syftet med denna artikel är att förklara redundans när det gäller databehandling, nätverk och hosting. Vi kommer att ge verkliga exempel på redundanta tekniklösningar för att illustrera vad Redundans är och hur det fungerar.
Atlantic.Net har skapat flera värdmiljöer, inklusive en hållbar molnplattform, höghastighets VPS-värd, HIPAA-kompatibel infrastruktur och hanterad privat molnhotell. Alla våra system är byggda med redundans som en primär drivande faktor i designprocessen.
i vardaglig engelska kan redundans ha en negativ konnotation; något överflödigt behövs vanligtvis inte eller anses överflödigt. Men i en molnhotellmiljö kan redundans betyda skillnaden mellan sömlös systemtillgänglighet och oönskad eller oväntad stilleståndstid.
- Vad är ett Redundant System?
- typer av redundanta system
- exempel på redundanta mjukvarutjänster
- Hyper-V replika
- Hyper-V-kluster
- HAProxy
- Heartbeat
- exempel på redundanta Hårdvarutjänster
- RAID
- Nätverksredundans
- First Hop redundans Protocols (FHRP)
- Virtual Router Redundancy Protocol (VRRP)
- Hot Standby Router Protocol (HSRP)
- Gateway Load Balancing Protocol (GLBP)
- datacenter redundans
- slutsats
Vad är ett Redundant System?
ett redundant system kommer att ge failover eller lastbalansering stöd för att skydda ett levande system i händelse av ett oväntat fel. Vid ström -, mekanisk-eller programvarufel kommer ett redundant system att ha en duplikatkomponent eller plattform att falla tillbaka till. I allmänhet kan varje komponent i ett system med en enda felpunkt ses som en risk för produktionstjänster.
kraft-eller mekaniska system har enklare fallbackstrategier som kräver enbart närvaro av en annan av samma typ av tjänst; programvarufel kräver vanligtvis extra konfiguration på värdsystemet eller en master eller gateway.
redundans kapacitet rekommenderas för alla affärskritiska system, men särskilt för system som har en betydande inverkan under driftstopp. Vissa företag kan hålla alla sina kritiska kundinformation i en databas; därför, för kontinuitet ändamål, skydda databasen med redundans kommer att skydda dataintegritet i händelse av ett katastrofalt fel.
typer av redundanta system
ett redundant system består av minst två system som är sammankopplade och utformade för samma ändamål. Det finns många olika typer av redundanta systemkonfigurationer tillgängliga, och olika implementeringar av systemet ger unika metoder för att hålla ett system uppe hela tiden.
inte alla servrar behöver konfigureras med redundans; snarare bör endast de mest kritiska beaktas. Vi rekommenderar starkt detaljerad riskbedömning för att förstå vilka servrar som omfattas och hur mycket driftstopp dina servrar kan hantera. Använd denna bedömning för att bestämma en RTO (Recovery Time Objective) och RPO (Recovery Point Objective) strategi. RTO är den maximala mängden acceptabel stilleståndstid. Detta kan sträcka sig från 5 sekunder till 24 timmar. RPO är den tidpunkt från vilken du behöver dina data; till exempel kan ditt företag fungera med en maximal förlust av 24 timmar värde av data.
Här är några populära exempel:
- Aktiv-Inaktiv / varm-kall – när en komponent i ett system är det aktiva systemet och en annan är inaktiv eller stängs av. Den inaktiva komponenten aktiveras endast när komponenten som för närvarande körs misslyckas eller genomgår underhåll
- aktiv-Aktiv/Hot-Hot – när båda systemen är i drift och gör anslutningar. Detta är mest känt som kluster. Vanligtvis bestämmer enheten framför båda maskinerna hur man delar upp inkommande trafik
- Active-Standby / Hot-Warm – när båda systemen är på, men endast en gör anslutningar. Det andra systemet är tänkt att regelbundet ta emot uppdateringar eller säkerhetskopior från det primära systemet. I händelse av ett fel tar systemet i vänteläge den primära rollen tills det ursprungliga systemet kan återställas.
varje typ har sina egna fördelar och nackdelar.
- aktiva inaktiva / varma kalla system kan ge en enkel redundant plattform, men varje failover kommer att resultera i att användarna ser en äldre version av systemet.
- Active-Active / Hot-Hot kräver en ständig uppdatering av båda systemen, antingen manuellt eller via en separat tjänst, för att säkerställa att alla användare kan använda något av systemen. Detta tillvägagångssätt kan kraftigt minska den aktiva belastningen på en tjänst du tillhandahåller till kunderna.
- Active-Standby / Hot-Warm kommer att ge failover-funktionerna i hot-cold med en mer uppdaterad kopia av ditt aktiva system på failover, men det ger ingen belastningslättnad.
andra former av multipel nodredundans finns tillgängliga som möjliggör större redundans och robusta lastbalanseringslösningar. Vid den tiden har du ett kluster med hög tillgänglighet, även känt som ett HA-kluster.
detta kan använda valfri kombination av de tidigare noterade redundanslösningarna med maximal flexibilitet i tillvägagångssättet eller mängden redundans som behövs. HA-kluster kan också ställas in på flera fysiska platser för att möjliggöra tillgänglighet upp till Internet-ryggradsnivån.
exempel på redundanta mjukvarutjänster
kort om låg resurstillgänglighet finns det väldigt liten anledning att inte ha egen replikering eller redundanta tjänster som inrättats i en virtuell miljö; således är många sådana tjänster tillgängliga som standard i de flesta virtualiseringssystem. Alla våra molntjänster har replikering tillgänglig, en funktion som gör att vi kan replikera vilken server som helst från en nod till en annan, oavsett om de befinner sig i samma datacenter eller separata datacenterregioner.
Hyper-V replika
Hyper-V replika är en form av varm varm redundans. En primär virtuell maskin skapas på en fysisk värd och accepterar inkommande anslutningar. När du aktiverar replikering överförs de virtuella hårddiskarna på den nya maskinen till en separat fysisk Hyper-V-värd. Denna värd konfigurerar sedan en VM på sig själv som replikerar på ett användardefinierat schema för att säkerställa att den senaste bilden av den aktiva servern tas. Ytterligare kontrollpunkter kan också hållas. Hyper-V privat hosting med hanterade tjänster tillhandahålls av Atlantic.Net med den här funktionen bakad i; Kontakta vårt team för mer information.
Hyper-V-kluster
Hyper-V kan också klustera genom en anslutning till andra Hyper-V-värdar. Virtuella datorer på någon Hyper-V-värd kan grupperas tillsammans på den singulära värden för att ge redundans på lokal nivå genom virtuellt nätverk.
Microsoft Network Load Balancing (NLB) kan användas för att skapa en enda resurs som består av flera värdar som delar samma information för att ge en enkel åtkomstpunkt för fildelning. Eftersom detta bara begränsas av mängden resurser du har tillgängliga kan du teoretiskt ställa in flera värdar med flera virtuella datorer för maximal redundans, vilket också gör att du kan utföra underhåll på enskilda virtuella datorer utan att offra service eller resurstillgänglighet. Hyper-V privat hosting med hanterade tjänster tillhandahålls av Atlantic.Net med den här funktionen bakad i; Kontakta vårt team för mer information.
HAProxy
förutom Hyper-V kan en gateway-enhet som en brandvägg användas för failover eller lastbalanseringstjänster. Till exempel Atlanten.Net kan ge pfSense med hög tillgänglighet Proxy, även känd som HAProxy.
HAProxy kommer att fungera som en lastbalanserare, en proxy eller en enkel varm varm hög tillgänglighetslösning för TCP-och HTTP-baserade applikationer. HAProxy är en mycket populär, Linux-baserad öppen källkodslösning som används av några av de mest besökta webbplatserna i världen.
Heartbeat
Heartbeat är en tjänst tillgänglig på de flesta distributioner av Linux som används för att avgöra om noder i ett kluster är fortfarande upp eller lyhörd. Det är väldigt enkelt att installera och ger failover-funktioner till alla system som arbetar över TCP.
utvecklarna av Heartbeat rekommenderar också andra klusterresurshanterare som startar eller stoppar tjänster baserat på om en viss värd är nere. Heartbeat har detta inkluderat, men andra chefer är tillgängliga. På grund av hjärtslagets enkelhet är det mycket anpassningsbart. Cloud Hosting plattformar som tillhandahålls av Atlantic.Net har redan den här funktionen bakat in, och vi kan hjälpa dig med att implementera Heartbeat på din egen privata Linux-distribution, om det behövs.
exempel på redundanta Hårdvarutjänster
det bästa med redundant hårdvara är dess enkelhet. Även om mjukvarutjänster kan kräva överdriven konfiguration och möjligen är ganska känsliga, är hårdvaran vanligtvis mycket enkel att installera och otroligt hållbar. Det första exemplet vi kommer att titta på är den allmänt använda RAID-tekniken.
RAID
RAID står för Redundant Array of Independent Disks (eller Redundant Array of cheap Disks beroende på hur länge du har använt den) och har flera nivåer som används antingen för dataskydd eller ökad disk I/O.
RAID kan antingen ställas in via en mjukvaru-eller hårdvarukontroll. Styrenheten har den programvara och konfiguration som krävs för att hantera RAID-skivorna. Konfigurationen kan exporteras till olika system med liten eller ingen ytterligare konfiguration.
RAID kan ställas in på några olika sätt för att ge en bra balans mellan båda dess egenskaper:
- RAID 0 – Detta är i huvudsak ingen redundans. Inga diskar på systemet delar data genom spegling, men alla data är randiga över varje disk som ger ökad läs – /skrivhastighet. Varje enhet kan fortfarande använda lagringen som tillhandahålls till fullo, vilket betyder att ju fler enheter du lägger till i en RAID 0 desto mer utrymme har du.
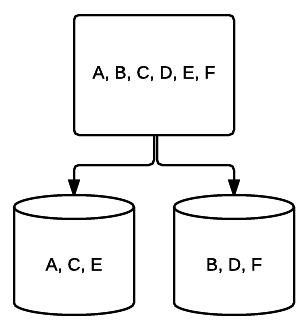
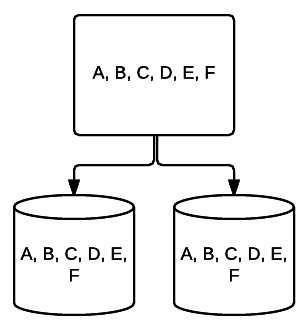
- RAID 1 – en grundläggande form av spegling ger utmärkt redundans på bekostnad av utrymme. I ett två-drivsystem skrivs en fullständig kopia av data på en enhet till den andra. Denna redundans förbättras med varje enhet som läggs till. Eftersom all data måste speglas över alla enheter, kommer det totala utrymmet på systemet att begränsas till bara utrymmet för den minsta enheten i systemet.
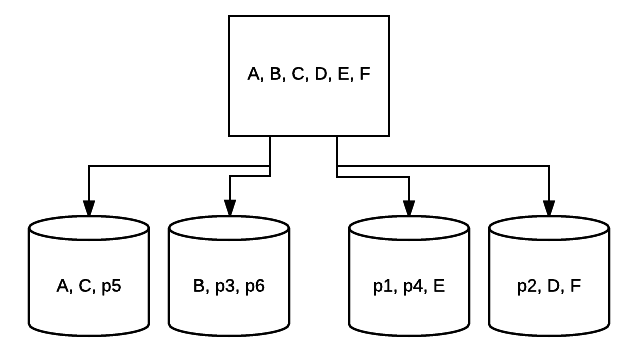
- RAID 5 – denna form av RAID används vanligtvis för att öka läshastigheten och tillförlitligheten. I det här fallet placeras ränder om varje enhet i systemet, med minst 3 enheter. Samtidigt placeras ett extra block av felkorrigerande data om varje enhet i en teknik som kallas paritet. Detta kontrollerar om data ändras vid överföring från en enhet till en annan. Detta ger också en minimal form av redundans eftersom 1 av dessa enheter kan misslyckas och systemet kan fortfarande köras. Ju fler enheter som läggs till i denna typ av RAID-installation, desto mer ökar din läshastighet. Med minimal redundans och striping över alla enheter är den totala mängden utrymme i denna inställning lika med storleken på din logiska RAID-volym gånger antalet enheter du använder, minus en. Om du till exempel har 5 500 GB-enheter i en RAID 5, skulle du ha 2000 GB användbar eller 2 TB (500 *(5-1)=2000).
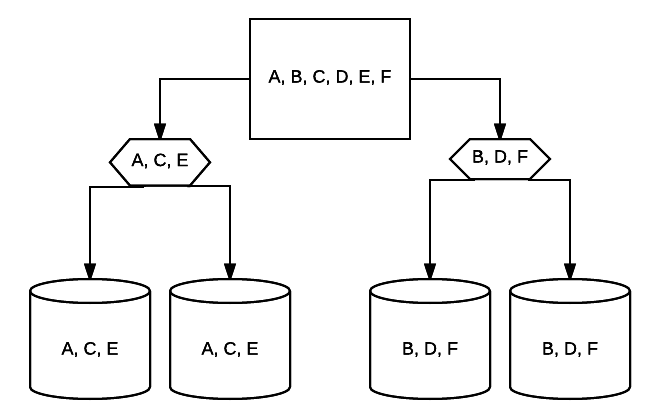
- RAID 10 – Detta är en kombination av RAID 1 och RAID 0. I det här fallet är alla data randiga över varje enhet med datablock som också speglas över hela det randiga systemet. Till exempel, i ett 4-enhet RAID 10-system kan 2 500 GB-enheter ha samma data, men inte alla data som behövs för att systemet ska fungera korrekt. 2 andra enheter data skulle krävas. Tänk på varje RAID 1-system som en enda enhet, och vart och ett av dessa system placeras i en RAID 0-array. I denna inställning kan prestanda ökas drastiskt som i RAID 0, med viss redundans fortfarande på plats med speglingen. Upp till hälften av enheterna i systemet kan misslyckas innan systemet kraschar, men som med alla redundanta array är det bäst att byta ut enheter så snart som möjligt. Atlantic.Net använder RAID 10 för alla SSD Cloud VPS Lagring.
För extra skydd skyddas RAID-kontrollerna av batteribackupenheter som driver ROM-chips som används för att spara konfigurationen i minnet vid strömförlust etc. En BBU kommer att ge ström till en RAID-array som ingår i ett avstängt system under en liten tid, vilket gör att innehållet i en RAID-kontrollers cache kan förbli intakt. Detta kan vara en livräddare om informationen ständigt matas in i din RAID-array och eventuella driftstopp kan orsaka datakorruption.
så, ditt fysiska system och tjänsterna inom kan konstrueras redundant ganska adekvat. Men hur är det med din anslutning till någon del av ditt system? Som i, din direkta internetanslutning till ditt system som helhet?
Nätverksredundans
First Hop redundans Protocols (FHRP)
i motsats till dynamiska gatewayupptäcktsprotokoll tillåter statiska gateways enkla humle mellan klienten och deras lämpliga gateway, men detta skapar en enda felpunkt – nämligen själva gatewayen.
För att förhindra eller minska effekten av gatewayfel skapades Fhrp: er. De ger redundanta gateways en reserv, eller erbjuder lastbalansering för högtrafiksystem, tillsammans med redundans. Dessa protokoll inkluderar VRRP, HSRP och GLBP.
Virtual Router Redundancy Protocol (VRRP)
VRRP är en form av redundans som används för routrar som kräver minst två fysiskt separata routrar anslutna via antingen Ethernet eller optiska fiberanslutningar. I den här situationen skapas och delas en virtuell router som innehåller statiska rutter mellan varje system.
ett system anses vara ’ master ’och ett annat’backup’. När master misslyckas tar säkerhetskopian över som nästa master. Detta kan ställas in med flera säkerhetskopior för extra redundans. Konceptet liknar Heartbeat genom att backupsystemen kommer att kontrollera om mastern är tillgänglig. När det inte får ett svar, efter en förutbestämd tid säkerhetskopieringen kommer att ta kontroll över den virtuella switch och acceptera anslutningar för alla förfrågningar som kommer in för standard IP konfigurerad för huvudströmställaren.
Hot Standby Router Protocol (HSRP)
HSRP är som VRRP; men i det här scenariot är den konfigurerade virtuella omkopplaren inte en ’switch’, utan snarare en logisk grupp av flera routrar. Gruppens IP är en IP som inte tilldelas en fysisk värd. Istället tilldelas gruppen en IP och en av routrarna bestäms vara den ’aktiva’ routern.
en standby-router är redo att ta alla anslutningar om den aktiva routern går ner. Alla routrar förutom aktiv och standby lyssnar alla för att bestämma sin plats i linje. HSRP är en Cisco proprietär protokoll och har mycket få, mindre skillnader till VRRP som deras standard timers bestämma när failover. HSRP har funnits lite längre och är mer känd jämfört med VRRP.
Gateway Load Balancing Protocol (GLBP)
GLBPS största fördel jämfört med HSRP och VRRP är dess förmåga att ladda balans utöver att ge redundans till en gateway med liten eller ingen extra konfiguration. Ungefär som HSRP och VRRP, GLBP kommer att skapa en grupp mellan fysiska Routrar och bestämma en aktiv virtuell Gateway, eller AVG.
en virtuell IP som för närvarande inte används av någon av routrarna i gruppen tilldelas AVG. AVG distribuerar sedan virtuella MAC-adresser bland resten av routrarna i gruppen. Varje backup router anses nu vara en aktiv virtuell speditör, eller AVF.
Arp-förfrågningar som skickas till AVG kommer att ge en annan virtuell MAC-adress till klienten som skickar begäran. Vid den tidpunkten vidarebefordrar trafiken från den klienten till gruppens virtuella IP till routern vars virtuella MAC-adress De fick, så att varje router fortfarande kan användas istället för att sitta ledigt.
i händelse av ett fel i AVG sker prioritetsbaserat val, precis som i HSRP och VRRP, och nästa säkerhetskopia tar sin plats och distribuerar virtuella MAC-adresser som vanligt. De andra routrarna behåller fortfarande den virtuella MAC-adressen som tillhandahålls av den ursprungliga AVG och saker fortsätter som vanligt. I händelse av ett fel på en av avf: erna kommer AVG att förhindra dirigering av trafik till sin virtuella MAC-adress.
precis som HSRP är GLBP en Cisco proprietär form av FHRP.
datacenter redundans
förutom redundansåtgärder för dina personliga servrar eller routrar är datacenter utformade för att vara motståndskraftiga mot systemfel. Datacenter faller under nivåer som definieras av Uptime Institute för att ge feltolerans för fel på mekaniska eller servicefel, vilket möjliggör så mycket drifttid som möjligt.
det finns fyra nivåer, var och en bygger på varandra för att ge hög tillgänglighet till alla kunder inom ett datacenter:
- Tier I-grundläggande kapacitet: Detta kräver utrymme för en IT-grupp för datacenteroperationer, en avbrottsfri strömförsörjning (UPS) som övervakar och filtrerar strömförbrukning och dedikerad kylutrustning som ständigt körs 24/7. Detta inkluderar också en kraftgenerator vid strömavbrott.
- Tier II – redundanta Kapacitetskomponenter: allt som Tier I tillhandahåller, Plus redundant ström och kylning till anläggningen. Detta kan inkludera extra UPS-enheter eller extra generatorer.
- Tier III – samtidigt underhållbar: Allt Tier II tillhandahåller, plus extra utrustning på plats för att förhindra behov av avstängningar för utbyte eller underhåll av utrustning. Vid denna nivå appliceras redundant kraft och kylning direkt på all teknisk utrustning, och själva utrustningen är konfigurerad för redundans eller sömlös failover.
- Tier IV-feltolerans: allt som Tier III tillhandahåller, plus oavbruten service på leverantörsnivå. Medan ett datacenter kan ha el eller vatten som tillhandahålls av en stad eller statlig leverantör, krävs en sekundär linje för varje tjänst som används av datacentret. Detta inkluderar även ISP. I händelse av ett fel i någon sektion som leder fram till klientutrustning finns det en reservplan på plats redo för en sömlös övergång.
slutsats
redundans har blivit en vardaglig term i IT-branschen på grund av nödvändighet. Den höga tillgängligheten av tjänster ger en enkel och pålitlig upplevelse för våra kunder.
oavsett om det är på servicenivå eller datacenternivå, är redundans till ditt system en viktig och svår fråga att ta itu med. Förhoppningsvis har detta dokument kasta lite ljus över de tillgängliga alternativen och kommer att hjälpa till i alla beslut som fattas om hög tillgänglighet framöver.
redo att dra nytta av Atlantic.Net redundanta system? Kontakta oss idag för att ta reda på mer om dedikerad server Hosting med Atlantic.Net.
===källor===
Redundant system grundläggande begrepp: http://www.ni.com/white-paper/6874/en/
kall/varm/varm Server: http://searchwindowsserver.techtarget.com/definition/cold-warm-hot-server
hög tillgänglighet Clustering: https://www.mulesoft.com/resources/esb/high-availability-cluster
Hyper-V replika: https://technet.microsoft.com/en-us/library/jj134172(V=ws.11).aspx
Hyper-V and High Availability: https://technet.microsoft.com/en-us/library/hh127064.aspx
HAProxy Description: http://www.haproxy.org/#desc
HAProxy – They use it!: http://www.haproxy.org/they-use-it.html
Heartbeat: http://www.linux-ha.org/wiki/Main_Page
RAID Definition: http://searchstorage.techtarget.com/definition/RAID
Striping: http://searchstorage.techtarget.com/definition/disk-striping
RAID Battery Backup Units: https://www.thomas-krenn.com/en/wiki/Battery_Backup_Unit_(BBU/BBM)_Maintenance_for_RAID_Controllers
High-Availability – VRRP, HSRP, GLBP: http://www.freeccnastudyguide.com/study-guides/ccna/ch14/vrrp-hsrp-glbp/
Understanding VRRP: http://www.juniper.net/techpubs/en_US/junos/topics/concept/vrrp-overview-ha.html
Configuring VRRP: http://www.cisco.com/c/en/us/td/docs/ios-xml/ios/ipapp_fhrp/configuration/15-mt/fhp-15-mt-book/fhp-vrrp.html
Configuring GLBP: http://www.cisco.com/c/en/us/td/docs/ios-xml/ios/ipapp_fhrp/configuration/xe-3s/fhp-xe-3s-book/fhp-glbp.html
Explaining the Uptime Institute’s Tier Classification System: https://journal.uptimeinstitute.com/explaining-uptime-institutes-tier-classification-system/