scopul acestui articol este de a explica redundanța în termeni de calcul, rețea și găzduire. Vom oferi exemple din lumea reală de soluții tehnologice redundante pentru a ilustra ce este redundanța și cum funcționează.
Atlantic.Net a creat mai multe medii de găzduire, inclusiv o platformă cloud durabilă, găzduire VPS de mare viteză, infrastructură compatibilă HIPAA și găzduire cloud privată gestionată. Toate sistemele noastre sunt construite cu redundanță ca factor principal de conducere al procesului de proiectare.
în engleza de zi cu zi, redundanța poate avea o conotație negativă; ceva redundant nu este de obicei necesar sau considerat de prisos. Cu toate acestea, într-un mediu de găzduire în cloud, redundanța poate însemna diferența dintre disponibilitatea perfectă a sistemului și timpul de nefuncționare nedorit sau neașteptat.
- ce este un sistem Redundant?
- tipuri de sisteme redundante
- Exemple de servicii software redundante
- Hyper-V Replica
- Clustering Hyper-V
- HAProxy
- Heartbeat
- Exemple de servicii hardware redundante
- RAID
- redundanță de rețea
- primele protocoale de redundanță Hop (FHRP)
- Virtual Router Redundancy Protocol (VRRP)
- Hot Standby Router Protocol (HSRP)
- Gateway Load Balancing Protocol (GLBP)
- redundanța centrelor de date
- concluzie
ce este un sistem Redundant?
un sistem redundant va oferi suport pentru failover sau echilibrare a sarcinii pentru a proteja un sistem live în cazul unei defecțiuni neașteptate. În cazul unei defecțiuni de putere, mecanice sau software, Un sistem redundant va avea o componentă sau o platformă duplicată la care să revină. În general, orice componentă a unui sistem cu un singur punct de eșec poate fi văzută ca un risc pentru serviciile de producție.
sistemele de alimentare sau mecanice au strategii de retragere mai simple care necesită simpla prezență a unui alt tip de serviciu; failoverele software necesită de obicei o configurație suplimentară pe sistemul gazdă sau pe un master sau gateway.
capacitățile de redundanță sunt recomandate pentru orice sistem critic de afaceri, dar în special pentru sistemele care au un impact semnificativ în timpul perioadelor de nefuncționare. Unele companii pot păstra toate informațiile critice despre clienți într-o bază de date; prin urmare, în scopuri de continuitate a activității, protejarea acelei baze de date cu redundanță va proteja integritatea datelor în cazul unei defecțiuni catastrofale.
tipuri de sisteme redundante
un sistem redundant este format din cel puțin două sisteme care sunt interconectate și proiectate în același scop. Există multe tipuri diferite de configurații de sistem redundante disponibile, iar diferite implementări ale sistemului oferă abordări unice pentru a menține un sistem în permanență.
nu toate serverele trebuie configurate cu redundanță; mai degrabă, ar trebui luate în considerare doar cele mai critice. Am recomandat o evaluare detaliată a riscurilor pentru a înțelege ce servere sunt în domeniu și cantitatea maximă de nefuncționare pe care o pot gestiona serverele dvs. Utilizați această evaluare pentru a determina o strategie RTO (obiectivul timpului de recuperare) și RPO (obiectivul punctului de recuperare). RTO este suma maximă de nefuncționare acceptabilă. Aceasta poate varia de la 5 secunde la 24 de ore. RPO este momentul în care aveți nevoie de datele dvs.; de exemplu, afacerea dvs. poate funcționa cu o pierdere maximă de 24 de ore în valoare de date.
iată câteva exemple populare:
- Activ-Inactiv / cald-rece – când o componentă a unui sistem este sistemul activ și alta este inactivă sau închisă. Componenta inactivă este activată numai atunci când componenta care rulează în prezent eșuează sau suferă întreținere
- Active-Active/Hot-Hot – când ambele sisteme sunt live și fac conexiuni. Acest lucru este cel mai frecvent cunoscut sub numele de clustering. De obicei, dispozitivul din fața ambelor mașini va determina cum să împartă traficul de intrare
- Active-Standby/Hot-Warm – când ambele sisteme sunt pornite, dar numai unul face conexiuni. Al doilea sistem este menit să primească periodic actualizări sau copii de rezervă din sistemul primar. În cazul unei defecțiuni, sistemul în standby își asumă rolul principal până când sistemul inițial poate fi recuperat.
fiecare tip are propriile sale argumente pro și contra.
- sistemele Active-Inactive / Hot-Cold pot oferi o platformă redundantă simplă, dar orice failover va avea ca rezultat utilizatorii să vadă o versiune mai veche a sistemului.
- Active-Active / Hot-Hot va necesita o actualizare constantă a ambelor sisteme, fie manual, fie printr-un serviciu separat, pentru a se asigura că toți utilizatorii pot utiliza oricare dintre sisteme. Această abordare poate reduce foarte mult încărcarea activă a unui serviciu pe care îl furnizați clienților.
- Active-Standby / Hot-Warm va oferi capacitățile de failover ale hot-cold cu o copie mai actualizată a sistemului dvs. activ pe failover, dar nu oferă nicio relaxare a sarcinii.
sunt disponibile alte forme de redundanță a nodurilor multiple care permit o redundanță mai mare și soluții robuste de echilibrare a sarcinii. În acel moment, veți avea un cluster cu disponibilitate ridicată, cunoscut și sub numele de cluster HA.
aceasta poate utiliza orice combinație a soluțiilor de redundanță menționate anterior, cu flexibilitate maximă în abordarea sau cantitatea de redundanță necesară. Clusterele HA pot fi, de asemenea, configurate în mai multe locații fizice pentru a permite disponibilitatea până la nivelul coloanei vertebrale a internetului.
Exemple de servicii software redundante
În lipsa disponibilității reduse a resurselor, există foarte puține motive pentru a nu avea replicare proprietară sau servicii redundante configurate într-un mediu virtual; astfel, multe astfel de servicii sunt disponibile în mod implicit în majoritatea sistemelor de virtualizare. Toate serviciile noastre cloud au replicare disponibilă, o caracteristică care ne permite să reproducem orice server de la un nod la altul, indiferent dacă se află în același centru de date sau în regiuni separate ale centrelor de date.
Hyper-V Replica
Hyper-V Replica este o formă de redundanță cald-cald. O mașină virtuală primară este creată pe o gazdă fizică și acceptă conexiunile primite. Când activați replicarea, hard disk-urile virtuale ale noii mașini sunt transferate către o gazdă fizică separată Hyper-V. Această gazdă configurează apoi un VM pe sine, care reproduce pe un program definit de utilizator pentru a se asigura că este luată cea mai recentă imagine a serverului activ. Puncte de control suplimentare pot fi păstrate, de asemenea. Găzduirea privată Hyper-V cu servicii gestionate este asigurată de Atlantic.Net cu această caracteristică coapte în; contactați echipa noastră pentru informații suplimentare.
Clustering Hyper-V
Hyper-V este, de asemenea, capabil de clustering printr-o conexiune la alte gazde Hyper-V. VM-urile de pe orice gazdă Hyper-V pot fi grupate împreună pe acea gazdă singulară pentru a oferi redundanță la nivel local prin rețele virtuale.
Microsoft Network Load Balancing (NLB) poate fi utilizat pentru a crea o singură resursă formată din mai multe gazde care partajează aceleași informații pentru a oferi un punct simplu de acces pentru partajarea fișierelor. Deoarece acest lucru este limitat doar de cantitatea de resurse pe care o aveți la dispoziție, puteți configura teoretic mai multe gazde cu mai multe VM-uri pentru redundanță maximă, ceea ce vă va permite, de asemenea, să efectuați întreținerea pe VM-uri individuale fără a sacrifica disponibilitatea serviciului sau a resurselor. Găzduirea privată Hyper-V cu servicii gestionate este asigurată de Atlantic.Net cu această caracteristică coapte în; contactați echipa noastră pentru informații suplimentare.
HAProxy
În afară de Hyper-V, un dispozitiv gateway, cum ar fi un firewall, poate fi utilizat pentru failover sau servicii de echilibrare a încărcării. De exemplu, Atlantic.Net poate oferi pfSense cu Proxy de înaltă disponibilitate, cunoscut și sub numele de HAProxy.
HAProxy va acționa ca un echilibrator de sarcină, un proxy sau o soluție simplă de disponibilitate ridicată la cald pentru aplicațiile TCP și HTTP. HAProxy este o soluție open-source foarte populară, bazată pe Linux, utilizată de unele dintre cele mai vizitate site-uri din lume.
Heartbeat
Heartbeat este un serviciu disponibil pe majoritatea distribuțiilor Linux care este utilizat pentru a determina dacă nodurile dintr-un cluster sunt încă active sau receptive. Este foarte simplu de configurat și oferă capabilități failover la orice sistem de lucru peste TCP.
dezvoltatorii Heartbeat recomandă și alți manageri de resurse de cluster care pornesc sau opresc serviciile în funcție de faptul dacă o anumită gazdă este dezactivată. Heartbeat a inclus acest lucru, dar alți manageri sunt disponibili. Datorită simplității bătăilor inimii, este foarte personalizabil. Platforme de Găzduire Cloud furnizate de Atlantic.Net aveți deja această caracteristică coaptă și vă putem ajuta să implementați Heartbeat pe propria distribuție privată Linux, dacă este necesar.
Exemple de servicii hardware redundante
cea mai bună parte a hardware-ului redundant este simplitatea sa. În timp ce serviciile software pot necesita o configurație excesivă și pot fi destul de sensibile, hardware-ul este de obicei foarte simplu de configurat și incredibil de durabil. Primul exemplu pe care îl vom analiza este tehnologia RAID utilizată pe scară largă.
RAID
RAID înseamnă Redundant Array de discuri independente (sau redundant Array de discuri ieftine în funcție de cât timp îl utilizați) și are mai multe niveluri utilizate fie pentru protecția datelor, fie pentru creșterea i/o a discului.
RAID poate fi configurat fie printr-un controler software sau hardware. Controlerul are software-ul și configurația necesare pentru a gestiona discurile RAID. Configurația poate fi exportată în diferite sisteme, cu o configurație suplimentară mică sau deloc.
RAID poate fi configurat în câteva moduri diferite pentru a oferi un echilibru bun al ambelor calități:
- RAID 0 – Aceasta nu este în esență redundanță. Niciun disc din sistem nu partajează date prin oglindire, dar toate datele sunt dungate pe fiecare disc, oferind o viteză crescută de citire/scriere. Fiecare unitate poate utiliza în continuare spațiul de stocare furnizat la maxim, ceea ce înseamnă că cu cât adăugați mai multe unități la un RAID 0, cu atât veți avea mai mult spațiu.
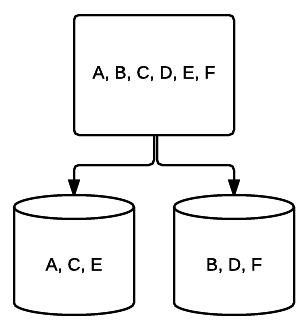
- RAID 1 – o formă de bază de oglindire oferind redundanță excelentă la costul spațiului. Într-un sistem cu două unități, o copie completă a datelor de pe o unitate este scrisă pe cealaltă. Această redundanță este îmbunătățită cu fiecare unitate adăugată. Deoarece toate datele trebuie să fie oglindite pe toate unitățile, spațiul total al sistemului va fi limitat doar la spațiul celei mai mici unități din sistem.
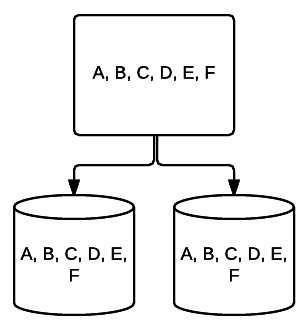
- RAID 5 – această formă de RAID este de obicei utilizată pentru a crește viteza și fiabilitatea citirii. În acest caz, dungile sunt plasate în jurul fiecărei unități din sistem, minimul fiind de 3 unități. În același timp, un bloc suplimentar de date de corectare a erorilor este plasat despre fiecare unitate într-o tehnică numită paritate. Aceasta verifică dacă datele sunt modificate la transferul de la o unitate la alta. Acest lucru oferă, de asemenea, o formă minimă de redundanță, deoarece 1 dintre aceste unități poate eșua și sistemul poate funcționa în continuare. Cu cât sunt adăugate mai multe unități la acest tip de configurare RAID, cu atât crește viteza de citire. Cu redundanță minimă și striping pe toate unitățile, cantitatea totală de spațiu în această configurare este egală cu dimensiunea volumului RAID logic ori numărul de unități pe care le utilizați, minus unul. De exemplu, dacă aveți unități 5 500 GB într-un RAID 5, ați avea 2000 GB utilizabile sau 2 TB (500 *(5-1)=2000).
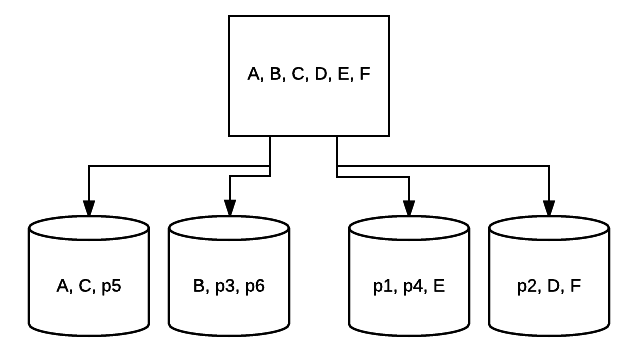
- RAID 10 – Aceasta este o combinație de RAID 1 și RAID 0. În acest caz, toate datele sunt dungate pe fiecare dispozitiv, blocuri de date fiind, de asemenea, oglindite pe întregul sistem dungat. De exemplu, într-un sistem 4 Drive RAID 10, unitățile 2 500 GB pot avea aceleași date, dar nu toate datele necesare pentru ca sistemul să funcționeze corect. 2 alte unități de date ar fi necesare. Gândiți-vă la fiecare sistem RAID 1 ca la o singură unitate și la fiecare dintre aceste sisteme plasate într-o matrice RAID 0. În această configurație, performanța poate fi crescută drastic ca în RAID 0, cu o anumită redundanță încă în vigoare cu oglindirea. Până la jumătate din unitățile din sistem pot eșua înainte ca sistemul să se blocheze, dar, ca și în cazul oricărei matrice redundante, este mai bine să înlocuiți unitățile cât mai curând posibil. Atlantic.Net foloseste RAID 10 pentru toate SSD nor de stocare VPS.
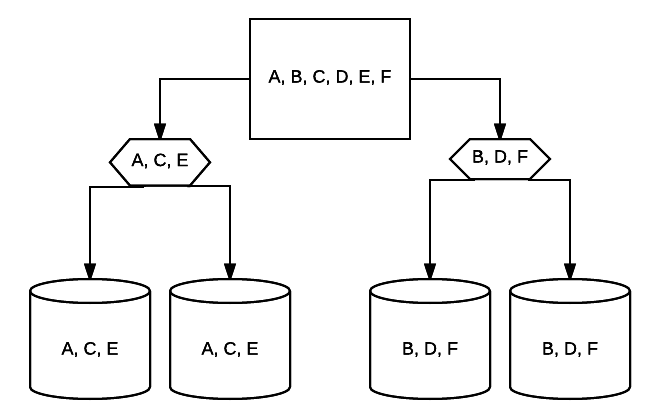
pentru o protecție suplimentară, controlerele RAID sunt protejate de unități de rezervă ale bateriei care alimentează cipurile ROM utilizate pentru a salva configurația în memorie în caz de pierdere de energie etc. Un BBU va furniza energie unei matrice RAID care face parte dintr-un sistem oprit pentru o perioadă mică de timp, permițând conținutului cache-ului unui controler RAID să rămână intact. Acest lucru poate fi un salvator dacă informațiile sunt în mod constant introduse în matricea dvs. RAID și orice timp de nefuncționare ar putea provoca corupția datelor.deci, sistemul dvs. fizic și serviciile din interior pot fi construite redundant destul de adecvat. Dar cum rămâne cu conexiunea dvs. cu orice parte a sistemului dvs.? Ca și în, Conexiunea directă la internet la sistemul dvs. ca un întreg?
redundanță de rețea
primele protocoale de redundanță Hop (FHRP)
spre deosebire de protocoalele dinamice de descoperire a gateway – ului, gateway-urile statice permit hamei simple între client și gateway-ul corespunzător, dar acest lucru creează un singur punct de eșec-și anume gateway-ul în sine.
pentru a preveni sau a reduce impactul eșecului gateway-ului, au fost create Fhrp-uri. Acestea oferă gateway-uri redundante o rezervă sau oferă echilibrarea sarcinii pentru sistemele cu trafic ridicat, împreună cu redundanța. Aceste protocoale includ VRRP, HSRP și GLBP.
Virtual Router Redundancy Protocol (VRRP)
VRRP este o formă de redundanță utilizată pentru routere care necesită cel puțin două routere separate fizic conectate fie prin conexiuni Ethernet, fie prin fibră optică. În această situație, un ‘router virtual’ care conține rute statice este creat și partajat între fiecare sistem.
un sistem este considerat ‘master’ și altul ‘backup’. Când maestrul eșuează, copia de rezervă preia ca următorul maestru. Acest lucru poate fi configurat cu mai multe copii de rezervă pentru redundanță suplimentară. Conceptul este foarte similar cu Heartbeat prin faptul că sistemele de rezervă vor verifica dacă master este disponibil. Odată ce nu primește un răspuns, după o perioadă predeterminată de timp, copia de rezervă va prelua controlul comutatorului virtual și va accepta conexiuni pentru toate cererile care vin pentru IP-ul implicit configurat pentru comutatorul principal.
Hot Standby Router Protocol (HSRP)
HSRP este ca VRRP; cu toate acestea, în acest scenariu, comutatorul virtual configurat nu este un ‘switch’, ci mai degrabă un grup logic de mai multe routere. IP-ul grupului este un IP care nu este atribuit unei gazde fizice. În schimb, grupului i se atribuie un IP și unul dintre routere este determinat a fi routerul ‘activ’.
un router standby este gata să ia orice conexiuni în cazul în care routerul activ merge în jos. Toate routerele, în afară de active și standby, ascultă toate pentru a-și determina locul în linie. HSRP este un protocol proprietar Cisco și are foarte puține diferențe minore față de VRRP, cum ar fi cronometrele implicite care determină când să eșueze. HSRP a fost în jur de un pic mai mult și este mai bine cunoscut în comparație cu VRRP.
Gateway Load Balancing Protocol (GLBP)
principalul avantaj al GLBP față de HSRP și VRRP este capacitatea sa de a încărca echilibrul pe lângă furnizarea de redundanță către un gateway cu o configurație suplimentară mică sau deloc. La fel ca HSRP și VRRP, GLBP va crea un grup între routerele fizice și va determina un Gateway Virtual activ sau AVG.
un IP virtual care nu este utilizat în prezent de niciunul dintre routerele din grup este atribuit AVG. AVG distribuie apoi adrese MAC virtuale între restul routerelor din grup. Fiecare router de rezervă este acum considerat un expeditor Virtual activ sau AVF.
cererile ARP trimise către AVG vor oferi o adresă MAC virtuală diferită clientului care trimite solicitarea. În acel moment, traficul de la acel client către IP-ul virtual al grupului se îndreaptă către routerul a cărui adresă MAC virtuală a primit-o, permițând fiecărui router să fie utilizat în continuare în loc să stea în brațe.
în cazul unui eșec al AVG, alegerile bazate pe prioritate au loc, la fel ca în HSRP și VRRP, iar următoarea copie de rezervă își ia locul, distribuind adresele MAC virtuale în mod normal. Celelalte routere păstrează în continuare adresa MAC virtuală furnizată de AVG originală și lucrurile continuă în mod normal. În cazul unei defecțiuni a unuia dintre AVFs, AVG va împiedica rutarea traficului către adresa sa virtuală MAC.la fel ca HSRP, GLBP este o formă proprietară Cisco a FHRP.
redundanța centrelor de date
pe lângă măsurile de redundanță pentru serverele sau routerele dvs. personale, centrele de date sunt concepute pentru a fi rezistente la defecțiunile sistemului. Centrele de date se încadrează în nivelurile definite de Uptime Institute pentru a oferi toleranță la erori pentru defectarea oricărei defecțiuni mecanice sau de serviciu, permițând cât mai mult timp posibil.
există patru niveluri, fiecare construindu-se unul pe altul pentru a oferi o disponibilitate ridicată tuturor clienților dintr-un centru de date:
- nivelul I-capacitate de bază: Acest lucru necesită spațiu pentru un grup IT pentru operațiunile centrelor de date, o sursă de alimentare neîntreruptibilă (UPS) care monitorizează și filtrează consumul de energie și echipamente de răcire dedicate care funcționează constant 24/7. Aceasta include, de asemenea, un generator de energie în caz de pană de curent electric.
- Nivelul II-componente de capacitate redundante: tot ceea ce oferă Nivelul I, plus puterea redundantă și răcirea instalației. Aceasta poate include unități UPS suplimentare sau generatoare suplimentare.
- Nivelul III – poate fi întreținut simultan: Tot ceea ce oferă Nivelul II, Plus echipamente suplimentare pentru a preveni orice nevoie de opriri pentru înlocuirea sau întreținerea echipamentelor. La acest nivel, puterea redundantă și răcirea sunt aplicate direct tuturor echipamentelor tehnice, iar echipamentul în sine este configurat pentru redundanță sau eșec fără probleme.
- Nivelul IV – toleranță la erori: tot ceea ce oferă nivelul III, plus servicii neîntrerupte la nivel de furnizor. În timp ce un centru de date poate avea electricitate sau apă furnizată de un furnizor de oraș sau de stat, este necesară o linie secundară a fiecărui serviciu utilizat de centrul de date. Aceasta include și ISP-ul. În cazul unei defecțiuni la orice secțiune care duce la echipamentul clientului, există un plan de rezervă pregătit pentru o tranziție fără probleme.
concluzie
redundanța a devenit un termen de zi cu zi în industria IT din necesitate. Disponibilitatea ridicată a serviciilor oferă o experiență ușoară și fiabilă pentru clienții noștri.
fie la nivel de serviciu, fie la nivel de centru de date, furnizarea de redundanță sistemului dvs. este o problemă importantă și dificil de abordat. Sperăm că această lucrare a aruncat o lumină asupra opțiunilor disponibile și va ajuta la orice decizie luată cu privire la disponibilitatea ridicată în viitor.
gata să profite de Atlantic.Net sistemele redundante? Contactați-ne astăzi pentru a afla mai multe despre gazduire server dedicat cu Atlantic.Net.
==surse===
concepte de bază ale sistemului Redundant: http://www.ni.com/white-paper/6874/en/
Server rece/cald/fierbinte: http://searchwindowsserver.techtarget.com/definition/cold-warm-hot-server
disponibilitate ridicată Clustering: https://www.mulesoft.com/resources/esb/high-availability-cluster
Hyper-V Replica: https://technet.microsoft.com/en-us/library/jj134172(V=ws.11).aspx
Hyper-V and High Availability: https://technet.microsoft.com/en-us/library/hh127064.aspx
HAProxy Description: http://www.haproxy.org/#desc
HAProxy – They use it!: http://www.haproxy.org/they-use-it.html
Heartbeat: http://www.linux-ha.org/wiki/Main_Page
RAID Definition: http://searchstorage.techtarget.com/definition/RAID
Striping: http://searchstorage.techtarget.com/definition/disk-striping
RAID Battery Backup Units: https://www.thomas-krenn.com/en/wiki/Battery_Backup_Unit_(BBU/BBM)_Maintenance_for_RAID_Controllers
High-Availability – VRRP, HSRP, GLBP: http://www.freeccnastudyguide.com/study-guides/ccna/ch14/vrrp-hsrp-glbp/
Understanding VRRP: http://www.juniper.net/techpubs/en_US/junos/topics/concept/vrrp-overview-ha.html
Configuring VRRP: http://www.cisco.com/c/en/us/td/docs/ios-xml/ios/ipapp_fhrp/configuration/15-mt/fhp-15-mt-book/fhp-vrrp.html
Configuring GLBP: http://www.cisco.com/c/en/us/td/docs/ios-xml/ios/ipapp_fhrp/configuration/xe-3s/fhp-xe-3s-book/fhp-glbp.html
Explaining the Uptime Institute’s Tier Classification System: https://journal.uptimeinstitute.com/explaining-uptime-institutes-tier-classification-system/