av: Arshad Ali / uppdaterad: 2020-07-29 / kommentarer (6)/relaterat: mer > gå med i tabeller
Problem
i tipset SQL Server Joinexempel, Jeremy Kadlec pratade om olika logiska join-operatörer, men hur implementerar SQL Server dem fysiskt? Vilka är de olika fysiska joinoperators? Hur skiljer de sig från varandra och i vilket scenario föredras enöver andra? I detta tips täcker vi dessa frågor och mer.
lösning
vi använder logiska operatorer när vi skriver frågor för att definiera en relationsfråga påden konceptuella nivån (vad som behöver göras). SQL implementerar dessa logiska operatörermed tre olika fysiska operatörer för att implementera den operation som definierats av delogiska operatörerna (hur det behöver göras). Även om det finns dussintals physicaloperators, i detta tips kommer jag att täcka specifika fysiska join operatörer. Även om vi har olika typer av logiska kopplingar på konceptuell/frågenivå, men SQL Serverimplements dem alla med tre olika fysiska kopplingsoperatörer som diskuteras nedan.
Vi kommer att täcka:
- Nested Loops Join
- Merge Join
- Hash Join
Vi kommer att titta påutförande planer för att se dessa operatörer och jag kommer att förklara varför varje inträffar.
För dessa exempel använder jag theAdventureWorks-databasen.
SQL Server Nested Loops Join Explained
innan du gräver in i detaljerna, låt mig först berätta vad en Nested Loops joinis om du är ny i programmeringsvärlden.
en kapslade slingor sammanfogning är en logisk struktur där en slinga (iteration) residesinuti en annan, det vill säga för varje iteration av den yttre slingan exekveras/bearbetas alla deiterationer av den inre slingan.
en kapslade loopar går fungerar på samma sätt. En av sammanfogningstabellerna är betecknadsom det yttre bordet och en annan som det inre bordet. För varje rad i den yttre tabellen matchas alla rader från den inre tabellen en efter en om raden matchardet ingår i resultatuppsättningen annars ignoreras det. Sedan nästa rad fråndet yttre bordet plockas upp och samma process upprepas och så vidare.
SQL Server optimizer kan välja en kapslade loopar gå när en av joiningtables är liten (betraktas som den yttre tabellen) och en annan är stor (anses den inre tabellen som indexeras på kolumnen som är i kopplingen) och henceit kräver minimal I/O och minst jämförelser.
optimizer anser tre varianter för en kapslade loopar ansluta:
- naive nested loops join i vilket fall sökningen skannarhela tabellen eller index
- index nested loops join när sökningen kan använda anexisting index för att utföra uppslag
- tillfälliga index nested loops join om optimizer createsa tillfälligt index som en del av frågeplanen och förstör det efter query executioncompletes
ett index Nested Loops join presterar bättre än en merge join eller hash join ifa liten uppsättning rader är inblandade. Medan, om en stor uppsättning rader är inblandade theNested Loops join kanske inte är ett optimalt val. Kapslade loopar stöder nästan alljoin typer utom höger och full yttre kopplingar, höger semi-join och höger anti-semijoins.
- I Script # 1 går jag med i SalesOrderHeader-tabellen med SalesOrderDetailtable och specificerar kriterierna för att filtrera resultatet av kunden withCustomerID = 670.
- detta filtrerade kriterier returnerar 12 poster från SalesOrderHeader-tabellenoch därmed är den mindre, den här tabellen har betraktats somyttertabell (topp en i den grafiska frågekörningsplanen)av optimeraren.
- för varje rad i dessa 12 rader i den yttre tabellen matchas radarfrån den inre tabellförsäljningsdetaljen (eller innertabellen skannas 12 gånger varje gång för varje rad med indexsöknings-eller korrelatparametern från den yttre tabellen) och 312 matchande rader returneras som du kanse i den andra bilden.
- i den andra frågan nedan använder jag SET STATISTICS PROFILE på för att displayprofile information om frågans utförande tillsammans med frågeresultatuppsättningen.
Script #1 – kapslade slingor gå exempel
SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader H INNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID = 670
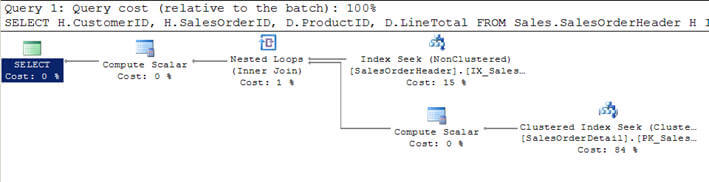
SET STATISTICS PROFILE ONSELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader HINNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderIDWHERE H.CustomerID = 670SET STATISTICS PROFILE OFF

om antalet poster som är inblandade är stort kan SQL Server välja att parallellisera en kapslad slinga genom att fördela de yttre tabellraderna slumpmässigt bland de tillgängliga looparna trådar dynamiskt. Det gäller dock inte detsamma för de inre tabellerna. För att lära dig mer om parallel scansclick här.
SQL Server Merge Join Explained
det första som du behöver veta om en Merge join är att det requiresboth ingångar som ska sorteras på join keys/merge kolumner (eller båda inmatningstabellerna har clusteredindex på kolumnen som ansluter tabellerna) och det kräver också minst en equijoin(lika med) uttryck/predikat.
eftersom raderna är försorterade börjar en sammanfogning omedelbart matchningsprocessen. Den läser en rad från en ingång och jämför den med raden i en annan ingång.Om raderna matchar, den matchade raden beaktas i resultatuppsättningen (då läser dennästa rad från inmatningstabellen, gör samma jämförelse/match och så vidare) orelse den mindre av de två raderna ignoreras och processen fortsätter på detta sätt tillsalla rader har bearbetats..
en sammanfogning går bättre när man går med i stora inmatningstabeller (förindexerad / sorterad)eftersom kostnaden är summan av rader i båda inmatningstabellerna i motsats till NestedLoops där det är en produkt av rader i båda inmatningstabellerna. Ibland bestämmer optimizerdecides att använda en sammanfogning när inmatningstabellerna inte sorteras och därför använder den en explicit sorterings fysisk operatör, men det kan vara långsammare än att använda ett index(försorterad inmatningstabell).
- I Script # 2 använder jag en liknande fråga som ovan, men den här gången har jag lagt till en where-klausul för att få alla kunder större än 100.
- i det här fallet beslutar optimeraren att använda en sammanfogning eftersom båda ingångarna är stora i termer av rader och de är också förindexerade/sorterade.
- Du kan också märka att båda ingångarna endast skannas en gång i motsats till de 12 skanningar vi såg i de kapslade slingorna går med ovan.
Script #2 – sammanfoga gå exempel
SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader H INNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID > 100
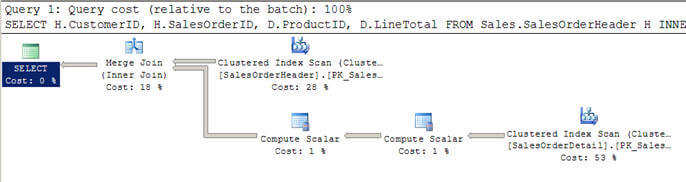
SET STATISTICS PROFILE ONSELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader HINNER JOIN Sales.SalesOrderDetail D ON H.SalesOrderID = D.SalesOrderIDWHERE H.CustomerID > 100SET STATISTICS PROFILE OFF

en Merge Join är ofta en effektivare och snabbare join operator om sorteddata kan erhållas från ett befintligt B-tree index och det utför nästan alla joinoperationer så länge det finns minst ett equality join-predikat involverat. Det stöder också flera jämställdhetsanslutningspredikat så länge inmatningstabellerna sorteras på alla inblandade anslutningstangenter och är i samma ordning.
närvaron av en Compute Scalar operator indikerar utvärderingen av ett uttryckatt producera ett beräknat skalärt värde. I ovanstående fråga väljer jag Linetotalvilket är en härledd kolumn, varför den har använts i exekveringsplanen.
SQL Server Hash Join Explained
en Hash join används normalt när inmatningstabeller är ganska stora och inga adekvata index finns på dem. En Hash join utförs i två faser; byggfasen och Sondfasen och därmed hash-anslutningen har två ingångar, dvs byggingång och probeinput. Den mindre av ingångarna betraktas som byggingången (för att minimera thememory krav på att lagra en hashtabell som diskuteras senare) och uppenbarligen är den andra sondinmatningen.
under byggfasen skannas sammanfogningstangenterna för alla rader i byggtabellen.Hashar genereras och placeras i en hash-tabell i minnet. Till skillnad från sammanfogningen blockerar den (inga rader returneras) fram till denna punkt.
under sondfasen skannas sammanfogningstangenterna för varje rad i sondtabellen.Återigen genereras hashar (med samma hashfunktion som ovan) och jämförs mot motsvarande hashtabell för en match.
en hashfunktion kräver betydande mängd CPU-cykler för att generera hashesoch minnesresurser för att lagra hashtabellen. Om det finns minnestryck byts några av partitionerna i hashtabellen till tempdb och närhelst det finns behov (antingen för att sondra eller uppdatera innehållet) återförs det till cachen.För att uppnå hög prestanda, kan query optimizer parallellisera en Hash gå toscale bättre än någon annan gå, för mer detailsclick här.
det finns i princip tre olika typer av hash-anslutningar:
- In-memory Hash-anslutning i vilket fall tillräckligt med minne finns tillgängligt för att lagra hash-tabellen
- Grace Hash-anslutning i vilket fall hash-tabellen inte kan passa i minnet och vissa partitioner spills till tempdb
- rekursiv Hash-anslutning i vilket fall en hash-tabell är så storoptimeraren måste använda många nivåer av sammanfogning.
För mer information om dessa olika typerklicka här.
- I Script # 3 skapar jag två nya stora tabeller (från befintliga AdventureWorkstables) utan index.
- Du kan se optimizer valde att använda en Hash gå i det här fallet.
- igen till skillnad från en kapslade slingor gå, det inte skanna den inre tabellen multipletimes.
Script #3 – Hash ansluta exempel
--Create tables without indexes from existing tables of AdventureWorks database SELECT * INTO Sales.SalesOrderHeader1 FROM Sales.SalesOrderHeader SELECT * INTO Sales.SalesOrderDetail1 FROM Sales.SalesOrderDetail GO SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader1 H INNER JOIN Sales.SalesOrderDetail1 D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID = 670 GO
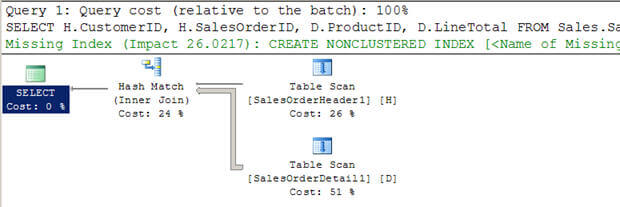
SET STATISTICS PROFILE ON SELECT H.CustomerID, H.SalesOrderID, D.ProductID, D.LineTotal FROM Sales.SalesOrderHeader1 H INNER JOIN Sales.SalesOrderDetail1 D ON H.SalesOrderID = D.SalesOrderID WHERE H.CustomerID = 670 SET STATISTICS PROFILE OFF

--Drop the tables created for demonstration DROP TABLE Sales.SalesOrderHeader1 DROP TABLE Sales.SalesOrderDetail1
Obs: SQL Server gör ett ganska bra jobb för att bestämma vilken joinoperator som ska användas i varje tillstånd. Att förstå dessa villkor hjälper dig att förståvad som kan göras i prestandajustering. Det rekommenderas inte att använda join tips (usingOPTION klausul) för att tvinga SQL Server att använda en specifik join operator (om du inte haringen annan väg ut), utan snarare kan du använda andra medel som att uppdatera statistik,skapa index eller skriva om din fråga.
nästa steg
- Recensionerql ServerJoin exempel tips.
- ReviewLogical och fysiska operatörer referens artikel om technet.
Senast uppdaterad: 2020-07-29


 Arshad Ali is a SQL and BI Developer focusing on Data Warehousing projects for Microsoft.
Arshad Ali is a SQL and BI Developer focusing on Data Warehousing projects for Microsoft.View all my tips
- More Database Developer Tips…