nu este ‘acum o zi de date mari..’poveste care a dat naștere acestei ere a datelor mari, dar’ cu mult timp în urmă… ‘ oamenii au început să colecteze informații prin sondaje manuale, site-uri web, senzori, fișiere și alte forme de metode de colectare a datelor. Chiar și aceasta include organizații internaționale precum OMS, ONU care a colectat la nivel internațional toate seturile posibile de informații pentru monitorizarea și urmărirea activităților nu numai legate de oameni, ci și de vegetație și specii de animale pentru a lua decizii importante și a implementa acțiunile necesare.astfel, multinaționalele mari, în special companiile de comerț electronic și marketing, au început să utilizeze aceeași strategie pentru a urmări și monitoriza activitățile clienților pentru a promova mărci și produse care au dat naștere filialei analytics. Acum nu se va satura atât de ușor, deoarece companiile au realizat valoarea reală a datelor pentru luarea deciziilor de bază în fiecare fază a proiectului de la început până la sfârșit pentru a crea cele mai bune soluții optimizate în ceea ce privește costul, cantitatea, piața, resursele și îmbunătățirile.
V-urile Big Data sunt volumul, viteza, varietatea, veridicitatea, valența și valoarea și fiecare are impact asupra colectării, monitorizării, stocării, analizei și raportării datelor. Ecosistemul în ceea ce privește jucătorii tehnologici ai sistemului big data este așa cum se vede mai jos.

acum voi discuta fiecare tehnologie unul câte unul pentru a da o privire asupra componentelor și interfețelor importante.
cum de a extrage date din datele de Social Media de la Facebook, Twitter și linkedin în fișier csv simplu pentru prelucrare ulterioară.pentru a putea extrage date de pe Facebook folosind un cod python, trebuie să vă înregistrați ca dezvoltator pe Facebook și apoi să aveți un jeton de acces. Iată pașii pentru aceasta.
1. Mergi la link developers.facebook.com, creați un cont acolo.
2. Mergi la link developers.facebook.com/tools/explorer.
3. Du-te la” aplicațiile mele „drop jos în colțul din dreapta sus și selectați”Adăugați o aplicație nouă”. Alegeți un nume afișat și o categorie și apoi „creați ID-ul aplicației”.
4. Reveniți din nou la același link developers.facebook.com/tools/explorer. veți vedea” Graph API Explorer „sub” Aplicațiile mele ” în colțul din dreapta sus. Din meniul derulant „Graph API Explorer”, selectați aplicația.
5. Apoi, selectați”Get Token”. Din acest drop-down, selectați „Get User Access Token”. Selectați Permisiuni din meniul care apare și apoi selectați „Obțineți jeton de acces.”
6. Mergi la link developers.facebook.com/tools/accesstoken. selectați ” Debug „corespunzător”user Token”. Accesați „extindeți accesul la Token”. Acest lucru vă va asigura că tokenul dvs. nu expiră la fiecare două ore.
cod Python pentru a accesa datele publice Facebook:
accesați linkulhttps://developers.facebook.com/docs/graph-api dacă doriți să colectați date despre orice este disponibil public. A se vedeahttps://developers.facebook.com/docs/graph-api/referință/v2.7/. Din această documentație, alegeți orice câmp doriți din care doriți să extrageți date precum „grupuri” sau „pagini” etc. Accesați Exemple de coduri după ce le-ați selectat și apoi selectați „Facebook graph api” și veți primi sugestii despre cum să extrageți informații. Acest blog este în primul rând pe obținerea de date de evenimente.
în primul rând, importați ‘urllib3’, ‘facebook’, ‘cereri’ dacă acestea sunt deja disponibile. Dacă nu, descărcați aceste biblioteci. Definiți un jeton variabil și setați valoarea acestuia la ceea ce ați obținut mai sus ca „jeton de acces utilizator”.

extragerea datelor de pe Twitter:
simplu 2 pași pot fi urmate ca mai jos
- vă va împrumuta pe pagina de detalii de aplicare; treceți la fila ‘Chei și jetoane de acces’, derulați în jos și faceți clic pe’Creați tokenul meu de acces’. Notă valorile API Keyand API Secret pentru o utilizare viitoare. Tu nu trebuie să împartă aceste cu nimeni, se poate accesa contul dvs. în cazul în care obține cheile.
- în scopul de a extrage tweets, va trebui să stabilească o conexiune sigură între R și Twitter, după cum urmează,
#Clear R Mediu
rm(list=ls())
#încărcați biblioteci necesare
instala.pachete („twitteR”)
instala.pachete („ROAuth”)
biblioteca („twitteR”)
biblioteca („ROAuth”)
# Descărcați fișierul și stoca în directorul de lucru
descărcare.fișier (url = ” http://curl.haxx.se/ca/cacert.pem”, destfile= ” cacert.PEM”)
#introduceți consumerKey și consumerSecret de mai jos
acreditările < – OAuthFactory$new(consumerKey=’XXXXXXXXXXXXXXXXXX’,
consumerSecret=’XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX’,
requestURL=’https://api.twitter.com/oauth/request_token’,
accessURL=’https://api.twitter.com/oauth/access_token’,
authURL=’https://api.twitter.com/oauth/authorize’)
cred$strângere de mână(cainfo=”cacert.pem”)
#încărcați datele de autentificare
încărcați („autentificare twitter.Rdata”)
#înregistrați autentificarea Twitter
setup_twitter_oauth(acreditări$consumerKey, acreditări$consumerSecret, acreditări$oauthKey, acreditări$oauthsecret)
#extrage Tweets cu șir în cauză(primul argument), urmat de numărul de tweets (N) și limba (lang)
tweets <- searchTwitter(‘#DataLove’, n=10, lang=”en”)
acum Puteți căuta orice cuvânt în funcția de căutare Twitter pentru a extrage tweet-urile care conțin cuvântul.
extragerea datelor din Oracle ERP
puteți vizita linkul pentru a verifica extragerea pas cu pas a fișierului csv din Baza de date oracle ERP cloud.
achiziția și stocarea datelor:
acum, odată ce datele sunt extrase, acestea trebuie stocate și procesate, ceea ce facem în etapa de achiziție și stocare a datelor.
să vedem cum funcționează Spark, Cassandra, Flume, HDFS, HBASE.Spark poate fi implementat într-o varietate de moduri, oferă legături native pentru limbajele de programare Java, Scala, Python și R și acceptă SQL, streaming de date, învățare automată și procesare grafică.RDD este Cadrul pentru spark, care va ajuta în prelucrarea paralelă a datelor prin împărțirea în cadre de date.
pentru a citi datele de pe platforma Spark, utilizați comanda de mai jos
results = spark.sql („Selectați * de la oameni”)
nume = rezultate.hartă (lambda p: p.name)
Conectați-vă la orice sursă de date precum json, JDBC, Hive Pentru a scânteia folosind comenzi și funcții simple. Ca puteți citi datele json ca mai jos
spark.citește.json („s3n://…”).registerTempTable („json”)
rezultate = scânteie.sql („SELECT * FROM people JOIN json…”)
Spark constau din mai multe caracteristici, cum ar fi streaming din surse de date în timp real pe care le-am văzut mai sus, folosind R și python source.
în site-ul principal Apache spark puteți găsi multe exemple care arată cum poate spark să joace un rol în extragerea datelor, modelarea.
https://spark.apache.org/examples.html
Cassandra:
Cassandra este, de asemenea, o tehnologie Apache ca spark pentru stocarea și recuperarea datelor și stocarea în mai multe noduri pentru a oferi 0 toleranță la erori. Utilizează comenzi normale de baze de date, cum ar fi crearea, selectarea, actualizarea și ștergerea operațiunilor. De asemenea , puteți crea indexuri, vizualizare materializată și normală cu comenzi simple, cum ar fi în SQL. Extensia este că puteți utiliza tipul de date JSON pentru efectuarea operațiunilor suplimentare, cum ar fi așa cum se vede mai jos
introduceți în mytable JSON ‘{ „\”myKey\””: 0, „valoare”: 0}’
acesta oferă drivere Git hub open source pentru a fi utilizate cu.Net, Python, Java, PHP, NodeJs, Scala, Perl, ROR.
la configurarea bazei de date, trebuie să configurați numărul de noduri de nume de noduri, aloca token bazat pe sarcină pe fiecare nod. De asemenea, puteți utiliza comenzi de autorizare și rol pentru a gestiona permisiunea la nivel de date pe un nod dat.
Pentru mai multe detalii puteți consulta link-ul dat
http://cassandra.apache.org/doc/latest/configuration/cassandra_config_file.html
Casandra promite să atingă toleranța la erori 0, deoarece oferă mai multe opțiuni pentru a gestiona datele de pe un nod dat prin cache, gestionarea tranzacțiilor, replicarea, concurența pentru citire și scriere, comenzile de optimizare a discului, gestionarea transportului și lungimea dimensiunii cadrului de date.
HDFS
ceea ce îmi place cel mai mult la HDFS este pictograma sa, un elefant jumbo puternic și rezistent ca HDFS în sine.
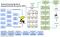
după cum se vede în diagrama de mai sus, sistemul HDFS pentru date mari este similar cu Cassandra, dar oferă o interfață foarte simplă cu sistemele externe.
Datele sunt tăiate în cadre de date de dimensiuni diferite sau similare, care sunt stocate în sistemul de fișiere distribuite. Datele sunt transferate în continuare la diferite noduri pe baza rezultatelor de interogare optimizate pentru a stoca date. Arhitectura de bază este de model centralizat de Hadoop dacă harta reduce modelul.
1. Datele sunt împărțite în blocuri de 128 MB
2. Aceste date sunt distribuite pe mai multe noduri
3. HDFS supraveghează procesarea
4. Replicarea și cache-ul sunt efectuate pentru a obține o toleranță maximă la erori.
5. după ce se efectuează harta și reducerea și se calculează cu succes lucrările, se întorc la serverul principal
Hadoop este codat în principal în Java, astfel încât este minunat dacă obțineți niște mâini pe Java decât va fi rapid și ușor de instalat și de rulat toate aceste comenzi.
Un ghid rapid pentru toate conceptul Hadoop legate pot fi găsite la link-ul de mai jos
https://www.tutorialspoint.com/hadoop/hadoop_quick_guide.html
raportare și vizualizare
acum vă permite să vorbim despre SAS, R studio și Kime, care sunt utilizate pentru analiza seturi mari de date cu ajutorul unor algoritmi complexe, care sunt algoritmi de învățare mașină, care se bazează pe unele modele matematice complexe, care analizează set complet de date și creează reprezentarea grafică pentru a participa la obiectivul specific de afaceri dorit. Exemplu de date de vânzări, potențialul pieței clienților, utilizarea resurselor etc.
SAS, R și Kinme toate cele trei instrumente oferă o gamă largă de caracteristici de la analize avansate, IOT, învățare automată, metodologii de gestionare a riscurilor, informații de securitate.
dar din moment ce unul dintre ele este comercial și alte 2 sunt sunt open source au unele diferențe majore între ele.
în loc să trec prin fiecare dintre ele unul câte unul, am rezumat fiecare dintre diferențele de software și câteva sfaturi utile care vorbesc despre ele.
