus) și comparateîmpotriva tabelului hash corespunzător pentru un meci.
o funcție Hash necesită o cantitate semnificativă de cicluri CPU pentru a genera resurse de memorie hashesand pentru a stoca tabelul hash. Dacă există o presiune de memorie, uniidin partițiile tabelului hash sunt schimbate în tempdb și ori de câte ori există o nevoie (fie pentru a sonda, fie pentru a actualiza conținutul) este readusă în memoria cache.Pentru a obține performanțe ridicate, Optimizatorul de interogări poate paraleliza un Hash join toscale mai bine decât orice alt join, pentru mai multe detaliifaceți clic aici.
există practic trei tipuri diferite de hash se alătură:
- In-memory hash Join, caz în care este disponibilă suficientă memorie pentru a stoca tabelul hash
- Grace hash Join, caz în care tabelul hash nu se poate încadra în memorie și unele partiții sunt vărsate în tempdb
- Recursive hash Join, caz în care un tabel hash este atât de marethe optimizer trebuie să utilizeze mai multe niveluri de îmbinare se alătură.
Pentru mai multe detalii despre aceste tipuri diferitefaceți clic aici.
- în scriptul #3, creez două noi tabele mari (din AdventureWorkstables existente) fără indexuri.
- puteți vedea Optimizatorul a ales să utilizeze un hash join în acest caz.
- din nou, spre deosebire de un bucle imbricate se alăture, nu scanează multipletimes tabelul interior.
Script #3 – Hash Join Example
--Create tables without indexes from existing tables of AdventureWorks database SELECT * INTO Sales.SalesOrderHeader1 FROM Sales.SalesOrderHeader SELECT * INTO Sales.SalesOrderDetail1 FROM Sales.SalesOrderDetail GO SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader1 H INNER JOIN Sales.SalesOrderDetail1 D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID = 670 GO
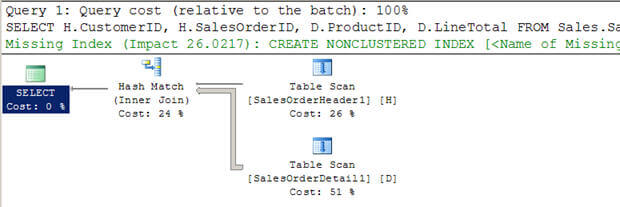
SET STATISTICS PROFILE ON SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader1 H INNER JOIN Sales.SalesOrderDetail1 D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID = 670 SET STATISTICS PROFILE OFF

--Drop the tables created for demonstration DROP TABLE Sales.SalesOrderHeader1 DROP TABLE Sales.SalesOrderDetail1
notă: SQL Server face o treabă destul de bună în a decide care joinoperator să utilizeze în fiecare condiție. Înțelegerea acestor condiții vă ajută să înțelegețice se poate face în reglarea performanței. Nu este recomandat să utilizați sugestii de asociere (folosind clauza de opțiune) pentru a forța SQL Server să utilizeze un anumit operator de asociere (cu excepția cazului în care nu aveți altă cale de ieșire), ci mai degrabă puteți utiliza alte mijloace,cum ar fi actualizarea statisticilor, crearea indexurilor sau rescrierea interogării.
pașii următori
- ReviewSQL ServerJoin Exemple sfat.
- ReviewLogical și fizice operatorii articol de referință pe technet.
Ultima actualizare: 2020-07-29


 Arshad Ali is a SQL and BI Developer focusing on Data Warehousing projects for Microsoft.
Arshad Ali is a SQL and BI Developer focusing on Data Warehousing projects for Microsoft.View all my tips
- More Database Developer Tips…