
Når Det gjelder operasjonalisering av loggdataene dine, gir HAProxy et vell av informasjon. I dette blogginnlegget demonstrerer vi hvordan du setter Opp haproxy-logging, målretter Mot En Syslog-server, forstår loggfeltene og foreslår noen nyttige verktøy for analyse av loggfiler.
Dyp Dykk Inn I HAProxy Logging
HAProxy sitter i den kritiske banen til infrastrukturen din. Enten det brukes som en kantbelastningsbalanser, en sidevogn eller Som Kubernetes ingress controller, er det viktig å få meningsfulle logger ut av HAProxy.
Logging gir deg innsikt om hver tilkobling og forespørsel. Det muliggjør observerbarhet som trengs for feilsøking og kan til og med brukes til å oppdage problemer tidlig. Det er en av de mange måtene Å få informasjon Fra HAProxy. Andre måter inkluderer å få beregninger ved Hjelp Av Statistikksiden ELLER Runtime API, sette opp e-postvarsler og bruke de forskjellige open source-integrasjonene for lagring av logg eller statistiske data over tid. HAProxy gir svært detaljerte logger med millisekund nøyaktighet og genererer et vell av informasjon om trafikk som strømmer inn i infrastrukturen. Dette inkluderer:
- Beregninger om trafikken: timing data, tilkoblinger tellere, trafikk størrelse, etc.
- Informasjon Om haproxy beslutninger: innhold bytte, filtrering, utholdenhet, etc.
- Informasjon om forespørsler og svar: overskrifter, statuskoder, nyttelast, etc.
- Avslutningsstatus for en økt og muligheten til å spore hvor feil oppstår (klientside, serverside?)
i dette innlegget lærer du hvordan du konfigurerer haproxy-logging og hvordan du leser loggmeldingene som den genererer. Vi viser deretter noen verktøy som du finner nyttige når du opererer loggdataene dine.
Syslog Server
HAProxy kan sende loggmelding for behandling av en syslog server. Dette er kompatibelt med kjente syslog-verktøy som Rsyslog, samt den nyere systemd-tjenesten journald. Du kan også bruke ulike logg speditører Som Logstash Og Fluentd å motta Syslog meldinger Fra HAProxy og sende dem til en sentral logg aggregator.
hvis Du jobber i et containermiljø, støtter HAProxy Cloud Native Logging som lar deg sende loggmeldingene til stdout og stderr. I så fall hopper du til neste avsnitt der du ser hvordan.
Før du ser på hvordan du aktiverer logging via HAProxy-konfigurasjonsfilen, bør du først sørge for at Du har En Syslog-server, for eksempel rsyslog, konfigurert til å motta loggene. På Ubuntu vil du installere rsyslog ved hjelp av apt package manager, slik som:
når rsyslog er installert, rediger konfigurasjonen for å håndtere inntak Av haproxy-loggmeldinger. Legg til følgende enten til /etc/rsyslog.conf eller til en ny fil i rsyslog.d directory, som /etc/rsyslog.d / haproxy.conf:
start deretter rsyslog-tjenesten på nytt. I eksemplet ovenfor lytter rsyslog PÅ IP loopback-adressen, 127.0.0.1, på standard UDP-port 514. Denne spesielle config skriver til to loggfiler. Filen som er valgt, er basert på alvorlighetsgraden som meldingen ble logget på. For å forstå dette, ta en nærmere titt på de to siste linjene i filen. De begynner slik:
Syslog-standarden foreskriver at hver loggede melding skal tilordnes en fasilitetskode og et alvorlighetsgrad. Gitt eksemplet rsyslog-konfigurasjonen ovenfor, kan du anta at vi konfigurerer HAProxy for å sende alle loggmeldingene med en anleggskode for local0.
alvorlighetsgraden er angitt etter fasilitetskoden, adskilt av en prikk. Her fanger den første linjen meldinger på alle alvorlighetsnivåer og skriver dem til en fil som heter haproxy-traffic.logge. Den andre linjen fanger bare varsel-nivå meldinger og over, logge dem til en fil som heter haproxy-admin.logge.
HAProxy er hardkodet for å bruke visse alvorlighetsgrad når du sender bestemte meldinger. Den kategoriserer for eksempel loggmeldinger relatert til tilkoblinger og HTTP-forespørsler med informasjonens alvorlighetsgrad. Andre hendelser er kategorisert ved hjelp av en av de andre, mindre ordrike nivåer. Fra mest til minst viktig er alvorlighetsgraden:
| Alvorlighetsgrad | HAProxy Logs |
| emerg | feil som å gå tom for operativsystemfilbeskrivelser. |
| alert | noen sjeldne tilfeller der noe uventet har skjedd, for eksempel å ikke kunne cache et svar. |
| crit | Ikke brukt. |
| err | Feil som å ikke kunne analysere en kartfil, å ikke kunne analysere HAProxy konfigurasjonsfilen, og når en operasjon på en pinne tabellen mislykkes. |
| advarsel | Visse viktige, men ikke-kritiske feil som å ikke angi en forespørselshode eller ikke koble til EN DNS-navneserver. |
| merknad | Endringer i en servers tilstand, for EKSEMPEL OPP eller NED eller når en server er deaktivert. Andre hendelser ved oppstart, for eksempel startproxyer og lastemoduler, er også inkludert. Helsesjekk logging, hvis aktivert, bruker også dette nivået. |
| info | DETALJER OG FEIL FOR tcp-tilkobling OG HTTP-forespørsel. |
| debug | Du kan skrive tilpasset Lua-kode som logger debug-meldinger |
Moderne Linux-distribusjoner leveres med service manager systemd, som introduserer journald for innsamling og lagring av logger. Journald tjenesten er ikke En Syslog implementering, men Det Er Syslog kompatibel siden det vil lytte på samme/dev / log socket. Det vil samle de mottatte loggene og tillate brukeren å filtrere dem etter fasilitetskode og / eller alvorlighetsgrad ved hjelp av tilsvarende journald-felt (SYSLOG_FACILITY, PRIORITY).
Haproxy Logging Configuration
haproxy configuration manual forklarer at logging kan aktiveres med to trinn: den første er å spesifisere En Syslog server iglobal seksjon ved hjelp av enlog direktivet:
log div > direktivet instruerer haproxy Å Sende Logger til syslog server lytting på 127.0.0.1:514. Meldinger sendes med facility local0, som er en av de standard, brukerdefinerte Syslog-fasilitetene. Det er også anlegget som vår rsyslog-konfigurasjon forventer. Du kan legge til mer enn enlog – setning for å sende utdata til Flere Syslog-servere.
du kan kontrollere hvor mye informasjon som logges ved å legge Til Et Syslog-nivå på slutten av linjen:
det andre trinnet for å konfigurere logging er å oppdatere de forskjellige proxyene (frontendbackend og listen seksjoner) for å sende meldinger til syslog-serveren(e) konfigurert i global – Delen. Dette gjøres ved å legge til etlog global – direktiv. Du kan legge den tildefaults – delen, som vist:
log global – direktivet sier i utgangspunktet, bruk log – linjen som ble satt i global – delen. Å sette etlog global – direktiv idefaults – delen tilsvarer å sette den inn i alle de påfølgende proxy-seksjonene. Så, dette vil gjøre det mulig å logge på alle proxyer. Du kan lese mer om delene Av en haproxy-konfigurasjonsfil i blogginnlegget De Fire Viktige Delene av En Haproxy-Konfigurasjon.
som standard er utdata fra HAProxy minimal. Hvis du legger til linjen option httplog tildefaults – delen, aktiveres MER detaljert HTTP-logging, som vi vil forklare mer detaljert senere.
en typisk haproxy-konfigurasjon ser slik ut:
bruk av globale loggingsregler Er det vanligste haproxy-oppsettet, men du kan sette dem direkte inn i enfrontend – delen i stedet. Det kan være nyttig å ha en annen logging konfigurasjon som en engangs. Du kan for eksempel peke På En Annen Mål Syslog-server, bruke et annet loggingsanlegg eller registrere forskjellige alvorlighetsgrad, avhengig av brukstilfellet til backend-programmet. Tenk på følgende eksempel derfrontend seksjoner, fe_site1 og fe_site2, angir FORSKJELLIGE IP-adresser og alvorlighetsgrad:
når du logger på en lokal Syslog-tjeneste, kan det være raskere å skrive til EN UNIX-kontakt enn å målrette tcp-tilbakekoblingsadressen. Generelt, På Linux-systemer, ER EN UNIX socket lytting For Syslog meldinger tilgjengelig på / dev / log fordi det er her syslog () funksjonen TIL GNU C biblioteket sender meldinger som standard. Mål UNIX-kontakten slik:
du bør imidlertid huske på at HVIS du skal bruke EN UNIX—kontakt for logging og samtidig kjører Du HAProxy i et chrooted miljø—eller du lar HAProxy opprette en chroot katalog for deg ved å bruke chroot configuration directive-DA MÅ UNIX-kontakten gjøres tilgjengelig i den chroot-katalogen. Dette kan gjøres på en av to måter.
Først når rsyslog starter opp, kan det opprette en ny lyttekontakt i chroot filsystem. Legg til følgende i haproxy rsyslog-konfigurasjonsfilen:
den andre måten er å manuelt legge til kontakten i chroot-filsystemet ved å brukemount – kommandoen med --bind – alternativet.
Pass på å legge til en oppføring i / etc / fstab-filen eller en systemd-enhetsfil slik at monteringen vedvarer etter en omstart. Når du har logget konfigurert, vil du forstå hvordan meldingene er strukturert. I neste avsnitt ser du feltene som utgjør tcp-og HTTP-nivåloggene.
hvis du trenger å begrense mengden data som er lagret, er det en måte å prøve bare en del av loggmeldingene. Sett loggnivået til stille for et tilfeldig antall forespørsler, som så:
Merk at hvis det er mulig, er det bedre å fange så mye data som mulig. På den måten mangler du ikke informasjon når du trenger det mest. DU kan også endre ACL-uttrykket slik at visse betingelser overstyrer regelen.
En annen måte å begrense antall meldinger logget er å sette option dontlog-normal i defaultsellerfrontend. På den måten blir bare tidsavbrudd, forsøk og feil fanget. Du vil sannsynligvis ikke aktivere dette hele tiden, men bare i bestemte tider, for eksempel når du utfører benchmarking tester.
hvis Du kjører HAProxy inne I En Docker-beholder og du bruker haproxy versjon 1.9, kan du i stedet for å sende loggutgang til En Syslog-server sende den til stdout og / eller stderr. Angi adressen til stdoutellerstderr, henholdsvis. I så fall er det også å foretrekke å sette formatet på meldingen til raw, slik som:
HAProxy Log Format
typen logging du vil se, bestemmes av proxy-modusen du angir i HAProxy. HAProxy kan operere enten Som En Layer 4 (TCP) proxy eller Som Layer 7 (HTTP) proxy. TCP-modus er standard. I denne modusen etableres en full dupleksforbindelse mellom klienter og servere, og ingen lag 7-undersøkelse vil bli utført. Hvis du har satt din rsyslog-konfigurasjon basert på vår diskusjon i den første delen, finner du loggfilen på /var / log / haproxy-traffic.logge.
når DU er I TCP-modus, som er satt ved å legge til mode tcp, bør du også legge til alternativ tcplog. Med dette alternativet er loggformatet standardisert til en struktur som gir nyttig informasjon som tilkoblingsdetaljer For Lag 4, tidtakere, byteantall osv. Hvis du skulle gjenskape dette formatet ved hjelp av log-format, som brukes til å angi et egendefinert format, vil det se slik ut:
Beskrivelser av disse feltene finner du i tcp log format dokumentasjon, selv om vi vil beskrive flere i den kommende delen.
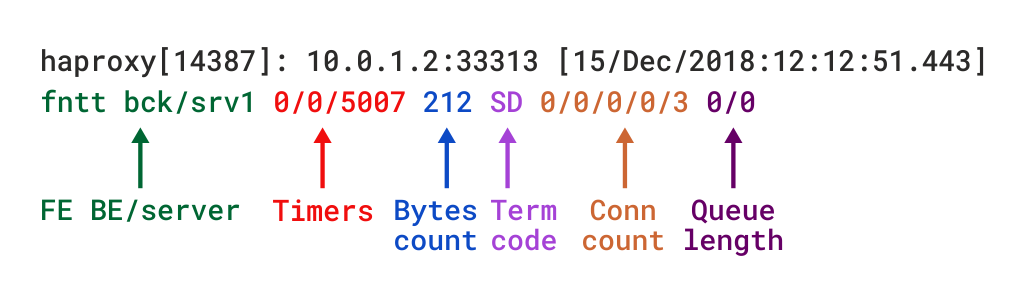
TCP loggformat I HAProxy
Når HAProxy kjøres som En Lag 7-proxy via mode http, bør du legge til alternativet httplog-direktiv. DET sikrer AT HTTP-forespørsler og svar blir analysert i dybden, og at INGEN RFC-kompatibelt innhold vil gå uoppdaget. Dette er modusen som virkelig fremhever diagnostisk verdi Av HAProxy. HTTP-loggformatet gir samme nivå av informasjon som TCP-formatet, men med tilleggsdata som er spesifikke FOR HTTP-protokollen. Hvis du skulle gjenskape dette formatet ved hjelp av log-format, vil Det se slik ut:
Detaljerte beskrivelser av de ulike feltene finnes i HTTP-loggformatdokumentasjonen.
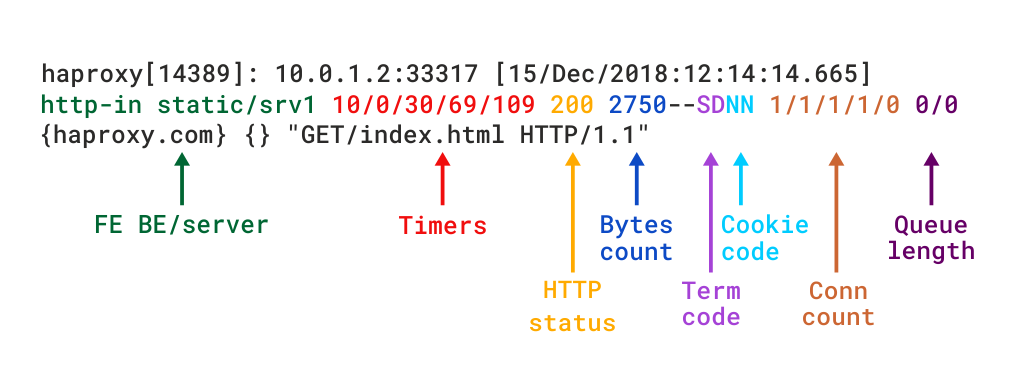
HTTP log format i HAProxy
DU kan også definere et tilpasset loggformat, fange bare det du trenger. Bruk log-format (eller log-format-sd for strukturerte data syslog) direktivet i defaults eller frontend. Les vårt blogginnlegg HAProxy Log Tilpasning for å lære mer og se noen eksempler.
i de neste seksjonene blir du kjent med feltene som er inkludert når du bruker option tcplogeller option httplog.
Proxyer
i loggfilen som produseres, begynner hver linje med frontend, backend og server som forespørselen ble sendt til. Hvis du for eksempel hadde Følgende HAProxy-konfigurasjon, vil du se linjer som beskriver forespørsler som rutes via http-i frontend til statisk backend og deretter til srv1-serveren.
Dette blir viktig informasjon når du trenger å vite hvor en forespørsel ble sendt, for eksempel når du ser feil som bare påvirker noen av serverne dine.
Timere
Timere leveres i millisekunder og dekker hendelsene som skjer under en økt. Tidtakere fanget av standard tcp loggformat Er Tw / Tc / Tt. DE som leveres av STANDARD HTTP-loggformat ER TR / Tw / Tc / Tr / Ta. Disse oversetter som:
| Timer | Betydning |
| TR | total tid for å få klientforespørselen (KUN HTTP-modus). |
| Tw | total tid brukt i køene som venter på et tilkoblingsspor. |
| Tc | den totale tiden for å etablere tcp-tilkoblingen til serveren. |
| Tr | serverens responstid (KUN HTTP-modus). |
| Ta | den totale aktive tiden FOR HTTP-forespørselen(KUN HTTP-modus). |
| tt | den totale TCP-øktvarigheten, mellom det øyeblikket proxyen aksepterte det og det øyeblikket begge ender ble stengt. |
du finner en detaljert beskrivelse av alle tilgjengelige timere i haproxy-dokumentasjonen. Følgende diagram viser også hvor tiden registreres under en enkelt ende-til-ende-transaksjon. Legg merke til at de lilla linjene på kantene angir timere.
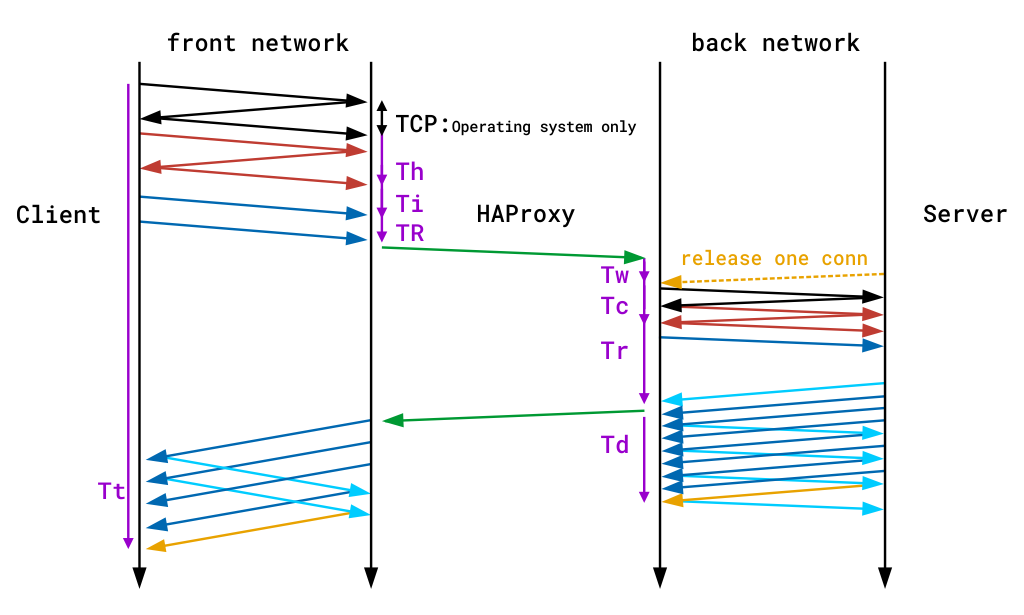
tidsregistrering under en enkelt ende-til-ende-transaksjon
Øktstatus Ved Frakobling
BÅDE TCP-og HTTP-logger inneholder en avslutningstilstandskode som forteller deg hvordan TCP-eller HTTP-økten avsluttet. Det er en kode på to tegn. Det første tegnet rapporterer den første hendelsen som førte til at økten ble avsluttet, mens DET andre rapporterer tcp-eller HTTP-økttilstanden da den ble lukket.
her er noen termineringskode eksempler:
| kode Med to tegn | Betydning |
| – | normal avslutning på begge sider. |
| cD | klienten sendte ikke eller bekreftet noen data og til slutt timeout client utløpt. |
| SC | serveren nektet eksplisitt tcp-tilkoblingen. | PC | proxyen nektet å etablere en tilkobling til serveren fordi prosessens socket grense ble nådd under forsøk på å koble til. |
det er mange årsaker til at en forbindelse kan ha blitt stengt. Detaljert informasjon om alle mulige avslutningskoder finnes i haproxy-dokumentasjonen.
Tellere
Tellere angir helsen til systemet når en forespørsel gikk gjennom. HAProxy registrerer fem tellere for hver tilkobling eller forespørsel. De kan være uvurderlig i å bestemme hvor mye belastning blir plassert på systemet, hvor systemet er tregt, og om grensene har blitt truffet. Når du ser på en linje i loggen, vil du se tellerne oppført som fem tall atskilt med skråstreker: 0/0/0/0/0.
i ENTEN TCP-eller HTTP-modus brytes disse ned som:
- det totale antall samtidige tilkoblinger på haproxy-prosessen når økten ble logget.
- totalt antall samtidige tilkoblinger rutes gjennom denne
frontendnår økten ble logget. - totalt antall samtidige tilkoblinger rutes til denne
backendnår økten ble logget. - totalt antall samtidige tilkoblinger som fortsatt er aktive på denne
servernår økten ble logget. - antall forsøk på nye forsøk når du prøver å koble til backend-serveren.
Andre Felt
HAProxy registrerer ikke alt ut av boksen, men du kan justere det for å fange det du trenger. EN HTTP request header kan logges ved å legge tilhttp-request capture direktivet:
loggen vil vise overskrifter mellom klammeparenteser og atskilt med rørsymboler. Her kan Du se Verts-og Brukeragentoverskriftene for en forespørsel:
et svarhode kan logges ved å legge til et http-response capture direktiv:
I dette tilfellet må du også legge til et declare capture response direktiv, som tildeler et fangespor hvor svarhodet, når det kommer, kan lagres. Hvert spor du legger til, tildeles automatisk EN ID som starter fra null. Henvis denne IDEN når du ringer http-response capture. Svarhoder logges etter forespørselshodene i et separat sett med klammeparenteser.
Cookie verdier kan logges på en lignende måte medhttp-request capture direktivet.
alt som fanges opp med http-request capture, INKLUDERT HTTP-overskrifter og informasjonskapsler, vil vises i samme sett med klammeparenteser. Det samme gjelder for alt fanget med http-response capture.
Du kan også brukehttp-request capture for å logge samplede data fra pinne tabeller. Hvis du sporer brukerforespørselsfrekvenser med en stick-table, kan du logge dem slik:
så hvis du gjør en forespørsel til en nettside som inneholder HTML-dokumentet og to bilder, vil brukerens samtidige forespørselsfrekvens øke til tre:
du kan også logge verdiene for hentemetoder, for eksempel å registrere VERSJONEN AV SSL / TLS som ble brukt (merk at det er en innebygd loggvariabel for å få dette kalt %sslv):
Variabler satt med http-request set-var kan også logges.
ACL-uttrykk evalueres til sann eller usann. Du kan ikke logge dem direkte, men du kan angi en variabel basert på om uttrykket er sant. For eksempel, hvis brukeren besøker / api, kan du angi en variabel kalt req. is_api til en VERDI Av Is API og deretter fange det i loggene.
Aktivere Haproxy Profilering
med utgivelsen Av HAProxy 1.9, kan DU ta OPP CPU tid brukt på å behandle en forespørsel innen HAProxy. Legg til profiling.tasks direktivet til global seksjon:
det er nye hentemetoder som avslører profileringsberegningene:
| Hent metode | beskrivelse |
date_us |
Mikrosekunderdelen av datoen. |
cpu_calls |
antall anrop til oppgaven som behandler strømmen eller gjeldende forespørsel siden den ble tildelt. Den tilbakestilles for hver ny forespørsel på samme tilkobling. |
cpu_ns_avg |
gjennomsnittlig antall nanosekunder brukt i hvert anrop til oppgaven som behandler strømmen eller gjeldende forespørsel. |
cpu_ns_tot |
det totale antall nanosekunder brukt i hvert anrop til oppgaven som behandler strømmen eller gjeldende forespørsel. |
lat_ns_avg |
gjennomsnittlig antall nanosekunder brukt mellom det øyeblikket oppgaven håndtering av strømmen er våknet opp og det øyeblikket det er effektivt kalt. |
lat_ns_tot |
det totale antall nanosekunder mellom det øyeblikket oppgaven håndterer strømmen er våknet opp og det øyeblikket det er effektivt kalt. |
Legg til disse i loggmeldingene slik:
Dette er en fin måte å måle hvilke forespørsler som koster mest å behandle.
Parsing HAProxy Logs
Som du har lært, Har HAProxy mange felt som gir en enorm mengde innsikt om tilkoblinger og forespørsler. Men å lese dem direkte kan føre til overbelastning av informasjon. Ofte er det lettere å analysere og samle dem med eksterne verktøy. I denne delen ser du noen av disse verktøyene og hvordan De kan utnytte loggingsinformasjonen fra HAProxy.
HALog
HALog Er et lite, men kraftig logganalyseverktøy som leveres Med HAProxy. Den ble designet for å bli distribuert på produksjonsservere der den kan hjelpe med manuell feilsøking, for eksempel når du står overfor live-problemer. DET er ekstremt raskt og i stand TIL å analysere TCP-og HTTP-logger på 1 til 2 GB per sekund. Ved å sende det en kombinasjon av flagg, kan du trekke ut statistisk informasjon fra loggene, inkludert forespørsler per URL og forespørsler per kilde IP. Deretter kan du sortere etter responstid, feilfrekvens og avslutningskode.
hvis du for eksempel vil trekke ut statistikk per server fra loggene, kan du bruke følgende kommando:
Dette er nyttig når du må analysere logglinjer per statuskode og raskt oppdage om en gitt server er usunn(f. eks. Eller en server kan nekte for mange forespørsler (4xx svar), som er et tegn på et brute-force angrep. Du kan også få gjennomsnittlig responstid per server medavg_rt kolonnen, som er nyttig for feilsøking.
Med HALog kan du få per-URL-statistikk ved å bruke følgende kommando:
utdataene viser antall forespørsler, antall feil, total beregningstid, gjennomsnittlig beregningstid, total beregningstid for vellykkede forespørsler, gjennomsnittlig beregningstid for vellykkede forespørsler, gjennomsnittlig antall byte sendt og totalt antall byte sendt. I tillegg til å analysere server og URL statistikk, kan du bruke flere filtre for å matche logger med en gitt responstid, HTTP statuskode, session avslutningskode, etc.
Haproxy Stats Page
Parsing loggene Med HALog er ikke den eneste måten å få beregninger ut Av HAProxy. Haproxy Stats-Siden kan aktiveres ved å legge tilstats enable – direktivet til en frontend eller listen – delen. Den viser live statistikk over serverne dine. Følg listen delen starter Stats siden lytter på port 8404:
Stats Siden er svært nyttig for å få umiddelbar informasjon om trafikken som strømmer Gjennom HAProxy. Det lagrer ikke disse dataene, skjønt, og viser data bare for en enkelt lastbalanser.
Haproxy Enterprise Dashboard i Sanntid
hvis Du bruker HAProxy Enterprise, har du tilgang til Dashbordet I Sanntid. Mens Stats-siden viser statistikk for en enkelt forekomst Av HAProxy, samler Dashbordet I Sanntid og viser informasjon på tvers av en klynge av lastbalansere. Dette gjør det enkelt å observere helsen til alle serverne dine fra en enkelt skjerm. Data kan vises i opptil 30 minutter.
dashbordet lagrer og viser informasjon om tjenestetilstand, forespørselsrater og belastning. Det gjør det også enklere å utføre administrative oppgaver, for eksempel å aktivere, deaktivere og tømme backends. På et øyeblikk kan du se hvilke servere som er oppe og hvor lenge. Du kan også vise stick tabelldata, som, avhengig av hva stick tabellen sporer, kan vise deg feilrater, forespørselsrater og annen sanntidsinformasjon om brukerne dine. Stick tabelldata kan også aggregeres.
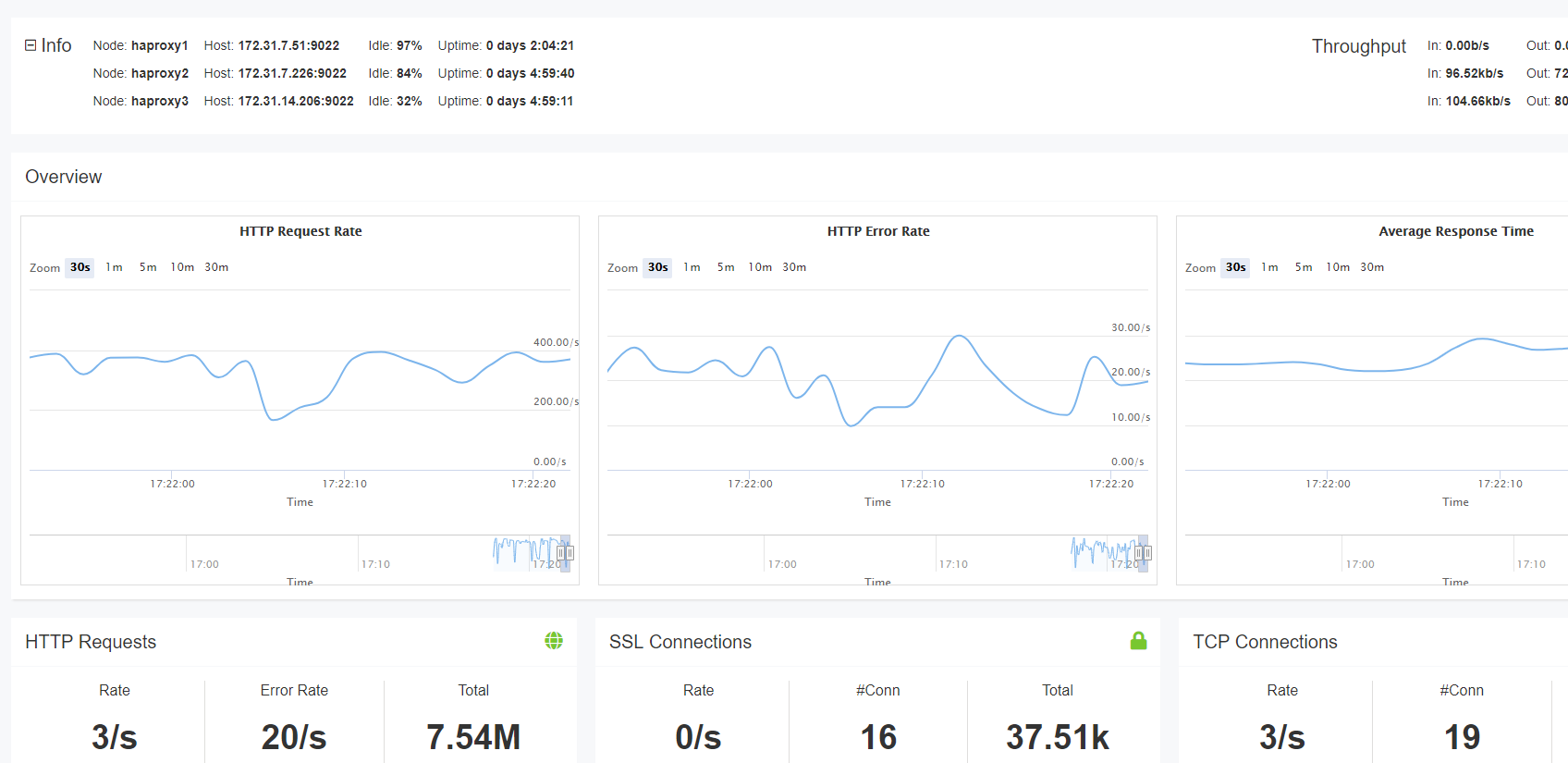
Sanntidsdashbordet i HAProxy Enterprise
Sanntidsdashbordet er et av mange tillegg som er tilgjengelige med HAProxy Enterprise.
Konklusjon
i dette blogginnlegget lærte du hvordan du konfigurerer haproxy-logging for å få observerbarhet over lastbalanseren din, som er en kritisk komponent i infrastrukturen din. HAProxy avgir detaljerte Syslog meldinger når de opererer i ENTEN TCP og HTTP-modus. Disse kan sendes til en rekke loggverktøy, for eksempel rsyslog.
haproxy leveres Med HALog kommandolinjeverktøy, som forenkler parsing loggdata når du trenger informasjon om hvilke typer svar brukerne får og belastningen på serverne. Du kan også få en visuell av helsen til serverne dine ved Å bruke Haproxy Stats-Siden eller Haproxy Enterprise Real-Time Dashboard.
Vil du vite når innhold som dette publiseres? Abonner på denne bloggen eller følg Oss På Twitter. Du kan også delta i samtalen På Slack! Haproxy Enterprise kombinerer haproxy med funksjoner i bedriftsklassen, for Eksempel Dashbordet I Sanntid og premium support. Kontakt oss for å lære mer eller registrer deg for en gratis prøveversjon i dag!